1.本发明属于信息传播、计算机基数、大数据挖掘算法技术领域,具体为一 种基于媒介贡献度的新闻热点预测方法。
背景技术:
2.在观察新信息分析和发布的时候,人们通常不清楚要发布的内容是否会引 起读者的关注,是否会点燃读者较高的传播热情。例如:在新闻门户、社交媒 体平台上,什么主题的新闻更容易成为传播的热点;在不同的平台、不同类型 的账号里,哪些平台发的新闻更容易成为当前的舆论热点;对于特定人物,有 关该人物哪些事项的主题会更容易成为新闻焦点。对于这类信息的预测通常依 赖于人的知识与经验,现提出通过计算机技术进行大数据的计算,帮助预测新 生的新闻事件中,哪些事件会变成人们关注、讨论和传播的舆论热点。
3.针对上述需求,现有的预测方法通常预测方法为人工的预测方案,其过程 和结果严重依赖用户的知识与经验,准确性及可重复性存在不稳定状态。因此 本发明提出一种基于媒介贡献度的新闻热点预测方法,通过新生事件参与信源 的贡献度数值,提早研判其是否可成为热点事件,以便做出针对性的议程设置 和准备应对措施。
技术实现要素:
4.本发明的目的在于解决背景技术中的问题,提供一种基于媒介贡献度的新 闻热点预测方法。
5.本发明采用的技术方案如下:
6.一种基于媒介贡献度的新闻热点预测方法,包括以下步骤:
7.步骤一:利用新闻热点标签的生成方法及系统提取新闻数据集中的新闻 簇;
8.步骤二:利用智能信息处理技术来采集出这些热点舆情事件的相关数据;
9.步骤三:利用贡献值计算的模型对不同领域热点事件中,不同平台、不同 类型账号、不同时期的贡献度进行计算;
10.步骤四:得到分平台、分信源、分时期的热点事件媒介贡献度指数。
11.优选的,所述步骤一包括:
12.第一提取单元,用于提取新闻数据集中的新闻簇,一个所述新闻簇包括至 少两个所述新闻记录;
13.确定单元,用于确定提取出的多个所述新闻簇中的热点新闻簇;
14.第二提取单元,用于提取所述热点新闻簇中各新闻记录的关键字;
15.第一生成单元,用于生成由一个新闻记录的至少两个所述关键字组合的组 合词,一个新闻记录对应一个或多个所述组合词;
16.第二生成单元,用于根据所述组合词的热度值生成新闻热点标签。
17.优选的,所述第一提取单元包括:
18.第一计算模块,用于计算所述新闻数据集中两个新闻记录之间的相似度; 判断模块,用于判断所述相似度是否大于第一预设阈值;以及
19.第一确定模块,用于所述相似度大于所述第一预设阈值时,确定所述两个 新闻记录属于同一新闻簇。
20.优选的,所述第一计算模块包括:
21.特征化子模块,用于将所述两个新闻记录分别进行特征化提取,得到一个 新闻记录对应的第一向量和另一个新闻记录对应的第二向量;
22.计算子模块,用于采用以下任意一个公式计算所述相似度:
23.sim(x,y)=(x*y)/(||x|1*1|γ||),或者;
[0024][0025]
其中,sim(x,y)为所述相似度,x为所述第一向量,y为所述第二向量, x=(x1,x2,x3,
…
,x
n
),y=(y1,y2,y3,
…
,y
n
),||x||和||y||分别为 x和y的欧几里得范数,所述第一向量对应的新闻记录为第一新闻记录,所述 特征化子模块采用以下步骤得到所述第一向量:对所述第一新闻记录的标题和 正文进行分词,得到由多个词元组成的第一词元集;根据词元在所述第一新闻 记录中出现的次数计算所述第一词元集中词元对应的特征值;删除所述第一词 元集中特征值小于第二预设阈值的词元;以及
[0026]
生成所述第一向量:x=(<w1,c1>,<w2,c2>,<w3,c3>,
···
,<w
n
,c
n
>),其 中,w1,w2,w3,
···
,w
n
为所述述第一词元集中词元,c1,c2,c3,
···
,c
n
分另l
j
为 词元对应的特征值,n为所述第一词元集中词元的个数,所述特征化子模块采用 以下公式计算所述第一词元集中词元对应的特征值:c
i
=a
l
a2*t a3*p a4*k其 中,c
i
为所述第一词元集中第i个词元对应的特征值,a
l
为所述第i个词元在 所述第一新闻记录中出现的次数,a2为所述第i个词元在所述第一新闻记录 的标题中出现的次数,a3为所述第i个词元在所述第一新闻记录的段首或段尾 中出现的次数,a4为所述第i个词元在所述第一新闻记录的关键句中出现的 次数,t、p、k均为无量纲参数。
[0027]
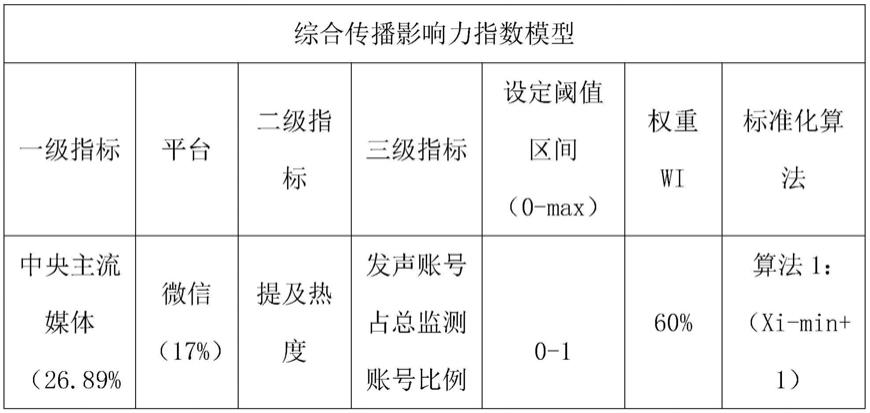
优选的,所述步骤三贡献值计算的模型分为两层,一层是账号分类层,其 根据账号属性进行分类,在根据数据测算不同权重占比,另一层是平台分类层, 其根据发文平台属性进行分类,在根据数据测算不同权重占比。
[0028]
优选的,所述步骤四中分时期的热点事件分为早期参与和新生事件,所述 早期参与进行加权,所述新生事件根据早期参与信源的贡献度数值,建立数据 集训练回归模型,最后利用机器学习算法研判其是否可成为热点事件。
[0029]
优选的,所述机器学习算法采用梯度下降算法:
[0030][0031]
其中是参数的梯度,目标函数j(θ)关于参数的梯度将是目标函数θ上升 最快的方向,η为所述第一词元集中词元的个数。
[0032]
综上所述,由于采用了上述技术方案,本发明的有益效果是:
[0033]
1、本发明中,克服了现有人工方法效率低下,准确度严重依赖知识经验 的弊端,
通过大数据及语义分析技术,使用计算机算法实现,大大提升速度、 效率及其适用场景。
[0034]
2、本发明中,通过大数据技术,采集和分析海量数据,极大扩大了分析 的样本数据及案例,充分利用历史积累的大量案例,对于用户内容倾向和舆论 热点传播的各方面特征进行挖掘,模型更为科学合理,分析结果不断得到改善, 并达到一定准确度。
[0035]
3、本发明中,提供的贡献度计算模型稳定性好,不停监测范围的变化不 会影响最终的计算结果,新模型准确度高,榜单排名不会受到某个指标极大, 极小值的影响,新模型排极端能力强,社会极端新闻不会影响榜单的权威性, 新模型数据覆盖面广。
[0036]
4、本发明中,预测过程以新闻内容倾向的标签为基础,结合新闻传播中 的时间、账号类型、媒介、用户反馈等各个维度,对于新闻热点的广泛传播特 征进行全面分析,提升预测判断的多因素作用及共同作用综合分析,预测结果 更为准确和贴近实际。
附图说明
[0037]
图1为本发明的新闻热点预测总体图;
[0038]
图2为本发明的新闻热点标签提取流程图;
[0039]
图3为本发明的梯度下降算法流程图。
具体实施方式
[0040]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实 施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅 用以解释本发明,并不用于限定本发明。
[0041]
参照图1
‑
3,一种基于媒介贡献度的新闻热点预测方法,包括以下步骤:
[0042]
步骤一:利用新闻热点标签的生成方法及系统提取新闻数据集中的新闻 簇;
[0043]
其中包括:
[0044]
第一提取单元,用于提取新闻数据集中的新闻簇,一个所述新闻簇包括至 少两个所述新闻记录;
[0045]
确定单元,用于确定提取出的多个所述新闻簇中的热点新闻簇;
[0046]
第二提取单元,用于提取所述热点新闻簇中各新闻记录的关键字;
[0047]
第一生成单元,用于生成由一个新闻记录的至少两个所述关键字组合的组 合词,一个新闻记录对应一个或多个所述组合词;
[0048]
第二生成单元,用于根据所述组合词的热度值生成新闻热点标签;
[0049]
所述第一提取单元包括:
[0050]
第一计算模块,用于计算所述新闻数据集中两个新闻记录之间的相似度;
[0051]
判断模块,用于判断所述相似度是否大于第一预设阈值;以及
[0052]
第一确定模块,用于所述相似度大于所述第一预设阈值时,确定所述两个 新闻记录属于同一新闻簇;
[0053]
所述第一计算模块包括:
[0054]
特征化子模块,用于将所述两个新闻记录分别进行特征化提取,得到一个 新闻记录对应的第一向量和另一个新闻记录对应的第二向量;
[0055]
计算子模块,用于采用以下任意一个公式计算所述相似度:
[0056]
sim(x,y)=(x*y)/(||x|1*1|γ||),或者;
[0057][0058]
其中,sim(x,y)为所述相似度,x为所述第一向量,y为所述第二向量, x=(x1,x2,x3,
…
,x
n
),y=(y1,y2,y3,
…
,y
n
),||x||和||y||分别为 x和y的欧几里得范数,所述第一向量对应的新闻记录为第一新闻记录,所述 特征化子模块采用以下步骤得到所述第一向量:对所述第一新闻记录的标题和 正文进行分词,得到由多个词元组成的第一词元集;根据词元在所述第一新闻 记录中出现的次数计算所述第一词元集中词元对应的特征值;删除所述第一词 元集中特征值小于第二预设阈值的词元;以及
[0059]
生成所述第一向量:x=(<w1,c1>,<w2,c2>,<w3,c3>,
···
,<w
n
,c
n
>),其 中,w1,w2,w3,
···
,w
n
为所述述第一词元集中词元,c1,c2,c3,
···
,c
n
分另l
j
为 词元对应的特征值,n为所述第一词元集中词元的个数,所述特征化子模块采用 以下公式计算所述第一词元集中词元对应的特征值:c
i
=a
l
a2*t a3*p a4*k其 中,c
i
为所述第一词元集中第i个词元对应的特征值,a
l
为所述第i个词元在 所述第一新闻记录中出现的次数,a2为所述第i个词元在所述第一新闻记录 的标题中出现的次数,a3为所述第i个词元在所述第一新闻记录的段首或段尾 中出现的次数,a4为所述第i个词元在所述第一新闻记录的关键句中出现的 次数,t、p、k均为无量纲参数。
[0060]
步骤二:利用智能信息处理技术来采集出这些热点舆情事件的相关数据, 例如不同平台上的信息量、传播数据量等等。针对抓取各平台信息的实际应用, 通过合理的接入不同平台的api,从而实现了增量抓取的算法,明显提高微博 信息的抓取的准确性与全面性,大大增强其实用性;
[0061]
步骤三:利用贡献值计算的模型对不同领域热点事件中,不同平台、不同 类型账号、不同时期的贡献度进行计算;
[0062]
具体的算法模型主要分了两层,一个是账号分类层,其根据账号属性进行 分类,在根据数据测算不同权重占比,另一个是平台分类层,其根据发文平台 属性进行分类,在根据数据测算不同权重占比,其中各账号分类的确定是根据 各大自媒体平台在账号注册时所使用的标准,如微信,抖音,快手,一点资讯, 头条等,具体的算法模型如下表:
[0063]
[0064]
[0065]
[0066]
[0067]
[0068][0069]
步骤四:得到分平台、分信源、分时期的热点事件媒介贡献度指数,分时 期的热点事件分为早期参与和新生事件,所述早期参与进行加权,所述新生事 件根据早期参与信源的贡献度数值,建立数据集训练回归模型,最后利用机器 学习算法研判其是否可成为热点
事件;
[0070]
通过不断优化算法,使得判断的准确性不断优化。具体的机器学习算法采 用梯度下降算法,目标函数关于参数的梯度将是目标函数上升最快的方向。对 于最小化优化问题,只需要将参数沿着梯度相反的方向前进一个步长,就可以 实现目标函数的下降,
[0071][0072]
其中是参数的梯度,目标函数j(θ)关于参数的梯度将是目标函数θ上升 最快的方向,η为所述第一词元集中词元的个数,根据计算目标函数采用数据 量的不同,梯度下降算法又可以分为批量梯度下降算法,随机梯度下降算法和 小批量梯度下降算法,对于批量梯度下降算法,其是在整个训练集上计算的, 如果数据集比较大,可能会面临内存不足问题,而且其收敛速度一般比较慢。 随机梯度下降算法是另外一个极端,是针对训练集中的一个训练样本计算的, 又称为在线学习,即得到了一个样本,就可以执行一次参数更新,所以其收敛 速度会快一些,但是有可能出现目标函数值震荡现象,因为高频率的参数更新 导致了高方差,小批量梯度下降算法是折中方案,选取训练集中一个小批量样 本计算,这样可以保证训练过程更稳定,而且采用批量训练方法也可以利用矩 阵计算的优势。
[0073]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发 明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明 的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
