1.本发明涉及人工智能领域,具体涉及一种应用于图像信号的提取高低层特征逻辑用于分类的深度学习方法。
背景技术:
2.分类是故障诊断、自动化、计算机视觉(cv)和自然语言处理(nlp)等多个领域的基本问题。深度学习一直是解决分类问题的有用工具。特征提取一直以来是卷积神经网络(cnn)模仿人类视觉的关键。cnn通过卷积核对输入图像进行特征提取。由于具备平移等变性以及分层表达的能力,cnn能够提取到更为深层的图像特征用于分类。之后,研究者利用跳跃连接对深层的cnn进行改进得到了残差神经网络resnet。这一模型解决了深层cnn存在的梯度消失、梯度弥散以及退化问题,使得神经网络具备了更强的特征提取能力。大脑中的生物树突被证明具有与\或\非的逻辑运算能力,能够计算输入信号之间的逻辑关系。现有模仿生物树突功能的模型是一种树突型网络(dd),该模型能够为逻辑抽取提供测度,随着层数的增加,dd能够构建更为复杂的逻辑关系。卷积树突网络(cdd)继承了dd的逻辑抽取和cnn的特征提取能力,弥补了dd无法进行特征提取,以及cnn无法进行逻辑提取的不足。因此,cdd更关注特征的组合并依靠特征之间的逻辑关系进行分类。目标检测领域中很多模型,如特征金字塔网络(fpn)、densnet、yolov3等都通过融合高低层特征来提高小物体的检测精度。图像分割领域中,高层语义分割结果保持了大量的语义结构,但是小结构丢失严重,低层特征的分割结果保留了大量的细节,但是语义类别预测的很差,因此通过对高底层特征融合,结合两者的优点获取了性能较好的语义分割模型。
3.目前仿照人类视觉感知能力已经有了上述的诸多尝试,但是仍然存在以下问题。传统神经网络模型无法做特征之间的逻辑提取。cdd虽然继承了dd与cnn的优点,但是cdd的特征提取层较浅,因而其特征提取能力较弱。另外,由于神经网络对特征的分层表达能力,无论是高层特征还是低层特征都包含了图像的大量信息,现有的分类网络只利用高层特征进行分类会丢失低层特征的大量信息。
技术实现要素:
4.本发明要解决的技术问题是,克服传统网络无法做特征之间的逻辑提取,卷积树突网络(cdd)的特征提取能力较弱以及现有神经网络无法组合高底层特征的问题,提供用于图像分类的基于提取高低层特征逻辑的深度学习方法,采用精心设计的架构,将传统网络鲁棒性较好的特征提取模块与cdd模块相结合,提取并组合高底层图像特征,最后依靠特征之间的逻辑关系进行分类。该方法主要运用于图像分类领域,能够提高所有的只通过提取图像特征用于分类的传统模型的分类精度,具有分类精度高、收敛速度快、鲁棒性好等优点。
5.本发明解决其技术问题所采用的技术方案为:一种用于图像分类的基于提取高低
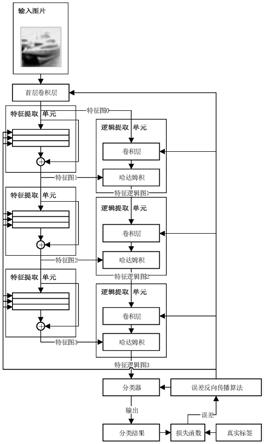
层特征逻辑的深度学习方法,其特征在于,由特征提取网络以及逻辑网络组成,特征提取网络由若干个特征提取单元串联得到,逻辑网络由若干个逻辑提取单元串联得到,特征提取单元为卷积层或残差块,逻辑提取单元为由卷积层和哈达姆积组成的卷积树突模块,各个单元之间的连接关系为,本层特征提取单元的输入是上级特征提取单元的输出,本层逻辑提取单元的输入是上一级逻辑提取单元的输出和本层特征提取单元的输出,特征提取网络是单输入多输出的,作用是提取从低到高各个层次的图像特征,输入为需要分类的图像,输出为各个层次的特征图,逻辑网络是多输入单输出的,作用是构造高底层图像特征之间的逻辑关系并根据逻辑关系分类,输入是各个层次的特征图,输出为分类结果,具体包括如下步骤:
6.步骤1、将带有图像标签的输入图像送入首层卷积层进行维度变换和初步特征提取得到特征图0;
[0007][0008]
式中,为特征图0,x
in
为输入图像,w
first
为首层卷积层的权重矩阵,为卷积;
[0009]
步骤2、将特征图0送入特征提取单元1经过特征提取后得到特征图1;
[0010][0011]
式中,为特征图0,x
f1
为特征图1,w
f1
为特征提取单元1的权重矩阵,w
s1
为特征提取单元1中跳跃连接中的线性映射权重矩阵,f(
·
)为非线性激活函数,为卷积;
[0012]
步骤3、将特征图0和特征图1同时送到逻辑提取单元1,经过高低层特征逻辑组合后,得到特征逻辑图1;
[0013][0014]
式中,为特征逻辑图1,为特征图0,x
f1
为特征图1,为逻辑提取单元1的权重矩阵,为卷积,
○
为哈达姆积;
[0015]
步骤4、将特征图1送入特征提取单元2经过特征提取后得到特征图2;
[0016][0017]
式中,x
f1
为特征图1,为特征图2,为特征提取单元2的权重矩阵,w
s2
为特征提取单元2中跳跃连接中的线性映射权重矩阵,f(
·
)为非线性激活函数,为卷积;
[0018]
步骤5、将特征逻辑图1和特征图2同时送入逻辑提取单元2,经过高低层特征逻辑组合后,得到特征逻辑图2;
[0019][0020]
式中,为特征逻辑图1,为特征逻辑图2,x
f1
为特征图1,x
f2
为特征图2,为逻辑提取单元2的权重矩阵,为卷积,
○
为哈达姆积;
[0021]
步骤6、继续利用下一层特征提取单元提取更高层次的特征以及下一层逻辑提取单元对高低层特征进行逻辑组合,直至得到最高层次的特征逻辑图,递推公式表示为:
[0022][0023]
[0024]
式中,k为层标记(k=2,3,
…
),为特征图k
‑
1,为特征图k,为特征逻辑图k
‑
1,为特征逻辑图k,为特征提取单元k的权重矩阵,w
sk
为特征提取单元k中跳跃连接中的线性映射权重矩阵,为逻辑提取单元2的权重矩阵,f(
·
)为非线性激活函数,为卷积;
[0025]
步骤7、将最高层的特征逻辑图重整为一维张量并送入分类器,分类器根据最高层次的特征逻辑得到图像的分类结果;
[0026][0027]
式中,x
out
为分类结果,为最高层的特征逻辑图,w
fc
为分类器中全连接层的权重矩阵,reshape(
·
)表示将变量重整为一维张量;
[0028]
步骤8、将分类结果与图像标签作对比,计算分类误差,利用误差反向传播算法调节首层卷积层、各个特征提取单元以及逻辑提取单元的权重多次迭代后得到最优的图像分类模型;
[0029]
e=l(x
lab
,x
out
)
[0030][0031]
式中,x
out
为分类结果,x
lab
为图像标签,e为分类误差,w
*
为模型中的所有权重,w
*’为经过误差反向传播算法调节后模型的所有权重,l(
·
)为损失函数,η为学习率;
[0032]
步骤9、使用最优的图像分类模型对不带有图像标签的输入图像进行分类,得到输入图像所属的类别。
[0033]
进一步的,将步骤3的所述公式展开,可以得到特征逻辑图1包含了特征图0和特征图1之间所有可能的特征逻辑组合;
[0034][0035][0036]
[0037]
式中,为特征逻辑图1,为特征图0,x
f1
为特征图1,为逻辑提取单元1的权重,f
ij0
为特征图0的图像特征,f
ij1
为特征图1的图像特征,与逻辑f
ij0
·
f
ij1
,或逻辑f
ij0
f
ij1
、非逻辑
‑
f
ij*
,为逻辑提取单元1的权重,其中i,j为矩阵下标(i=1,2,
…
,n;j=1,2,
…
,m),n为图像的长度,m为图像的宽度,*代表任意层,为卷积,
○
为哈达姆积,(padding=1,stap=1)表示对图像周围做一个像素的填充且卷积步长为1。
[0038]
进一步的,使用步骤6所述递推公式,可以获得所有高低层特征之间的特征逻辑组合,再通过误差反向传播算法调节逻辑组合前的权重,即可获取对分类精度有贡献的高低层特征逻辑关系。
[0039]
本发明的原理是:传统的分类网络能够提取到鲁棒性较好的图像特征用于分类,但是其忽略了特征之间潜在的逻辑关系。同时只依靠高层特征进行分类的方式,也忽略了低层特征中蕴含的大量细节特征。因此本发明通过精心设计的架构,将传统网络鲁棒性较好的特征提取模块与cdd模块相结合,提取并组合高底层图像特征,最后依靠特征之间的逻辑关系进行分类。
[0040]
本发明与现有技术相比的优点在于:
[0041]
与只通过提取图像特征用于分类的传统模型(如resnet、wrn等)相比的优点为:本发明考虑了高底层特征之间的逻辑关系,分类精度和收敛速度都显著提升;与依靠特征之间的逻辑关系进行分类的cdd网络相比的优点为:具备了更强的特征提取能力,能够提取到更高层次的图像特征,因此模型更为鲁棒。
附图说明
[0042]
图1是本发明的流程图。
具体实施方式
[0043]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合说明书附图进一步详细说明本发明的示例性实施方式。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0044]
前述技术方案中所涉及的分类目标可为任意维度和大小的张量,为了说明本发明的一种提取高低层特征逻辑用于分类的深度学习方法,下面采用本发明构建一个完整的图像分类模型,对两个开源数据集cifar10和cifar100的图像信号进行分类,并与仅依靠高层特征进行分类的两种传统模型(resnet,wrn)在同一框架下对比。并将本发明应用于resnet的模型叫做resnet
‑
cdd,应用于wrn的模型叫做wrn
‑
cdd。
[0045]
如图1所示,本发明由特征提取单元和逻辑提取单元组成。根据cifar10和cifar100数据的中图像的尺寸大小,将输入数据替换为3
×
32
×
32的张量,然后将图像张量化后送入模型,再按照上述步骤1到8对模型进行训练,经过多次迭代后即可得到最优的分类模型。整个提取特征以及获取有益特征逻辑组合的过程,均以减小误差为目标,以误差反向传播算法为方法自动进行迭代优化,不需要人工参与。模型预测分类过程为步骤1到7。由于模型内部的各类权重已经被训练集中的大量数据调整和优化,因此测试集中的图像信号
经过模型得到的输出与图像标签之间的误差,同样会在允许范围内。
[0046]
表1、表2、表3和表4所示,为在两个开源数据集cifar10和cifar100上,将本发明与仅依靠高层特征进行分类的两种传统模型(resnet,wrn)在同一框架下对比,将本发明应用于resnet的模型叫做resnet
‑
cdd,应用于wrn的模型叫做wrn
‑
cdd。
[0047]
从表1、表2、表3和表4中可以看出如下现象:在分类难度较小的cifar10数据集上,当原模型较小(层数或宽度或者参数量较小,即特征提取能力较弱)时,本发明对原模型的精度提升较大,当模型逐渐变大时(即特征提取能力逐渐增强)时,原模型的精度逐渐达到了本发明的精度水平。而当在分类难度较大的cifar100数据集上,本发明都对原模型有较大的提升,并且也呈现一种随着原模型从小变大(即原模型的特征提取能力从若变强),本发明对原模型的提升从大变小的趋势。
[0048]
表1本发明(resnet
‑
cdd)与原模型(resnet)在cifar10数据集的对比实验结果
[0049][0050]
表2本发明(resnet
‑
cdd)与原模型(resnet)在cifar100数据集的对比实验结果
[0051][0052]
表3本发明(wrn
‑
cdd)与原模型(wrn)在cifar10数据集的对比实验结果
[0053][0054]
表4本发明(wrn
‑
cdd)与原模型(wrn)在cifar100数据集的对比实验结果
[0055][0056]
首先,从上述中可以看到本发明的精度更高、收敛速度更快、以及鲁棒性更好的优点。其次,本发明能够极大地增强特征提取能力较弱的分类模型,这符合人类的视觉特点,实际上人类的只需通过提取一些低层次的图像特征(如,轮廓、纹理、色彩等),然后再经过大脑的逻辑组合即可实现高精度分类,并且人类不会局限于只对同一层次的特征进行逻辑组合,而是组合可利用的所有高底层特征。同时也要说明,如果被识别对象比较简单,仅仅需要几个简单的特征即可区分,那人类视觉也不需要通过特征之间的逻辑组合进行分类,这解释了原模型在cifar10数据集上能够达到与本发明同等水平的分类精度。
[0057]
本发明说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
[0058]
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
