1.本发明涉及工业机器人位姿精度在线补偿技术领域,特别涉及一种基于深度强化学习的工业机器人位姿精度在线补偿方法。
背景技术:
2.随着国内高精尖制造业向着自动化及智能化的方向发展,工业机器人因其所具有的高效率、高质量和环境适应性好等特点,在喷涂、焊接、搬运和装配等自动化生产中的应用越来越广泛,工业机器人的需求量也日益增加,实现高精密制造业的技术革新,大幅提升加工质量与生产效率,突破工业机器人的高精度定位问题是一个必须解决的难题。机器人操作精度直接影响到机器人的作业效果,尤其是在作业过程中对某些性能指标有较高要求时,同样也给提高机器人操作精度也提出了更高的要求。
3.现今机器人精度补偿的方法主要有两种:误差预测补偿和误差标定补偿。误差预测补偿方法生产成本较高,且机器人长时间运动会导致机械结构发生磨损,产生的误差无法避免,故在实际中应用较少。误差标定补偿主要采用对系统进行误差建模的思路,得到非系统误差的数学模型,从而实现动态误差反馈。但对于工业机器人这样的串联结构,其本身的动力学解算就十分复杂,同时再引入温度、不同姿态下载荷变化的影响,这样的误差模型必然十分庞大复杂,求解是十分困难的。同时,由于这类非系统误差在一般的工业应用环境中的影响远小于系统误差,因此目前工业环境下也并未形成比较统一的,针对非系统误差进行在线补偿的模型。此外,现有的位姿精度补偿方法无法实现在线实时机器人目标位姿的姿态补偿;离线位姿补偿虽可以同时提高机器人的绝对位置精度和姿态精度,但无法进行在线补偿。例如,专利cn107351089a公开了一种机器人运动学参数标定位姿优化选取方法,但该方法的算法收敛时间受迭代次数、需辨识参数个数及位姿点数的影响,不易收敛。专利cn108608425a公开了一种六轴工业机器人铣削加工离线编程方法,该方法需要构建复杂的一维机器人位姿优化模型,难以保证数学模型与实际机器人切削过程的相近程度,降低了实际的补偿效果上限。专利cn112450820a公开了一种位姿优化方法、移动机器人及存储介质,无法实现机器人姿态误差的预测与补偿。专利cn112536797a公开了一种工业机器人的位置与姿态误差综合补偿方法,该方法无需建立复杂的运动误差模型,同时提升工业机器人的绝对位置精度和姿态精度,但是误差预测过程的可解释性较弱,另外无法实现在不同工作应用环境下在线对非系统误差进行预测与补偿。
技术实现要素:
4.为了解决上述问题,本发明提出了一种基于深度强化学习的工业机器人位姿精度在线补偿方法,不依赖于工业机器人的数学模型,而是通过使用两个功能不同的网络共同实现机器人模型与当前环境的交互学习,动态地调整控制参数,解决工业机器人的非系统误差位姿补偿问题。本发明采用以下技术方案:
5.一种基于深度强化学习的工业机器人位姿精度在线补偿方法,包括以下步骤:
6.步骤1,在不同运行状态下操作机器人,获取机器人的实际位姿,将所述实际位姿与理论位姿做误差运算,作为训练集;
7.步骤2,构建深度强化学习网络模型,确定所述深度强化学习网络的输入输出层;
8.步骤3,完成所述深度强化学习网络模型的预训练,得到网络模型参数;
9.步骤4,利用训练好的所述深度强化学习网络模型,在线预测机器人的位姿偏差,实现闭环的实时误差补偿返回,对非系统误差进行在线补偿。
10.进一步的,所述步骤1中,所述机器人的实际位姿利用激光跟踪仪测量,所述激光跟踪仪测量坐标系与机器人基坐标系采用坐标系转换矩阵进行转换:
[0011][0012]
其中,r为旋转矩阵:
[0013]
r=(n
c3
,n
c1
×
n
c3
,n
c1
)
[0014]
式中,n
c1
为c1轨迹圆的法线方向,n
c3
为c3轨迹圆的法线方向;
[0015]
q为位移矢量,采用下述方式获得:
[0016]
轨迹圆c1与轨迹圆c6相交于p
t
点,即机器人零位状态时的靶球位置,轨迹圆c1的半径为r1;根据机器人自身读数,可得默认工具中心点在机器人基坐标系下的坐标p0=[x0,y0,z0]
t
,定义p
t
点相对于p0点的偏移矢量δ=(δx,δy,δz),则矢量o6o
b
在基坐标系下可表示为下式:
[0017][0018]
其中,δy0=o6p0·
n
c3
,轨迹圆c6的圆心o6在激光跟踪仪测量坐标系下的坐标矢量为进一步可得位移矢量q
′
:
[0019][0020]
为了保证位移矢量的误差尽可能小,在机器人空间中随机采样十个点p
i
,
b
p
i
为靶球在基坐标系下的坐标矢量,
c
p
i
为靶球在机器人默认工具坐标系下的坐标矢量,基于最小二乘拟合方法计算得位移矢量q
″
。
[0021][0022]
通过公式分别计算位移矢量q
′
、q
″
位移矢量误差δe,选取其中误差小的位移矢量为坐标系转换矩阵中的位移矢量q:
[0023][0024]
q=min{δe(q
i
),q
i
∈{q
′
,q
″
}}
[0025]
进一步的,所述深度强化学习网络模型为actor
‑
critic网络模型,actor神经网络根据当前环境状态s计算生成策略,产生具体的关节运动动作作为机器人运动的输入,与环境进行交互;critic神经网络用于评估actor网络在状态s下产生的策略关节动作输出,确定此时情况是好是坏,通过一个值来衡量,并将这一衡量值返回actor神经网络学习,进行参数优化,使代价函数收敛到全局最优。
[0026]
进一步的,将机器人的末端执行位置tcp位姿、刚度k、温变t、负载η、时间信号t以
及时间信号函数sin(t)与ln(t),作为所述深度强化学习网络的输入,所述末端执行位置tcp位姿由坐标position(x,y,z)和欧拉角orientation(α,β,γ)构成;将机器人各关节角度值δjoint_angle(a1,a2,a3,a4,a5,a6)作为所述深度强化学习网络的输出。
[0027]
进一步的,所述步骤3,具体包括以下步骤:
[0028]
(1)将步骤1采集的工业机器人的状态特征及其对应的位姿误差参数海量数据集作为训练样本,输入机器人仿真交互软件中,每一局训练开始,实际位置为机器人样本数据集实际位姿,目标位置为机器人样本数据集理论位姿;
[0029]
(2)actor
‑
critic网络从机器人仿真交互环境中得到当前机器人tcp、刚度k、温变t、负载η状态值和时间信号以及时间函数,actor
‑
critic网络进行计算得到当前各关节的角度修正值,并将此值发回机器人仿真交互软件;
[0030]
(3)机器人仿真交互软件接收到关节角度修正值后,对机器人进行各关节限位计算,判断是否都处于限位内,若是则执行各关节运动修正,同时若某一机器人关节没有在限位内,结束当前对局,并将消息传至actor
‑
critic网络;
[0031]
(4)获取当前机器人位姿与目标位置进行奖励值计算得奖励函数r,如果r值过低,则也需结束当前对局;r值正常,则继续当前对局,将r返回给actor
‑
critic网络继续学习;
[0032]
重复上述步骤,训练得出actor
‑
critic网络模型结构参数。
[0033]
进一步的,所述奖励函数r由机器人理论位姿和实际位姿计算得到:
[0034][0035]
r=η*d
m
(p,p0)
[0036]
其中,p为当前位姿,p0为目标位姿,∑为p与p0的协方差矩阵,η<0:
[0037][0038]
相对于现有技术,本发明有益效果如下:
[0039]
(1)本发明不依赖于工业机器人的数学模型,而是利用强化学习算法,通过不断的探索和试错学习来发现最优控制策略,实现温变、刚度等非系统误差的在线补偿,解决机械臂运动中由温度、动力学载荷变化等因素形成的非系统误差问题。
[0040]
(2)本发明使用两个功能不同的网络共同实现机器人模型与当前环境的交互学习,即actor神经网络与critic神经网络。actor神经网络根据当前环境状态s(包含tcp位姿p、刚度k、温变t、负载η)计算生成机器人运动策略,产生具体的关节运动动作作为机器人运动的输出,与环境进行交互。critic神经网络用于评估actor网络在状态s下产生的策略关节动作输出,确定此时情况是好是坏,通过一个值来衡量,并将这一衡量值返回actor神经网络学习,从而进行参数优化,使代价函数收敛到全局最优。
附图说明
[0041]
图1为基于深度强化学习的工业机器人位姿精度在线补偿方法的流程图;
[0042]
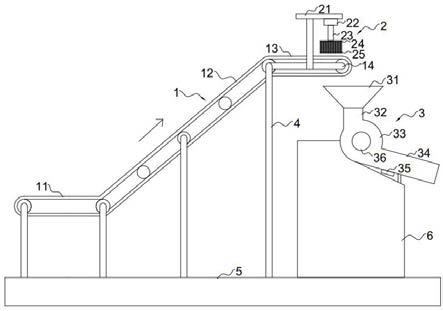
图2为获取工业机器人末端位姿位置信息及在线位姿精度补偿实验平台示意图;
[0043]
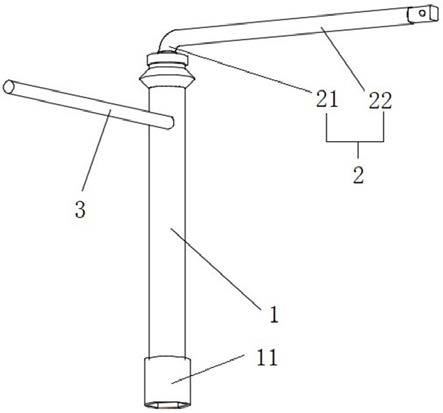
图3为机器人本体及坐标系示意图;
[0044]
图4为actor
‑
critic网络逻辑结构图;
[0045]
图5为与机器人仿真场景机器人交互进行深度强化学习网络训练的算法流程图。
具体实施方式
[0046]
下面结合附图和实施例,对本发明作进一步详细说明,但本发明的实施方式不限于此。
[0047]
在现场工作环境中,机器人定位受到复杂多变的载荷、动力学及温变等外部因素影响,系统误差作用形式会产生变化,同时会引入非系统误差,故此本发明提出了一种基于深度强化学习的工业机器人位姿精度在线补偿方法,如图1所示,包括以下步骤:
[0048]
步骤1:在不同运行状态(负载、温度)下操作机器人,测量实际位姿并和理论位姿做误差运算,收集全部数据作为训练集。具体如下:
[0049]
本发明实现机械臂末端位姿位置信息获取及精度补偿的实验平台,如图2所示,包括工业机器人及其控制柜、位姿位置测量系统装置(激光跟踪仪和位姿测量靶)、移动式工作站,其中工业机器人为六自由度开链结构,机器人末端安装有末端执行器,绝对定位精度在2
‑
3mm。通过激光跟踪仪实时监控机器人位置,并基于ethercat总线实时传输到twincat主站,从而实现全闭环环路;实时获取来自于激光跟踪仪的机器人末端执行器六自由度位姿信息和来自于工业机器人的运动控制信息,并可以对机器人
‑
激光跟踪仪系统状态机进行实时分析与控制。
[0050]
为了后续误差计算,需要统一坐标系,进行激光跟踪仪测量坐标系与工业机器人基坐标系之间的转换,将工业机器人坐标系的位姿数据转换至激光跟踪仪坐标系下,采用轴线测量与多点拟合相结合的方法,计算基坐标系的坐标原点,从而得到转换矩阵。用多点拟合法计算位移矢量q,保证位移矢量q计算精度;采用轴线矢量测量法计算旋转矩阵r,为业机器人基坐标系b至激光跟踪仪测量坐标系l的转换矩阵:
[0051][0052]
具体的,如图3所示,将机器人运动至home位姿,将激光跟踪仪的靶球放在末端执行器的靶座上,分别单独旋转机器人a1轴、a3轴及a6轴拟合得到轨迹圆c1、c3和c6,圆心对应为o1、o3和o6,并得到c1和c3轨迹圆的法线方向n
c1
和n
c3
,分别为基坐标系的z,y方向,计算得旋转矩阵r:
[0053]
r=(n
c3
,n
c1
×
n
c3
,n
c1
)
[0054]
轨迹圆c1与轨迹圆c6相交于p
t
点,即机器人零位状态时的靶球位置,轨迹圆c1的半径为r1。根据机器人自身读数,可得默认工具中心点(定义在机器人第六轴法兰盘的中心处)在机器人基坐标系下的坐标p0=[x0,y0,z0]
t
,定义p
t
点相对于p0点的偏移矢量δ=(δx,δy,δz),则矢量o6o
b
在基坐标系下可表示为下式:
[0055][0056]
其中,δy0=o6p0·
n
c3
,轨迹圆c6的圆心o6在激光跟踪仪测量坐标系下的坐标矢量
为进一步可得位移矢量q
′
:
[0057][0058]
为了保证位移矢量的误差尽可能小,在机器人空间中随机采样十个点p
i
,
b
p
i
为靶球在基坐标系下的坐标矢量,
c
p
i
为靶球在机器人默认工具坐标系下的坐标矢量,基于最小二乘拟合方法计算得位移矢量q
″
。
[0059][0060]
通过公式分别计算位移矢量q
′
、q
″
位移矢量误差δe,选取其中误差小的位移矢量为坐标系转换矩阵中的位移矢量q:
[0061][0062]
q=min{δe(q
i
),q
i
∈{q
′
,q
″
}}
[0063]
对于非系统误差,其在机器人使用过程中产生,且会随着工作温度、运行时间和运动姿态等因素不断变化。操作工业机器人在不同运行状态(刚度、负载、温度)下运动,使用激光跟踪仪测量其实际位置,进一步通过坐标系转换矩阵运算,对激光跟踪仪测量到的实际数据进行转换,将其从激光跟踪仪坐标系转换到机器人坐标系上,对机器人实际位姿和理论位姿做误差运算,得到机器人位姿误差。
[0064]
按照<位姿误差,机器人运行状态(刚度、负载、温度)>的格式存储为数据样本,通过实验采集,构建大样本的机器人运动误差数据集。
[0065]
步骤2:构建深度强化学习网络模型,确定学习网络输入输出层。
[0066]
图4是actor
‑
critic网络逻辑结构图,actor
‑
critic网络提供了一种深度强化学习网络设计框架,使用两个功能不同的网络共同实现机器人模型与当前环境的交互学习,分别为actor神经网络和critic神经网络。actor神经网络本质上是一个dpg网络,根据当前环境状态s(包含tcp位姿p、刚度k、温变t、负载η)计算生成策略,产生具体的关节运动动作作为机器人运动的输入,与环境进行交互。critic神经网络用于评估actor网络在状态s下产生的策略关节动作输出,确定此时情况是好是坏,通过一个值来衡量,并将这一衡量值返回actor神经网络学习,从而进行参数优化,使代价函数收敛到全局最优。
[0067]
以机器人的末端执行位置tcp位姿以及刚度k、温变t、负载η状态值作为网络的输入层,末端执行位置tcp位姿由坐标position(x,y,z)和欧拉角orientation(α,β,γ)构成,但由于机器人的运动偏差一般都极小,如果以该理论位置对应的误差值为输出层,会使得网络的输出与输入极其相似,导致学习难度提高,以致无法正确得到学习结果。因此,为了使网络的输入和输出尽可能远离,将输入和输出建立非线性关系,以机器人各关节角度值作为网络的输出,用δjoint_angle(a1,a2,a3,a4,a5,a6)表示,最后机器人的tcp位姿也可通过对关节角度进行正运动学计算得到。
[0068]
机器人刚度、温变、负载等非系统误差在短周期变化微小,且是时间的函数。若直接将影响因素数据作为网络输入,由于始终缺乏变化,在经历基于梯度的网络参数多次更新中,与其相连接的神经元参数,会被认为学习价值低,数值会压得很小,而且会被快速固定,这样相当于忽略了非系统误差因素。因此,将时间信号t以及时间信号函数sin(t)与ln(t)作为网络的输入,由于时变信号的影响因素存在周期性,或是存在指对数关系,使得强
化学习网络使用的神经元变少,而且可以更快更多地学习特征信息。最后网络的输入输出如表1所示。
[0069]
表1机器人深度强化学习网络输入输出表
[0070][0071]
步骤3:完成强化学习网络模型的预训练,训练得到网络模型参数。
[0072]
在机器人仿真交互软件里搭建强化学习网络模型虚拟训练虚拟场景,通过udp协议与python进行通信,实现深度强化学习训练网络与机器人仿真交互场景进行交互训练网络,如图5所示,训练深度强化学习网络流程如下所述:
[0073]
(1)将步骤1采集的工业机器人的状态特征维度s(包含tcp位姿p、刚度k、温变t、负载η),及其对应的位姿误差参数海量数据集作为训练样本,输入机器人仿真交互软件中,每一局训练开始,实际位置为机器人样本数据集实际位姿,目标位置为机器人样本数据集理论位姿。
[0074]
(2)actor
‑
critic网络从机器人仿真交互环境中得到当前机器人tcp、刚度k、温变t、负载η状态值和时间信号以及时间函数,初始化系统状态在actor网络使用作为输入,进行计算输出当前各关节的运动角度修正值a={δjoint_angle(a1,a2,a3,a4,a5,a6)},并将此值发回机器人仿真交互软件。
[0075]
(3)机器人仿真交互软件接收到关节角度修正值后,对机器人进行各关节限位计算,判断是否都处于限位内,若是则执行各关节运动修正,得到新的状态s
′
。若某一机器人关节没有在限位内,结束当前对局,并将消息传至强化学习网络。
[0076]
(4)在critic网络中分别使用作为输入,得到q值输出v(s),v(s
′
),计算td误差,步长为α,衰减因子γ,探索率ε:
[0077]
δ=r γv(s
′
)
‑
v(s)
[0078]
使用均方差损失函数σ(r γv(s
′
)
‑
v(s,ω))2作critic网络参数ω的梯度更新,并更新actor网络策略参数θ为:
[0079][0080]
对于actor的分值函数可以选择softmax或者高斯分值函数。
[0081]
(4)获取当前机器人位姿与目标位置进行计算得奖励函数r,使用马氏距离负数计
算得:
[0082][0083]
r=η*d
m
(p,p0)
[0084]
其中p为当前位姿,p0为目标位姿,∑为p与p0的协方差矩阵,η<0:
[0085][0086]
如果r值过低,则也需结束当前对局,因为r值低说明网络输出修正值不正常,是无用的,结束对局是为了防止网络记忆错误操作数据进行学习。r值正常,则继续当前对局,将r返回给强化学习网络继续学习。
[0087]
重复上述步骤,从而训练得出actor
‑
critic网络模型结构参数。
[0088]
步骤4:通过训练好的actor
‑
critic网络模型在线针对当前机器人状态计算当前位姿偏差,得到实时位姿误差补偿值,实现闭环的实时误差补偿返回,对非系统误差进行在线补偿,从而实现机器人位姿定位精度在线补偿。
[0089]
本发明提出的位姿定位精度在线补偿方案针对在线输入轨迹中的非系统误差,通过在线误差强化学习方法实现刚度、温变、负载等非系统误差的在线补偿,可以提高工业机器人的绝对定位精度,实现稳健的机器人运动位姿实时补偿与控制。因为此补偿方法无需建立机器人运动学模型、计算速度快,而且具有通用性,为后续机器人实时在线校准、提高在线校准的精度和速度提供了保障。
[0090]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。