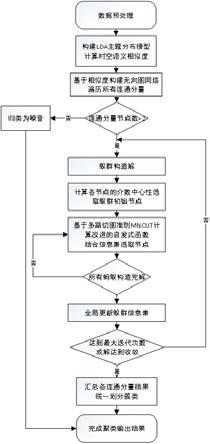
一种基于多路切图准则和蚁群优化的od流向聚类方法
技术领域
1.本发明涉及城市交通数据挖掘分析领域,特别是一种基于多路切图准则和蚁群优化的od流向聚类方法。
背景技术:
2.交通流是城市综合系统中的重要组成部分,蕴含着丰富的潜在信息,在一定程度上反映城市的空间分布规律、区域关联特征、居民出行特征等。因此挖掘并分析交通流向数据的特点,对于探索城市潜在规律,为城市管理提供建议具有重要意义。
3.聚类算法是挖掘交通流向数据较为主流的方法,属于无监督学习算法,通过聚类将具有相同特征的流向划分为同一簇类,发现数据的共同特点和隐含特征。od流向数据聚类,根据聚类对象的不同分为针对轨迹点的聚类和针对od流向整体的聚类。基于轨迹点的聚类主要有:基于共享邻居数的空间点聚类算法、基于交通网格的空间数据点聚类算法。针对od流向整体的聚类主要有:有基于扫描统计的聚类方法、基于流密度域分解的任意形状流聚类方法、基于最小生成树和最优分割的流聚类等。常见od流向聚类方法往往忽略了整体流向属性,全局聚类效果有待提高,缺少针对流向的语义信息的衡量。
4.谱聚类算法基于图论思想,将聚类问题转化为无向图的分割问题,通过优化切图准则实现聚类。目前主流算法以迭代二分切图为主,多路切图准则相较于二分切图准则更符合实际情况也更为细致客观。蚁群算法是模拟蚂蚁行为的启发式算法,它由多个独立蚂蚁通过信息素的积累实现相互协作从而表现出群体智能,具有启发式搜索、分布计算、信息正反馈等特点,从而实现对复杂问题的全局优化,对于np问题求解有重要意义。
技术实现要素:
5.有鉴于此,本发明的目的是提供一种基于多路切图准则和蚁群优化的od流向聚类方法,基于多路切图准则改进了启发式函数,并基于复杂网络思想利用介数中心性筛选蚁群初始节点,有效改善聚类效果。
6.本发明采用以下方案实现:一种基于多路切图准则和蚁群优化的od流向聚类方法,包括以下步骤:
7.步骤s1:去除od流向数据和poi(兴趣点)数据中的重复值、错误值、无意义值,利用mongodb构建od流向库,利用2dsphere indexes建立空间索引;
8.步骤s2:建立流向终点缓冲区,选择缓冲区中的poi点,基于poi数据调用python gensim工具库构建主题分布模型,在此基础上计算语义相似度,并计算od流向空间、时间相似度,最终得到流向时空语义相似度;
9.步骤s3:基于时空语义相似度构建od流向初始无向图复杂网络,提取所有连通分量,利用连通分量识别出噪音和有待聚类的连通分量;
10.步骤s4:基于多路切图准则设计改进启发式函数,结合蚁群信息素正反馈作用,对有待聚类的连通分量,采用多进程并行的方式,一个进程对一个连通分量进行聚类;
11.步骤s5:汇总步骤s4中各进程的聚类结果,得到最终聚类结果。
12.进一步地,所述步骤s2具体包括以下步骤:
13.步骤s21:根据流向终点建立半径250米的圆形缓冲区,搜索缓冲区内的所有poi点;
14.步骤s22:根据流向编号,将每条流向对应的poi点的类型字段值汇总为一个文档,该文档即为该流向对应的poi语义文档,再将所有流向的语义文档汇总建立语料库,利用语料库调用python gensim工具库对lda主题分布模型进行训练,训练获得语料—主题分布,再将流向语料输入模型进行预测,得到主题—流向,即流向的主题概率分布;
15.步骤s23:根据主题概率分布计算js散度,将js散度作为语义相似度度量,流向i与流向j的语义相似度计算公式如下:
[0016][0017][0018]
其中,p
i
、p
j
分别为流向i、j的主题概率分布;p
i
(x)、p
j
(x)分别为流向i,j中x主题的主题概率分布值;
[0019]
步骤s24:计算流向的空间相似度sim
dis
及时间相似度sim
t
;
[0020]
步骤s25:利用高斯核函数对流向语义、时间和空间相似度进行映射,得到od流向时空语义相似度,计算公式如下:
[0021][0022]
进一步地,所述步骤s3具体包括以下步骤:
[0023]
步骤s31:以流向为网络节点,以两两流向之间的od流向时空语义相似度为边的权重,使用networkx建立无向图复杂网络,提取所有连通分量;
[0024]
步骤s32:根据连通分量的节点数划分分量;小于阈值的归类为噪音分量;大于阈值则归类为待聚类的连通分量。
[0025]
进一步地,所述步骤s4具体包括以下步骤:
[0026]
步骤s41:采用多进程并行的方式,一个进程对一个连通分量进行聚类,每个进程均执行步骤s42
‑
步骤s48;
[0027]
步骤s42:根据连通分量的节点个数,建立维度为n*n的初始信息素矩阵,信息素初始值均为1;
[0028]
步骤s43:计算连通分量中每个节点的介数中心性,根据中心性值大小排序,选取前k个点为蚂蚁的初始位置,开始搜索;中心性计算公式如下:
[0029]
[0030]
其中,表示经过节点i,且为最短路径的路径数量;g
st
表示连接s和t的最短路径的数量;
[0031]
步骤s44:获取蚂蚁所在节点的邻接节点,判断邻接节点是否在禁忌表中,若不在禁忌表中,将该节点加入备选节点列表;
[0032]
步骤s45:遍历备选节点列表,计算基于多路切图准则改进的启发式函数n
ij
(t),并结合信息素pher
ij
(t),计算节点被选取概率在t时刻下,处于结点i的蚂蚁k选择结点j作为下一个结点的概率的计算公式如下:
[0033][0034][0035][0036]
其中,pher
ij
(t)为信息素因子;n
ij
(t)为启发式函数;sim
ij
为流向时空语义相似度;mncut
(k,ij)
(t)为t时刻选择j节点的多路切图因子;cut(a
(k)
,v
‑
a
(k)
)为a
(k)
类内节点与其他类内节点邻接边的权值之和;assoc(a
(k)
)为a
(k)
类各节点间邻接边的权值之和;
[0037]
步骤s46:依据各备选节点的选取概率,采取轮盘赌方式选择下一节点,同时将选取节点加入禁忌表中;
[0038]
步骤s47:根据蚂蚁选取的节点,进行信息素更新,信息素的更新方程如下:
[0039][0040]
其中,ε为信息素挥发率;为t时刻第k只蚂蚁在ij的边上增加的信息素浓度;c
k
(t)为t时刻第k只蚂蚁所经过边的时空语义相似度;
[0041]
步骤s48:所有蚂蚁无可选节点时,该轮迭代结束,进入下一轮迭代;直到结果收敛或达到最大迭代次数结束迭代。
[0042]
进一步地,所述步骤s5具体包括以下步骤:
[0043]
步骤s51:将步骤s4中各进程聚类得到的结果进行汇总,合并为一个结果列表;
[0044]
步骤s52:遍历结果列表,统一输出类别编号,用以避免类别编号重复。
[0045]
与现有技术相比,本发明具有以下有益效果:
[0046]
1、本发明有效提取了流向语义信息,并结合时间相似度、空间相似度计算了时空语义相似度,更为全面地衡量了流向的相似度。
[0047]
2、本发明将无向图复杂网络思想与聚类算法有机结合,采用高斯核函数进行复杂网络简化,利用图连通分量实现噪音自动识别。
[0048]
3、本发明基于多路切图准则改进了启发式函数,并基于复杂网络思想利用介数中心性筛选蚁群初始节点,有效改善聚类效果。
附图说明
[0049]
图1为本发明实施例的方法流程示意图。
[0050]
图2为本发明实施例的所建复杂网络的部分连通分量示意图。
[0051]
图3为本发明实施例的原始流向图。
[0052]
图4为本发明实施例的部分聚类结果。
具体实施方式
[0053]
下面结合附图及实施例对本发明做进一步说明。
[0054]
应该指出,以下详细说明都是例示性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
[0055]
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
[0056]
如图1所示,本实施例提供一种基于多路切图准则和蚁群优化的od流向聚类方法,包括以下步骤:
[0057]
步骤s1:去除od流向数据和poi(兴趣点)数据中的重复值、错误值、无意义值,利用mongodb构建od流向库,利用2dsphere indexes建立空间索引;
[0058]
步骤s2:建立流向终点缓冲区,选择缓冲区中的poi点,基于poi数据调用python gensim工具库构建主题分布模型,在此基础上计算语义相似度,并计算od流向空间、时间相似度,最终得到流向时空语义相似度;
[0059]
步骤s3:基于时空语义相似度构建od流向初始无向图复杂网络,提取所有连通分量,利用连通分量识别出噪音和有待聚类的连通分量;
[0060]
步骤s4:基于多路切图准则设计改进启发式函数,结合蚁群信息素正反馈作用,对有待聚类的连通分量,采用多进程并行的方式,一个进程对一个连通分量进行聚类;
[0061]
步骤s5:汇总步骤s4中各进程的聚类结果,得到最终聚类结果。
[0062]
在本实施例中,所述步骤s2具体包括以下步骤:
[0063]
步骤s21:根据流向终点建立半径250米的圆形缓冲区,搜索缓冲区内的所有poi点;
[0064]
步骤s22:根据流向编号,将每条流向对应的poi点的类型字段值汇总为一个文档,该文档即为该流向对应的poi语义文档,再将所有流向的语义文档汇总建立语料库,利用语料库调用python gensim工具库对lda主题分布模型进行训练,训练获得语料—主题分布,再将流向语料输入模型进行预测,得到主题—流向,即流向的主题概率分布;
[0065]
步骤s23:根据主题概率分布计算js散度,将js散度作为语义相似度度量,流向i与流向j的语义相似度计算公式如下:
[0066]
[0067][0068]
其中,p
i
、p
j
分别为流向i、j的主题概率分布;p
i
(x)、p
j
(x)分别为流向i,j中x主题的主题概率分布值;
[0069]
步骤s24:计算流向的空间相似度sim
dis
及时间相似度sim
t
;
[0070]
步骤s25:利用高斯核函数对流向语义、时间和空间相似度进行映射,得到od流向时空语义相似度,计算公式如下:
[0071][0072]
在本实施例中,所述步骤s3具体包括以下步骤:
[0073]
步骤s31:以流向为网络节点,以两两流向之间的od流向时空语义相似度为边的权重,使用networkx建立无向图复杂网络,提取所有连通分量;
[0074]
步骤s32:根据连通分量的节点数划分分量;小于阈值的归类为噪音分量;大于阈值则归类为待聚类的连通分量。在本实施例中,阈值为2。
[0075]
在本实施例中,所述步骤s4具体包括以下步骤:
[0076]
步骤s41:采用多进程并行的方式,一个进程对一个连通分量进行聚类,每个进程均执行步骤s42
‑
s48。
[0077]
步骤s42:根据连通分量的节点个数,建立维度为n*n的初始信息素矩阵,信息素初始值均为1;
[0078]
步骤s43:计算连通分量中每个节点的介数中心性,根据中心性值大小排序,选取前k个点为蚂蚁的初始位置,开始搜索;中心性计算公式如下:
[0079][0080]
其中,表示经过节点i,且为最短路径的路径数量;g
st
表示连接s和t的最短路径的数量;
[0081]
步骤s44:获取蚂蚁所在节点的邻接节点,判断邻接节点是否在禁忌表中,若不在禁忌表中,将该节点加入备选节点列表;
[0082]
步骤s45:遍历备选节点列表,计算基于多路切图准则改进的启发式函数n
ij
(t),并结合信息素pher
ij
(t),计算节点被选取概率在t时刻下,处于结点i的蚂蚁k选择结点j作为下一个结点的概率的计算公式如下:
[0083]
[0084][0085][0086]
其中,pher
ij
(t)为信息素因子;n
ij
(t)为启发式函数;sim
ij
为流向时空语义相似度;mncut
(k,ij)
(t)为t时刻选择j节点的多路切图因子;cut(a
(k)
,v
‑
a
(k)
)为a
(k)
类内节点与其他类内节点邻接边的权值之和;assoc(a
(k)
)为a
(k)
类各节点间邻接边的权值之和;
[0087]
步骤s46:依据各备选节点的选取概率,采取轮盘赌方式选择下一节点,同时将选取节点加入禁忌表中;
[0088]
步骤s47:根据蚂蚁选取的节点,进行信息素更新,信息素的更新方程如下:
[0089][0090]
其中,ε为信息素挥发率;为t时刻第k只蚂蚁在ij的边上增加的信息素浓度;c
k
(t)为t时刻第k只蚂蚁所经过边的时空语义相似度;
[0091]
步骤s48:所有蚂蚁无可选节点时,该轮迭代结束,进入下一轮迭代;直到结果收敛或达到最大迭代次数结束迭代。
[0092]
在本实施例中,所述步骤s5具体包括以下步骤:
[0093]
步骤s51:将步骤s4中各进程聚类得到的结果进行汇总,合并为一个结果列表;
[0094]
步骤s52:遍历结果列表,统一输出类别编号,用以避免类别编号重复。
[0095]
较佳的,本实施例利用流向终点poi构建主题分布模型,计算流向时空语义相似度,构建无向图复杂网络及初始信息素矩阵,提取网络所有连通分量,识别待聚类连通分量,基于多路切图准则和蚁群优化对待聚类的连通分量采用多线程/多进程的蚁群算法进行并行聚类,实现od流向聚类。
[0096]
较佳的,本实施例以厦门市出租车od流向数据和厦门市poi数据为例,本实施例的基于多路切图准则和蚁群优化的od流向聚类方法的相关参数如表1所示:
[0097][0098][0099]
具体包括以下步骤:
[0100]
步骤s1:去除od流向数据和poi(兴趣点)数据中的重复值、错误值、无意义值,利用mongodb构建od流向库,利用2dsphere indexes建立空间索引;
[0101]
步骤s2:建立流向终点缓冲区,选择缓冲区中的poi,基于poi数据调用python gensim工具库构建主题分布模型,在此基础上计算语义相似度,计算od流向空间、时间相似度,最终得到流向时空语义相似度;
[0102]
步骤s3:基于时空语义相似度构建od流向初始无向图复杂网络,提取所有连通分量,利用连通分量识别出噪音和有待聚类的连通分量;
[0103]
步骤s4:基于多路切图准则设计改进启发式函数,结合蚁群信息素正反馈作用,对有待聚类的连通分量,采用多进程并行的方式,一个进程对一个连通分量进行聚类;
[0104]
步骤s5:汇总步骤s4中各进程的聚类结果,得到最终聚类结果。
[0105]
步骤s2具体步骤为:
[0106]
步骤s21:根据流向终点建立半径250米的圆形缓冲区,搜索缓冲区内的所有poi点。
[0107]
步骤s22:根据流向编号,将每条流向对应的poi点的类型字段值汇总为一个文档,该文档即为该流向对应的poi语义文档,再将所有流向的语义文档汇总建立语料库,利用语料库对lda主题分布模型进行训练,训练获得厦门od流向的“语料—主题”分布,再将流向语料输入模型进行预测,得到“主题—流向”,即厦门od流向的主题概率分布。这里本实例根据数据的特点进行了模型训练,获得了工作通勤、旅游出行、购物出行、休闲娱乐、就医出行等十类较为有代表性的出行主题。如下表所示:
[0108][0109]
步骤s23:根据主题概率分布计算js散度,将js散度作为语义相似度度量,流向i与流向j的语义相似度计算公式如下:
[0110][0111][0112]
其中,p
i
、p
j
分别为流向i、j的主题概率分布;p
i
(x)、p
j
(x)分别为流向i,j中x主题的主题概率分布值;
[0113]
步骤s24:流向的空间相似度sim
dis
及时间相似度sim
t
引用现有技术中提及的方法
进行计算;
[0114]
步骤s25:利用高斯核函数对流向语义、时间和空间相似度进行映射,得到od流向时空语义相似度,计算公式如下:
[0115][0116]
如图2所示,步骤s3的具体步骤为:
[0117]
步骤s31:以流向为网络节点,以两两流向之间的od流向时空语义相似度为边的权重,使用networkx建立无向图复杂网络,计算所有连通分量。
[0118]
步骤s32:根据连通分量的节点数划分分量。小于阈值2的归类为噪音分量;大于阈值则归类为待聚类的连通分量。
[0119]
如图3、4所示,步骤s4具体包括以下步骤:
[0120]
步骤s41:采用多进程并行的方式,一个进程对一个连通分量进行聚类,每个进程均执行步骤s42
‑
s48。
[0121]
步骤s42:根据连通分量的节点个数,建立维度为n*n的初始信息素矩阵,信息素初始值均为1;
[0122]
步骤s43:计算连通分量中每个节点的介数中心性,根据中心性值大小排序,选取前k个点为蚂蚁的初始位置,开始搜索;中心性计算公式如下:
[0123][0124]
其中,表示经过节点i,且为最短路径的路径数量;g
st
表示连接s和t的最短路径的数量;
[0125]
步骤s44:获取蚂蚁所在节点的邻接节点,判断邻接节点是否在禁忌表中,若不在禁忌表中,将该节点加入备选节点列表;
[0126]
步骤s45:遍历备选节点列表,计算基于多路切图准则改进的启发式函数n
ij
(t),并结合信息素pher
ij
(t),计算节点被选取概率在t时刻下,处于结点i的蚂蚁k选择结点j作为下一个结点的概率的计算公式如下:
[0127][0128][0129][0130]
其中,pher
ij
(t)为信息素因子;n
ij
(t)为启发式函数;sim
ij
为流向时空语义相似度;mncut
(k,ij)
(t)为t时刻选择j节点的多路切图因子;cut(a
(k)
,v
‑
a
(k)
)为a
(k)
类内节点与其
他类内节点邻接边的权值之和;assoc(a
(k)
)为a
(k)
类各节点间邻接边的权值之和;
[0131]
步骤s46:依据各备选节点的选取概率,采取轮盘赌方式选择下一节点,同时将选取节点加入禁忌表中;
[0132]
步骤s47:根据蚂蚁选取的节点,进行信息素更新,信息素的更新方程如下:
[0133][0134]
其中,ε为信息素挥发率;为t时刻第k只蚂蚁在ij的边上增加的信息素浓度;c
k
(t)为t时刻第k只蚂蚁所经过边的时空语义相似度;
[0135]
步骤s48:所有蚂蚁无可选节点时,该轮迭代结束,进入下一轮迭代;直到结果收敛或达到最大迭代次数结束迭代,如图4所示,交通出行部分聚类结果。
[0136]
步骤s5具体为:
[0137]
步骤s51:将步骤s4中各进程聚类得到的结果进行汇总,合并为一个结果列表。
[0138]
步骤s52:遍历结果列表,统一输出类别编号,避免类别编号重复。以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

