一种基于多管道匹配的ab实验分流方法
技术领域
1.本发明涉及计算机数据处理应用技术领域,尤其是一种基于多管道匹配的ab实验分流方法。
背景技术:
2.ab实验是在产品应用或页面或流程制作两个(a/b)或多个(a/b/n)版本,在同一个时间维度,从全体用户流量中划分出组成成分相同或相似的访客群组,来随机的访问这些不同的实验版本,为不同的实验版本设置不同的实验方案,收集各个群组的用户体验数据和业务数据,观察分析实验指标效果,通过数据驱动来推进产品的迭代、验证算法效果、获取业务产出等等,得到实验结论,最后分析评估出最优版本,并正式采用,此种实验方法被广泛应用在互联网产品中进行产品的迭代优化。
3.现代互联网产品在庞大的用户群体下,无法快速的决策某项功能的正确性以及最优方案,所以一个快速且有效的ab实验方案对整个产品的更迭优化起着至关重要的作用,一般情况下,为同一个优化目标制定两个方案,让同一用户群体中的一部分用户命中a方案,同时另一部分用户命中b方案,统计并比较不同方案下的点击率、转化率等数据指标,通过不同方案的数据表现,在确定数据表现通过假设检验后决定最终方案,应用ab实验来确定方案结果的项目包括多版本的活动落地页、多版本的营销发券等等,而ab实验过程中将用户群体进行分流的步骤又是决定ab实验是否能验证出最优指标的关键,ab实验的分流需要确保各个实验版本中所分配的用户流量符合预期,且所分配的用户流量满足一致性、均匀性以及独立性,才能确保ab实验的有效性。
4.现有的ab实验的分流方法,是对每个用户标识进行hash取数取模后进行ab实验,用户标识包括系统自动分配的uid(user identification)和用户自己设置的id身份标识,hash(哈希)是一种散列算法,将任意长度的输入通过散列算法变换成固定长度的输出,此种ab实验分流方法受限于uid或id的生成规则,如果uid或id本身是不均匀的,则hash取数取模后也会造成ab实验的版本分流不均,也就无法确保ab实验的有效性。
技术实现要素:
5.本发明的目的在于克服现有技术的不足,提供一种将用户转换为分桶编号后再进行ab实验版本取数取模得到的流量均匀的ab实验分流方法。
6.本发明解决其技术问题是采取以下技术方案实现的:
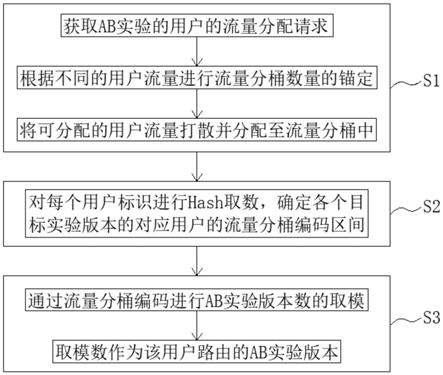
7.一种基于多管道匹配的ab实验分流方法,包括以下步骤:
8.s1、获取针对ab实验的当前用户的流量分配请求,所述当前用户的流量分配请求包括当前用户流量分配的目标实验的目标实验版本以及各个目标实验版本的用户流量比例,根据不同的用户流量进行流量分桶数量的锚定,将当前可分配的用户流量打散并分配至预定数目的流量分桶中,其中,用户流量分桶数量的锚定为:
9.当用户流量数大于1亿时,流量分桶数量为1000,当用户流量数小于1亿时,流量分
桶数量为100;
10.s2、根据各个目标实验版本的用户流量比例,对每个用户标识进行hash取数后进行流量分桶编码,确定各个目标实验版本的对应用户的流量分桶编码区间,流量分桶编码区间的确定规则为:
11.当用户流量数大于1亿时,流量分桶编码区间为1
‑
1000,当用户流量数小于1亿时,流量分桶编码区间为1
‑
100;
12.s3、根据所确定的各个目标实验版本的对应用户流量分桶编码区间,通过步骤s2中的每个用户的流量分桶编码进行ab实验版本数的取模,取模数作为该用户路由的ab实验版本,此种分流方法解决了简单的uid或id用户标识进行hash取数取模造成的ab实验版本分流不均的问题。
13.优选的,所述步骤s2中用户标识包括系统设定的uid标识码和用户自定的id标识码。
14.优选的,所述步骤s2中hash取数采用md5算法进行取数,所述md5算法的取数步骤为:
15.第一步,对于任意长度的明文,md5对其进行分组,添加位数,使得每一组输入的长度为512位,在明文后添加位的方法是第一个添加位是1,其余都是0,然后将真正明文的长度以64位表示,附加于前面已添加过位的明文后,此时的明文长度正好为512位的倍数,当明文长度大于2的64次方时,仅仅使用低64位比特填充,附加到最后一个分组的末尾;
16.第二步,对这些明文分组反复重复处理,将512位的明文分组划分为16个子明文分组,每个子明文分组为32位,申请4个32位的链接变量,记为a、b、c、d,子明文分组与链接变量先后进行4轮运算,再将链接变量与初始链接变量进行求和运算,链接变量作为下一个明文分组的输入重复上述操作;
17.第三步,输出4个32位字的级联,4个链接变量的数据就是产生128位的md5数据摘要。
18.优选的,所述步骤s3中ab实验版本数的取模方法为:
19.先配置数量为m的ab实验版本,再将每个用户标识经过hash取数后得到的值按照ab实验版本的数量m进行取模,每个用户会落到1至m的ab实验版本中的其中一个,即对应的项目版本。
20.本发明的优点和积极效果是:
21.本发明通过将所有需要进行ab实验的用户流量根据特定的分桶标准进行分桶编码,再通过每个用户的分桶编码进行ab实验版本数的取模数作为该用户路由的ab实验版本,此种方法解决了简单的uid或id用户标识进行hash取数取模造成的ab实验版本分流不均的问题,通过多管道匹配路由的方式抹平了分配不均的问题。
附图说明
22.图1是本发明的流量分流方法的步骤流程示意图。
具体实施方式
23.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
24.需要说明的是,当组件被称为“固定于”另一个组件,它可以直接在另一个组件上或者也可以存在居中的组件。当一个组件被认为是“连接”另一个组件,它可以是直接连接到另一个组件或者可能同时存在居中组件。当一个组件被认为是“设置于”另一个组件,它可以是直接设置在另一个组件上或者可能同时存在居中组件。本文所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。
25.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
26.以下结合附图对本发明实施例做进一步详述:
27.如图1所示,本发明所述的一种基于多管道匹配的ab实验分流方法,包括以下步骤:
28.s1、获取针对ab实验的当前用户的流量分配请求,当前用户的流量分配请求包括当前用户流量分配的目标实验的目标实验版本以及各个目标实验版本的用户流量比例,根据不同的用户流量进行流量分桶数量的锚定,将当前可分配的用户流量打散并分配至预定数目的流量分桶中,其中,用户流量分桶数量的锚定为:
29.当用户流量数大于1亿时,流量分桶数量为1000,当用户流量数小于1亿时,流量分桶数量为100;
30.s2、根据各个目标实验版本的用户流量比例,对每个用户标识进行hash取数后进行流量分桶编码,用户标识包括系统设定的uid标识码和用户自定的id标识码,确定各个目标实验版本的对应用户的流量分桶编码区间,流量分桶编码区间的确定规则为:
31.当用户流量数大于1亿时,流量分桶编码区间为1
‑
1000,当用户流量数小于1亿时,流量分桶编码区间为1
‑
100;
32.s3、根据所确定的各个目标实验版本的对应用户流量分桶编码区间,通过步骤s2中的每个用户的流量分桶编码进行ab实验版本数的取模,取模数作为该用户路由的ab实验版本,其中,ab实验版本数的取模方法为:
33.先配置数量为m的ab实验版本,再将每个用户标识经过hash取数后得到的值按照ab实验版本的数量m进行取模,每个用户会落到1
‑
m的ab实验版本中的其中一个,即对应的项目版本。
34.上述的hash为散列算法,即哈希算法,基本原理是将任意长度的输入,通过hash算法变为固定长度的输出,原始数据映射后的二进制串就是哈希值,即散列值,此种转换是一种压缩映射,也就是散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,换言之,就是一种可以将任意长度的消息压缩到某一固定长度的消息摘要的函数,但是,hash虽然被称为算法,但实际上它更像是一种思想,是一个广义的算法,没有固定的公式,只要符合散列思想的算法都可以被称为hash算法,使用hash算法可以提高存储空间的利用率,提高数据的查询效率。
35.在本实施例中,步骤s2中hash取数采用md5算法进行取数,md5属于hash算法的一种,对于任意长度的明文,md5首先对其进行分组,添加位数,使得每一组输入的长度为512位,在明文后添加位的方法是第一个添加位是1,其余都是0,然后将真正明文的长度以64位表示,附加于前面已添加过位的明文后,此时的明文长度正好为512位的倍数,当明文长度大于2的64次方时,仅仅使用低64位比特填充,附加到最后一个分组的末尾,然后对这些明文分组反复重复处理,将512位的明文分组划分为16个子明文分组,每个子明文分组为32位,申请4个32位的链接变量,记为a、b、c、d,子明文分组与链接变量先后进行4轮运算,再将链接变量与初始链接变量进行求和运算,链接变量作为下一个明文分组的输入重复上述操作,最后,输出4个32位字的级联,4个链接变量的数据就是产生128位的md5摘要。
36.具体实施时,在ab实验中,例如多版本活动落地页的ab实验和多版本的营销发券ab实验,先圈选出实验的定向人群,再配置多版本活动落地页或多版本的营销发券的金额,假定有两个模型,a和b,创建两个不相交的样本,基于定向人群的用户的身份标识(id或uid)的样本选择方式创建或基于请求的样本选择方式创建,对于第一个样本,使用模型a,对于第二个样本,使用模型b,此中的每个样本,称为一个桶,本发明通过将所有需要进行ab实验的用户流量根据特定的分桶标准进行分桶编码,再通过每个用户的分桶编码进行ab实验版本数的取模数作为该用户路由的ab实验版本,评估出多版本活动落地页或多版本的营销发券金额中面向业务目标的最优的选项。此种方法解决了简单的uid或id用户标识进行hash取数取模造成的ab实验版本分流不均的问题,通过多管道匹配路由的方式抹平了分配不均的问题。
37.需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
