1.本技术涉及数据库技术领域,更具体地,涉及一种层次化数据库操作加速系统和方法。
背景技术:
2.在数据库应用领域,面临海量数据处理分析的性能挑战下,通常采用异构计算解决方案来满足性能需求。通常的硬件加速方案都是在部署数据库软件的服务器上扩展一块pcie(peripheral component interconnect express,周边设备高速连接)接口的加速卡,通过将部分数据库操作卸载到加速卡中执行实现数据库处理性能的提升。如何采用硬件尽可能大的提升数据库处理性能,已经成为数据库领域一个重要的技术研究点。
3.数据库查询操作采用硬件加速较之软件获得显著的性能提升,但单张加速卡由于硬件条件比如fpga(field programmable gate array,现场可编程门阵列)资源,高速缓存容量,功耗散热限制等限制,其性能增益存在上限。当单节点处理性能需要更进一步的提升,需要承载更多的数据库查询操作卸载到加速卡上执行时,扩展多卡成为自然而然的选择,但如何实现单节点的多卡扩展,是一个急需解决的问题。
4.现有技术中的一种方案是针对多个可用加速器中的每一个的处理配置检索成本信息,基于所述成本信息和对查询的分析,将一个或多个查询操作卸载到多个加速器中的至少一个。然而,该方案存储单元均在主机(即主机)侧,同时各加速器的执行结果需要汇聚到主机进行处理,因而造成了多加速卡系统加速的性能瓶颈。
5.现有技术中的另一种方案是单节点纵向扩展节点通过一个pcie 转换器连接了多个硬件加速器,并连接了一个存储设备,通过将查询分片的方式,将主机处理后的查询分片分发到至少一个加速器上执行并返回该分片的结果,然而,单节点纵向扩展节点仅为单一的存储单元,同时各加速器执行各自的查询分片,执行结果需要汇聚到主机进行处理,因而影响了多加速卡系统加速性能的进一步提升。
6.因此,如何进一步提升包括多加速卡的单节点数据库系统的处理性能,提高数据查询效率,是目前亟待解决的技术问题。
技术实现要素:
7.本发明提供一种层次化数据库操作加速系统,用以解决现有技术中包括多加速卡的单节点数据库系统存在性能瓶颈的技术问题。
8.该系统包括:主机,接收查询计划,根据所述查询计划,生成相应的查询操作并进行分发,所述主机还接收并处理汇总执行结果;层级加速模块,与所述主机相连,接收主机分配的所述查询操作并返回所述汇总执行结果;所述层级加速模块包括一个主加速卡和至少一个从加速卡,所述主加速卡和所述
从加速卡相互连接,执行被分配的查询操作,产生执行结果;其中所述从加速卡向所述主加速卡返回所述执行结果,由所述主加速卡完成执行结果汇聚和被分配的后续查询操作,向主机返回所述汇总执行结果。
9.在本技术一些实施例中,所述主机和各所述加速卡分别设置有用于存储数据的存储单元,形成加速芯片片内高速缓存、加速卡内存、加速卡存储器、主机侧存储器的多级存储架构;所述主机根据数据分布信息和各加速卡的执行能力信息将所述查询计划分发至各所述加速卡,所述数据分布信息根据各所述存储单元之间的数据分布状态确定。
10.在本技术一些实施例中,所述加速芯片片内高速缓存、所述加速卡内存、所述加速卡存储器、所述主机侧存储器之间按照预设缓存规则进行数据传递。
11.在本技术一些实施例中,各所述从加速卡按预设周期向所述主加速卡发送自身的通告信息,所述主加速卡根据所述通告信息更新各所述加速卡间的数据分布;其中,所述通告信息包括加速卡存储器的剩余容量和存储的数据内容、以及各所述从加速卡记录的各自节点数据块的热度和关联度。
12.在本技术一些实施例中,按照预设规则从各所述加速卡中选定所述主加速卡,所述主加速卡、所述从加速卡和主机之间根据预设物理接口规范进行连接。
13.在本技术一些实施例中,各所述加速卡根据从其他加速卡接收的数据、加速卡自身的内存中的数据、内存池中的数据、加速卡自身的存储器中的数据执行各所述查询操作;各所述加速卡将各所述查询操作的所述执行结果的部分或全部进行保存、发送给其他加速卡、返回所述主加速卡;其中,所述内存池由各所述加速卡内存和所述主机的主机内存按照缓存一致性协议生成。
14.在本技术一些实施例中,各所述加速卡之间通过数据总线和/或网络接口连接,各所述主加速卡和所述从加速卡具备对数据进行加密和/或压缩、解密和/或解压的功能。
15.相应的,本发明还提出了一种层次化数据库操作加速方法,所述方法包括:当接收到主机分配的与查询计划对应的查询操作时,基于层级加速模块中的多个加速卡执行各所述查询操作,所述层级加速模块中的多个加速卡包括一个主加速卡和至少一个从加速卡;基于所述主加速卡向所述主机返回汇总执行结果,以使所述主机根据所述汇总执行结果确定与查询请求对应的结果数据;其中,所述查询计划根据所述查询请求生成,所述查询操作包括由所述主加速卡执行的主查询操作和由所述从加速卡执行的从查询操作,所述汇总执行结果是所述主加速卡根据各所述从查询操作的执行结果执行所述主查询操作的结果。
16.在本技术一些实施例中,基于层级加速模块中多个加速卡执行各所述查询操作,具体为:基于各所述加速卡根据从其他加速卡接收的数据、加速卡自身的内存中的数据、内存池中的数据、加速卡自身的存储器中的数据执行各所述查询操作;基于各所述加速卡将各所述查询操作的执行结果的部分或全部进行保存、发送给其他加速卡、返回所述主加速卡;其中,所述内存池由各所述加速卡内存和所述主机的主机内存按照缓存一致性协
议生成。
17.在本技术一些实施例中,所述方法还包括:基于各所述从加速卡按预设周期向所述主加速卡发送自身的通告信息;以及,基于所述主加速卡根据所述通告信息更新各所述加速卡间的数据分布;其中,所述通告信息包括加速卡存储器的剩余容量和存储的数据内容、以及各所述从加速卡记录的各自节点数据块的热度和关联度。
18.本发明的层次化数据库操作加速系统通过上述技术方案,对数据库的查询操作进行层次化加速,并针对性地构建了加速芯片片内高速缓存、加速卡内存、加速卡存储器以及主机侧存储器的多级存储架构,从而有效避免将执行结果汇聚到主机处理,消除了性能瓶颈,充分发挥多加速卡的加速能力,进一步提升了包括多加速卡的单节点数据库系统的处理性能,提高了数据查询效率。
附图说明
19.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
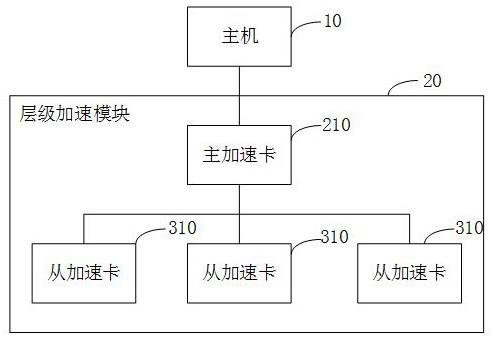
20.图1示出了本发明实施例提出的一种层次化数据库操作加速系统的结构示意图;图2示出了本发明实施例中加速卡的存储架构示意图;图3示出了本发明实施例中主机的存储架构示意图;图4示出了本发明实施例中加速卡与主机的物理连接示意图;图5示出了本发明实施例中包括三个加速卡的层次化数据库操作加速系统架构示意图;图6示出了本发明实施例中在主加速卡部署压缩/解压缩,加密/解密功能的示意图;图7示出了本发明实施例中在从加速卡部署远端存储访问功能和加密/解密功能的示意图;图8示出了本发明实施例提出的一种层次化数据库操作加速方法的流程示意图;图9示出了本发明实施例中在主机接收到一个客户端的查询操作时postgresql输出的q7执行计划示意图;图10示出了与图9对应的执行计划树的示意图;图11示出了将图10中的执行计划树分配到各加速卡的示意图;图12示出了本发明实施例中在主机同时接收到两个客户端的查询操作时postgresql输出的q4执行计划示意图;图13示出了与图12对应的执行计划树的示意图;图14示出了本发明实施例中在主机同时接收到两个客户端的查询操作时postgresql输出的q14执行计划示意图;图15示出了与图14对应的执行计划树的示意图。
具体实施方式
21.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
22.本技术实施例提供一种层次化数据库操作加速系统,如图1所示,包括:主机10,接收查询计划,根据所述查询计划,生成相应的查询操作并进行分发,所述主机10还接收并处理汇总执行结果;层级加速模块20,与所述主机10相连,接收主机10分配的所述查询操作并返回所述汇总执行结果;所述层级加速模块20包括一个主加速卡210和至少一个从加速卡310,所述主加速卡210和所述从加速卡310相互连接,执行被分配的查询操作,产生执行结果;其中所述从加速卡310向所述主加速卡210返回所述执行结果,由所述主加速卡210完成执行结果汇聚和被分配的后续查询操作,向主机10返回所述汇总执行结果。
23.本实施例中,主机10连接有层级加速模块20,该层级加速模块20基于加速卡进行加速,加速卡包括一个主加速卡210和至少一个从加速卡310。所述加速卡可以为外部硬件加速器,是基于硬件实现加速的设备,包括gpu(graphics processing unit,图形处理器)、或fpga、或asic(application specific integrated circuit,专用集成电路)。
24.当主机10接收到与查询请求时,主机10将对应的查询计划分发至各加速卡,使各加速卡执行查询操作,该查询计划可以为一个或多个基于优化引擎生成的执行计划树,此处各加速卡包括主加速卡210和各从加速卡310,该查询操作包括由主加速卡210执行的主查询操作和由从加速卡310执行的从查询操作。各从加速卡310执行各从查询操作后将对应的执行结果发送到主加速卡210,主加速卡210对各从加速卡310的执行结果进行数据汇聚,并根据数据汇聚的结果执行主查询操作,然后主加速卡210将执行所述主查询操作的结果作为汇总执行结果发送到主机10,主机10根据该汇总执行结果确定与查询请求对应的结果数据,然后可以将该结果数据返回用户或客户端。
25.为了减少因为访问外部存储单元中的数据的时间,提高数据库操作的速度,在本技术一些实施例中,所述主机10和各所述加速卡分别设置有用于存储数据的存储单元,形成加速芯片片内高速缓存、加速卡内存、加速卡存储器、主机侧存储器的多级存储架构。
26.其中,如已有生成好的数据库数据,则从主机10存储器中提前加载存放到加速卡存储器中;如从初始空数据库开始,则数据产生时按主机10定义的数据分布规则存放到加速卡存储器中。
27.在本技术具体的应用场景中,如图2所示为加速卡的存储架构示意图,如图3所示为主机的存储架构示意图。如图2所示,加速卡的存储架构包括,1、加速芯片片内高速缓存、2、加速卡内存、3、加速卡存储器;图3中所示,主机的存储架构包括主机内存和4、主机侧存储器。
28.其中,加速卡存储器可包括hdd(hard disk drives,机械硬盘驱动器)或者ssd(solid state drives,固态硬盘),加速卡内存包括dram(dynamic random access memory,动态随机存取存储器),sram(static random access memory,静态随机存取存储
器),sdram(synchronous dynamic random access memory,同步动态随机存取存储器),非易失存储器等。
29.主机根据预设数据分布规则预先将主机侧存储器中存储的数据加载存放到各加速卡存储器中,该数据分布规则具体可以为表征数据在各存储单元之间分布的元数据。主机接收到查询请求时,根据各所述存储单元之间的数据分布状态确定数据分布信息,并根据数据分布信息和各加速卡的执行能力信息将查询计划分发至各所述加速卡。其中,执行能力信息根据各加速卡可执行的操作确定,该操作可包括扫描,连接,排序和汇聚操作。
30.为了提高查询效率,在本技术一些实施例中,所述加速芯片片内高速缓存、所述加速卡内存、所述加速卡存储器、所述主机侧存储器之间按照预设缓存规则进行数据传递。
31.本实施例中,可基于预设缓存规则在各级存储之前进行数据换入换出,预设缓存规则可以为lru(least recently used,最近最少使用)规则。
32.为了提高数据查询的效率,在本技术一些实施例中,各所述从加速卡按预设周期向所述主加速卡发送自身的通告信息,所述主加速卡根据所述通告信息更新各所述加速卡间的数据分布。
33.本实施例中,通告信息包括加速卡存储器的剩余容量和存储的数据内容、以及各所述从加速卡记录的各自节点数据块的热度和关联度,主加速卡根据通告信息更新各所述加速卡间的数据分布。其中,预设周期由主机设定,各自节点数据块的热度根据访问频次确定,各自节点数据块的关联度根据表间join操作确定。
34.可选的,静态数据由主机指定或随机存储到任意加速卡的加速卡存储器中,一些实施例中,各加速卡存储器池化形成同一存储,主机和各加速卡都不感知数据的具体存放位置。
35.为了提高数据查询的效率,在本技术一些实施例中,主加速卡基于负载均衡将各剩余容量在各加速卡存储器之间平均分配,或基于负载均衡将高于预设访问频次的热点数据在各加速卡存储器之间平均分配,或将关联度高于预设值的数据存入同一个加速卡存储器中。
36.在本技术具体的应用场景中,主加速卡通过的数据刷新模块获取通告信息,并基于数据刷新模块控制各加速卡间的数据分布,数据刷新模块可以是主加速卡内集成的可执行指令的处理器,包括arm(advanced risc machines,高级精简指令集处理器),或第五代精简指令集处理器risc
‑
v等微处理器,也可以是由fpga实现的功能模块,从而在各加速卡执行查询操作时,使在各个加速卡间的数据流动量尽可能小,提高了数据查询效率。
37.为了提高系统的兼容性,在本技术一些实施例中,按照预设规则从各所述加速卡中选定所述主加速卡,所述主加速卡、所述从加速卡和主机之间根据预设物理接口规范进行连接。
38.本实施例中,主加速卡和从加速卡可以为内部硬件结构相同的加速卡,可以实现相同的功能;也可以为内部硬件结构不同的加速卡,可以实现不同的功能;各从加速卡也可以为内部硬件结构不同的加速卡,可以实现不同的功能。按照预设规则从各加速卡中选定主加速卡,在本技术一些实施例中,所述主加速卡是在pcie总线上第一个扫描出加速卡,或所述主加速卡为主机根据各加速卡的标识(如物理mac地址)指定的加速卡,或所述主加速卡是根据硬件拨码开关确定的,如将拨码开关拨到1的加速卡为主加速卡。在当前主加速卡
故障时,则由预设的后继加速卡接替当前主加速卡。
39.各加速卡(即主加速卡和各从加速卡)和主机之间根据预设物理接口规范进行连接,在本技术具体的应用场景中,图4中示出了各加速卡和主机之间(a)、(b)、(c)、(d)四种连接方式,如图4中(a)所示,各加速卡可以直接连接主机;如图4中(b)所示,主加速卡直接连接主机并下挂其余从加速卡;如图4中(c)所示,主加速卡直接连接主机,各从加速卡可以接桥接芯片后连接主机;如图4中(d)所示,各加速卡可以经pcie转换芯片连接主机。另外,各加速卡也可在同一pcie总线上,经pcie总线连接主机。
40.为了提高系统的可靠性,在本技术一些实施例中,各所述加速卡根据从其他加速卡接收的数据、加速卡自身的内存中的数据、内存池中的数据、加速卡自身的存储器中的数据执行各所述查询操作;各所述加速卡将各所述查询操作的执行结果的部分或全部进行保存、发送给其他加速卡、返回所述主加速卡。
41.本实施例中,各加速卡接收到待执行的查询操作后,根据实际需要可根据从其他加速卡接收的数据、加速卡自身的内存中的数据、内存池中的数据、加速卡自身的存储器中的数据执行各所述查询操作,内存池由各所述加速卡内存和所述主机的主机内存按照缓存一致性协议生成,各加速卡执行各查询操作之后,各所述加速卡根据实际需要将各查询操作的执行结果的部分或全部进行保存、发送给其他加速卡、返回所述主加速卡。
42.在本技术具体的应用场景中,如图5所示,从加速卡card2执行所分配的查询操作时,可能需要接受主加速卡card1通过总线送来的数据,也可能需要读取本节点的数据,也可能读取从加速卡card3的内存数据。从加速卡card2执行完毕后,可能需要将一部分相关执行结果通过总线送给从加速卡card3,也可能将部分结果存储在本地,也可能就直接将汇总执行结果送主加速卡card1。
43.为了提高系统的可靠性,在本技术一些实施例中,各所述加速卡之间通过数据总线和/或网络接口连接,各所述加速卡中的一个或多个具备对数据进行加密和/或压缩、解密和/或解压的功能。
44.本实施例中,网络接口包括ethernet以太网,fc(fiber channel,光纤通道),roce(rdma over converged ethernet,基于融合以太网的rdma)v2中的一种或多种。在本技术具体的应用场景中,如图5所示,各加速卡通过外部的以太交换机(ethernet switch)实现高速互联。也可以是其余任意一种加速卡支持的网络交换设备。更进一步的,这个网络交换设备可以连接更多的同构系统或加速卡,构建更大规模的多卡系统。数据分布更新产生的节点间的数据移动可以通过高速网络接口直接完成,也可以网络接口和内部总线同时进行。
45.各加速卡中的一个或多个具备对数据进行加密和/或压缩、解密和/或解压的功能。在本技术具体的应用场景中,如图6所示,当层级加速模块启用,从主机侧的存储介质中加载加密和/或压缩的数据库数据时,需要先由主加速卡完成数据的解压和/或解密后,再分发到各加速卡(包括主加速卡和从加速卡)。当结果数据需要存盘持久化时,各从加速卡将执行结果汇聚到主加速卡后,再经过主加速卡完成加密和/或压缩后,送往主机侧进行持久化存储。如图7所示,通过在一张从加速卡上部署远端存储访问功能,支持连接远端存储设备。如此时远端存储设备存储的为加密数据,则该从加速卡还需部署加密/解密功能,由
此完成对远端存储设备的支持。
46.本技术实施例还提出了一种层次化数据库操作加速方法,如图8所示,所述方法包括以下步骤:步骤s101,当接收到主机分配的与查询计划对应的查询操作时,基于层级加速模块中的多个加速卡执行各所述查询操作,所述层级加速模块中的多个加速卡包括一个主加速卡和至少一个从加速卡。
47.步骤s102,基于所述主加速卡向所述主机返回汇总执行结果,以使所述主机根据所述汇总执行结果确定与查询请求对应的结果数据。
48.其中,所述查询计划根据所述查询请求生成,所述查询操作包括由所述主加速卡执行的主查询操作和由所述从加速卡执行的从查询操作,所述汇总执行结果是所述主加速卡根据各所述从查询操作的执行结果执行所述主查询操作的结果。
49.为了提高查询操作的可靠性和效率,在本技术一些实施例中,基于层级加速模块中多个加速卡执行各所述查询操作,具体为:基于各所述加速卡根据从其他加速卡接收的数据、加速卡自身的内存中的数据、内存池中的数据、加速卡自身的存储器中的数据执行各所述查询操作;基于各所述加速卡将各所述查询操作的执行结果的部分或全部进行保存、发送给其他加速卡、返回所述主加速卡;其中,所述内存池由各所述加速卡内存和所述主机的主机内存按照缓存一致性协议生成。
50.为了提高数据查询的效率,在本技术一些实施例中,所述方法还包括:基于各所述从加速卡按预设周期向所述主加速卡发送自身的通告信息;以及,基于所述主加速卡根据所述通告信息更新各所述加速卡间的数据分布;其中,所述通告信息包括加速卡存储器的剩余容量和存储的数据内容、以及各所述从加速卡记录的各自节点数据块的热度和关联度。
51.为了进一步阐述本发明的技术思想,现结合具体的应用场景,对本发明的技术方案进行说明。
52.应用场景一主机接收到一个客户端的查询操作,以tpc
‑
h的测试的q7为例,该句sql如下:select supp_nation, cust_nation,l_year,sum(volume) as revenuefrom
ꢀꢀꢀꢀꢀꢀ
(
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
select
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
n1.n_name as supp_nation,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
n2.n_name as cust_nation,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
extract(year from l_shipdate) as l_year,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
l_extendedprice * (1
ꢀ‑ꢀ
l_discount) as volume
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
from
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
supplier, lineitem, orders, customer, nation n1, nation n2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
where
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
s_suppkey = l_suppkey
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
and o_orderkey = l_orderkey
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
and c_custkey = o_custkey
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
and s_nationkey = n1.n_nationkey
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
and c_nationkey = n2.n_nationkey
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
and (
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(n1.n_name = 'germany' and n2.n_name = 'egypt')
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
or (n1.n_name = 'egypt' and n2.n_name = 'germany')
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
and l_shipdate between date '1995
‑
01
‑
01' and date '1996
‑
12
‑
31'
ꢀꢀꢀꢀ
) as shippinggroup by
ꢀꢀꢀꢀ
supp_nation, cust_nation,l_yearorder by
ꢀꢀꢀꢀ
supp_nation, cust_nation,l_yearpostgresql输出的执行计划如图9所示。
53.主机将计划树转变匹配加速卡的查询操作,并依据加速卡的执行能信息,将如图10所示的执行计划树分配到多个加速卡上。
54.以图5的三张加速卡系统为例,假定依据当前数据分布信息(order表,customer表和nation表在主加速卡card1存储,lineitem在从加速卡card2存储,supplier在从加速卡card3存储,nation的一个副本也在从加速卡card3)和加速卡的执行能力(各加速卡都可执行扫描,连接,排序和汇聚操作),主机将图10的计划树分解为4个部分,如图11所示,其中主加速卡card1分配执行第四部分查询操作400,从加速卡card2分配执行第二部分查询操作200,从加速卡card3分配执行第三部分查询操作300,最后的第一部分查询操作100需要重新汇总到主加速卡card1执行,再由主加速卡card1返回最终结果给主机。
55.可以理解的是,第四部分查询操作400和第一部分查询操作100为主查询操作,第二部分查询操作200和第三部分查询操作300分别为从查询操作。
56.因此,当各加速卡接收到各自分配的执行操作后,主加速卡card1,从加速卡card2和从加速卡card3都开始读取各自本卡的存储数据,执行各自的扫描操作;主加速卡card1再执行完两步join连接操作后,将执行结果通过总线发送给从加速卡card2,则开始等待其汇总阶段的输入到来;从加速卡card2执行完扫描,并接收到主加速卡card1送来的执行结果后,开始执行join连接操作,执行完毕后,将结果发送给主加速卡card1;从加速卡card3执行完扫描和join连接操作后,将结果发送给主加速卡;主加速卡card1在接收到从加速卡card2和从加速卡card3返回的数据后,开始执行最终的操作,完成后将结果返回给主机。
57.应用场景二主机同时接收到两个客户端的查询操作,以tpc
‑
h的测试的q4和q14为例,q4的sql如下:
select
ꢀꢀ
o_orderpriority, count(*) as order_countfrom
ꢀꢀꢀꢀꢀꢀ
orderswhere
ꢀꢀꢀꢀ
o_orderdate >= date '1993
‑
10
‑
01'
ꢀꢀꢀꢀ
and o_orderdate < date '1993
‑
10
‑
01' interval '3' month
ꢀꢀꢀꢀ
and exists (select *
ꢀꢀꢀꢀ
from
ꢀꢀꢀ
lineitem
ꢀꢀꢀꢀ
where l_orderkey = o_orderkey and l_commitdate < l_receiptdate)group by o_orderpriorityorder by
ꢀꢀ
o_orderprioritypostgresql输出的执行计划如图12所示。
58.主机将执行计划转变为匹配加速卡的查询操作,得到执行计划树,如图13所示。
59.q14的sql如下:select
ꢀꢀ
100.00 * sum(case
ꢀꢀꢀꢀꢀ
when p_type like 'promo%'
ꢀꢀꢀꢀꢀꢀꢀꢀ
then l_extendedprice * (1
ꢀ‑ꢀ
l_discount)
ꢀꢀꢀꢀꢀ
else 0
ꢀꢀ
end) / sum(l_extendedprice * (1
ꢀ‑ꢀ
l_discount)) as promo_revenuefrom
ꢀꢀ
lineitem, partwhere
ꢀꢀ
l_partkey = p_partkey
ꢀꢀ
and l_shipdate >= date '1993
‑
09
‑
01'
ꢀꢀ
and l_shipdate < date '1993
‑
09
‑
01' interval '1' monthpostgresql输出的执行计划如图14所示。
60.主机将执行计划转变为匹配加速卡的查询操作,得到如图15所示的执行计划树。
61.以图5的三张加速卡系统为例,假定依据当前数据分布信息(part在从加速卡card2存储,order在从加速卡card3存储,lineitem表在从加速卡card2和从加速卡card3各有一部分存储)和加速卡的执行能力信息(各加速卡都可执行扫描,连接,排序和汇聚操作),主机将图13和图15的计划树分发:其中从加速卡card2分配执行图15的计划树,card3分配执行图13的计划树。
62.因此,当各卡接收到各自分配的执行操作后,主加速卡card1,从加速卡card2和从加速卡card3都开始准备执行各自的操作;从加速卡card2执行完扫描,并接收到从加速卡card3送来的部分数据,开始执行join连接操作,汇聚执行完毕后,将结果发送给主加速卡card1;从加速卡card3执行完扫描,并接收到从加速卡card2送来的部分数据,开始执行join连接操作,再排序汇聚后,将结果发送给主加速卡card1;主加速卡card1在接收到从加速卡card2和从加速卡card3返回的数据后,将两个执行结果返回给主机。
63.最后应说明的是:以上实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不驱使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
