一种筛选pid控制回路中数据的方法和系统辨识方法
技术领域
1.本发明涉及工业自动化控制技术领域,尤其涉及一种筛选pid控制回路中数据的方法和系统辨识方法。
背景技术:
2.在我国,实际工业现场还存在大量的回路采用的是人工控制。其中pid控制(比例积分微分控制)是一种很常见的回路控制,降低回路pid参数的整定难度,提供经济实惠的模型预测控制(mpc)方案,是提高我国过程工业自动化的重要方法,也是当前我国工业自动化公司的重要使命。系统辨识是mpc的关键步骤,同时也是pid参数整定的一种重要方法。
3.系统辨识要求数据是充分激励的。在以往的系统辨识中,常常需要进行激励实验,导致回路的正常运行受到干扰,降低了工厂的效益。而实际上,工厂储存了大量的回路运行历史数据,虽然历史数据中包含各种异常段、平稳段等,但是仍然存在能反映过程真实动态变化的数据段,而这些数据段可用于系统辨识。如果能够从历史数据中,自动筛选出充分激励的数据段,那么将显著降低模型预测控制、pid参数整定等的成本,提高工厂经济效益。
4.因此,亟需一种筛选pid控制回路中数据的方法和系统辨识方法,能够从回路历史运行数据中自动筛选出适合于系统辨识的数据段。
技术实现要素:
5.(一)要解决的技术问题
6.鉴于上述技术中存在的问题,本发明至少从一定程度上进行解决。为此,本发明的一个目的在于提出了一种筛选pid控制回路中数据的方法,能够从pid控制回路的历史运行数据中自动筛选出充分激励的数据段。
7.本发明的第二个目的在于提出一种系统辨识方法,使辨识获得的模型精度高,数值计算可靠。
8.本发明的第三个目的在于提出一种计算机设备。
9.(二)技术方案
10.为了达到上述目的,本发明一方面提供一种筛选pid控制回路中数据的方法,包括:
11.获取pid控制回路的历史运行数据;运行数据包括每一时刻pid控制回路的输入,输出,设定值,开闭环状态。
12.对历史运行数据进行预处理,获得预处理后的运行数据。
13.根据pid控制回路的开闭环状态,对预处理后的运行数据进行分割,获得多个开环数据段和多个闭环数据段。
14.基于开环数据激励段检测策略,根据每一个开环数据段中输入值的变化和输入值变化后引起的输出变化,从每一个开环数据段中筛选出激励数据段;基于闭环数据激励段检测策略,根据每一个闭环数据段中设定值的变化和设定值变化后引起的输出变化,从每
一个闭环数据段中筛选出激励数据段。
15.可选地,基于开环数据激励段检测策略,根据每一个开环数据段中输入值的变化和输入值变化后引起的输出变化,从每一个开环数据段中筛选出激励段数据,包括:根据每一个开环数据段中输入值的变化梯度δu(t),筛选出满足|δu(t)|>c
u
r
u
的目标输入值变化梯度;根据稳态段判断标准检测每一个开环数据段中发生目标输入值变化梯度后引起的输出变化,若所述输出变化中存在稳态段,则将所述输出变化到达稳态段之前对应的运行数据作为激励段数据,若所述输出变化中不存在稳态段,则将所述输出变化对应的运行数据作为激励段数据。
16.基于闭环数据激励段检测策略,根据每一个闭环数据段中设定值的变化和设定值变化后引起的输出变化,从每一个闭环数据段中筛选激励段数据,包括:根据每一个闭环数据段中设定值的变化梯度δr(t),筛选出满足|δr(t)|>c
r
r
y
的目标设定值变化梯度;根据稳态段判断标准检测每一个闭环数据段中发生目标设定值变化梯度后引起的输出变化,若输出变化中存在稳态段,则将输出变化到达稳态段之前对应的运行数据作为激励段数据,若输出变化中不存在稳态段,则将输出变化对应的运行数据作为激励段数据。
17.其中,稳态段判断标准为|δy(t)|<c
y
r
y
,δy(t)为输出值的变化梯度,c
y
为第四阈值,r
y
为r时刻输出值y(t)的量程;c
u
为第三阈值,r
u
为t时刻输入值u(t)的量程;c
r
为第六阈值。
18.可选地,对历史运行数据进行预处理,包括:对历史运行数据中的缺失数据进行剔除处理;对历史运行数据中的异常峰值进行处理。
19.可选地,对历史运行数据中的缺失数据进行剔除处理,包括:基于数据剔除策略s(t)=s
u
(t)∩s
y
(t)∩s
r
(t),检测历史运行数据中每一时刻的运行数据,剔除s(t)=0的运行数据;根据历史运行数据剔除处理后形成的数据段,生成多个有效数据段。
20.其中,s
u
(t)为t时刻输入值u(t)的状态码,如果u(t)缺失,则s
u
(t)=0,否则s
u
(t)=1;s
y
(t)为t时刻输出值y(t)的状态码,如果y(t)缺失,则s
y
(t)=0,否则s
y
(t)=1;s
r
(t)为r时刻设定值r(r)的状态码,如果r(t)缺失,则s
r
(t)=0,否则s
r
(t)=1;s(t)为t时刻运行数据的状态码,符号∩表示且运算,只有当s
u
(t)、s
y
(t)、s
r
(t)都等于1时,s(t)=1,否则s(t)=0。
21.可选地,根据历史运行数据剔除处理后形成的数据段,生成多个有效数据段,包括:根据历史运行数据剔除处理后形成的数据段,将间距小于第一阈值的相邻数据段间的缺失数据进行线性插值,形成新的数据段;检测每一个数据段的长度,剔除长度小于第二阈值的数据段,生成多个有效数据段。
22.可选地,对历史运行数据中的异常峰值进行处理,包括:对每一个有效数据段进行异常峰值初处理,获得每一个初处理数据段。
23.其中异常峰值初处理包括:计算每一个有效数据段中u(t)的平均值和标准差σ
u
,以及y(t)的平均值和标准差σ
y
;根据筛选出每一个有效数据段中u(t)的异常峰值;根据筛选出每一个有效数据段中y(t)的异常峰值;根据每一个有效数据段中异常峰值邻近的数据对该异常峰值进行插值处理。
24.对每一个初处理数据段进行异常峰值再处理,获得每一个再处理数据段。
25.其中异常峰值再处理包括:采用半窗口大小为p的中值滤波算法对每个初处理数据段进行滤波,获得每一个滤波数据段;根据每个初处理数据段及其对应的滤波数据段,计算两者之间的u(t)差值和y(t)差值,获得每一个差值δu(t)数据段和每一个差值δy(t)数据段;计算每一个差值δu(t)数据段的平均值和标准差σ
δu
,以及计算每一个差值δy(r)数据段的平均值和标准差σ
δy
;根据筛选出每一个差值δu(t)数据段中δu(t)的异常峰值;根据筛选出每一个差值δy(t)数据段的异常峰值;根据每一个差值δu(t)数据段中异常峰值邻近的数据对该异常峰值进行插值处理,根据每一个差值δy(t)数据段中异常峰值邻近的数据对该异常峰值进行插值处理。
26.本发明第二方面提供一种系统辨识方法,包括:
27.采用如上所述的方法获取激励数据段。
28.采用高阶arx模型对激励数据段进行辨识,获得高阶过程模型。
29.采用morsm方法对高阶过程模型进行降阶处理,获得第一低阶过程模型。
30.根据阻尼高斯牛顿法和第一低阶过程模型求解高阶过程模型的渐近负对数似然函数最小化时对应的低阶过程模型,获得第二低阶过程模型,将第二低阶过程模型作为pid回路模型。
31.可选地,高阶辨识模型的渐近负对数似然函数为:
[0032][0033]
其中,m为考虑的频率离散点数;n
s
为激励数据段的总数;为激励数据段的总数;φ
u
(ω)、φ
v
(ω)分别为输入u(t)、扰动项h(q)e(t)的自谱,φ
ue
(ω)为输入u(t)与白噪声e(t)的互谱,r表示arx模型的方程误差,即a(q)y(t)
‑
b(q)u(t)的估计方差;是高阶过程模型的频率响应,n表示高阶过程模型的阶数,符号^表示估计值,上标l是要求解的第二低阶过程模型;j表示虚数。
[0034]
在高阶辨识模型是对单激励数据段的辨识时,渐近负对数似然函数表示为:
[0035][0036]
根据阻尼高斯牛顿法和所述第一低阶过程模型求解高阶过程模型的渐近负对数似然函数最小化时对应的低阶过程模型,获得第二低阶过程模型,包括:
[0037]
ε(ω)的雅可比矩阵j为:
[0038][0039]
其中,ε=[ε(ω1),
…
,ε(ω
m
)]
t
;θ为第一低阶过程模型,;θ为第一低阶过程模型,下标n
l
表示低阶过程模型的阶数。
[0040]
由于则其中,令令ε(ω)的偏导表示为:
[0041][0042][0043]
其中,
[0044][0045][0046][0047][0048]
根据j
t
j
·
δθ=
‑
j
t
ε和θ(
k 1
)=θ
(k)
α
·
δθ,获得第二低阶过程模型;其中α为阻尼因子,初始值θ
(0)
是第一低阶过程模型。
[0049]
本发明第三方面提出一种计算机设备,包括存储器、处理器及存储在存储器上并
可在处理器上运行的pid控制回路中的数据筛选程序,处理器执行pid控制回路中的数据筛选程序时,实现如上所述的筛选pid控制回路中数据的方法。
[0050]
本发明第四方面提出一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的系统辨识程序,处理器执行系统辨识程序时,实现如上所述的系统辨识方法。
[0051]
(三)有益效果
[0052]
本发明的有益效果是:
[0053]
1、通过预先定义的运行数据状态码和基于状态码构建的数据剔除策略来检测历史运行数据并剔除缺失数据,简化了缺失数据剔除处理的流程。以及通过预先定义的开环状态码和闭环状态码用于激励数据段的筛选,简化了激励数据段筛选的流程。
[0054]
2、基于3σ原则,通过检测有效数据段输入与输入平均值的偏差,和输出与输出平均值的偏差来确定异常峰值,以及结合检测数据段滤波前后输入差值与输入差值平均值的偏差,和输出差值和输出差值平均值的偏差来确定异常峰值;并根据插值法对异常峰值进行处理。能够全面地检测出异常峰值,使异常峰值处理的结果更好。
[0055]
3、本发明提出的筛选pid控制回路中数据的方法,实现了通过检测开环数据中u(t)的变化,来筛选开环数据中的激励数据段,通过检测闭环数据中r(r)的变化,来筛选闭环数据中的激励数据段,能够从pid控制回路的历史运行数据中自动筛选出充分激励的数据段。
[0056]
4、本发明提出的系统辨识方法,可以同时辨识多个激励数据段,适用于开环、闭环pid控制过程的辨识,普适性高,并且使辨识获得的模型精度高,数值计算可靠。
附图说明
[0057]
本发明借助于以下附图进行描述:
[0058]
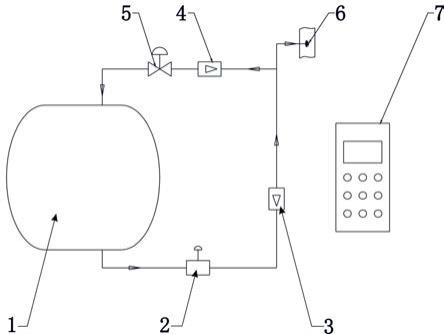
图1为根据本发明一个实施例的pid闭环控制回路示意图;
[0059]
图2为根据本发明一个实施例的pid开环控制回路示意图;
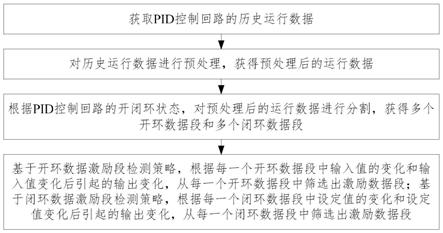
[0060]
图3为根据本发明一个实施例的筛选pid控制回路中数据的方法的流程示意图;
[0061]
图4为根据本发明一个实施例的系统辨识方法的流程示意图。
具体实施方式
[0062]
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
[0063]
pid控制在工业现场应用十分普遍。图1为本发明一个实施例示出的pid闭环控制回路示意图,图2为本发明一个实施例示出的pid开环控制回路示意图。图中,g(q)为被控对象的传递函数模型,h(q)为干扰噪声的传递函数模型,g
c
(q)为pid控制器的传递函数,y(t)为t时刻被控对象的输出值,u(t)为t时刻被控对象的输入值,r(t)为t时刻的设定值,e(t)为高斯白噪声,均值为0,方差为λ,v(t)为干扰噪声。使用线性函数来描述被控对象,如下:
[0064]
y(t)=g(q)u(r) v(r)
[0065]
v(t)=h(q)e(r)
[0066]
式中,g(q)为被控对象模型,t为时间,q为延迟算子,有q
‑1u(t)=u(t
‑
1)。
[0067]
被控对象模型g(q)的准确辨识要求被控对象的输入和输出数据是充分激励的。为获取充分激励的数据,在以往的系统辨识中,常常需要进行激励实验。而实际上,工厂的pid回路存在大量的历史运行数据,如果能从中筛选出可用的充分激励数据段,则可以减少激励实验的时间,甚至完全避免做激励实验。
[0068]
在pid控制回路中主要有两类情况可能包含充分激励段:
[0069]
a)回路运行于如图2所示的开环状态下,输入u(t)是人为给定的,只要u(t)的变化足以激励过程,回路的数据就可用于系统辨识。
[0070]
b)回路运行于如图1所示的闭环状态下,只要设定值r(t)的变化足以激励过程,回路的数据就可用于系统辨识。
[0071]
由此,本发明将历史运行数据中充分激励数据段的筛选问题转化为开环状态下u(t)的变化检测问题和闭环状态下r(t)的变化检测问题。
[0072]
为此,本发明实施例提出一种筛选pid控制回路中数据的方法,通过获取包括pid控制回路的输入,输出,设定值,开闭环状态的历史运行数据,根据pid控制回路的开闭环状态,对历史运行数据进行分割,获得多个开环数据段和多个闭环数据段;并基于开环数据激励段检测策略,根据每一个开环数据段中输入值的变化和输入值变化后引起的输出变化,从每一个开环数据段中筛选出激励数据段,基于闭环数据激励段检测策略,根据每一个闭环数据段中设定值的变化和设定值变化后引起的输出变化,从每一个闭环数据段中筛选出激励数据段。实现了通过检测开环数据中u(t)的变化,来筛选开环数据中的激励数据段,通过检测闭环数据中r(t)的变化,来筛选闭环数据中的激励数据段,能够从pid控制回路的历史运行数据中自动筛选出充分激励的数据段。
[0073]
为了更好的理解上述技术方案,下面将参照附图更详细地描述本发明的示例性实施例。虽然附图中显示了本发明的示例性实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更清楚、透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
[0074]
图3为本发明一个实施例的筛选pid控制回路中数据的方法的流程示意图。
[0075]
如图3所示,该筛选pid控制回路中数据的方法包括以下步骤:
[0076]
步骤101、获取pid控制回路的历史运行数据。
[0077]
具体地,运行数据包括每一时刻pid控制回路的输入,输出,设定值,开闭环状态。
[0078]
具体的,作为一个实施例,步骤101还包括:检测历史运行数据,如果运行数据t时刻缺失开闭环状态数据,则根据r时刻pid控制回路的输出值和设定值,确定t时刻的开闭环状态数据。这是由于在t时刻,开环状态下设定值和输出值是相等的,闭环状态下设定值和输出值是不同的,且设定值呈现阶梯变化。
[0079]
步骤102、对历史运行数据进行预处理,获得预处理后的运行数据。
[0080]
pid控制回路运行不可避免会存在各种类型的异常值,如停机导致的数据缺失,仪表失灵或上下游回路干扰导致的异常峰值等。在系统辨识前,需要处理这些异常值,因此需要对历史运行数据进行预处理。
[0081]
具体地,作为一个实施例,对历史运行数据进行预处理,包括:对历史运行数据中的缺失数据进行剔除处理;对历史运行数据中的异常峰值进行处理。
[0082]
优选地,作为一个实施例,对历史运行数据中的缺失数据进行剔除处理,包括:基
于数据剔除策略s(t)=s
u
(t)∩s
y
(t)∩s
r
(t),检测历史运行数据中每一时刻的运行数据,剔除s(t)=0的运行数据;根据历史运行数据剔除处理后形成的数据段,生成多个有效数据段。
[0083]
其中,s
u
(t)为t时刻输入值u(t)的状态码,如果u(t)缺失,则s
u
(t)=0,否则s
u
(t)=1;s
y
(t)为t时刻输出值y(t)的状态码,如果y(t)缺失,则s
y
(r)=0,否则s
y
(t)=1;s
r
(t)为t时刻设定值r(t)的状态码,如果r(t)缺失,则s
r
(t)=0,否则s
r
(t)=1;s(t)为t时刻运行数据的状态码,符号∩表示且运算,只有当s
u
(t)、s
y
(t)、s
r
(t)都等于1时,s(t)=1,否则s(t)=0。
[0084]
通过预先定义的运行数据状态码和基于状态码构建的数据剔除策略来检测历史运行数据并剔除缺失数据,简化了缺失数据剔除处理的流程。
[0085]
进一步地,作为一个实施例,根据历史运行数据剔除处理后形成的数据段,生成多个有效数据段,包括:根据历史运行数据剔除处理后形成的数据段,将间距小于第四阈值的相邻数据段间的缺失数据进行线性插值,形成新的数据段;检测每一个数据段的长度,剔除长度小于第五阈值的数据段,生成多个有效数据段。避免数据段碎片化,同时舍弃很短的数据段。
[0086]
具体地,检测历史运行数据剔除处理后形成的数据段的位置和长度,第i个数据段表示为:
[0087]
[x
start,i,
x
end,i
]
[0088]
第i个数据段的长度表示为:
[0089]
l
i
=x
end,i
‑
x
start,i
1
[0090]
式中,x
start,i
和x
end,i
分别表示第i个数据段在历史运行数据中的起始位置和终止位置。
[0091]
根据数据段的位置,筛选出间距小于第一阈值的相邻数据段,公式表示为:
[0092]
d
i
=x
start,i 1
‑
x
end,i
[0093]
d
i
<d1[0094]
式中,d
i
为相邻数据段的间距,d1为第一阈值。
[0095]
将间距小于第一阈值的相邻数据段间的缺失数据区间(x
end,i
,x
start,i 1
)进行线性插值,并将该缺失数据区间的全部s(t)设置为1,形成新的数据段。
[0096]
根据数据段的长度,剔除长度小于第二阈值的数据段,生成多个有效数据段。即当l
i
<l1时,l1为第二阈值,将该数据段的s(t)设置为0,也就是说舍弃很短的数据段。
[0097]
优选地,作为一个实施例,对历史运行数据中的异常峰值进行处理,包括:
[0098]
步骤102
‑
1、对每一个有效数据段进行异常峰值初处理,获得每一个初处理数据段。
[0099]
其中异常峰值初处理包括:计算每一个有效数据段中u(r)的平均值和标准差σ
u
,以及y(t)的平均值和标准差σ
y
;根据筛选出每一个有效数据段中u(t)的异常峰值;根据筛选出每一个有效数据段中y(t)的异常峰值;根据每一个有效数据段中异常峰值邻近的数据对该异常峰值进行插值处理。
[0100]
步骤102
‑
2、对每一个初处理数据段进行异常峰值再处理,获得每一个再处理数据
段。
[0101]
其中异常峰值再处理包括:采用半窗口大小为p的中值滤波算法对每个初处理数据段进行滤波,获得每一个滤波数据段。根据每个初处理数据段及其对应的滤波数据段,计算两者之间的u(t)差值和y(t)差值,获得每一个差值δu(t)数据段和每一个差值δy(t)数据段。计算每一个差值δu(t)数据段的平均值和标准差σ
δu
,以及计算每一个差值δy(t)数据段的平均值和标准差σ
δy
;根据筛选出每一个差值δu(t)数据段中δu(t)的异常峰值;根据筛选出每一个差值δy(t)数据段的异常峰值。根据每一个差值δu(t)数据段中异常峰值邻近的数据对该异常峰值进行插值处理,根据每一个差值δy(t)数据段中异常峰值邻近的数据对该异常峰值进行插值处理。
[0102]
基于3σ原则,通过检测有效数据段输入与输入平均值的偏差,和输出与输出平均值的偏差来确定异常峰值,以及结合检测数据段滤波前后输入差值与输入差值平均值的偏差,和输出差值和输出差值平均值的偏差来确定异常峰值;并根据插值法对异常峰值进行处理。能够全面地检测出异常峰值,使异常峰值处理的结果更好。
[0103]
步骤103、根据pid控制回路的开闭环状态,对预处理后的运行数据进行分割,获得多个开环数据段和多个闭环数据段。
[0104]
回路运行的历史数据包含了开环和闭环状态,而判断开环数据和闭环数据充分激励段的标准是不同的,故需要根据pid控制回路的开闭环状态,将预处理后的运行数据中的开环段和闭环段分割出来。
[0105]
具体地,作为一个实施例,开环数据段为t时刻开环状态码s
open
(t)均为1的数据段,闭环数据段为t时刻闭环状态码s
closed
(t)均为1的数据段。
[0106]
步骤104、基于开环数据激励段检测策略,根据每一个开环数据段中输入值的变化和输入值变化后引起的输出变化,从每一个开环数据段中筛选出激励数据段;基于闭环数据激励段检测策略,根据每一个闭环数据段中设定值的变化和设定值变化后引起的输出变化,从每一个闭环数据段中筛选出激励数据段。
[0107]
优选地,作为一个实施例,基于开环数据激励段检测策略,根据每一个开环数据段中输入值的变化和输入值变化后引起的输出变化,从每一个开环数据段中筛选出激励数据段,包括:根据每一个开环数据段中输入值的变化梯度δu(t),筛选出满足|δu(t)|>c
u
r
u
的目标输入值变化梯度;根据稳态段判断标准检测每一个开环数据段中发生目标输入值变化梯度后引起的输出变化,若输出变化中存在稳态段,则将输出变化到达稳态段之前对应的运行数据作为激励段数据,若输出变化中不存在稳态段,则将输出变化对应的运行数据作为激励段数据。
[0108]
其中,c
u
为第三阈值,要求输入的改变引起的输出变化要明显大于扰动和噪声引起的变化,可选取5%;r
u
为t时刻输入值u(t)的量程;稳态段判断标准为|δy(t)|<c
y
r
y
,δy(t)为输出值的变化梯度,c
y
为第四阈值,r
y
为t时刻输出值y(t)的量程。
[0109]
进一步地,作为一个实施例,根据开环数据段中筛选出的激励数据段,将间距小于第五阈值且之间不存在闭环数据的相邻激励数据段进行合并。避免激励数据段碎片化。
[0110]
优选地,作为一个实施例,基于闭环数据激励段检测策略,根据每一个闭环数据段
中设定值的变化和设定值变化后引起的输出变化,从每一个闭环数据段中筛选激励段数据,包括:根据每一个闭环数据段中设定值的变化梯度δr(t),筛选出满足|δr(t)|>c
r
r
y
的目标设定值变化梯度;根据稳态段判断标准检测每一个闭环数据段中发生目标设定值变化梯度后引起的输出变化,若输出变化中存在稳态段,则将输出变化到达稳态段之前对应的运行数据作为激励段数据,若输出变化中不存在稳态段,则将输出变化对应的运行数据作为激励段数据。
[0111]
其中,c
r
为第六阈值,要求设定值的改变引起的输出变化要明显大于扰动噪声引起的变化,可选取5%;稳态段判断标准为|δy(t)|<c
y
r
y
。
[0112]
进一步地,作为一个实施例,根据闭环数据段中筛选出的激励数据段,将间距小于第五阈值且之间不存在开环数据的相邻数据段进行合并。
[0113]
在激励数据段的筛选中,通过梯度来判断激励段,且阈值的选取具有很大的普适应,方法简单有效。
[0114]
在以往的系统辨识方法中,不能对多个激励数据段进行辨识,并且还存在仅能对开环pid控制过程进行辨识,不能对闭环pid控制过程进行辨识的方法。为对上述筛选pid控制回路中数据方法获取的激励数据段进行系统辨识,本发明实施例还提供一种系统辨识方法。
[0115]
下面就参照附图来描述根据本发明实施例提出的系统辨识方法。
[0116]
图4为本发明一个实施例的系统辨识方法的流程示意图。
[0117]
如图4所示,该系统辨识方法包括以下步骤:
[0118]
步骤201、获取激励数据段。
[0119]
步骤202、采用高阶arx(auto regressive with exogeneous,带外部输出的自回归)模型对激励数据段进行辨识,获得高阶过程模型。
[0120]
具体地,作为一个实施例,高阶arx模型结构为:
[0121]
a(q)y(t)=b(q)u(t) e(t)
[0122]
其中,a(q)=1 a1q
‑1 a2q
‑2
…
a
n
q
‑
n
,b(q)=b1q
‑1 b2q
‑2
…
b
n
q
‑
n
,a1…
a
n
和b1…
b
n
是要求解的模型的参数,n表示高阶arx模型的阶数。
[0123]
根据高阶arx模型,辨识出的高阶过程模型扰动模型和扰动信号谱表示为:
[0124][0125]
其中,上标n表示高阶arx模型的阶数;下标n表示激励数据段;符号^表示估计值;ω表示频率;r表示arx模型的方程误差,即a(q)y(t)
‑
b(q)u(t)的估计方差;j表示虚数。
[0126]
步骤203、采用morsm(model order reduction steiglitz
‑
mcbride,斯蒂格里茨
·
麦克布赖德模型降阶)方法对高阶过程模型进行降阶处理,获得第一低阶过程模型。
[0127]
具体地,获得的第一低阶过程模型表示为:
[0128][0129]
式中,q是算符,n
l
表示低阶过程模型的阶数。
[0130]
步骤204、根据阻尼高斯牛顿法和第一低阶过程模型求解高阶过程模型的渐近负对数似然函数最小化时对应的低阶过程模型,获得第二低阶过程模型,将第二低阶过程模型作为pid回路模型。
[0131]
根据极大似然准则,当n
→
∞时,高阶过程模型的渐近负对数似然函数为:
[0132][0133]
式中,是高阶过程模型的频率响应;j表示虚数;上标l是要求解的第二低阶过程模型;φ
u
(ω)、φ
v
(ω)分别为输入u(t)、扰动项h(q)e(t)的自谱;φ
ue
(ω)为输入u(t)与白噪声e(t)的互谱;r表示arx模型的方程误差,即a(q)y(t)
‑
b(q)u(t)的估计方差。
[0134]
在高阶辨识模型是对单激励数据段的辨识时,令dω≈2πδf,δf为常数,单位hz,为分析方便,取δf=1,渐近负对数似然函数可离散化为:
[0135][0136]
令
[0137][0138][0139]
将ε(ω
p
)带入离散渐近负对数似然函数,得
[0140][0141]
式中,m为考虑的频率离散点数。
[0142]
上式为平方准则,故可根据阻尼高斯牛顿法和第一低阶过程模型求解高阶过程模型的渐近负对数似然函数最小化时对应的低阶过程模型,包括:
[0143]
ε(ω)的雅可比矩阵j为:
[0144]
[0145]
其中,ε=[ε(ω1),
…
,ε(ω
m
)]
t
;θ为第一低阶过程模型,;θ为第一低阶过程模型,下标n
l
表示低阶过程模型的阶数。
[0146]
由于则其中,令令ε(ω)的偏导表示为:
[0147][0148][0149]
其中,
[0150][0151][0152][0153][0154]
根据j
t
j
·
δθ=
‑
j
t
ε和θ
(k 1)
=θ
(k)
α
·
δθ,获得第二低阶过程模型;其中α为阻尼因子,初始值θ
(0)
是第一低阶过程模型。
[0155]
在高阶辨识模型是对多个激励数据段的辨识时,高阶辨识模型的渐近负对数似然函数变为:
[0156][0157]
式中,n
s
为激励数据段的总数。
[0158]
求解过程与单激励数据段的辨识类似,此处不再赘述。
[0159]
本发明实施例提出的系统辨识方法,可以同时辨识多个激励数据段,适用于开环、闭环pid控制过程的辨识,普适性高,并且使辨识获得的模型精度高,数值计算可靠。
[0160]
本发明实施例提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的pid控制回路中的数据筛选程序,处理器执行pid控制回路中的数据筛选程序时,实现如上所述的筛选pid控制回路中数据的方法。
[0161]
本发明实施例提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的系统辨识程序,处理器执行系统辨识程序时,实现如上所述的系统辨识方法。
[0162]
需要理解的是,以上对本发明的具体实施例进行的描述只是为了说明本发明的技术路线和特点,其目的在于让本领域内的技术人员能够了解本发明的内容并据以实施,但本发明并不限于上述特定实施方式。凡是在本发明权利要求的范围内做出的各种变化或修饰,都应涵盖在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。