1.本发明涉及天然气集输领域,具体涉及一种工艺参数驱动的三甘醇脱水装置三甘醇损耗量在线预测方法。
背景技术:
2.三甘醇是一种优良的脱水剂,广泛应用于天然气脱水工艺中。三甘醇损耗量是三甘醇脱水装置的一项重要生产指标。三甘醇损耗会导致三甘醇脱水装置脱水效果降低,缩短三甘醇的使用寿命。有效的监测三甘醇损耗量,及时调整生产工艺有利于降低生产成本和提高脱水效果,因此有效监测三甘醇损耗量是实际生产的重要任务之一。在实际生产中,通常通过人工日检测三甘醇损耗量,检测成本高,时效性差,同时传统的三甘醇损耗量预测方法认为三甘醇损耗与运行参数、原料气气质、处理气量负荷等相关,有研究人员建立了线性模型预测三甘醇损耗量,但这些关系是经验的,无法自适应的预测脱水系统的三甘醇损耗。针对传统检测及预测方法无法实时有效的监测三甘醇的损耗问题,本发明通过极端梯度提升树(extreme gradient boosting,xgboost)算法评估三甘醇脱水装置原始特征集各参数对三甘醇损耗量的影响关系的重要程度,减少冗余或无关参数对损耗量预测的影响,实现关键参数的选择。通过参数选择后的高维数据样本集,训练优化具有抗噪声能力强和泛化能力强优势的随机森林(random forest,rf)模型。优化后的rf预测模型可以通过三甘醇脱水装置的工艺监测参数实时的在线预测三甘醇损耗量,实现脱水装置脱三甘醇损耗的评估。
技术实现要素:
3.针对常规三甘醇脱水装置三甘醇损耗量人工检测成本高,时效性差及传统预测方法无法自适应的预测脱水系统的三甘醇损耗的缺点,本发明公开了一种工艺参数驱动的三甘醇脱水装置三甘醇损耗量在线预测方法,通过评估和选择对三甘醇损耗有重要影响的关键参数,结合泛化能力强和预测准确率高的随机森林(random forest,rf)模型,实现一种三甘醇脱水装置工艺参数的三甘醇损耗量在线预测。
4.本发明通过下述技术方案实现:
5.一种工艺参数驱动的脱水装置三甘醇损耗量在线预测方法,包括以下步骤:
6.步骤s1:对于具有n个工艺监测参数的三甘醇脱水装置,将各参数依次编号为参数1至参数n,将n个工艺参数和三甘醇损耗量数据组成预测模型原始训练数据集x,数据集共有m个样本,将各样本依次编号为样本1至样本m;
7.步骤s2:建立用于特征选择的极端梯度提升树(extreme gradient boosting,xgboost)模型,所述xgboost模型由多棵串行的决策树组成,所述决策树为分类回归树(classification and regression tree,cart),模型当前决策树的建立依赖已建立好的决策树模型,即对于当前正构建的第t棵决策树的目标拟合值为前t
‑
1棵决策树的损失值,
所述损失值为目标值与预测值的差,直至模型收敛时模型训练完成,当模型训练完成时计算xgboost模型中每个工艺参数特征作为分裂条件时的平均增益判断工艺参数的重要性,所述平均增益为工艺参数j总的增益和除以树分裂中参数j出现的总频次,设定模型训练时所需的相关参数,设定均方误差为模型的损失函数,以及设定模型损失函数正则项的叶节点复杂性系数γ、惩罚系数λ,决策树的数量、决策树最大深度和学习率,所述损失函数、叶节点复杂性系数γ、惩罚系数λ用于控制决策树节点的分裂,所述决策树的数量、决策树最大深度和学习率是为了防止模型过拟合;
8.步骤s3:训练模型,建立xgboost的第t棵树,所述1≤t≤决策树的数量,计算当前未分裂决策树节点的最大增益,所述最大增益是决策树分裂的判定标准,所述最大增益计算过程:依次遍历所有参数特征k=1,2,
…
,n,将参数特征k的样本值从小到大排列,所述参数特征k的样本值只含有参数特征k的值,但分裂时该样本包含其它特征的值作为一个整体分裂,依次取出第i个样本,将小于该样本值的样本放入左子树,计算左右子树各样本的损失函数的一阶导数和g
l
、g
r
和二阶导数和h
l
、h
r
,获得当前节点分裂的增益,所述增益的计算过程为:当遍历完成后,一种最大增益对应的参数特征和参数值分裂子树,所述节点分裂,如第x
k
个工艺参数的第i个样本值x
ki
,则当前节点分裂标准为x
jk
<x
ki
,所有满足分裂条件的样本分入左子树,其余样本分入右子树,并计算左右子树各样本的权值w
i
,所述权值是满足某决策树分裂条件的预测值,左子树各样本权重值:右子树各样本权重值:当模型建立完成时,预测值由测试样本满足模型中所有分裂条件的叶节点的权值求和得到;
9.步骤s4:重复步骤s3,完成第t棵决策树的训练,该决策树建立完成的条件为:直到所有的节点分裂完毕或达到决策树最大深度,所述节点分裂完毕,表示该节点只有一个样本,得到训练完成的第t棵决策树;
10.步骤s5:重复步骤s3~步骤s4,直到所有的决策树建立完毕,得到参数特征选择模型;
11.步骤s6:分别计算xgboost模型中每个工艺参数特征作为分裂条件时的平均增益。所述平均增益用于表征工艺参数对目标参数的重要程度。将所有工艺参数的平均增益排序,设定阈值选择关键工艺参数,得到特征选择后的训练数据集;
12.步骤s7:对于特征选择后的训练数据集,设定rf决策树的数量,所述决策树为cart树,所述rf模型由并行的决策树组成,每个决策树为一个为弱学习器,将所有弱学习器得到的结果进行算术平均得到最终的预测值,rf模型采用bagging的集合策略训练模型,所述bagging方法在一次抽取中,有的样本被多次抽到,有的样本未抽到,每个训练子集的大小约为特征选择后的训练数据集的三分之二,每一次抽取用于训练一个弱学习器,该抽样方法使决策树具有泛化能力很强的特点;
13.步骤s8:训练模型,建立rf的第i棵树,所述1≤i≤决策树的数量,通过bagging方法从特征选择后的训练数据集中有放回的抽取m个样本作为新的训练子集,对于当前的rf第i棵决策树,对每个节点的分裂,该节点含有n
d
个参数特征,从n
d
个工艺参数特征属性中随机选取n
try
个作为候选分裂属性,所述n
try
<n
d
,根据平方误差最小化准则从n
try
个工艺参数
特征属性中,选择最优分裂属性作为节点分裂的指标进行分裂,所述最优分裂属性即选用平方误差最小的工艺参数特征属性,其最优分裂属性计算过程为:依次遍历所有参数特征k=1,2,
…
,n
try
和第k个参数在该节点的样本值,即对于第k个参数特征及该参数特征的某个样本值s,分别作为分裂变量和分裂条件值,依据公式样本值s,分别作为分裂变量和分裂条件值,依据公式r1(k,s)={x|x
(k)
≤s},r2(k,s)={x|x
(k)
>s}选择最优分裂特征和分裂值,所述y
i
为样本目标值,c1为r1所有样本目标值的均值和c2为r2所有样本目标值的均值,并将c1和c2作为分裂后左右子树节点的预测值;
14.步骤s9:重复步骤s8,当节点的数据量小于指定数量时或平方误差收敛,节点停止续分裂,所述节点停止分裂表示,第i棵决策树训练完成;
15.步骤s10:重复步骤s8~步骤s9,直至所有的rf决策树建立完毕,得到训练完成的预测模型;
16.步骤s11:进行三甘醇脱水装置损耗量在线预测,对于三甘醇脱水装置历史工艺参测数据,依据步骤s6选取预测模型对工艺参测数据进行特征选择,对于特征选择的数据集,利用步骤7~步骤10建立rf三甘醇脱水装置三甘醇损耗量预测模型。将三甘醇脱水装置实时工艺参测数据作为rf预测模型的输入,实现三甘醇脱水装置三甘醇损耗量在线预测。
17.本发明的原理为,通过xgboost算法评估和选择原始数据集中的重要参数,减少冗余或无关特征对预测结果的影响.以提高三甘醇脱水装置三甘醇损耗量的预测精度;以工艺监测参数建立三甘醇损耗量预测模型充分利用了三甘醇脱水装置生产系统中各相关参数与三甘醇损耗量的影响关系;rf模型对异常值和噪声具有很好的容忍度,且不容易出现过拟合,具有较高的预测准确率,以rf模型建立脱水装置三甘醇损耗量实时预测模型,有利于提高模型的预测准确率。
18.本发明具有较高的预测精度,是实现三甘醇脱水装置三甘醇损耗量在线预测的有效方法,常规三甘醇损耗量采用人工日检测的方式监测,导致三甘醇损耗量检测成本高,时效性差,本发明针对三甘醇脱水装置历史工艺监测数据,利用xgboost选取对三甘醇损耗量有关键影响的参数组成高维训练数据集,结合rf模型具有受异常值和噪声影响小,泛化能力强的预测特性,一种工艺监测数据学习各工艺参数间的耦合关系,可以较高精度实现三甘醇脱水装置三甘醇损耗量的在线预测。
附图说明
19.此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
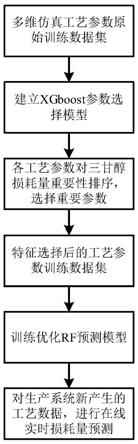
20.图1为本发明一种工艺参数驱动的三甘醇脱水装置三甘醇损耗量在线预测方法实现流程图;
21.图2为xgboost特征选择模型示意图。
22.图3为rf模型示意图。
具体实施方式
23.为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
24.实施例一:
25.本发明一种工艺参数驱动的三甘醇脱水装置三甘醇损耗量在线预测方法实现流程图如图1所示,包括以下步骤:
26.步骤s1:对于具有n个工艺监测参数的三甘醇脱水装置,将各参数依次编号为参数1至参数n,将n个工艺参数和三甘醇损耗量数据组成预测模型原始训练数据集x,数据集共有m个样本,将各样本依次编号为样本1至样本m;
27.如针对某天然气三甘醇脱水装置,监测参数包括各子部件的压力控制阀开度、吸收塔压力、闪蒸罐液位、精馏柱温度、重沸器温度等33个工艺监测参数,以及三甘醇损耗量日检测数据。但由于目前三甘醇损耗量日检测数据少,无法达到作为训练数据集的要求。因此,本实例说明通过建立三甘醇脱水装置仿真模型,通过动态仿真模型生成了工艺参数数据和三甘醇损耗量数据作为原始训练数据集。仿真模型模拟了进装置压力、三甘醇循环量、吸收塔差压、出吸收塔富甘醇温度、闪蒸罐压力、闪蒸罐液位、闪蒸罐液位控制阀开度、重沸器温度、精馏柱顶部温度等18个参数和三甘醇损耗量参数,并生成了1000条仿真样本数据。
28.步骤s2:建立用于特征选择的极端梯度提升树(extreme gradient boosting,xgboost)模型,所述xgboost模型由多棵串行的决策树组成,所述决策树为分类回归树(classification and regression tree,cart),模型当前决策树的建立依赖已建立好的决策树模型,即对于当前正构建的第t棵决策树的目标拟合值为前t
‑
1棵决策树的损失值,所述损失值为目标值与预测值的差,直至模型收敛时模型训练完成,当模型训练完成时计算xgboost模型中每个工艺参数特征作为分裂条件时的平均增益判断工艺参数的重要性,所述平均增益为工艺参数j总的增益和除以树分裂中参数j出现的总频次,设定模型训练时所需的相关参数,设定均方误差为模型的损失函数,以及设定模型损失函数正则项的叶节点复杂性系数γ、惩罚系数λ,决策树的数量、决策树最大深度和学习率,所述损失函数、叶节点复杂性系数γ、惩罚系数λ用于控制决策树节点的分裂,所述决策树的数量、决策树最大深度和学习率是为了防止模型过拟合;
29.针对该三甘醇脱水装置仿真数据组成高维原始训练数据集,以工艺参数为自变量,以三甘醇损耗量为因变量,设定模型损失函数正则项的叶节点复杂性系数γ=0.0、惩罚系数λ=1,决策树的数量500、决策树最大深度3和学习率0.01。
30.步骤s3:训练模型,建立xgboost的第t棵树,所述1≤t≤决策树的数量,计算当前未分裂决策树节点的最大增益,所述最大增益是决策树分裂的判定标准,所述最大增益计算过程:依次遍历所有参数特征k=1,2,
…
,n,将参数特征k的样本值从小到大排列,所述参数特征k的样本值只含有参数特征k的值,但分裂时该样本包含其它特征的值作为一个整体分裂,依次取出第i个样本,将小于该样本值的样本放入左子树,计算左右子树各样本的损失函数的一阶导数和g
l
、g
r
和二阶导数和h
l
、h
r
,获得当前节点分裂的增益,所述增益的计算过程为:当遍历完成后,一种最大增益对应的参数特征和参
数值分裂子树,所述节点分裂,如第x
k
个工艺参数的第i个样本值x
ki
,则当前节点分裂标准为x
jk
<x
ki
,所有满足分裂条件的样本分入左子树,其余样本分入右子树,并计算左右子树各样本的权值w
i
,所述权值是满足某决策树分裂条件的预测值,左子树各样本权重值:右子树各样本权重值:当模型建立完成时,预测值由测试样本满足模型中所有分裂条件的叶节点的权值求和得到;
31.在xgboost特征选择模型中,通过计算某节点包含的训练子集的最大增益分裂节点,同时添加新树时,即新一次的迭代,决策树中节点的权值继承之前的决策树的权值,以实现模型的串行优化。不断增加新树以提高模型的准确度。
32.步骤s4:重复步骤s3,完成第t棵决策树的训练,该决策树建立完成的条件为:直到所有的节点分裂完毕或达到决策树最大深度,所述节点分裂完毕,表示该节点只有一个样本,得到训练完成的第t棵决策树;
33.节点分裂,迭代优化第t棵树。
34.步骤s5:重复步骤s3~步骤s4,直到所有的决策树建立完毕,得到参数特征选择模型;
35.当训练损失收敛后结束训练,特征选择模型训练完成。
36.步骤s6:分别计算xgboost模型中每个工艺参数特征作为分裂条件时的平均增益。所述平均增益用于表征工艺参数对目标参数的重要程度。将所有工艺参数的平均增益排序,设定阈值选择关键工艺参数,得到特征选择后的训练数据集;
37.进行关键参数选择时,通过计算三甘醇脱水装置各工艺监测参数在xgboost模型中作为分裂条件时的平均增益。将所有参数的平均增益排名,并设定阈值选择重要参数。对于该脱水装置选择了出缓冲罐贫甘醇温度、精馏柱顶部温度、重沸器温度、出板式换热器富甘醇温度、闪蒸罐液位控制阀开度、闪蒸罐液位、计量温度、.三甘醇循环量等8个关键参数。将关键参数和三甘醇损耗量组成新的训练数据集。
38.步骤s7:对于特征选择后的训练数据集,设定rf决策树的数量,所述决策树为cart树,所述rf模型由并行的决策树组成,每个决策树为一个为弱学习器,将所有弱学习器得到的结果进行算术平均得到最终的预测值,rf模型采用bagging的集合策略训练模型,所述bagging方法在一次抽取中,有的样本被多次抽到,有的样本未抽到,每个训练子集的大小约为特征选择后的训练数据集的三分之二,每一次抽取用于训练一个弱学习器,该抽样方法使决策树具有泛化能力很强的特点;
39.针对该三甘醇脱水装置仿真数据特征选择后的训练数据集,以工艺参数为自变量,以三甘醇损耗量为因变量,设置rf决策树的数量为100。
40.步骤s8:训练模型,建立rf的第i棵树,所述1≤i≤决策树的数量,通过bagging方法从特征选择后的训练数据集中有放回的抽取m个样本作为新的训练子集,对于当前的rf第i棵决策树,对每个节点的分裂,该节点含有n
d
个参数特征,从n
d
个工艺参数特征属性中随机选取n
try
个作为候选分裂属性,所述n
try
<n
d
,根据平方误差最小化准则从n
try
个工艺参数特征属性中,选择最优分裂属性作为节点分裂的指标进行分裂,所述最优分裂属性即选用平方误差最小的工艺参数特征属性,其最优分裂属性计算过程为:依次遍历所有参数特征k=1,2,
…
,n
try
和第k个参数在该节点的样本值,即对于第k个参数特征及该参数特征的某个
样本值s,分别作为分裂变量和分裂条件值,依据公式样本值s,分别作为分裂变量和分裂条件值,依据公式r1(k,s)={x|x
(k)
≤s},r2(k,s)={x|x
(k)
>s}选择最优分裂特征和分裂值,所述y
i
为样本目标值,c1为r1所有样本目标值的均值和c2为r2所有样本目标值的均值,并将c1和c2作为分裂后左右子树节点的预测值;
41.对于rf第i棵树的优化,在每个节点分裂时,从节点包含的n
d
个工艺参数特征属性中随机选取n
try
个作为候选分裂属性,根据平方误差最小化准则选择最佳的分裂属性分裂节点,将该节点处的数据,分裂到左右节点中,完成该节点的分裂,以左右子树样本标签的均值作为左右节点的预测值。
42.步骤s9:重复步骤s8,当节点的数据量小于指定数量时或平方误差收敛,节点停止续分裂,所述节点停止分裂表示,第i棵决策树训练完成;
43.节点分裂,并完成第i棵树的训练优化。
44.步骤s10:重复步骤s8~步骤s9,直至所有的rf决策树建立完毕,得到训练完成的预测模型;
45.当训练损失收敛后结束训练,rf预测模型训练完成。
46.步骤s11:进行三甘醇脱水装置损耗量在线预测,对于三甘醇脱水装置历史工艺参测数据,依据步骤s6选取预测模型对工艺参测数据进行特征选择,对于特征选择的数据集,利用步骤7~步骤10建立rf三甘醇脱水装置三甘醇损耗量预测模型。将三甘醇脱水装置实时工艺参测数据作为rf预测模型的输入,实现三甘醇脱水装置三甘醇损耗量在线预测。
47.进行三甘醇脱水装置三甘醇损耗量在线预测,将脱水装置新产生的实时工艺监测参数数据作为训练完成的rf模型的输入数据,实现三甘醇脱水装置三甘醇损耗量在线预测。
48.以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。