1.本发明涉及驾驶人状态识别技术领域,具体涉及一种基于图像区域定位机制的驾驶人注意力分散检测方法。
背景技术:
2.随着科技的发展,智能手机、平板电脑和车辆信息系统等智能电子设备使得驾驶人注意力分散的概率大大提升,极易产生安全隐患引发交通事故,危害生命与财产安全。据统计,每年有近125万人死于交通事故。近五分之一的事故是由驾驶人注意力分散造成的。随着人工智能技术的进步,自动驾驶技术得到了迅速的发展。然而,目前的有条件自主驾驶系统仍然需要准备好及时接管的驾驶员。美国国家交通安全委员会统计,2018到2019年间,uber自动驾驶测试汽车在18个月内发生37起车祸。因此,设计精确有效的驾驶员分心行为检测系统对提高交通安全具有重要意义。
3.驾驶员注意力分散检测方法可分为以下三类:基于驾驶人生理信息、驾驶操作信息和视觉信息。当驾驶员的精神状态发生变化时,其生理信号也发生改变,然而大多数生理采集传感器需要穿戴到驾驶人身体相应位置,影响驾驶体验。基于操作行为的驾驶人状态识别方法主要利用驾驶人对方向盘、油门和制动踏板获取操作信息,分析其在不同状态下的驾驶行为,推测其是否处于危险驾驶状态。但是该方法的识别精度往往受驾驶人的操作习惯、技能和交通路况等因素的影响。基于视觉的检测方法能够非侵入式地提取驾驶员的视觉图像信息,并且不受外部干扰的影响。因此,视觉特征是驾驶员注意力分散检测方法中应用最广泛的信息。基于视觉的检测方法可分为两类:第一种方法直接对原始图像进行分类来检测驾驶员的状态和行为,这种方法除了图像中的驾驶员外,还经常受到图像中其他因素的干扰;第二种方法利用目标检测或图像分割模型,从驾驶员图像中提取手、头、上身等关键区域或特征,然后将提取的信息输入到识别模型中,得到检测结果,然而这些区域或特征的定位往往受到算法精度的限制,常被误检。
技术实现要素:
4.本发明为了克服以上技术的不足,提供了一种基于图像区域定位机制的驾驶人注意力分散检测方法,在不增加模型复杂度的前提下解决了基于图像信息的驾驶人行为检测方法中关键位置和特征的自动提取问题,提升模型的检测精度。
5.本发明克服其技术问题所采用的技术方案是:一种基于图像区域定位机制的驾驶人注意力分散检测方法,包括如下步骤:a)采集驾驶人不同行为的视觉图像,根据每张视觉图像中驾驶人的不同行为状态,通过自动定位和手动调节的方式确定不同行为状态中需要注意的关键区域;b)利用高斯模型建立驾驶人的视觉图像中关键区域的概率热图,构建基于区域定位的驾驶人行为检测数据集;c)建立神经网络模型,构建类激活映射和关键区域概率热图驱动的代价函数,利
用代价函数训练神经网络,得到优化后的神经网络模型;d)在车内安装摄像头,获取驾驶人侧部的实时图像,将图像输入到优化后的神经网络模型中,提取模型输出概率,得到驾驶人的行为状态。
6.进一步的,步骤a)中在车内安装摄像头,通过摄像头采集驾驶人不同行为的视频,将视频逐帧转换为视觉图像并保存得到样本图像。
7.进一步的,步骤a)中驾驶人的行为状态分别定义为:正常驾驶状态、使用智能手机或平板电脑状态、打电话状态、与副驾驶交谈状态、喝水状态及操作中控电子设备状态;驾驶人处于正常驾驶状态时,需要注意的关键区域位于视觉图像中驾驶人的手部和上臂;驾驶人处于使用智能手机或平板电脑状态时,需要注意的关键区域位于视觉图像中驾驶人手部的手机或平板电脑;驾驶人处于打电话状态时,需要注意的关键区域位于视觉图像中驾驶人的嘴部和手机位置;驾驶人处于与副驾驶交谈状态时,需要注意的关键区域位于视觉图像中驾驶人的嘴部和脸部;驾驶人处于喝水状态时,需要注意的关键区域位于视觉图像中驾驶人的手执的容器;驾驶人处于操作中控电子设备状态时,需要注意的关键区域位于视觉图像中驾驶人的手部和中控设备。
8.进一步的,步骤a)的步骤包括:a
‑
1)在样本图像中找出驾驶人在执行不同行为过程中肢体运动的区域,确立驾驶人图像中基于不同行为状态的关键区域;a
‑
2)基于确立的关键区域,通过骨骼点定位方法自动获取样本图像中驾驶人的上臂骨骼点和头部骨骼点的位置信息,基于上臂骨骼点和头部骨骼点绘制矩形框,骨骼点位于矩形框的中心位置,得到图像的重点区域初始位置;a
‑
3)根据矩形框的位置和大小,手动修正得到图像最终的关键区域。
9.进一步的,步骤b)包括如下步骤:b
‑
1)基于关键区域,通过公式建立二维高斯模型,式中为归一化因子,为协方差矩阵,为转置,为二维高斯模型的变量,为驾驶人行为图像中的关键位置,,为关键区域的横坐标,为关键区域的纵坐标,为中最大值,为中最小值,为中最大值,为中最小值;b
‑
2)将二维高斯模型转换为二维图像,得到驾驶人的视觉图像中关键区域的概率热图;b
‑
3)遍历基于区域定位的驾驶人行为检测数据集中所有的图像样本,重复执行步骤b
‑
1)至b
‑
2),将所有的驾驶人的视觉图像中关键区域的概率热图进行保存,得到基于区域定位的驾驶人行为检测数据集。
10.进一步的,步骤c)包括如下步骤:c
‑
1)建立resnext神经网络模型,在神经网络顶层采用全局平均池化层;c
‑
2)在全局池化层顶层建立softmax分类器输出驾驶人行为预测概率值;c
‑
3)通过公式计算神经网络顶层输出的每个驾驶人行为状态
类别的类激活函数,为类的热图,为顶层神经元个数,为顶层权值参数,为全局均值池化层前一层的映射值;c
‑
4)提取神经网络模型的驾驶人行为预测概率值和类激活映射,通过公式计算得到区域增强优化函数,式中,为非线性变换函数,为神经网络第类行为状态类别的类激活映射,为与真实的行为状态类别相同类的第类激活映射,为与真实的行为类别相同的类,为系数,矩阵哈达玛积,为预定义的第类激活映射;c
‑
5)通过公式计算代价函数,为基于驾驶人状态值的代价函数,,为系数,为resnext神经网络模型的输出值,为标定值;c
‑
6)通过代价函数训练resnext神经网络模型直至收敛,通过交叉验证确立模型的超参数。
11.进一步的,步骤d)中在驾驶人右上方车顶位置安装摄像头。
12.进一步的,步骤d)包括如下步骤:d
‑
1)读取c
‑
6)中训练好的resnext神经网络模型作为检测模型;d
‑
2)将通过摄像头获取的驾驶人每一帧图像输入检测模型中;d
‑
3)在resnext神经网络模型顶层的softmax分类器中获取预测概率值,识别驾驶人当前的行为状态。
13.本发明的有益效果是:通过手动标定的方法获取图像中驾驶人不同行为状态下需要关注的区域,将该区域与神经网络类激活映射结合,建立基于区域增强驱动的模型优化函数,通过该优化函数训练神经网络使得检测模型在检测过程中能够根据驾驶人不同行为特点自动获取驾驶人图像中的关键区域,解决了基于视觉特征的检测方法中关键特征和位置的自动提取问题,提升模型的识别精度。
附图说明
14.图1为本发明的方法流程图;图2为本发明的具体实施的流程图。
具体实施方式
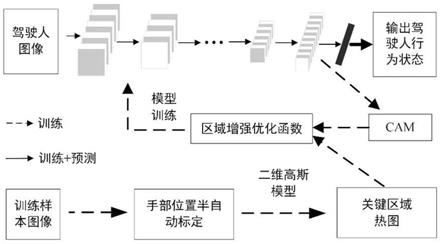
15.下面结合附图1、附图2对本发明做进一步说明。
16.如附图所示,一种基于图像区域定位机制的驾驶人注意力分散检测方法,包括如下步骤:a)采集驾驶人不同行为的视觉图像,根据每张视觉图像中驾驶人的不同行为状态,通过自动定位和手动调节的方式确定不同行为状态中需要注意的关键区域。
17.b)利用高斯模型建立驾驶人的视觉图像中关键区域的概率热图,构建基于区域定位的驾驶人行为检测数据集。
18.c)建立神经网络模型,构建类激活映射和关键区域概率热图驱动的代价函数,利用代价函数训练神经网络,得到优化后的神经网络模型。
19.d)在车内安装摄像头,获取驾驶人侧部的实时图像,将图像输入到优化后的神经网络模型中,提取模型输出概率,得到驾驶人的行为状态。
20.如附图2所示,通过手动标定的方法获取图像中驾驶人不同行为状态下需要关注的区域,将该区域与神经网络类激活映射结合,建立基于区域增强驱动的模型优化函数,通过该优化函数训练神经网络使得检测模型在检测过程中能够根据驾驶人不同行为特点自动获取驾驶人图像中的关键区域,解决了基于视觉特征的检测方法中关键特征和位置的自动提取问题,提升模型的识别精度。
21.具体的,步骤a)中在车内安装摄像头,通过摄像头采集驾驶人不同行为的视频,将视频逐帧转换为视觉图像并保存得到样本图像。
22.具体的,步骤a)中驾驶人的行为状态分别定义为:正常驾驶状态、使用智能手机或平板电脑状态、打电话状态、与副驾驶交谈状态、喝水状态及操作中控电子设备状态;驾驶人处于正常驾驶状态时,需要注意的关键区域位于视觉图像中驾驶人的手部和上臂;驾驶人处于使用智能手机或平板电脑状态时,需要注意的关键区域位于视觉图像中驾驶人手部的手机或平板电脑;驾驶人处于打电话状态时,需要注意的关键区域位于视觉图像中驾驶人的嘴部和手机位置;驾驶人处于与副驾驶交谈状态时,需要注意的关键区域位于视觉图像中驾驶人的嘴部和脸部;驾驶人处于喝水状态时,需要注意的关键区域位于视觉图像中驾驶人的手执的容器;驾驶人处于操作中控电子设备状态时,需要注意的关键区域位于视觉图像中驾驶人的手部和中控设备。
23.具体的,步骤a)的步骤为下所示:a
‑
1)在样本图像中找出驾驶人在执行不同行为过程中肢体运动的区域,确立驾驶人图像中基于不同行为状态的关键区域。
24.a
‑
2)基于确立的关键区域,通过骨骼点定位方法自动获取样本图像中驾驶人的上臂骨骼点和头部骨骼点的位置信息,基于上臂骨骼点和头部骨骼点绘制矩形框,骨骼点位于矩形框的中心位置,得到图像的重点区域初始位置。设图像的尺寸为h
í
b,初始矩形框的尺寸设置如下:正常驾驶图像中的矩形框高为h/5,宽为b/4;驾驶人处于使用智能手机或平板电脑图像中的矩形框高为h/4,宽为b/5;驾驶人打电话图像中的矩形框高为h/4,宽为b/5;驾驶人于与副驾驶交谈图像中的矩形框高为h/3,宽为b/5;驾驶人于喝水图像中的矩形框高为h/4,宽为b/5;驾驶操作中控电子设备图像中的矩形框高为h/2,宽为b/5。
25.a
‑
3)根据矩形框的位置和大小,手动修正得到图像最终包含关键区域的矩形框。优选的,最终修正的矩形框在关键区域中占比大于等于90%且矩形框小于等于样本图像的1/2。基于以上原则,手动修正后的最终矩形框的尺寸范围如下:正常驾驶图像中的矩形框高的范围为:h/9 ~ h/7,宽的范围为b/6 ~ b/3;驾驶人处于使用智能手机或平板电脑图像中的矩形框高的范围为:h/6 ~ h/2,宽的范围为b/6 ~ b/3;驾驶人打电话图像中的矩形框高的范围为:h/6 ~ h/4,宽的范围为b/8 ~ b/6;驾驶人于与副驾驶交谈图像中的矩形框高的范围为:h/4 ~ h/3,宽的范围为b/6 ~ b/5;驾驶人于喝水图像中的矩形框高高的范围为:h/7 ~ h/3,宽的范围为b/8 ~ b/5;驾驶操作中控电子设备图像中的矩形框高的范围为:h/3 ~ h/2,宽的范围为b/6 ~ b/4。
26.具体的,步骤b)包括如下步骤:b
‑
1)基于关键区域,通过公式建立二维高斯模型,式中为归一化因子,为协方差矩阵,为转置,为二维高斯模型的变量,为驾驶人行为图像中的关键位置,,为关键区域的横坐标,为关键区域的纵坐标,为中最大值,为中最小值,为中最大值,为中最小值。
27.b
‑
2)将二维高斯模型转换为二维图像,得到驾驶人的视觉图像中关键区域的概率热图。
28.b
‑
3)遍历基于区域定位的驾驶人行为检测数据集中所有的图像样本,重复执行步骤b
‑
1)至b
‑
2),将所有的驾驶人的视觉图像中关键区域的概率热图进行保存,得到基于区域定位的驾驶人行为检测数据集。
29.具体的,步骤c)包括如下步骤:c
‑
1)建立网络层数为50层的resnext神经网络模型,在神经网络顶层采用全局平均池化层。
30.c
‑
2)在全局池化层顶层建立softmax分类器输出驾驶人行为预测概率值。
31.c
‑
3)通过公式计算神经网络顶层输出的每个驾驶人行为状态类别的类激活函数,为类的热图,为顶层神经元个数,为顶层权值参数,为全局均值池化层前一层的映射值。
32.c
‑
4)提取神经网络模型的驾驶人行为预测概率值和类激活映射,通过公式计算得到区域增强优化函数,式中,为非线性变换函数,为神经网络第类行为状态类别的类激活映射,为与真实的行为状态类别相同类的第类激活映射,为与真实的行为类别相同的类,为系数,矩阵哈达玛积,为预定义的第类激活映射。
33.c
‑
5)通过公式计算代价函数,为基于驾驶人状态值的代价函数,传统的resnext网络用的代价函数为,,为系数,为resnext神经网络模型的输出值,为标定值。
34.c
‑
6)通过代价函数训练resnext神经网络模型直至收敛,通过交叉验证确立模型的超参数。最后确定的超参数主要有:神经网络训练学习率,批量训练样本数(batch size)、损失函数中的系数、批样本数量,动量优化器的动量参数β。
35.优选的,在本专利中神经网络训练学习率r = 0.001,批量训练样本数:batchsize=32、损失函数中的系数 =0.3,动量优化器的动量参数β=0.9。
36.优选的,步骤d)中在驾驶人右上方车顶位置安装摄像头。
37.具体的,步骤d)包括如下步骤:d
‑
1)读取c
‑
6)中训练好的resnext神经网络模型作为检测模型。
38.d
‑
2)将通过摄像头获取的驾驶人每一帧图像输入检测模型中。
39.d
‑
3)在resnext神经网络模型顶层的softmax分类器中获取预测概率值,识别驾驶人当前的行为状态。
40.为了验证本专利的基于图像区域定位机制的驾驶人注意力分散检测方法提升了检测精度,通过实车实验构建了驾驶人行为数据集,该数据集包含了正常驾驶状态、使用智能手机或平板电脑状态、打电话状态、与副驾驶交谈状态、喝水状态及操作中控电子设备状态这6种行为的驾驶人图像共12688张,其中驾驶人40名,40名驾驶人中女性10名,男性30名。如果将该数据集输入传统的训练方法训练的resnext模型,则以50层的resnext模型为例,模型识别精度仅为89.75%。如果将数据集输入本发明所训练的resnext模型中,则以50层的resnext模型为例,模型识别精度能够达到95.59%。
41.为了验证本专利中基于图像区域定位机制的驾驶人注意力分散检测方法精度,通过实车实验构建了驾驶人行为数据集,该数据集包含了正常驾驶状态、使用智能手机或平板电脑状态、打电话状态、与副驾驶交谈状态、喝水状态及操作中控电子设备状态这6种行为的驾驶人图像共12688张,其中驾驶人40名,40名驾驶人中女性10名,男性30名。实验以50层的resnext模型为例,依托该数据集进行训练和验证,实验结果如表1所示,表1中c0
‑
c5分别表示正常驾驶状态、使用智能手机或平板电脑状态、打电话状态、与副驾驶交谈状态、喝水状态及操作中控电子设备状态这6种行为。通过实验结果可以看出相对于传统的训练方法,通过本专利提供的训练方法能够有效提升resnext模型的识别精度。
42.表1最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。