1.本发明涉及一种面向基层治理的事件自动分拨方法。
背景技术:
2.当前,政务大数据分析多聚焦于基础类数据,对于业务类数据的研究与应用相对较少。现有的应用主要关注各类事件数据的统计和展示,很少将业务数据资源转换为决策工具指导社会治理工作。随着社会治理中部门协调合作的逐渐深入,社会网格化程度的逐渐提升,在处理社会事务过程中会产生关于网格事件的大量数据,这为基于事件的社会治理提供了丰富的数据资源。网格化管理过程中累积的事件数据是一类重要业务数据,但只是简单地用于事务处理流转和热点事件统计,并没有充分发挥其潜在应用价值。此外,基层社会治理需要的数据分散在各个部门,由于缺乏一个统一的参照物,各类数据无法有效关联和综合聚类,为城市管理和社会治理带来了诸多不便。
3.因此,需要将地址和空间位置作为数据融合聚类的枢纽,并在此基础上深度发掘基层治理网格化管理中事件数据背后的价值,使其推动政府管理理念和社会治理模式创新。
技术实现要素:
4.本发明的目的是提供一种面向基层治理的事件自动分拨方法,该方法提高了事件派发效率,降低了事件派单的错误率,提升了基层对事件的处理质量。
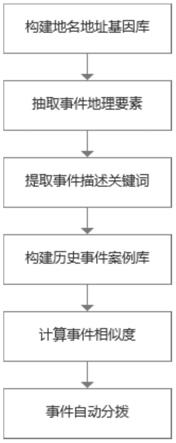
5.为了实现上述目的,本发明提供了一种面向基层治理的事件自动分拨方法,包括:
6.步骤1、构建地名地址基因库;
7.步骤2、抽取事件地理要素;
8.步骤3、提取事件描述关键词;
9.步骤4、构建历史事件案例库;
10.步骤5、计算事件相似度;
11.步骤6、事件自动分拨。
12.优选地,在步骤1中,基于统一的标准地址库构建地名地址基因库,使用自定义三元组表示地址基因,并构建树集合以表征地址基因之间的层次关系。
13.优选地,步骤1包括:
14.步骤1a、利用统计学特征确定标准地址库中地址的落差点,通过递增切分的方法对递增的短语在整个地址库中的数量进行统计;地址元素的使用频次会随地址描述逐渐精确而逐渐降低,当待判断短语后缀超过落差点后,对应的短语在整个地址库中出现的数量将发生明显下降,据此划分出落差点集合m;
15.步骤1b、按照地址构成方式的规则设计决策树,然后根据决策树对每一个落差点m
i
∈m是否构成后缀词或后缀点做出判断,依据判定成功的后缀点进行分词,并对两个后缀点之间的地址要素加以记录;
16.步骤1c、经过分词后,标准化的地址描述所包含的地址要素被划分为专有地址部分与通配地址部分,同时获得一个包含专有地址名词基因的词表wordlist;针对专有地址部分,基于标准地址自身的前后文关系,结合地址信息本身所包含的层次,为提取后的专有地名元素赋予先后序关系标记,构成形式如(id,ele
i
,seqmark
i
)的三元组,其中,id表示对地址元素的唯一标识,ele
i
表示专有地名元素,seqmark
i
是以地址元素所属行政区划层级表示的先后序标记;
17.针对每一条地址,将对应的三元组元素按前后序关系构建成一颗子树tree
i
,将每一棵子树完全相同三元组的节点进行合并,合并后的若干棵树构成的集合treeset构成了一个基本的地名地址基因库addressdb,其中包含以地理要素为基础构建的地名地址基因及其对应的层次关系;
18.步骤1d、利用构建好的地名地址基因库对事件描述全文进行要素抽取,使用获得的词表wordlist与全文进行匹配,提取其中的专有地址基因集d1;针对“号”、“号楼”、“栋”、“幢”等地址通配名进行逆向增字匹配,匹配到通配名后向前判断通配名之前的字符是否为阿拉伯数字、以汉字表达的数字或英文字母,符合的话则将其加入匹配结果并继续判断,直到判断为否为止,构建通配地址基因集d2;
19.对集合d1中的两个相邻元素d1、d2,两个元素在事件描述文本中的对应起始位置loc若满足则判定两元素为相邻,反之判定为不相邻;
20.对相邻的基因元素,利用地名地址基因库中专有地址基因三元组之中包含的先后续标记关系seqmark对相邻元素的完整程度进行判断,若两个相邻元素的标记之间存在缺失值,则证明两个地理元素之间存在要素缺失,根据构建出的地址基因库中的三元组树从上到下搜索,对不符合条件的相邻地址基因进行补充,组装成新的完整地名地址基因,作为事件中提取得到的地名地址信息。
21.优选地,在步骤2中,将社基层治理实践中包含的元素划分为时间元素、地理元素、事件元素与其他元素四类,使用地名地址基因对内容中包含的地址信息进行提取,而后对相邻的地理元素进行完整性判断,并将不完整的地址基因扩充为完整基因集,进一步合并后将每一个地址基因扩充成标准化地址,基于该地址匹配结果将该事件拟分拨给对应网格下的社区管理人员处置。
22.优选地,步骤3包括:
23.步骤3a、对事件描述进行句子分割并使用jieba分词进行分词处理得到documenttokens和sentencetokens,并将分词后的token进行词性标注得到带有词性标签的labeltoken序列;
24.步骤3b、使用np
‑
chunker根据词性标签从labeltoken序列中提取名词token(np),得到的np作为候选关键词;
25.步骤3c、将所有document tokens使用xlnet生成词向量,再使用sif权重将词向量组成word level的文本向量;
26.步骤3d、首先,将所有sentence tokens使用xlnet生成词向量,使用sif权重将词向量组成多个句向量;其次,根据文本的内容层次分布,使用加权平均的方法将多个句向量组合成sentencelevel的文本向量;最后,将wordlevel和sentencelevel的文本向量加权组成documentvector;
27.步骤3e、将每个label token使用xlnet生成wordvector,计算与documentvector之间的距离,将此距离视为候选关键字与文档主题之间的相似度,选择最相似的候选关键词的前n个作为最终关键词。
28.优选地,在步骤4中,使用步骤3中的技术对文本型的事件描述进行关键词提取,将关键词作为事件案例的标签,并对标签进行编码处理,从而事件案例可以表示成:<标签编码集合,事件描述,事件解决方案描述,效果描述>,实现对事件案例的快速检索。
29.优选地,步骤5包括:
30.步骤5a、选取原文中与标准摘要计算rouge得分最高的一句话加入候选集合,接着继续从原文中进行选择,保证选出的摘要集合rouge得分增加,直至无法满足该条件;得到的候选摘要集合对应的句子设为1标签,其余为0标签;采用上述数据训练一个二分类模型作为句子重要性判别模型,或者使用强化学习、图神经网络对句子进行打分的方法判别句子重要性;
31.步骤5b、使用上述模型对事件描述文本进行文本分类,或者使用强化学习、图神经网络对句子进行打分,将重要性高的句子作为文本摘要的输入文本,采用预训练语言模型对输入文本进行wordlevel的embedding和sentencelevel的embedding;
32.步骤5c、以有监督的训练方式,使用融合word level和sentence level的多层次embedding数据训练一个融合注意力机制和指针生成网络的seq2seq结构的文本摘要模型,最终利用该模型计算事件描述的文本摘要;
33.步骤5d、对两个事件描述的文本摘要进行相似度计算,采用预训练语言模型提取文本摘要的词向量,结合sif权重计算文本摘要的句向量;计算两个事件描述文本摘要句向量的距离,将此距离视为两个事件描述的全文相似度。
34.优选地,步骤6包括:
35.步骤6a、对待处理的新事件经过步骤3对文本型的事件描述进行关键词提取,将关键词作为事件的标签,并对标签进行编码处理,得到待处理事件表示:<标签编码集合,事件描述>;用标签编码集合中的每个标签编码在历史事件案例库中进行查询,查找包含待处理事件标签的所有历史事件案例作为候选集;
36.步骤6b、经过步骤5对候选集中的所有事件描述与待处理的事件描述进行全文的相似度计算,得到根据相似度排序的top n事件案例自动推送给社区管理人员;
37.步骤6c、社区管理人员根据提供的案例处理当前事件,形成当前事件的解决方案,当前的事件可以表示成:<标签编码集合,事件描述,事件解决方案描述>;
38.步骤6d、将当前事件存入基层治理历史事件案例库。
39.根据上述技术方案,本发明基于统一的标准地址库构建地名地址基因库,使用自定义三元组表示地址基因,并构建树集合以表征地址基因之间的层次关系;将基层治理实践中包含的元素划分为时间元素、地理元素、事件元素与其他元素四类,使用地名地址基因对内容中包含的地址信息进行提取,而后对相邻的地理元素进行完整性判断,并将不完整的地址基因扩充为完整基因集,进一步合并后将每一个地址基因扩充成标准化地址;构建基层治理事件历史案例库,然后通过使用自然语言处理技术分析挖掘事件之间的相似性,找出与待处理事件最相似的案例并给出解决方案参考。
40.本发明的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
41.附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:
42.图1是本发明提供的一种面向基层治理的事件自动分拨方法的流程图;
43.图2是本发明提供的一种面向基层治理的事件自动分拨方法中步骤1b的操作流程图;
44.图3是本发明提供的一种面向基层治理的事件自动分拨方法中步骤3b的操作流程图;
45.图4是本发明提供的一种面向基层治理的事件自动分拨方法中步骤3d的操作流程图;
46.图5是本发明提供的一种面向基层治理的事件自动分拨方法中步骤3e的操作流程图。
具体实施方式
47.以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
48.参见图1,本发明提供一种面向基层治理的事件自动分拨方法,包括:
49.步骤1、构建地名地址基因库;
50.步骤2、抽取事件地理要素;
51.步骤3、提取事件描述关键词;
52.步骤4、构建历史事件案例库;
53.步骤5、计算事件相似度;
54.步骤6、事件自动分拨。
55.在事件上报过程中,由于表达习惯的不同,同一地理实体可能对应多种不同的地名描述,这些地名指代往往存在模糊性、随机性、多样性等特点。地名地址在形式上可以分解为若干地名地址要素,引起相互之间的关联与派生关系,单个地名地址要素或若干个地名地址要素的组合形成地名地址基因。尽管地名指代的描述存在不确定性,但针对同一事件的地名地址使用一般存在描述相似性,即地名描述中所包含的地名地址基因往往是相似的。
56.因此,在步骤1中,本发明基于统一的标准地址库构建地名地址基因库,使用自定义三元组表示地址基因,并构建树集合以表征地址基因之间的层次关系。
57.具体的,步骤1包括:
58.步骤1a、利用统计学特征确定标准地址库中地址的落差点,通过递增切分的方法对递增的短语在整个地址库中的数量进行统计;地址元素的使用频次会随地址描述逐渐精确而逐渐降低,当待判断短语后缀超过落差点后,对应的短语在整个地址库中出现的数量将发生明显下降,据此划分出落差点集合m;
59.步骤1b、由于存在落差点之间的元素长度过短、错误或并非完整元素等情况,落差点并不完全等于后缀点,但落差点中包含划分地址中专有名词的后缀点,且后缀点之间的内容构成地址要素。为了对m中的元素是否为正确的后缀点做出判断,按照地址构成方式的
规则设计决策树,然后根据决策树对每一个落差点mi∈m是否构成后缀词或后缀点做出判断,依据判定成功的后缀点进行分词,并对两个后缀点之间的地址要素加以记录,见图2;
60.步骤1c、经过分词后,标准化的地址描述所包含的地址要素被划分为专有地址部分与通配地址部分,同时获得一个包含专有地址名词基因的词表wordlist;针对专有地址部分,基于标准地址自身的前后文关系,结合地址信息本身所包含的层次,为提取后的专有地名元素赋予先后序关系标记,构成形式如(id,ele
i
,seqmark
i
)的三元组,其中,id表示对地址元素的唯一标识,ele
i
表示专有地名元素,seqmark
i
是以地址元素所属行政区划层级表示的先后序标记;
61.针对每一条地址,将对应的三元组元素按前后序关系构建成一颗子树tree
i
,将每一棵子树完全相同三元组的节点进行合并,合并后的若干棵树构成的集合treeset构成了一个基本的地名地址基因库addressdb,其中包含以地理要素为基础构建的地名地址基因及其对应的层次关系;
62.步骤1d、利用构建好的地名地址基因库对事件描述全文进行要素抽取,使用获得的词表wordlist与全文进行匹配,提取其中的专有地址基因集d1;针对“号”、“号楼”、“栋”、“幢”等地址通配名进行逆向增字匹配,匹配到通配名后向前判断通配名之前的字符是否为阿拉伯数字、以汉字表达的数字或英文字母,符合的话则将其加入匹配结果并继续判断,直到判断为否为止,构建通配地址基因集d2;
63.对集合d1中的两个相邻元素d1、d2,两个元素在事件描述文本中的对应起始位置loc若满足则判定两元素为相邻,反之判定为不相邻;
64.对相邻的基因元素,利用地名地址基因库中专有地址基因三元组之中包含的先后续标记关系seqmark对相邻元素的完整程度进行判断,若两个相邻元素的标记之间存在缺失值,则证明两个地理元素之间存在要素缺失,根据构建出的地址基因库中的三元组树从上到下搜索,对不符合条件的相邻地址基因进行补充,组装成新的完整地名地址基因,作为事件中提取得到的地名地址信息。
65.在步骤2中,将社基层治理实践中包含的元素划分为时间元素、地理元素、事件元素与其他元素四类,使用地名地址基因对内容中包含的地址信息进行提取,而后对相邻的地理元素进行完整性判断,并将不完整的地址基因扩充为完整基因集,进一步合并后将每一个地址基因扩充成标准化地址,基于该地址匹配结果将该事件拟分拨给对应网格下的社区管理人员处置。
66.步骤3包括:
67.步骤3a、对事件描述进行句子分割并使用jieba分词进行分词处理得到documenttokens和sentencetokens,并将分词后的token进行词性标注得到带有词性标签的labeltoken序列;
68.步骤3b、如图3所示,使用np
‑
chunker根据词性标签从labeltoken序列中提取名词token(np),得到的np作为候选关键词;
69.步骤3c、将所有document tokens使用xlnet生成词向量,再使用sif权重将词向量组成word level的文本向量;
70.步骤3d、如图4所示,首先,将所有sentence tokens使用xlnet生成词向量,使用sif权重将词向量组成多个句向量;其次,根据文本的内容层次分布,使用加权平均的方法
将多个句向量组合成sentencelevel的文本向量;最后,将wordlevel和sentencelevel的文本向量加权组成documentvector;
71.步骤3e、参见图5,将每个label token使用xlnet生成wordvector,计算与documentvector之间的距离,将此距离视为候选关键字与文档主题之间的相似度,选择最相似的候选关键词的前n个作为最终关键词。
72.在步骤4中,历史基层治理事件案例主要是文本类型数据,包括对事件整体情况的描述,还包括对事件的解决方案的描述,可能还包括对事件求解效果的描述,所以事件案例可以表示成:<事件描述,事件解决方案描述,效果描述>,为了快速检索历史事件案例,需要对事件描述生成标签,利用标签实现快速检索。即使用步骤3中的技术对文本型的事件描述进行关键词提取,将关键词作为事件案例的标签,并对标签进行编码处理,从而事件案例可以表示成:<标签编码集合,事件描述,事件解决方案描述,效果描述>,实现对事件案例的快速检索。
73.步骤5包括:
74.步骤5a、选取原文中与标准摘要计算rouge得分最高的一句话加入候选集合,接着继续从原文中进行选择,保证选出的摘要集合rouge得分增加,直至无法满足该条件;得到的候选摘要集合对应的句子设为1标签,其余为0标签;采用上述数据训练一个二分类模型作为句子重要性判别模型,或者使用强化学习、图神经网络对句子进行打分的方法判别句子重要性;
75.步骤5b、使用上述模型对事件描述文本进行文本分类,或者使用强化学习、图神经网络对句子进行打分,将重要性高的句子作为文本摘要的输入文本,采用预训练语言模型对输入文本进行wordlevel的embedding和sentencelevel的embedding;
76.步骤5c、以有监督的训练方式,使用融合word level和sentence level的多层次embedding数据训练一个融合注意力机制和指针生成网络的seq2seq结构的文本摘要模型,最终利用该模型计算事件描述的文本摘要;
77.步骤5d、对两个事件描述的文本摘要进行相似度计算,采用预训练语言模型提取文本摘要的词向量,结合sif权重计算文本摘要的句向量;计算两个事件描述文本摘要句向量的距离,将此距离视为两个事件描述的全文相似度。
78.步骤6包括:
79.步骤6a、对待处理的新事件经过步骤3对文本型的事件描述进行关键词提取,将关键词作为事件的标签,并对标签进行编码处理,得到待处理事件表示:<标签编码集合,事件描述>;用标签编码集合中的每个标签编码在历史事件案例库中进行查询,查找包含待处理事件标签的所有历史事件案例作为候选集;
80.步骤6b、经过步骤5对候选集中的所有事件描述与待处理的事件描述进行全文的相似度计算,得到根据相似度排序的top n事件案例自动推送给社区管理人员;
81.步骤6c、社区管理人员根据提供的案例处理当前事件,形成当前事件的解决方案,当前的事件可以表示成:<标签编码集合,事件描述,事件解决方案描述>;
82.步骤6d、将当前事件存入基层治理历史事件案例库。
83.由此可见,本发明基于标准地址库,通过统计学方法、策略树和数据比对技术将地名地址描述拆分为“地名地址基因”,并通过构建三元组的方式构建了一个地名地址统一基
因库,获取地名中的谱特征。基于已构建的地名地址基因库对基层治理事件中的地理信息加以提取,并利用地址基因之间的关联关系对缺失地址元素进行补全和还原。利用历史事件案例构建案例库,对事件描述关键词进行编码,以关键词编码进行查询实现快速的事件检索,使用全文相似度实现精准的事件匹配。在事件描述的关键词提取过程中使用预训练语言模型xlnet提取语义信息获取词向量,并使用sif权重获取融合多层次语义的全文向量,该全文向量更符合原文语义信息,从而使得提取的关键词更加准确有效。在事件描述的全文匹配的过程中采用有监督的方式以多层次embedding数据训练一个融合注意力机制和指针生成网络的seq2seq结构的文本摘要模型,以实现事件描述的全文精准匹配。
84.以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
85.另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
86.此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
