1.本发明属于图像合成和翻译领域,尤其涉及到人脸图像的年龄转换方法。
背景技术:
2.随着社会步入数字时代,人们的影视文娱活动逐渐丰富。通过人工智能方法实现人脸图片的年龄转换可以作为视频特效,广泛应用于直播平台,社交媒体中。不少影视作品需要拍摄角色从小到大的过程,而传统的手工年龄转换特效制作开销大耗时长,使用人工智能方法能够大大地降低成本。刑侦中往往遇到犯人或失踪者已经经过数十年未现身的情况,面对此问题,传统方法采用专家人工绘制年龄转换画像的方式,所需时间长且专家人数有限。使用人工智能方法可以有效解决这一问题。人脸图片年龄转换是指输入一张或多张人脸图片,对其中人脸部分进行图像翻译,以实现预测图片中人在过去或在未来的样子的任务。直到深度学习技术被广泛运用以前,人工智能方法往往只能预测成年后很小年龄跨度的人脸图片,并且只集中在人脸的纹理变化上。进入深度学习时代之后,人工智能方法有了长足的进步,实现了更大的年龄转换跨度,人脸形变等效果。但是存在模型训练时间极长,单独为人脸年龄转换设计的训练过程中抽取的特征不够具有代表性,大跨度年龄转换生成图片真实度不高,年龄转换过程中人脸身份、姿态、背景和光照不易保持等问题。因此,现有的人脸图片年龄转换技术有待提升。
技术实现要素:
3.针对现有技术存在的以上问题,本发明旨在提供一种基于梯度对抗攻击和生成对抗模型的人脸图片年龄转换方法,通过使用梯度对抗攻击的方式抽取解码器、判别器、人脸识别和年龄估计模块的先验知识,在不需要额外训练的情况下直接通过迭代生成看起来很真实的人脸年龄转换图片,并确保图片人脸与目标年龄尽可能相近、人脸的表情、姿态和背景保持不变。
4.为实现本发明的目的,本发明所采用的技术方案如下:
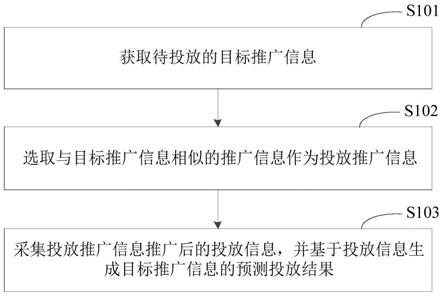
5.一种基于梯度对抗攻击和生成对抗模型的人脸图片年龄转换方法,所述方法包括以下步骤:
6.步骤1:使用人脸对齐方法从在野图片中裁剪出对正的人脸图片;
7.步骤2:包含有判别器、解码器、人脸年龄估计模型、人脸身份识别模型;
8.步骤3:使用解码器隐空间的平均向量初始化或使用更新后的隐空间向量,解码得到生成图片后输入到判别器、人脸年龄估计模型、人脸身份识别模型中取得生成图片与目标年龄的差别、生成图片真实度、生成图片的人脸身份保持度;
9.步骤4:以目标年龄差别、生成图片真实度、人脸身份保持度加权得到优化目标,用梯度下降的方式更新隐空间向量;
10.步骤5:重复步骤3和步骤4,直到达到算法的最大迭代数,最后取得的图片为算法
的输出。
11.作为本发明的一种改进,所述步骤1中,人脸对齐方法为:
12.在野人脸图片包括人的全身,包括很多无关背景,首先使用人脸识别算法取得人脸特征点,使用sdm算法取得人脸106特征点,然后通过一组特征点的连线与水平的角度差来旋转图片,再使用瞳孔连线与水平线的角度差,然后人为规定一个人脸中心,本例使用眉间,按照一定像素长宽,以规定的人脸中心裁剪出人脸图片。本方法具体采用sdm算法取得106 特征点,然后用瞳孔连线与水平线的角度差旋转图片,使得瞳孔连线变得水平,然后使用眉间作为人脸中心,用256
×
256大小从原图裁剪。
13.作为本发明的一种改进,所述步骤2中,包括有生成对抗模型中的判别器,以图片作为输入,输出一维数值,用于表示图片来自生成数据集或真实数据集的可能性,这一判别器用d 表示,主要使用多层卷积神经网络,以及残差连接结构实现,运用其计算的表达式为d(x),若输入图片x接近于虚假的生成图片,那么d(x)尽可能接近于0;若输入图片x接近于真实的图片,那么d(x)尽可能接近于1,本方法使用带有多层卷积神经网络以及残差连接的模型,类似于stylegan2的判别器,输入图片为256
×
256大小的三通道rgb图片;
14.包括有解码器,将隐空间编码作为输入,输出生成的图片,使用g
θ
表示解码器,其输入隐空间编码w,得到输出图片的过程表示为:
15.x
′
=g
θ
(w);
16.本方法中输入为512维隐空间向量,生成256
×
256大小的三通道rgb图片,使用类似于stylegan2的生成器的解码器结构,包含有14层卷积神经网络和8层残差卷积模块,
17.包括有人脸年龄估计模型e
age
,以图片作为输入,以一定形式输出估计的年龄,本例使用年龄的回归值,代表年龄的特殊编码。本方法使用预训练的人脸年龄估计算法dex,以224
×
224大小的三通道彩色图片作为输入,输出101维年龄特征,
18.包括有人脸身份估计模型e
id
,使用人脸识别算法,判断视觉相似性的vgg损失或最小二乘损失。本方法使用预训练的人脸识别算法lightcnn,以112
×
112大小的单色图片作为输入,输出人脸特征向量e
id
(x)。
19.本例使用现成的模型。本方法采用已经在ffhq数据集上训练的stylegan2预训练权值的解码器g
θ
和判别器d,预训练的人脸识别器lightcnn,以及预训练的人脸年龄估计模块dex。
20.作为本发明的一种改进,所述步骤3中,以一种方式初始化隐空间向量。使用从多维高斯分布,以预设的方差σ和均值μ生成一个随机向量,本例使用能够生成高质量图片的一系列隐空间向量的平均,我们以w0代表初始化得到的隐空间向量,我们设定更新用的隐空间向量 w=w0,之后被更新的隐空间向量也用w表示。
21.符合本方法步骤2描述的解码器表示为g
θ
,得到生成图片的过程为:
22.x
′
=g
θ
(w)。
23.作为本发明的一种改进,所述步骤4中,分别将生成的图片输入到判别器d,人脸年龄估计器e
age
,人脸身份估计器e
id
中,输出分别为d(x
′
),e
age
(x
′
),e
id
(x
′
),然后将输入的真实图片x也输入到人脸身份估计器e
id
,人脸年龄估计其中e
age
,得到的输出分别为: e
age
(x),e
id
(x),方法的目标是为了让生成的图片尽可能真实,并且尽可能接近目标年龄特征 c,以及在变换的过程中保持人脸身份、表情、姿态、背景等不变。计算损失函数,并要求最优的w
使损失函数最小化:
[0024][0025]
其中λ
age
和λ
id
代表给年龄目标和年龄无关特征的目标的权重,目标年龄特征c是使用高斯分布生成的,该特征有101维。比如若要求的年龄y=30,那么就以向量中第30维的位置作为高斯分布的期望点,以σ2type equation here.=10为方差,μ=y为数学期望生成高斯分布的概率密度函数p(z),然后将自变量z代入向量维度数目,即第12维的值c
12
=p(12)。
[0026]
本方法要使用梯度下降法更新隐空间向量w,梯度的数学表达式如下:
[0027][0028]
式中的||
·
||2代表二范数,梯度更新的学习率自行设定,设定学习率为α,更新之后的隐空间向量如下表达式:
[0029][0030]
其中w
t 1
和w
t
分别为t 1次迭代和t次迭代的隐空间向量w;
[0031]
除上面的设定方法之外,额外添加视觉相似度损失,如||x
‑
x
′
||2,vgg损失如 ||φ
l
(x)
‑
φ
l
(x
′
)||2,其中φ
l
为vgg神经网络的第l层,一般采用最后一层的特征向量,添加此类损失有助于保持表情,姿态和背景在转换过程中不发生变化。
[0032]
判别器损失项log(1
‑
d(x
′
))在本例中修改为非饱和损失,表达式如下:
[0033]
‑
log(d(x
′
));
[0034]
这有助于提供更好的梯度信息给隐空间向量w。
[0035]
作为本发明的一种改进,所述步骤5中,重复步骤3和步骤4,即可使得生成图片在保持真实度和原有输入图片的人脸身份、表情、姿态、背景等特征的情况下转换人脸的外观年龄,设定最大迭代数为t
max
,每次算法迭代会使得从0开始的迭代数t加一,当迭代数t=t
max
时,算法终止,最后一次得到的生成人脸图片将作为算法输出,算法被表示如下:
[0036][0037]
与其他方法相比,本发明提出的方法有如下有益效果:
[0038]
第一,相较于stylegan2这种无监督,不分类的方法,分类的人脸年龄转换模型在抽取图像特征的时候具有约束,并且其训练过程采用图片翻译的形式,往往需要循环一致性损失和重建损失来监督。而能够重建的图片在数据集中是有限的,限制了采用训练的方
法抽取的特征的普适性和多样性。本发明直接从stylegan2等模型中抽取先验知识,避免了直接训练的方法的偏差。
[0039]
第二,人脸年龄数据集往往呈现长尾分布,幼儿和老年图片会相对较少。基于训练的方法往往需要对数据进行重采样或重加权来降低长尾分布带来的影响,以提升幼儿和老年图片生成的效果。但这一过程往往导致模型忽略包含大量数据的成年人图片类别的有效特征。本发明直接从无分类训练的模型中抽取先验,避免了分类训练因重采样、重加权导致的特征分布问题。
[0040]
第三,训练一个人脸年龄转换模型需要开销相当长的时间,而本发明不需要训练模型。
附图说明
[0041]
图1是本发明一种基于梯度对抗攻击和生成对抗模型的人脸图片年龄转换方法流程图;
[0042]
图2是本发明采用的模型总体结构结构图。
具体实施方式
[0043]
下面结合附图和实施例对本发明的技术方案作进一步的说明。
[0044]
实施例1:参见图1、图2,一种基于梯度对抗攻击和生成对抗模型的人脸图片年龄转换方法,所述方法包括以下步骤:
[0045]
步骤1:使用人脸对齐方法从在野图片中裁剪出对正的人脸图片;
[0046]
步骤2:使用判别器、解码器、人脸年龄估计模型和人脸身份识别模型;
[0047]
步骤3:使用解码器隐空间的平均向量初始化或使用更新后的隐空间向量,解码得到生成图片后输入到判别器、人脸年龄估计模型、人脸身份识别模型中取得生成图片与目标年龄的差别、生成图片真实度、生成图片的人脸身份保持度;
[0048]
步骤4:以目标年龄差别、生成图片真实度、人脸身份保持度加权得到优化目标,用梯度下降的方式更新隐空间向量;
[0049]
步骤5:重复步骤3和步骤4,直到达到算法的最大迭代数,最后取得的图片为算法的输出。
[0050]
所述步骤1中,人脸对齐的方法为:首先以完整图片作为输入,这张图片可能包含有除人脸外的其他内容,列如躯干、图像背景等。本发明首先对完整图片进行人脸对齐,首先使用sdm算法等人脸识别算法检测出图片的106人脸特征点。106特征点包括有人脸五官和轮廓,下巴、眉毛、眼睛的位置。本发明首先根据左右眼瞳孔的位置的连线计算其与水平线的角度,然后使用图像旋转算法,计算旋转矩阵,对原图进行旋转,使得此时瞳孔连线呈水平位置。
[0051]
然后依据人脸左右眉尖的位置,计算其中点作为人脸的中心位置。本发明处理的输入图片大小为256
×
256的三通道rgb图片,步骤1的最后一步需要以人脸中心为裁剪图片中心,以长宽分别256像素进行图像裁剪。得到的图片作为输入x。
[0052]
所述步骤2中,运用了生成对抗模型中的解码器d或称生成器g
θ
,判别器,并且还需要人脸年龄估计模型e
age
和人脸识别模型e
id
。本发明使用在ffhq上训练,无监督,无分类训
练得到的stylegan2的解码器和生成器。stylegan2的训练方式决定了它能够很好抽取数据集中的特征,并且生成极其真实的图片。使用本发明的方法时也可以采用其他的解码器和生成器,但需要同样保证解码器能生成多样而真实的图片,其抽取的数据特征能够正确反映真实数据分布。
[0053]
解码器g
θ
以512维隐空间向量w作为输入,并且在每一层中使用的隐空间向量不同,最大支持14
×
512维的隐空间向量。之所以可支持最多14个,是因为模型中含有14个风格卷积模块。本发明中该解码器被设计为输出256
×
256大小的三通道rgb图片,在运行时设定解码器的截断(truncation)参数为0.7,使得在维持很高的图片多样性的情况下,也能保持图像的真实性。设定通道乘数为1,得到的解码器参数量较大,需占据430mb的空间。本发明中解码器的权值是冻结的,在运行过程中都不会发生改变。
[0054]
判别器d以256
×
256大小的三通道rgb图片作为输入,输出一个数值输出,作为对输入图片是否真实的判断。若输入图片看起来十分真实,那么输出d(x)会较大,否则d(x)会很小。本发明中判别器d的权值是冻结的,在运行过程中不发生更新。
[0055]
本发明选用的人脸年龄估计模型e
age
为dex,它是一个多层卷积神经网络,并有一个全链接头部。该模型以224
×
224大小的三通道rgb图片作为输入,输出一个101维的图像人脸年龄特征。在算法运行过程中其权值也是冻结的,不需要进行更新。
[0056]
本发明选用的人脸识别模型e
id
为lightcnn,同样也是一个多层卷积神经网络。在运行时以112
×
112大小的单色图片作为输入,本例输出倒数第二层的特征向量。我们需要的是其输出的特征向量,代表人脸的身份。同样,其权值在算法运行中是冻结的。
[0057]
所述步骤3中,初始化一个隐空间向量w并输入到解码器中得到生成图片x
′
=g
θ
(w)。本发明中认定解码器能够生成足够多样的人脸图片,这些图片与隐空间一一对应。我们期望的原图片在对应年龄段的输出同样也是一张人脸图片,在满足上面的假设时认为期望得到的图片在隐空间中也存在一个向量w
*
,本发明的目标就是在隐空间中找到或逼近最佳的隐空间向量w
*
。在这个过程中,若解码器具有连续和平滑等性质,那么会大大提高算法成功的可能性,当隐空间发生细微变化时,生成的图片的特征能照某一方向(人脸的眉毛粗细,皮肤光滑程度) 进行细微的变化,就能使用解码器提供的梯度来更新隐空间向量w,使其趋近于w*。
[0058]
需要注意,隐空间的大小相对于真实数据集还是过于庞大,因此空间内能够生成有效图片的区域也比较有限。若初始化的隐空间向量w0处于无效区域,那么其获得的更新梯度将会是无效的,算法将会发散。基于此思路,我们需要以启发式的方法初始化隐空间向量w0。本例提供三种方法初始化隐空间向量。1) 我们从隐空间中用高斯分布采样很多的向量,并逐一生成图片,再人为筛选出其中真实且有效的图片,记录些图片对应的隐空间向量,称为有效隐空间向量集。然后初始化的隐空间特征为有效隐空间向量集的算术平均。2)对生成的图片进行人工分类,再记录不同年龄段图片对应的隐空间向量集,那么就可以以对应年龄段的平均隐空间向量初始化w0。使用这一方法可以有效保证初始向量位于有效隐空间具有大的裕度的位置,并且附加目标年龄段的目标特征。3)使用能够基本通过解码器重建输入图片的初始隐空间向量,这要求使用额外的编码器styleganencoder将原始图片编码到隐空间。
[0059]
所述步骤4中,对隐空间向量w的更新方向进行引导。我们要求生成的目标图片x*
能够在外观年龄上趋近于设定的目标y,并且保持人脸的身份、表情、姿态、背景和光照条件等不发生改变,此外确保图片尽可能真实。为此,本发明提出以下的约束。
[0060]
1.抽取生成图片和原始图片的人脸身份特征:e
id
(x
′
),e
id
(x),要求它们在l2距离 ||e
id
(x
′
)
‑
e
id
(x)||2上尽可能相近。
[0061]
2.抽取生成图片的年龄特征,要求其与目标特征c在l2距离||e
age
(x
′
)
‑
c||2上相近。
[0062]
3.对生成图片的真实性进行判别d(x
′
),要求真实性尽可能高,即
[0063]
log(1
‑
d(x))越低越好。本例中将其修改为使用非饱和损失
‑
log(d(x))。
[0064]
4.使用vgg损失||φ
l
(x)
‑
φ
l
(x
′
)||2或者重建损失||x
‑
x
′
||2确保人脸的表情、姿态、背景和光照的一致性。
[0065]
隐空间向量的优化目标为:
[0066][0067]
其中λ
age
,λ
id
和λ
rec
分别代表年龄约束,身份约束和重建约束的权值。代表上面介绍的任一一种重建损失, 目标年龄特征c是使用高斯分布生成的,该特征有101维。下面举例,若要求的年龄y=30,那么就以向量中第30维的位置作为高斯分布的期望点, 以σ2type equation here.=10为方差,μ=y为数学期望生成高斯分布的概率密度函数p(z),然后将自变量z代入向量维度数目,即第12维的值c
12
=p(12)。本例中λ
age
,λ
id
和λ
rec
分别设定为1.0,1.0和10.0,确保各项损失在同一数量级。图2.展示了本发明所采用的全部模型及其运算的流程。
[0068]
本方法要使用梯度下降法更新隐空间向量w,梯度的数学表达式如下:
[0069][0070]
式中的||
·
||2代表二范数,梯度更新的学习率自行设定,设定学习率为α,更新之后的隐空间向量如下表达式:
[0071][0072]
其中w
t 1
和w
t
分别为t 1次迭代和t次迭代的隐空间向量w;
[0073]
除上面的设定方法之外,额外添加视觉相似度损失,如||x
‑
x
′
||2,vgg损失如 ||φ
l
(x)
‑
φ
l
(x
′
)||2,其中φ
l
为vgg神经网络的第l层,一般采用最后一层的特征向量,添加此类损失有助于保持表情,姿态和背景在转换过程中不发生变化。
[0074]
本例中判别器损失项log(1
‑
d(x
′
)被修改为非饱和损失,表达式如下:
[0075]
‑
log(d(x
′
));
[0076]
这有助于提供更好的梯度信息给隐空间向量w。
[0077]
所述步骤5中,重复迭代步骤3和步骤4,迭代结束判断条件有两个。1)使用迭代数作为算法结束的依据2)使用人脸年龄估计模块的结果作为依据,将抽取的生成图片年龄特征 e
age
(x
′
)通过分类函数映射到年龄值y
′
=f(e
age
(x
′
)),若该年龄值与目标年龄值的差异小于规定值时(即|y
′‑
y|<σ),结束算法。在迭代过程中,隐空间向量会朝着w*的方向进行更新,与此同时生成图片也会朝着x*进行变化。
[0078]
即可使得生成图片在保持真实度和原有输入图片的人脸身份、表情、姿态、背景等
特征的情况下转换人脸的外观年龄,达到迭代结束条件后,最后一次得到的生成人脸图片 g
θ
(w
tmax
)将作为算法输出,算法被表示如下:
[0079][0080][0081]
需要说明的是上述实施例仅仅是本发明的较佳实施例,并没有用来限定本发明的保护范围,在上述技术方案的基础上做出的等同替换或者替代均属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。