1.本发明涉及图像处理领域,尤其涉及利用深度学习模型对图像进行处理以确定图像中对象的三维尺寸的图像处理领域。
背景技术:
2.随着移动互联网的发展,用户试图利用移动终端,特别是移动终端的摄像头拍摄人脚的图像,并从图像中获取脚的尺寸。
3.目前利用移动终端来测量脚尺寸的方案包括在拍摄脚的图像同时,在图像中放入预先已知尺寸的参考物(如身份证),并通过计算单应性变换(homorgraphy)来确定脚的尺寸,该方案把3d测量退化为平面的2d测量。
4.还有一种方案是考虑到移动终端中除了摄像头之外,还有其它传感器(例如惯性传感器),因此可以利用视觉惯性测量系统(vio),通过摄像头拍摄视频以确定视频中对象的尺寸信息。这种方案的典型例子包括例如arkit和arcore等。
5.因此,如上所述,需要一种新的、利用移动终端的对象测量方法,可以准确地获得对象的物理三维尺寸。
技术实现要素:
6.为此,本发明提供了一种对象的三维尺寸测量的方法和移动终端,以力图解决或至少缓解上面存在的至少一个问题。
7.根据本发明的一个方面,提供了一种对象的三维尺寸测量方法,该对象的三维模型可以表征为多个主成分分量。该方法包括步骤:获取包括该对象的二维图像;确定该二维图像中的特征点,特征点包括该对象的特征点;根据二维图像中的特征点来计算指示该对象和二维图像之间的投影关系的投影矩阵;确定该对象在二维图像中的特征点;计算根据投影矩阵将三维模型上的特征点投影到二维平面上之后的投影特征点;确定每个主成分分量相对应的权重,以使得投影特征点和所确定的对象的特征点之间的第一差值在第一预定范围之内;以及根据所确定的各主成分分量的权重来确定该对象的三维模型,以便根据所确定的三维模型来确定该对象的各三维尺寸。
8.可选地,在根据本发明的测量方法中,二维图像中还包括具有已知尺寸和形状的参照对象。计算投影矩阵的步骤包括:提取二维图像中的参照对象的角点作为二维图像的特征点;以及根据参照对象的角点位置、已知尺寸和形状来计算投影矩阵。
9.可选地,在根据本发明的测量方法中,计算投影矩阵的步骤包括:使用对象在所确定的二维图像中的特征点作为该二维图像的特征点;以及根据三维模型上的对应特征点位置信息和二维图像中的对象的特征点位置信息来计算该投影矩阵。
10.可选地,在根据本发明的测量方法中,计算投影矩阵的步骤包括根据黄金标准算法来确定该投影矩阵。
11.可选地,在根据本发明的测量方法中,该对象的三维模型可以表征为对象的平均
模型和多个主成分分量的加权和。
12.可选地,根据本发明的测量方法还包括步骤:确定对象在二维图像中的对象轮廓;以及计算根据投影矩阵将三维模型投影到二维平面上的投影轮廓。确定每个主成分分量相对应的权重还包括:确定该权重,以使得第一差值和该投影轮廓和所确定的对象轮廓之间的第二差值之和在第二预定范围之内。
13.可选地,在根据本发明的测量方法中,其中确定每个主成分分量的权重的步骤包括:为第一差值和第二差值分配权重;以及确定每个主成分分量相对应的权重,以使得第一差值和第二差值的加权和在所述第二预定范围之内。
14.可选地,在根据本发明的测量方法中,确定每个主成分分量的权重的步骤包括:确定每个主成分分量相对应的第一权重,以使得所述第一差值在第三预定范围之内;根据所确定的第一权重更新该对象的三维模型,并重新计算投影关键点和投影轮廓;以及确定每个主成分分量相对应的权重,以使得根据重新计算的投影关键点和投影轮廓所计算的第一差值和第二差值的加权和在所述第二预定范围之内。
15.可选地,在根据本发明的测量方法中,计算投影轮廓的步骤包括:选择在该三维模型上的预定个投影点,并计算所选择的投影点在该二维平面上的投影轮廓位置;选择在该对象轮廓中与该投影轮廓位置最接近的点作为对象轮廓点;以及计算各投影轮廓位置和对应对象轮廓点之间的距离之和,以作为第二差值。
16.可选地,在根据本发明的测量方法中,获取对象的二维图像的步骤包括:使用移动终端的摄像头拍摄该对象的多张图像。
17.可选地,在根据本发明的测量方法中,获取包括对象的二维图像的步骤包括:使用移动终端的摄像头拍摄该对象的一段视频;以及从该视频中获取多个视频帧作为包括该对象的图像。
18.可选地,在根据本发明的测量方法中,确定对象特征点的步骤包括:利用卷积神经网络对该二维图像进行处理,以确定对象特征点。
19.可选地,在根据本发明的测量方法中,确定该对象在二维图像中的轮廓的方法包括:利用卷积神经网络对该二维图像进行图像分割处理,以提取对象轮廓。
20.可选地,在根据本发明的方法中,该对象为脚。
21.可选地,在根据本发明的方法中,该对象的各三维尺寸包括下列尺寸中的一个或者多个:脚长、脚宽、脚背高、跖趾围和跗围。
22.根据本发明的另一个方面,提供了一种移动终端,包括:摄像头,适于拍摄对象的一张或者多张二维图像;以及尺寸测量应用,适于执行根据本发明的测量方法,以确定摄像头拍摄的对象的三维尺寸。
23.根据本发明的再一个方面,提供了一种计算设备,包括:至少一个处理器;和存储有程序指令的存储器,其中,程序指令被配置为适于由至少一个处理器执行,程序指令包括用于执行如上所述任一方法的指令。
24.根据本发明的方案,将对象的三维模型表征为对象的平均模型和多个主成分分量的加权和,这样确定对象的三维模型就转变为确定各主成分分量的权重值。随后,先确定将三维对象投影到二维平面上的投影矩阵,并将该投影矩阵用在三维对象的关键点和对象本身上,以获得投影后的二维关键点位置和对象轮廓,并通过迭代计算的方式,使得拍摄图像
中的二维关键点和对象轮廓与投影计算得到的相应关键点和对象轮廓之间的差值在一个预定范围之内,从而确定各主成分分量的权重值,并最终获得对象的三维模型和相应尺寸。
25.另外,根据本发明的方案,利用深度学习模型,特别是卷积神经网络来进行图像处理,以更准确地获取图像中的关键点和轮廓,可以进一步提高该方案的准确度。
26.此外,根据本发明的方案,在确定各主成分分量的权重值时,可以按照顺序先考虑投影关键点和所确定的对象关键点之间的第一差值,并随后考虑投影轮廓和所确定的对象轮廓之间的第二差值,这样可以首先获取一个准确度稍低的权重值,并在此基础上进一步迭代以获取准确度更高的权重值,从而加快计算权重值的速度。
27.根据本发明的方案可以在实践中用于测量人的脚,通过事先构造人脚的平均模型并确定相应的主成分分量,随后利用本发明的方案确定人脚的物理三维模型,从而进一步确定脚的各个三维尺寸,并可以很好地应用于例如鞋的定制和选型等领域。
28.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
29.为了实现上述以及相关目的,本文结合下面的描述和附图来描述某些说明性方面,这些方面指示了可以实践本文所公开的原理的各种方式,并且所有方面及其等效方面旨在落入所要求保护的主题的范围内。通过结合附图阅读下面的详细描述,本公开的上述以及其它目的、特征和优势将变得更加明显。遍及本公开,相同的附图标记通常指代相同的部件或元素。
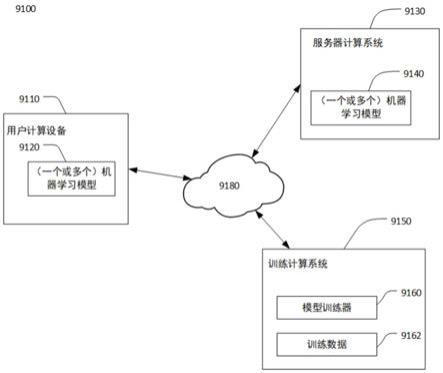
30.图1a示出了根据本发明的一些实施方式的示例计算机系统9100的示意图;
31.图1b示出了根据本发明的一些实施方式而作为机器学习模型9120的一种深度神经网络的示意图;
32.图2a示出了根据本发明一个实施例的计算设备200的示意图;
33.图2b以软件栈的形式示出了包括人工智能的应用在计算设备200中的实现方式;
34.图3示出了根据本发明一个实施例的对象的三维尺寸测量方法300的流程图;以及
35.图4a和4b示出了人脚三维模型上的各种特征尺寸值。
具体实施方式
36.下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
37.图1a描绘了根据本公开的示例实施例的示例计算系统9100的框图。系统9100包括通过网络9180通信地耦接的用户计算设备9110、服务器计算系统9130和训练计算系统9150。
38.用户计算设备9110可以是任何类型的计算设备,包括但不限于例如个人计算设备(例如,膝上型或者桌面型计算机)、移动计算设备(智能电话或平板电脑)、游戏控制台或控
制器、可穿戴计算设备、嵌入式计算设备、边缘计算设备或任何其他类型的计算设备。用户计算设备9110可以作为端智能设备部署在用户现场处,并与用户进行交互而处理用户输入。
39.用户计算设备9110可以存储或包括一个或多个机器学习模型9120。机器学习模型9120可以被设计用于执行各种任务,诸如图像分类、目标检测、语音识别、机器翻译、内容过滤等等。机器学习模型9120可以是诸如神经网络(例如,深度神经网络)或者包括非线性模型和/或线性模型在内的其他类型的机器学习模型。机器学习模型9120的示例包括但不限于各类深度神经网络(dnn),如前馈神经网络、递归神经网络(rnn,例如,长短期记忆递归神经网络(lstm)、包括或者不包括注意力机制(attention)的转换器神经网络(transformer))、卷积神经网络(cnn)或其他形式的神经网络。机器学习模型9120可以包括一个机器学习模型,或者可以是多个机器学习模型的组合。
40.图1b中示出了根据一些实施方式而作为机器学习模型9120的一种神经网络。神经网络具有分层架构,每一网络层具有一个或多个处理节点(称为神经元或滤波器),用于处理。在深度神经网络中,前一层执行处理后的输出是下一层的输入,其中架构中的第一层接收网络输入用于处理,而最后一层的输出被提供为网络输出。如图1b所示,机器学习模型9120包括网络层9122、9124、9126等,其中网络层9124接收网络输入,网络层9126提供网络输出。
41.在深度神经网络中,网络内的主要处理操作是交织的线性和非线性变换。这些处理分布在各个处理节点。图1b还示出了模型9120中的一个节点9121的放大视图。节点9121接收多个输入值a1、a2、a3等等,并且基于相应处理参数(诸如权重w1、w2、w3等)对输入值进行处理,以生成输出z。节点9171可以被设计为利用一个激活函数来处理输入,这可以被表示为:
42.z=σ(w
t
α b)
ꢀꢀꢀ
(1)
43.其中α∈r
n
表示节点9121的输入向量(其中包括元素a1、a2、a3等);w∈r
n
表示节点9121所使用的处理参数中的权重向量(其中包括元素w1、w2、w3等),每个权重用于加权相应的输入;n表示输入值的数目;b∈r
n
表示节点9121所使用的处理参数中的偏置向量(其中包括元素b1、b2、b3等),每个偏置用于偏置相应的输入和加权的结果;σ( )表示节点9121所使用的激活函数,激活函数可以是线性函数、非线性函数。神经网络中常用的激活函数包括sigmoid函数、relu函数、tanh函数、maxout函数等等。节点9121的输出也可以被称为激活值。取决于网络设计,每一网络层的输出(即激活值)可以被提供给下一层的一个、多个或全部节点作为输入。
44.在机器学习模型9120中的每个网络层可以包括一个或多个节点9121,当以网络层为单位来查看机器学习模型9121中的处理时,每个网络层的处理也可以被类似表示为公式(1)或公式(2)的形式,此时a表示网络层的输入向量,而w表示网络层的权重。
45.应当理解,图1b示出的机器学习模型的架构以及其中的网络层和处理节点的数目均是示意性的。在不同的应用中,根据需要,机器学习模型可以被设计为具有其他架构。
46.继续参考图1a,在一些实现方式中,用户计算设备9110可以通过网络9180从服务器计算系统130接收机器学习模型9120,存储在用户计算设备的存储器中并由在用户计算设备中的应用来使用或者实现。
47.在另一些实现方式中,用户计算设备9110可以调用在服务器计算系统9130中存储和实现的机器学习模块9140。例如,机器学习模型9140可以由服务器计算系统9130实现为web服务的一部分,从而用户计算设备9110可以例如通过网络9180并根据客户端-服务器关系来调用作为web服务实现的机器学习模型9140。因此,可以在用户计算设备102处使用的机器学习模块包括在用户计算设备9110处存储和实现的机器学习模型9120和/或在服务器计算系统9130处存储和实现的机器学习模型9140。
48.用户计算设备9110还可以包括接收用户输入的一个或多个用户输入组件9122。例如,用户输入组件9122可以是对用户输入对象(例如,手指或指示笔)的触摸敏感的触敏组件(例如,触敏显示屏或触摸板)。触敏组件可用于实现虚拟键盘。其他示例用户输入组件包括麦克风、传统键盘、摄像头或用户可以通过其提供用户输入的其他设备。
49.服务器计算系统9130可以包括一个或多个服务器计算设备。在服务器计算系统9130包括多个服务器计算设备的情况下,这些服务器计算设备可以根据顺序计算架构、并行计算架构或其一些组合来操作。
50.如上所述,服务器计算系统9130可以存储或包括一个或多个机器学习模型9140。类似于机器学习模型9120,机器学习模型9140可以被设计用于执行各种任务,诸如图像分类、目标检测、语音识别、机器翻译、内容过滤等等。模型9140可以包括各种机器学习模型。示例的机器学习模型包括神经网络或其他多层非线性模型。示例神经网络包括前馈神经网络、深度神经网络、递归神经网络和卷积神经网络。
51.用户计算设备9110和/或服务器计算系统9130可以经由与通过网络9180通信地耦接的训练计算系统9150的交互来训练模型9120和/或9140。训练计算系统9150可以与服务器计算系统9130分离,或者可以是服务器计算系统9130的一部分。
52.类似于服务器计算系统9130,训练计算系统9150可以包括一个或多个服务器计算设备或以其他方式由一个或多个服务器计算设备实现。
53.训练计算系统9150可以包括模型训练器9160,其使用诸如例如误差的反向传播的各种训练或学习技术训练存储在用户计算设备9110和/或服务器计算系统9130处的机器学习模型9120和/或9140。在一些实现方式中,执行误差的反向传播可以包括执行通过时间截断的反向传播(truncated backpropagation through time)。模型训练器9160可以执行多种泛化技术(例如,权重衰减、丢失等)以改进正在训练的模型的泛化能力。
54.具体地,模型训练器9160可以基于训练数据9162的集合来训练机器学习模型9120和/或9140。训练数据9162可以包括多个不同的训练数据集合,每个训练数据集合例如分别有助于训练机器学习模型9120和/或9140执行多个不同的任务的。例如,训练数据集合包括有助于机器学习模型9120和/或9140执行对象检测、对象识别、对象分割、图像分类和/或其他任务的数据集。
55.在一些实现方式中,如果用户已经明确同意,则训练示例可以由用户计算设备9110提供。因此,在这样的实现方式中,提供给用户计算设备9110的模型9120可以由训练计算系统9150在从用户计算设备9110接收的特定于用户的数据上训练。在一些情况下,该过程可以被称为个性化模型。
56.另外,在一些实现方式中,模型训练器9160可以对在服务器计算系统9130中的机器学习模型9140进行修改以获得适于在用户计算设备9110中使用的机器学习模型9120。这
些修改例如包括减少模型中的各种参数数量、以更小的精度来存储参数值等,以使得训练后的机器学习模型9120和/或9140适于考虑到服务器计算系统9130和用户计算设备9110的不同处理性能来运行。
57.模型训练器9160包括用于提供所期望的功能性的计算机逻辑。模型训练器9160可以用控制通用处理器的硬件、固件和/或软件来实现。例如,在一些实现方式中,模型训练器9160包括存储在存储设备上、加载到存储器中并由一个或多个处理器执行的程序文件。在其他实现方式中,模型训练器9160包括一个或多个计算机可执行指令的集合,其存储在诸如ram、硬盘或光学或磁性介质的有形计算机可读存储介质中。在一些实现方式中,模型训练器9160可以跨多个不同的设备复制和/或分布。
58.网络9180可以是任何类型的通信网络,诸如局域网(例如,内联网)、广域网(例如,因特网)或其一些组合,并且可以包括任何数量的有线或无线链路。通常,通过网络9180的通信可以经由任何类型的有线和/或无线连接,使用各种通信协议(例如,tcp/ip、http、smtp、ftp)、编码或格式(例如,html、xml和json)和/或保护方案(例如,vpn、https、ssl)来承载。
59.图2a示出了可用于实现本发明的一个示例计算系统。本发明也可以使用其他计算系统实现。例如,在一些实现方式中,用户计算设备9110可以包括模型训练器9160和训练数据集9162。在这样的实现方式中,模型9120可以在用户计算设备9110本地训练并使用。在一些这样的实现方式中,用户计算设备9110可以实现模型训练器9160,以基于特定于用户的数据来个性化模型120。
60.图1a所示的示例计算系统9100中的用户计算设备9110、服务器计算系统9130和训练计算系统9150均可以通过如下所述的计算设备9200来实现。图2a示出了根据本发明一个实施例的计算设备9200的示意图。
61.如图2a所示,在基本的配置9202中,计算设备9200典型地包括系统存储器9206和一个或者多个处理器9204。存储器总线9208可以用于在处理器9204和系统存储器9206之间的通信。
62.取决于期望的配置,处理器9204可以是任何类型的处理,包括但不限于:微处理器(μp)、微控制器(μc)、数字信息处理器(dsp)、图形处理器(gpu)、神经网络处理器(npu)或者它们的任何组合。处理器9204可以包括诸如一级高速缓存9210和二级高速缓存9212之类的一个或者多个级别的高速缓存、处理器核心9214和寄存器9216。示例的处理器核心9214可以包括运算逻辑单元(alu)、浮点数单元(fpu)或者它们的任何组合。示例的存储器控制器9218可以与处理器9204一起使用,或者在一些实现中,存储器控制器9218可以是处理器9204的一个内部部分。
63.取决于期望的配置,系统存储器9206可以是任意类型的存储器,包括但不限于:易失性存储器(诸如ram)、非易失性存储器(诸如rom、闪存等)或者它们的任何组合。系统存储器9206可以包括操作系统9220、一个或者多个应用9222以及数据9224。在一些实施方式中,一个或多个处理器9204执行应用中的程序指令并处理数据9224来实现应用9222的功能。
64.计算设备9200还可以包括接口总线9240。接口总线9240实现了从各种接口设备(例如,输出设备9242、外设接口9244和通信设备9246)经由总线/接口控制器9230到基本配置9202的通信。示例的输出设备9242包括图形处理单元9248和音频处理单元9250。它们可
以被配置为有助于经由一个或者多个a/v端口9252与诸如显示器或者扬声器之类的各种外部设备进行通信。示例外设接口9244可以包括串行接口控制器9254和并行接口控制器9256,它们可以被配置为有助于经由一个或者多个i/o端口9258和诸如输入设备(例如,键盘、鼠标、笔、语音输入设备、视频输入设备、触摸输入设备)或者其他外设(例如打印机、扫描仪等)之类的外部设备进行通信。示例的通信设备9246可以包括网络控制器9260,其可以被布置为便于经由一个或者多个通信端口9264与一个或者多个其他计算设备262通过网络通信链路(例如,通过网络9180)的通信。
65.计算设备9200还可以包括储存接口总线9234。储存接口总线9234实现了从储存设备9232(例如,可移除储存器9236和不可移除储存器9238)经由总线/接口控制器9230到基本配置9202的通信。操作系统9220、应用9222以及数据9224的至少一部分可以存储在可移除储存器9236和/或不可移除储存器9238上,并且在计算设备9200上电或者要执行应用9222时,经由储存接口总线9234而加载到系统存储器9206中,并由一个或者多个处理器9204来执行。
66.在一些实现方式中,在利用计算设备9200来实现服务器计算系统9130和/或训练计算系统9150时,计算设备9200可以不包括输出设备9242和外设接口9244,以便让计算设备9200专用于机器学习模型9140的推理和训练。
67.应用9222在操作系统9220上执行,即操作系统9220提供了各种对硬件设备(例如,储存设备9232、输出设备9242、外设接口9244和通信设备)进行操作的接口,并同时提供了应用上下文管理的环境(例如,存储空间管理和分配、中断处理、进程管理等)。应用9222利用操作系统9220提供的接口和环境来控制计算设备9200执行相应功能。在一些实现方式中,一些应用9222还提供了接口。这样另一些应用9222可以调用这些接口来实现功能。
68.图2b以软件栈的方式示出了应用9222在计算设备9200中的实现。如图2b所示,采用了机器学习模型9120/9140来进行推理的应用称为机器学习应用9602。如上所述,机器学习应用9602可以实现任何类型的机器智能,包括但不限于:图像识别、映射和定位、自主导航、语音合成、医学成像或语言翻译等。
69.机器学习框架9604可以提供机器学习操作单元库。机器学习操作单元是机器学习算法通常执行的基本操作。当机器学习模型9120/9140基于机器学习框架9604来设计和运行时,可以使用由机器学习框架604提供的操作单元来执行必要的计算。示例性的操作单元包括张量卷积、激活函数和池化,它们是在训练卷积神经网络(cnn)时执行的计算操作。机器学习框架604还可以提供操作单元以用于实现由许多机器学习算法执行的基本线性代数子程序,比如矩阵和向量运算。利用机器学习框架9604可以显著简化机器学习模型的开发过程,并提高其执行效率。例如,在没有机器学习框架604的情况下,机器学习模型的开发者需要从头开始创建和优化与机器学习算法相关联的主要计算逻辑,然后在开发出新的并行处理器时重新优化所述计算逻辑,这需要大量的时间和精力。市面上已知的机器学习框架9604例如包括谷歌公司的tensorflow和脸谱公司的pytorch等。本发明不受限于具体的机器学习框架9604,任何便于实现机器学习模型的机器学习框架都在本发明的保护范围之内。
70.机器学习框架9604可以处理从机器学习应用9602接收的输入数据,并生成适当的输出至计算框架9606。计算框架9606可以使提供给底层硬件驱动器9608的底层指令抽象
化,以使得机器学习框架9604能够利用硬件9610(例如,如2a中的处理器9204)提供的硬件加速功能而无需非常熟悉硬件9610的架构。另外,计算框架9606可以跨越多种类型和各代硬件9610来实现针对机器学习框架9604的硬件加速。例如,目前已知的计算框架9606包括nvidia公司的cuda等。本发明不受限于具体的计算框架9606,任何能够将硬件驱动器9608的指令进行抽象化并利用硬件9610的硬件加速功能的计算框架都在本发明的保护范围之内。
71.根据一种实施方式,底层硬件驱动器9608可以包含在操作系统9220中,而计算框架9606和机器学习框架9604可以实现为单独的应用,或者并入到各个应用9222中。所有这样的配置方式都是示意性的,并都在本发明的保护范围之内。
72.这里讨论的技术参考处理器、服务器、数据库、软件应用和其他基于计算机的系统、以及所采取的动作和发送到这些系统以及从这些系统发送的信息。基于计算机的系统的固有灵活性允许组件之间和之中的任务和功能性的各种可能的配置、组合以及划分。例如,这里讨论的处理可以使用单个设备或组件或组合工作的多个设备或组件来实现。数据库和应用可以在单个系统上实现或跨多个系统分布。分布式组件可以顺序或并行操作。
73.图3示出了根据本发明一个实施例的对象的三维尺寸测量方法300的流程图。方法300可以在参考图2a所述的计算设备200上执行。根据一种实施方式,计算设备200可以是一种移动终端,方法300在移动终端中驻留的一个应用上执行,该应用可以根据移动终端中的操作系统9220提供的接口来调用移动终端上的摄像头来拍摄要测量对象的图像或者视频。
74.对于诸如人的脸和脚这样的对象来说,由于可以事先收集到大量的对象样本,因此可以基于变形模型(morphable model)进行对象的三维模型重建。具体而言,对所收集到的对象样本数据集进行分析,以从中确定对象模型的各个主成分分量,于是任意的对象模型s可以表征为:
[0075][0076]
其中,是平均的对象模型,s
i
是主成分分量,m是用来求解主成分分量的模型的个数,α
i
是权重系数。
[0077]
这样,对象的三维模型可以表征为多个主成分分量。进一步来说,对象的三维模型可以表征为对象的平均模型和多个主成分分量的加权和,建立一个具体对象的三维模型就转换为确定该对象的各个主成分分量的权重系数值。
[0078]
在blanz volker,and thomas vetter等人1999年于siggraph.vol.99.上发表的文章."a morphable model for the synthesis of 3d faces."中已经公开了有关变形模型(morphable model)进行对象的三维模型重建的具体内容,这里通过引用的方式将该公开的内容在此并入,且为了节省说明书的篇幅,不在此进行详细描述。
[0079]
方法300始于步骤s310。在步骤s310中,获取要确定三维尺寸的目标对象的一张或者多张二维图像,并优选为至少三张图像,以便在后续处理中可以对图像内容进行相互验
证而取得更高的效率。根据一种实施方式,可以利用移动终端的摄像头来拍摄目标对象的图像。例如,在一种方式中,可以用摄像头直接拍摄对象的多张图像。在另一种方式中,可以用摄像头拍摄对象的一段视频,并选择视频中的多个视频帧以作为对象的多张图像。根据一种实施方式,可以采用各种视频处理方式来处理视频,以选择视频中的关键帧作为对象的二维图像。例如可以选择场景内容变化较快的前后帧、或者视频质量最高的视频帧等来作为对象的二维图像。本发明不受限于选择视频中的视频帧的方式。
[0080]
随后,在步骤s320中,提取在步骤s310所获取的图像上的特征点,并根据特征点的属性来计算投影矩阵p。投影矩阵p指示对象和二维图像之间的投影关系,即投影矩阵p用于将三维位置投影到预定的二维平面上。具体而言,通过在投影矩阵p上进行矩阵乘法运算,将三维空间中的三维坐标转化为某个二维平面上的二维坐标。
[0081]
可以有多种方式来确定投影矩阵p。根据一种实施方式,可以在步骤s310获取对象的二维图像时,同时获取参照对象的图像。即在步骤s310所获取的图像中即包括要测量的对象还包括参照对象,而参照对象具有已知的尺寸的形状。因此,在步骤s320中,可以获取参考对象的一些关键点作为图像的特征点。例如,参考对象可以是固定大小的纸、银行卡或者身份证这样具有已知固定尺寸的对象。从图像中可以获取参考对象在图像中的角点位置作为特征点,然后根据参考对象的已知尺寸和形状来计算投影矩阵。bujnak,martin,zuzana kukelova,和tomas pajdla等人在2008年于2008 ieee conference on computer vision and pattern recognition发表的文章"a general solution to the p4p problem for camera with unknown focal length."中公开了利用参照对象来确定投影矩阵的具体内容,这里通过引用的方式将该公开的内容在此并入,且为了节省说明书的篇幅,不在此进行详细描述。
[0082]
根据另一种实施方式,可以在步骤s310所获取的二维图像中进行检测,以获取多个对象特征点作为特征点。例如,在对象为脚的情况下,脚的各个脚趾位置特征点可作为脚的特征点。如上所述,由于事先已经收集了大量的对象数据集,因此,也可以在这些对象数据集中进行图像处理以确定对象的特征点特征。基于所确定的特征点特征,可以采用各种图像处理方法来确定图像中的对象特征点。例如,可以采用深度学习模型,例如基于卷积神经网络的深度学习模型,在已收集的数据集上进行训练,并将所训练好的模型应用到步骤s310所获取的二维图像上,以确定其中的多个对象特征点。sun,yi,xiaogang wang,和xiaoou tang等人在2013年于proceedings of the ieee conference on computer vision and pattern recognition.2013发表的文章"deep convolutional network cascade for facial point detection."以及zhou,erjin,等人在2008年于proceedings of the ieee international conference on computer vision workshops.2013发表的文章"extensive facial landmark localization with coarse-to-fine convolutional network cascade."中公开了检测对象特征点的具体内容,这里通过引用的方式将该公开的内容在此并入,且为了节省说明书的篇幅,不在此进行详细描述。
[0083]
随后,根据对象三维模型上的对应特征点位置信息和所确定的二维图像上的对象特征点位置来计算投影矩阵。虽然此时对象的三维模型并不准确,但是在大量数据集的基础上构造的平均模型中包括了相应特征点的大概位置信息和相对位置信息,可以利用这样的平均模型中的特征点位置进行投影矩阵的运算,并后续通过迭代的方式逐步逼近。
[0084]
可以有多种方式,在对象模型的三维特征点位置和对应二维图像上的特征点位置信息的基础上,计算投影矩阵。根据一种实施方式,可以采用黄金标准算法来确定该投影矩阵。hartley,richard,和andrew zisserman在2003年由cambridge university press出版的图书multiple view geometry in computer vision中公开了利用黄金标准算法计算投影矩阵的具体内容,这里通过引用的方式将该公开的内容在此并入,且为了节省说明书的篇幅,不在此进行详细描述。
[0085]
随后,在步骤s330中,分别确定步骤s310中所获取图像中的对象特征点和对象轮廓。上面对步骤s330的说明中,已经描述了获取对象特征点的详细内容,这里不再进行赘述。
[0086]
类似地,可以利用各种图像处理技术,例如图像分割技术来对图像进行处理以获取图像中的对象轮廓。根据一种实施方式,可以采用诸如grabcut、graphcut之类的图像分割方法对图像进行分割处理,以获取对象轮廓。另外,根据一种实施方式,可以采用深度学习模型,例如卷积神经网络来对图像进行处理,以获取对象轮廓。深度学习模型可以先在已收集的对象数据集上进行训练,然后将训练好的模型应用到步骤s310所获取的图像上,对图像进行分割处理,以获取对象轮廓。chen,liang-chieh等人在2017年于ieee transactions on pattern analysis and machine intelligence 40.4(2017):834-848发表的文章"deeplab:semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected crfs."中公开了利用卷积神经网络来对图像进行分割以确定对象轮廓的具体内容,这里通过引用的方式将该公开的内容在此并入,且为了节省说明书的篇幅,不在此进行详细描述。
[0087]
随后,基于在步骤s320确定的投影矩阵和在步骤s330确定的图像中的对象特征点位置和对象轮廓信息来计算对象三维模型中的各主成分分量的权重。具体来说,要求解变形模型中的各个权重值,以使得通过投影矩阵获得的平面投影和步骤s310获取的二维图像中的特征点的位置尽量接近,即计算下面的等式:
[0088][0089]
其中,x
i
是从步骤s310所获取的图像中提取的对象二维特征点,x
i
是对象三维模型上对应的3d特征点,f(ps
j
)是根据步骤s320计算出的投影矩阵p把对象三维模型s投影到平面并求轮廓,y
j
是步骤s330获取的脚部轮廓上离散点。n是特征点个数,m是轮廓点个数,γ
i
和η
j
是对应的权重。
[0090]
应当注意的是,针对上面等式的计算,根据实际情况,当上述计算得到的值在预定范围之内时,就可以认为已经达到了最小化的程度,而不再进行进一步的计算。
[0091]
具体而言,在步骤s340中,计算px
i
,即利用投影矩阵p将三维模型上的n个对应特征点投影到二维平面上之后的投影特征点位置;以及计算f(ps
j
),即利用投影矩阵p将三维模型s投影到平面上之后,在轮廓上的m个点的位置信息。求投影后轮廓位置的函数f可以根据对象的特征来确定,并且可以采用本领域任何常用的技术来执行,并不再进行赘述。
[0092]
可以多种方式来选择要投影的轮廓位置点信息,例如可以固定间隔预定距离选择一个位置点,或者根据对象的特征选择一些特征轮廓点进行轮廓位置投影,所有这些都在
本发明的保护范围之内。
[0093]
随后,在步骤s350中,分别计算‖px
i-x
i
‖2和||f(ps
j
)-y
j
||2,即投影特征点和所确定的对象特征点之间的第一差值,以及投影轮廓和所确定的对象轮廓中选定点之间的第二差值。由于存在多个点,为了计算总的差值,可以采用平方和的方式。本发明不受限于此,任何可以计算多个点之间的差值总和的方式都在本发明的保护范围之内。
[0094]
第二差值表征了根据投影矩阵计算得到的对象轮廓和利用图像处理方法对步骤s310所获取的图像进行分割而获取的对象轮廓之间的差异。因此,根据一种实施方式,在计算第二差值时,可以先选择在对象模型上的预定个点进行投影,然后根据该投影位置,选择分割得到的轮廓上距离该投影位置最接近的点,即距离f(ps
j
)的最近点参与第二差值的计算,从而可以更快速进行主成分分量的权重值计算。
[0095]
接着,在步骤s350中进行主成分分量的各权重值的迭代计算,以使得第一差值和第二差值之和在一个预定范围之内。
[0096]
如上所述,第一差值和第二差值具有各自的权重γ
i
和η
j
。根据一种实施方式,可以预先设置固定的权重值γ
i
和η
j
,在步骤s350中进行迭代计算时,以第一差值和第二差值的加权和落入预定范围。根据另一种实施方式,权重值γ
i
和η
j
可以改变,例如在迭代的初期,可以将γ
i
设置为1,而η
j
设置为0,以仅仅考虑特征点信息进行迭代计算,从而获取一个具有相对较低准确度的α
i
。随后,逐步减低γ
i
值,并提高η
j
值,将轮廓上的点逐步考虑进来,从而提供越来越准确的α
i
,并最终达到完全收敛为止。
[0097]
具体而言,可以确定每个主成分分量相对应的第一权重值,以使得第一差值在预定范围之内;随后,根据所确定的第一权重更新对象的三维模型,并重新计算投影特征点和投影轮廓;然后再次确定每个主成分分量相对应的第二权重,以使得根据重新计算的投影特征点和投影轮廓所计算的第一差值和第二差值的加权和在另一个预定范围之内。可以把计算得到的第二权重值确定为最终的权重值。
[0098]
应当注意的是,本发明不受限于对第一差值和第二差值进行迭代计算的具体方式,所有可以让第一差值和第二差值之和最小化(即,落入预定范围之内)以确定α
i
的方式都在本发明的保护范围之内。
[0099]
还应当注意的是,在本发明中,可以仅仅计算第一差值和第二差值,并使第一差值或者第二差值中的任一个最小来确定各主成分分量的权重,这样的方式也在本发明的保护范围之内。
[0100]
另外,可选地,当在步骤s320中计算投影矩阵时,如果采用了对二维图像进行图像识别而获取的对象特征点进行投影矩阵的计算,则在步骤s350进行迭代计算时,需要考虑迭代投影矩阵值,因此要将迭代范围扩大到步骤s320。
[0101]
在步骤s350获取了各主成分分量的权重值之后,对象的三维模型也就确定了,接下来在步骤s360中,就可以在所确定的三维模型上确定对象的各三维尺寸。
[0102]
方法300可以用于各种能够以变形模型表征的三维对象。特别地,方法300可以用于具有现有大量数据集的对象上,这样的对象例如包括人脸、人脚和人手等。
[0103]
根据本发明的一种实施方式,可以将方法300应用于人的脚上。因此,在步骤s360中,可以基于步骤s350所获取的人脚对象模型,来计算人脚的各种特征尺寸。
[0104]
图4a和4b示出了各种可以基于人脚三维模型而计算的各种特征尺寸。如图4a和4b
所示,在计算得到脚的三维模型之后,分别在垂直平面(x-y轴定义的平面)和水平平面(y-z轴定义的平面)上进行投影,并可以计算下列特征尺寸:
[0105]
脚长l:脚部最前端到最后端在y轴上的投影距离。
[0106]
脚宽:截取y坐标在l*(0.635-δ)到l*(0.725 δ)之前的所有点(δ一般取0.025),找到x坐标最大和最小的两个点,二者在x轴方向的投影距离为脚宽。
[0107]
脚背高:在y轴0.5l处做处置与xy平面的垂线,与脚背的交点距离地面的距离是脚背高。
[0108]
跖趾围:用一个平面去截取脚模,这个平面通过脚宽找到的两个点并且和xy平面夹角75度,截取脚模得到的围线距离为跖趾围。
[0109]
跗围:用一个平面去截取脚模,这个平面通过两个点且平行于x轴,一个点是y轴上0.41l处,另一个点是在y轴0.55l处做垂直于xy平面的垂线与脚背的交点。
[0110]
根据本发明的方法300,可以在摄像头拍摄的脚部图像的基础上,高准确度地还原出脚的三维模型,从而进一步去获取脚的各种特征尺寸,以方便在线选择时候的鞋,或者进行定制鞋的处理。
[0111]
根据本发明的方案还可以用于各种与脚和鞋相关的领域。根据一种实施方式,在获得用户的脚的三维模型之后,可以根据脚的各种特征尺寸,确定对于用户而言更加合适的鞋。例如,可以事先获取各种鞋的三维尺寸,随后根据脚的特征尺寸来选择对于该用户更加合适的鞋。对于脚还处于生长期的用户,例如婴儿或者小孩而言,根据本发明的方案可以确定用户的脚的特征尺寸,并考虑到脚的成长性来推荐具有合适尺寸的鞋。根据进一步的实施方式,还可以结合健康数据(例如,在对大量用户的脚的尺寸进行分析之后得到)来确定用户当前脚可能存在的问题,并为用户推荐有利于缓解用户脚问题的鞋。
[0112]
这里描述的各种技术可结合硬件或软件,或者它们的组合一起实现。从而,本发明的方法和设备,或者本发明的方法和设备的某些方面或部分可采取嵌入有形媒介,例如可移动硬盘、u盘、软盘、cd-rom或者其它任意机器可读的存储介质中的程序代码(即指令)的形式,其中当程序被载入诸如计算机之类的机器,并被所述机器执行时,所述机器变成实践本发明的设备。
[0113]
在程序代码在可编程计算机上执行的情况下,计算设备一般包括处理器、处理器可读的存储介质(包括易失性和非易失性存储器和/或存储元件),至少一个输入装置,和至少一个输出装置。其中,存储器被配置用于存储程序代码;处理器被配置用于根据该存储器中存储的所述程序代码中的指令,执行本发明的方法。
[0114]
以示例而非限制的方式,可读介质包括可读存储介质和通信介质。可读存储介质存储诸如计算机可读指令、数据结构、程序模块或其它数据等信息。通信介质一般以诸如载波或其它传输机制等已调制数据信号来体现计算机可读指令、数据结构、程序模块或其它数据,并且包括任何信息传递介质。以上的任一种的组合也包括在可读介质的范围之内。
[0115]
在此处所提供的说明书中,算法和显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与本发明的示例一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的实施方式。
[0116]
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下被实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
[0117]
类似地,应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
[0118]
本领域那些技术人员应当理解在本文所公开的示例中的设备的模块或单元或组件可以布置在如该实施例中所描述的设备中,或者可替换地可以定位在与该示例中的设备不同的一个或多个设备中。前述示例中的模块可以组合为一个模块或者此外可以分成多个子模块。
[0119]
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。
[0120]
此外,本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
[0121]
此外,所述实施例中的一些在此被描述成可以由计算机系统的处理器或者由执行所述功能的其它装置实施的方法或方法元素的组合。因此,具有用于实施所述方法或方法元素的必要指令的处理器形成用于实施该方法或方法元素的装置。此外,装置实施例的在此所述的元素是如下装置的例子:该装置用于实施由为了实施该发明的目的的元素所执行的功能。
[0122]
如在此所使用的那样,除非另行规定,使用序数词“第一”、“第二”、“第三”等等来描述普通对象仅仅表示涉及类似对象的不同实例,并且并不意图暗示这样被描述的对象必须具有时间上、空间上、排序方面或者以任意其它方式的给定顺序。
[0123]
尽管根据有限数量的实施例描述了本发明,但是受益于上面的描述,本技术领域内的技术人员明白,在由此描述的本发明的范围内,可以设想其它实施例。此外,应当注意,本说明书中使用的语言主要是为了可读性和教导的目的而选择的,而不是为了解释或者限定本发明的主题而选择的。因此,在不偏离所附权利要求书的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。对于本发明的范围,对本
发明所做的公开是说明性的而非限制性的,本发明的范围由所附权利要求书限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。