1.本发明是关于一种基于位置的多阶段逐次减小的流行病确诊患者密切接触人员检测方法及系统,属于基于位置服务的流行病传播网络挖掘技术。具体涉及用户位置数据获取、地理位置信息分析、地理位置信息聚类。
背景技术:
2.流行病学中的密切接触者:密切接触者就是指与病毒确诊或高度疑似病例有直接居住生活在一起的成员。包括办公室的同事,学校里一个班级的学生及班主任老师,同一教室、宿舍的同事、同学,同机的乘客等。以及其它形式的直接接触者包括病毒病人的陪护、乘出租车、乘电梯等直接接触者,根据流行病学调查和现场情况由卫生防疫人员综合评定确定的接触者史,以及其它形式的直接接触者,就是指14天内曾与病毒的确诊或高度疑似病例有过共同的生活或工作的人。
3.在此次疫情期间,由于新冠肺炎病毒存在易感染、潜伏期较长、可在潜伏期内传播且可通过气溶胶传播的特点,因此,导致了疫情极易扩散。尤其是对于一些无症状感染者,他们未知自身携带病毒,在这种情况下,一旦他们与其他人进行了密切接触,则很容易对其他人造成感染,若不对患者的密切接触人员进行控制,则很容易导致疫情爆发扩散,因此,在当下疫情已经得到一定控制的情况下,实时对疫情进行监控,以便及时发现患者的密切接触者至关重要。
4.在疫情发生期间,常用的方法是利用政府机关的交通数据来筛查人员流动路径,该方法存在严重依赖数据准确性、筛查严密性不高、实时性较差等问题。若采用聚类的方法进行密切接触人员的检测,对于这种百万级的大数据,在实际操作中,利用普通的聚类算法难以完成计算。本发明则考虑使用一种基于位置的多阶段逐次减小的聚类方法,通过降低算法的计算复杂度,使得计算速度极大提高。
技术实现要素:
5.针对上述问题,本发明的目的是提供一种能够在疫情期间快速找到确诊患者的密切接触人员的基于位置的多阶段逐次减小的流行病确诊患者密切接触人员检测方法及系统。
6.为实现上述目的,本发明采取一下技术方案:一种基于位置的多阶段逐次减小的流行病确诊患者密切接触人员检测方法,其特征在于,包括以下内容:
7.1)从某地图软件中采集用户在某城市一天内的位置数据,对8时到22时的用户位置数据进行切片,每隔t小时切片一次,共设14/t 1个时间切片(时间快照)。其中,切片的数目并非固定,可以根据不同城市的具体要求,每天选取的时间切片个数可以有相应的差异,例如,对于疫情较为严重的城市,可以采用每半小切片一次,每天共设置30个时间切片,疫情较轻的城市可每1小时切片一次,每天共设15个切片。
8.2)对每一个时间切片进行聚类。每一个用户为1个样本点,样本点分为三类,分别为:特征值为1的确诊感染者;特征值为0的风险未知者;特征值为-1的排除风险者。类也分为三种,分别为:特征值为1的存在风险类;特征值为0的风险未知类;特征值为-1的排除风险类。在每次聚类只给定一个初始特征值为1的样本点。
9.3)使用本发明提出的残k-means方法进行聚类。首先,根据城市的区域划分或地域特点,给定一个初始类别数目k值,按照k-means方法对所有的样本点进行聚类,在聚类开始时,全部类别初始特征值为0,即无法排除风险。在聚类过程中,对于特征值为1的确诊感染者,若其在多次迭代过程中,从未出现在某一类中,则可认为在该置信度下,这一类的特征可改写为-1,在后续的计算中可忽略此类。对于特征值为-1的未患病人员,若在多次迭代过程中,持续被划分在排除风险的类别中,则可认为在该置信度下该样本的特征值可标为-1,在后续过程中可忽略这些样本。利用这种方法,可以持续缩减需要参与到计算中来的数据量,从而可以实现在计算速度上的极大提高。
10.4)持续对剩余的样本点进行残k-means聚类。在迭代过程中,排除风险的类别和样本在计算中被逐渐忽略,对无法排除风险的类别不断进行聚类,当聚类结果保持不变时,迭代结束,完成聚类。在聚类中剩余的类均为无法排除风险的类别,这些类中的样本点均无法排除与确诊患者密切接触的风险。对于各时间片内的密切接触者,可基于频次叠加确定其感染概率。
11.优选地,所述步骤1)中,对8时到22时的用户位置数据进行切片,其中,在每一个时间切片中,对于一个用户m,其位置可以用位置函数l(m)进行表示。
12.优选地,所述步骤3)中,使用本发明提出的残k-means方法进行聚类,在聚类过程中,对于样本点m,需要计算其到每一个类的距离,并将该样本点划分到距离其最近的一个类中。样本点m到类n的距离可以表示为d=l(m)-l(c_n),其中,c表示类n的中心。
13.优选地,所述步骤3)中,使用本发明提出的残k-means方法进行聚类,在每次迭代结束后,需要为在此次迭代中有变化的类更新类的中心位置,类的中心采用均值方法进行计算。例如,对于点a(x1,y1)、b(x2,y2)和c(x2,y2),这三个点的中心可以表示为(x1 x2 x3)/3和(y1 y2 y3)/3。
14.优选地,所述步骤3)中,对于特征值为1的确诊感染者,若其在多次迭代过程中,从未出现在某一类中,则可认为在该置信度下,这一类的特征可改写为-1,在后续的计算中可忽略此类。对于特征值为-1的未患病人员,若在多次迭代过程中,持续被划分在排除风险的类别中,则可认为在该置信度下该样本的特征值可标为-1,在后续过程中可忽略这些样本。其中,迭代次数越多,则可排除此类或此样本点的置信度越高,迭代次数越少,则可排除此类的置信度越低。
15.一种基于位置的多阶段逐次减小的流行病确诊患者密切接触人员检测系统,其特征在于,包括:用户位置数据切片模块,用于从某地图软件中采集用户在某城市一天内的位置数据,并对8时到22时的用户位置数据进行切片,其中每隔t小时切片一次,共设14/t 1个时间切片;地理位置信息聚类模块,用于根据每一时间切片中的用户位置数据进行本发明提出的多阶段逐次减小的残k-means聚类,通过在聚类过程中不断忽略已经排除感染风险的类别和样本,进而大大减少了聚类运算的时间复杂度,使得在疫情期间的利用大规模聚类算法寻找密切接触人员成为可能;感染概率判别模块,对于每一个时间切片,地理位置信
息聚类模块会给出该时间切片下存在感染风险的样本,该模块根据上述数据样本,进行叠加,基于频次给出相应的感染概率。
16.本发明由于采取以上技术方案,其具有以下优点:1、本发明基于大规模数据的聚类需求,基于通用聚类算法做出改进,并依照实际应用需求,提出一种在该场景下可行性的聚类方法,即残k-means聚类,这种方法通过剔除多次筛选中人工确认的数据,可以排除一些聚类、一些节点,以提高计算效率,使得用户位置数据得以充分利用,聚类速度极大提高。2、本发明对于政府机构而言,是有效的疫情防控筛查工具;对于数据提供方而言,可以更有效地利用数据仓库在实际应用场景进行挖掘;对于用户而言,授权数据共享可以对自己的行动路径有更为清晰准确的评估,以采取预防和准备。
附图说明
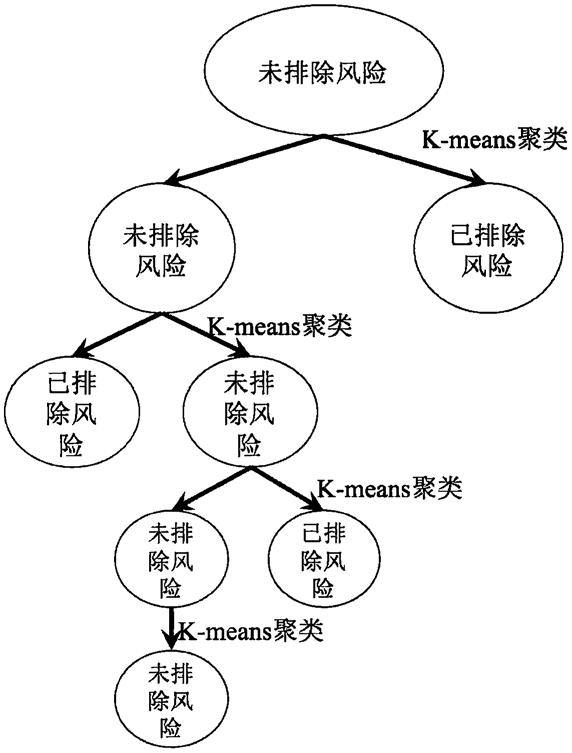
17.附图为利用残k-means方法进行聚类的过程,图中的每一层表示对上一层的部分未排除风险的聚类结果继续进行k-means聚类的结果。
具体实施方式
18.以下结合附图来对本发明进行详细的描绘。然而应当理解,附图的提供仅为了更好地理解本发明,它们不应该理解成对本发明的限制。在本发明的描述中,需要理解的是,术语“第一”、“第二”等仅仅是用于描述的目的,而不能理解为指示或暗示相对重要性。
19.对k-means聚类算法做简单的解释:
20.k-means算法是指k均值聚类算法,其步骤可描述如下:
21.1)预先选取k个类的聚类中心。
22.2)对于每一个样本点,计算其到每个聚类中心的距离,将该样本点归到与其距离最短的聚类中心所在的类,并更新发生变化的类的中心值。
23.3)不断进行上述k-means算法中步骤2)中的迭代,直至各类不再发生变化时,迭代结束。
24.k-means方法是一种简单直观的基于位置的聚类方法,但是在面对较大的数据量时,由于要不断进行迭代,给计算带来了较大的困难。
25.而本发明提出的残k-means算法可以在发现确诊患者肯定不在某一类里时,在后面的迭代中忽略这一类和肯定属于这一类的样本点,能够在寻找确诊患者的密切接触人员的过程中,舍弃可以舍弃的计算量,从而大大提高了计算速度,减少了k-means聚类算法的资源消耗,适合在疫情期间用来寻找确诊患者的密切接触人员。
26.本发明提供的基于位置的多阶段逐次减小的流行病确诊患者密切接触人员检测方法,包括以下内容:
27.1)从某地图软件中采集用户在某城市一天内的位置数据,对8时到22时的用户位置数据进行切片,每隔t小时切片一次,共设14/t 1个时间切片(时间快照)。其中,切片的数目并非固定,可以根据不同城市的具体要求,每天选取的时间切片个数可以有相应的差异,例如,对于疫情较为严重的城市,可以采用每半小切片一次,每天共设置30个时间切片,疫情较轻的城市可每1小时切片一次,每天共设15个切片。
28.2)对每一个时间切片进行聚类。每一个用户为1个样本点,样本点分为三类,分别
为:特征值为1的确诊感染者;特征值为0的未风险未知者;特征值为-1的排除风险者。类也分为三种,分别为:特征值为1的存在风险类;特征值为0的风险未知类;特征值为-1的排除风险类。在每次聚类只给定一个初始特征值为1的样本点。
29.3)使用本发明提出的残k-means方法进行聚类。首先,根据城市的区域划分或地域特点,给定一个初始类别数目k值,按照k-means方法对所有的样本点进行聚类,在聚类开始时,全部类别初始特征值为0,即无法排除风险。在聚类过程中,对于特征值为1的确诊感染者,若其在多次迭代过程中,从未出现在某一类中,则可认为在该置信度下,这一类的特征可改写为-1,在后续的计算中可忽略此类。对于特征值为-1的未患病人员,若在多次迭代过程中,持续被划分在排除风险的类别中,则可认为在该置信度下该样本的特征值可标为-1,在后续过程中可忽略这些样本。利用这种方法,可以持续缩减需要参与到计算中来的数据量,从而可以实现在计算速度上的极大提高。
30.4)持续对剩余的样本点进行残k-means聚类。在迭代过程中,排除风险的类别和样本在计算中被逐渐忽略,对无法排除风险的类别不断进行聚类,当聚类结果保持不变时,迭代结束,完成聚类,在聚类中剩余的样本点均无法排除与确诊患者密切接触的风险。此时,初始存在的节点有一大部分都已经被舍弃,也正是因为不断舍弃排除风险节点,才使得本发明提出残k-means算法可以完成聚类要求。对于各时间片内的密切接触者,可基于频次叠加确定其感染概率。
31.上述步骤1)中,对8时到22时的用户位置数据进行切片,其中,在每一个时间切片中,对于一个用户m,其位置可以用位置函数l(m)进行表示。
32.上述步骤3)中,使用本发明提出的残k-means方法进行聚类,在聚类过程中,对于样本点m,需要计算其到每一个类的距离,并将该样本点划分到距离其最近的一个类中。样本点m到类n的距离可以表示为d=l(m)-l(c_n),其中,c表示类n的中心。
33.上述步骤3)中,使用本发明提出的残k-means方法进行聚类,在每次迭代结束后,需要为在此次迭代中有变化的类更新类的中心位置,类的中心采用均值方法进行计算。例如,对于点a(x1,y1)、b(x2,y2)和c(x2,y2),中心可以表示为(x1 x2 x3)/3和(y1 y2 y3)/3。
34.上述步骤3)中,在聚类过程中,对于特征值为1的确诊感染者,若其在多次迭代过程中,从未出现在某一类中,则可认为在该置信度下,这一类的特征可改写为-1,在后续的计算中可忽略此类。对于特征值为-1的未患病人员,若在多次迭代过程中,持续被划分在排除风险的类别中,则可认为在该置信度下该样本的特征值可标为-1,在后续过程中可忽略这些样本。其中,迭代次数越多,则可排除此类或此样本点的置信度越高,迭代次数越少,则可排除此类的置信度越低。
35.上述步骤4)中,迭代过程中,排除风险的类别在计算中被逐渐忽略,对无法排除风险的类别不断进行聚类,当聚类结果保持不变时,迭代结束,完成聚类。该过程可以理解为:对于已知的确诊患者,该特征值为1的样本会被划分到某一类中,那么在接下来的聚类过程中,需要对这一类再次进行上述步骤3)中的聚类过程,直至聚类结果保持不变为止。
36.述步骤4)中,迭代过程中,排除风险的类别在计算中被逐渐忽略,对无法排除风险的类别不断进行聚类,当聚类结果保持不变时,迭代结束,完成聚类。在这一聚类过程中,需要参与聚类的节点数目也随着聚类过程不断减少,在聚类趋近于终止时,节点数据会趋于收敛。聚类结束后的结果即为在该时间切片中,每一个确诊患者和其在该时刻下的密切接
触者。
37.述步骤4)中,对于各时间片内的密切接触者,可基于频次叠加确定其感染概率。对于不同的时间片,若同一个样本在不同的时间片中被判断为存在感染风险的频次高,则可判断其感染概率高,若被判断为存在感染风险的频次低则可判断为感染概率相对较低。
38.残k-means算法的核心思想则是在聚类过程中不断舍弃已经排除风险的类和节点,由于一个确诊患者的可传染范围有限,因此,在实际操作中,一大部分的节点都可以在这一过程中被忽略掉,从而可以尽最大的可能缩减参与计算的数据量,能够极大提高聚类算法的运算速度。相比一个一般性的时空聚类算法,可能计算速度远远达不到这么快,甚至是不可解的。但对于这样确定性的问题,即找已经确诊者的密切接触者,残k-means算法可以通过舍弃可以舍弃的节点和类,极大提高聚类的速度,具有较高的技术优势,在这种情景下,利用本发明提出的残k-means算法进行聚类是可行的。
39.基于上述一种基于位置的多阶段逐次减小的流行病确诊患者密切接触人员检测方法,本发明还提供一种基于位置的多阶段逐次减小的流行病确诊患者密切接触人员检测系统,包括:用户位置数据切片模块,用于从某地图软件中采集用户在某城市一天内的位置数据,并对8时到22时的用户位置数据进行切片,其中每隔t小时切片一次,共设14/t 1个时间切片;地理位置信息聚类模块,用于根据每一时间切片中的用户位置数据进行本发明提出的多阶段逐次减小的残k-means聚类,通过在聚类过程中不断忽略已经排除感染风险的类别和样本,进而大大减少了聚类运算的时间复杂度,使得在疫情期间的利用大规模聚类算法寻找密切接触人员成为可能;感染概率判别模块,对于每一个时间切片,地理位置信息聚类模块会给出该时间切片下存在感染风险的样本,该模块根据上述数据样本,进行叠加,基于频次给出相应的感染概率。
40.上述各实施例仅用于说明本发明,其中各部件的结构、连接方式和制作工艺等都是可以有所变化的,凡是在本发明技术方案的基础上进行的等同变换和改进,均不应排除在本发明的保护范围之外。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。