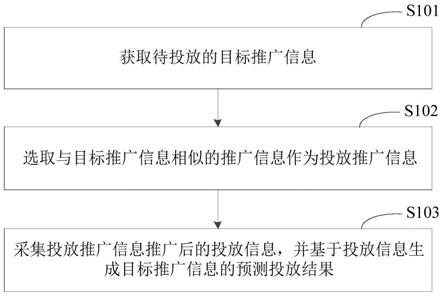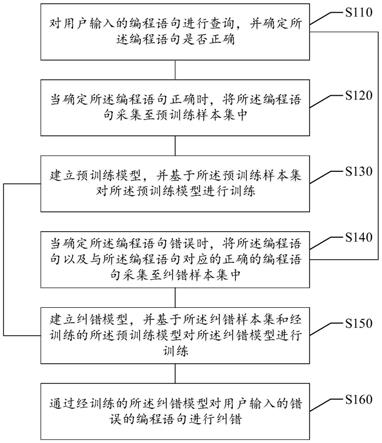
1.本发明涉及驾驶员注意力分析和建模技术,具体涉及一种基于驾驶员眼动扫视的城市环境下安全驾驶推荐方法。
背景技术:
2.近几十年来,人类视觉注意的计算建模受到了广泛的关注。在当代先进的工业应用中,它已经被证明能够非常类似地预测人类的视觉注意力。然而,基于人类视觉注意的眼睛扫视位置(visual saccades)和计算视觉注意模型(saccades predicted by computational visual attention model)预测的眼睛扫视位置哪一种方案更可靠,是否切实有助于实际驾驶,一直存在争议。
3.考虑到驾驶相关注意力模型的生物灵感可以从复杂驾驶条件下的熟练驾驶员那里获得,在复杂驾驶条件下,驾驶员的注意力通过眼跳交替注视以安全驾驶,从而不断地指向各种显著和信息丰富的视觉刺激,本文提出了一种在拥挤的道路环境下,特别是当驾驶员的视力经常受到视觉拥挤的影响时,提高驾驶安全性的眼跳推荐策略。
技术实现要素:
4.有鉴于此,本发明提供一种基于驾驶员眼动扫视的城市环境下安全驾驶推荐方法,以解决上述技术问题。
5.为实现上述目的,本发明提供如下技术方案:
6.一种基于驾驶员眼动扫视的城市环境下安全驾驶推荐方法,包括以下步骤:
7.步骤1:原始驾驶视频的采集与预处理,对虚拟和现实的城市驾驶场景进行原始驾驶视频采集,并对原始驾驶视频进行预处理;
8.步骤2:获得受试者和模型的眼动扫视轨迹、注视点,召集有驾驶经验的受试者参与眼动实验,获得受试者共性的眼动扫视轨迹,通过眼动扫视设备获得受试者共性的眼动扫视轨迹;选择一个注意力模型预测预处理后驾驶视频的注视点和相应的扫视轨迹;
9.步骤3:初步选择扫视轨迹方案,通过比较受试者和模型的注视点和扫视的差异性,初步选择扫视轨迹的最优方案;
10.步骤4:提取预处理后原始驾驶视频中与眼动扫视有关的关键特征;
11.步骤5:构建神经网络模型,选择最合理注视点,构建神经网络模型,通过参考整体安全驾驶方案,选择最合理的注视点,满足安全驾驶的要求;
12.步骤6:优化步骤5的注视点,确定最终推荐安全驾驶方案,一步优化步骤5选定的注视点,提高驾驶舒适性,通过主观评价方案,让受试者参与,最终促进安全驾驶的目标标。
13.进一步地,所述对虚拟和现实的城市驾驶场景进行原始驾驶视频采集包括:一半原始驾驶视频在野外条件下拍摄,另一半则是在虚拟场景下拍摄,原始驾驶视频采用安装在汽车挡风玻璃上的数码摄像机,另外使用高清摄像机拍摄,每秒30帧。
14.更进一步地,所述安装在汽车挡风玻璃上的数码摄像机记录从真实场景和虚拟场
景下10种高速道路和城市道路的驾驶环境中抽取6个高清晰度彩色视频片段。
15.更进一步地,所述对原始驾驶视频的预处理包括对原始驾驶视频进行颜色阈值化处理和高斯滤波处理。
16.更进一步地,所述受试者至少包括35名,所有受试者都有至少一年的驾驶经验或有10000公里及以上的驾驶记录,所有受试者视力正常或矫正至正常,色觉正常。
17.进一步地,步骤2具体包括:步骤2具体包括:所述注意力模型采用经典的注意力模型,通过采用经典的注意力模型分析预处理后的原始驾驶视频得到受试者的注视点和模型预测的注视点的2种不同的眼动扫视方案。
18.进一步地,步骤3包括4种与眼动扫视有关的关键特征,所述关键特征包括:通过分析驾驶专家指定相邻两帧之间的显著标识物的差异性,相邻两帧之间受试者眼动扫视点和模型眼动扫视点的距离差,同一帧之间两种眼动扫视方案的距离差和正逆向视频之间的受试者扫视点和模型扫视点的距离差,以及最优显著标识物和次优显著标识物的差异性的四种特征。
19.进一步地,所述关键特征提取方式如下:
20.步骤4.1:通过眼动扫视仪和模型预测获得受试者和模型的眼动扫视数据;
21.步骤4.2:采用小波分析和近似熵的算法进行眼动扫视的提取。
22.进一步地,步骤5具体包括:根据关键特征选择正向传播网络训练、预判和验证剩余预处理原始驾驶视频中的扫视点。
23.进一步地,步骤6具体包括:在得到步骤5推荐点方案后,根据视觉舒适性和安全性选择进一步优化注视点,让受试者根据推荐的注视点来进行驾驶,然后参与评判打分。
24.从上述的技术方案可以看出,本发明的优点是:
25.与现有技术相比,在拥挤的道路环境下,尤其是当驾驶员的视力经常受到视觉拥挤的影响时,本发明通过分析受试者和模型预测的驾驶者的与眼动扫视有关的关键特征、扫视轨迹,选择更加合理、更优方案,达到安全驾驶,为未来实现完全自动驾驶提供参考。
26.除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。
附图说明
27.在附图中:
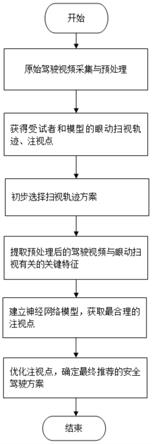
28.图1为本发明的一种基于驾驶员眼动扫视的城市环境下安全驾驶推荐方法的流程示意图。
29.图2为本发明实施例的使用安装在迷你suv(现代ix25)上的网络摄像头拍摄的城市驾驶场景。
30.图3为本发明实施例的使用安装在迷你suv(现代ix25)上的网络摄像头拍摄的的高速公路场景。
31.图4为本发明实施例的在visual studio 2019平台上从ue4(虚幻引擎4)拍摄的来自城市道路的驾驶场景。
32.图5为本发明实施例的在visual studio 2019平台上从ue4(虚幻引擎4)拍摄的来自高速道路的驾驶场景。
33.图6为本发明实施例应用t
‑
sne后,一个驾驶视频剪辑的静态的眼动扫视散点图。
34.图7为本发明实施例应用t
‑
sne后,一个驾驶视频剪辑的动态的眼动扫视散点图。
35.图8为本发明实施例在高速环境道路驾驶任务下的眼动扫视聚类图。
36.图9为本发明实施例在城市环境道路的驾驶任务下的眼动扫视聚类图。
具体实施方式
37.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
38.参见图1至图9,本发明公开的一种基于驾驶员眼动扫视的城市环境下安全驾驶推荐方法,包括以下步骤:
39.步骤1:原始驾驶视频采集与预处理,
40.召集有驾驶经验的受试者参与眼动实验,对虚拟和现实的城市驾驶场景进行原始驾驶视频采集,并原始驾驶视频进行预处理;
41.步骤2:获得受试者和模型的眼动扫视轨迹、注视点,
42.通过眼动扫视设备获得受试者共性的眼动扫视轨迹;选择一个具有代表性的注意力模型预测预处理后原始驾驶视频的注视点和相应的扫视轨迹;
43.步骤3:初步选择扫视轨迹方案,
44.通过比较受试者和模型的注视点和扫视的差异性,初步选择扫视轨迹的最优方案;
45.步骤4:提取预处理后原始驾驶视频中与扫视眼动有关的关键特征;
46.步骤5:构建神经网络模型,选择最合理注视点,
47.构建神经网络模型,通过参考整体安全驾驶方案,选择最合理的注视点;
48.步骤6:优化步骤5的注视点,确定最终安全驾驶方案,
49.优化步骤5选定的注视点,提高驾驶舒适性,通过主观评价方案,让受试者参与,最终促进安全驾驶的目标。
50.具体地,本发明实施过程中采用一辆小型客车(7座以下)以及一台高清摄像机来录取外界驾驶场景。
51.s1:尽可能收集全面而丰富的虚拟和现实驾驶场景进行采集与预处理,比如高速公路,城市道路、高速道路以及雨天雾天等自然场景;
52.s2:通过眼动仪设备获得受试者的眼动扫视数据,同时通过注意力模型获得预测的眼动扫视数据;
53.s3:通过分析受试者的眼动扫视和预测眼动扫视的差异;
54.s4:对预处理后的原始驾驶视频进行多维关键特征抽取;
55.s5:训练神经网络,然后去判断在不同驾驶场景下的注视点,参考驾驶专家的意见(ground truth)而提出推荐安全驾驶的方案,验证其合理性;
56.s6:优化注视点的选择,提高舒适性来进一步提升安全性,最终确定并推荐安全驾驶方案。
57.如图2至图5所示,采集数据时候实验需要配置一台前景视野比较宽阔的小型客车(7座以下)。同时,原始驾驶视频数据库要尽可能收集驾驶者在现实生活中遇到的所有驾驶任务,比如:虚拟和现实的城市驾驶场景包括复杂、简单的高速公路、城市道路的驾驶场景,并且强调不同的天气下状况。所有的原始驾驶视频需要同时考虑左舵(如英国或者澳大利亚)和右舵(如中国或者美国)的场景。一半的原始驾驶视频是在恶劣的天气条件下拍摄的,即下雨、多雾、下雪、大风和夜晚等环境,另一半则是在晴天拍摄的。从10种不同的驾驶环境中抽取6个高清晰度彩色视频片段,用安装在汽车挡风玻璃上的数码摄像机进行记录。另外使用松下hx
‑
dc3高清摄像机拍摄的,其分辨率为640
×
480像素,每秒30帧。高清摄像机被固定在三脚架上以确保良好的图像质量。。
58.具体地,图2是安装在迷你suv上的网络摄像头采集采集的城市驾驶图片信息,图3是安装在迷你suv上的网络摄像头采集的高速公路图片信息,图4是虚拟平台上ue4拍摄的城市道路的驾驶场景,图5是虚拟平台上ue4拍摄的高速道路的驾驶场景。采集了不同场景下的驾驶图片,以确保采集驾驶图片的广泛性。
59.需要至少35名受试者,年龄在21
‑
42岁之间,平均32.4
±
0.42岁(平均值
±
扫描电镜)的成年人(7名女性,28名男性)自愿参加本研究。所有参与者都有至少一年的驾驶经验或有10000公里及以上的驾驶记录。所有受试者视力正常或矫正至正常,色觉正常。同时,采用经典的注意力模型分析以上原始驾驶视频得到2种不同的方案,即受试者注视点和模型预测的注视点。。
60.原始驾驶视频的预处理包括对原始驾驶视频进行颜色阈值化处理和高斯滤波处理。
61.具体地,采集受试者眼动扫视的设备为眼动扫视仪,该眼动扫视仪采用善睐眼动平台2.0下的眼动仪。
62.注意力模型采用经典注意力模型,通过采用经典注意力模型分析预处理后的原始驾驶视频得到受试者注视点和模型预测的注视点。
63.通过分析和抽取四种关键的眼动扫视特征,即(1)通过分析驾驶专家指定相邻两帧之间的显著标识物的差异,(2)相邻两帧之间受试者眼动扫视点和模型眼动扫视点的距离差,(3)同一帧之间两种眼动扫视方案的距离差和正逆向视频之间的受试者扫视点和模型扫视点的距离差,(4)以及最优显著标识物和次优显著标识物的差异性的四种特征。
64.具体地,与眼动扫视有关的关键特征提取方式如下:
65.步骤a:通过眼动扫视仪获得受试者的眼动扫视数据;
66.步骤b:采用小波分析和近似熵的算法进行与眼动扫视有关的的关键特征提取。选择正向传播网络训练、预判和验证剩余预处理后的驾驶视频中的扫视点。虚拟和真实驾驶场景下注视点数据高维度分类的可视化效果如图6
‑
7所示。。
67.具体地,如图6所示,本实施例应用t
‑
sne后采集驾驶视频剪辑的眼动扫视散点图。其中:蓝色(1)表示其他静态视觉刺激上的眼动扫视散点,红色(2)表示交通信号灯上的眼动扫视散点,绿色(3)表示交通标志上的眼动扫视散点。如图7所示,本实施例应用用t
‑
sne后采集的驾驶视频的又一眼动扫视散点图。绿色(4)表示行人动态刺激上的眼动扫视散点,(5)蓝色表示其他动态视觉刺激上的眼动扫视散点,(6)红色表示运动车辆视觉刺激上的眼动扫视散点。通过采集静态和动态眼动扫视散点图,为安全驾驶方案的选择提供更准确的
依据。
68.得到注视点的方案后,根据视觉舒适性选择进一步优化注视点,受试者根据注视点来驾驶,并进行评判打分,进而最终确定推荐安全驾驶方案。如图8至图9所示的在不同环境下的眼动扫视聚类图。图像8至图9的最右表示了在采用视觉安全方位和推荐方案后的眼动扫视聚类图。
69.具体地,如图8所示,在高速环境道路驾驶任务下,红圈圆形区域(7)表示新手驾驶员的眼动扫视聚类;绿色圆形区域(8)表示在视觉安全范围内的眼动扫视聚类;黑色圆形区域(9)表示在同时采用视觉安全方位和推荐策略后的眼动扫视聚类。如图9所示,在城市环境道路任务下,红色圆形区域(10)新手驾驶员的眼动扫视聚类;绿色圆形区域(11)在视觉安全范围内的眼动扫视聚类;黑色圆形区域(12)表示在同时采用视觉安全方位和推荐策略后的眼动扫视聚类。通过对不同环境下新手驾驶员、视觉安全范围和两者综合评判打分,最终确定推荐眼动扫视方案。
70.首先采集原始驾驶视频,采用注意力模型对原始驾驶视频中注视点进行定位。其次,通过眼动扫视仪测量被试对推荐的扫视,分析了不同驾驶条件下模型预测的眼动扫视轨迹和受试者扫视轨迹之间的时延,模型预测扫视轨迹与受试者受控之间的时延。视觉安全距离通过总延时来测量好,进而确定初步方案。再通过在原始驾驶视频上提取眼动扫视的四个关键特征,对注视点进行优化,确定最终推荐的安全驾驶方案,能够为未来的自主驾驶提供合理的推荐。
71.以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。