1.本发明涉及自然语言处理领域,具体涉及一种基于司法庭审的问题生成方法、装置及计算设备。
背景技术:
2.随着社会经济的发展,文化教育程度的提高,人们的法律意识也越来越强,导致司法庭审案件越来越多。传统的司法庭审,是由庭审法官进行对原告和被告发问,由原告被告回答相关问题,从而形成庭审笔录。这种庭审方式需要的时间较长,花费人力物力相对较高,效率低下。
3.有鉴于此,如何提供一种基于司法庭审的智能提问方案,从而提高庭审效率,就成为亟待解决的技术问题。
技术实现要素:
4.鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的基于司法庭审的问题生成方法、装置及计算设备。
5.根据本发明的一个方面,提供一种基于司法庭审的问题生成方法,包括:
6.利用编码器对诉状文本进行编码处理,生成针对所述诉状文本的第一语义向量;
7.利用分类器对所述第一语义向量进行处理,得到表示所述诉状文本的案件类别的类别标签;
8.将所述第一语义向量与所述类别标签进行拼接,得到第一拼接向量;
9.利用解码器对所述第一拼接向量进行解码处理,生成庭审法官的首个提问语句。
10.可选地,根据本发明的基于司法庭审的问题生成方法,还包括:利用所述编码器对庭审的历史对话进行编码处理,生成针对所述历史对话的第二语义向量,其中所述历史对话包括庭审法官的提问语句和原被告的回答语句;将所述第二语义向量与所述类别标签进行拼接,得到第二拼接向量;利用所述解码器对所述第二拼接向量进行解码处理,生成庭审法官的后续提问语句。
11.可选地,在根据本发明的基于司法庭审的问题生成方法中,所述利用所述编码器对庭审的历史对话进行编码处理,包括:从所述历史对话中获取预定数目个最近的对话语句;利用所述编码器对所获取的对话语句进行编码。
12.可选地,在根据本发明的基于司法庭审的问题生成方法中,所述从所述历史对话中获取预定数目个最近的对话语句,包括:当所述历史对话中包括的对话语句的数量小于所述预定数目时,则获取所述历史对话中的所有对话语句。
13.可选地,在根据本发明的基于司法庭审的问题生成方法中,所述编码器和解码器采用rnn网络、lstm网络或者gru网络。
14.可选地,在根据本发明的基于司法庭审的问题生成方法中,所述分类器采用softmax分类器
15.根据本发明的一个方面,提供一种基于司法庭审的问题生成装置,包括:
16.编码器,适于对诉状文本进行编码处理,生成针对所述诉状文本的第一语义向量;
17.分类器,适于对所述第一语义向量进行处理,得到表示所述诉状文本的案件类别的类别标签;
18.拼接单元,适于将所述第一语义向量与所述类别标签进行拼接,得到第一拼接向量;
19.解码器,适于对所述第一拼接向量进行解码处理,生成庭审法官的首个提问语句。
20.可选地,在根据本发明的基于司法庭审的问题生成装置中,所述编码器还适于,对庭审的历史对话进行编码处理,生成针对所述历史对话的第二语义向量,其中所述历史对话包括庭审法官的提问语句和原被告的回答语句;所述拼接单元还适于,将所述第二语义向量与所述类别标签进行拼接,得到第二拼接向量;所述解码器还适于,对所述第二拼接向量进行解码处理,生成庭审法官的后续提问语句。
21.根据本发明的又一个方面,提供一种计算设备,包括:至少一个处理器;和存储有程序指令的存储器,其中,所述程序指令被配置为适于由所述至少一个处理器执行,所述程序指令包括用于执行上述方法的指令。
22.根据本发明的又一个方面,提供一种存储有程序指令的可读存储介质,当所述程序指令被计算设备读取并执行时,使得所述计算设备执行上述的方法。
23.本发明将神经网络语言模型应用到司法领域,基于诉状文本自动确定案件类别信息,基于诉状文本和案件类别信息确定庭审法官的首个提问语句,并基于历史庭审对话和案件类别信息,自动生成下一步的提问语句,能够显著提高庭审效率。
24.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
25.通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
26.图1示出了根据本发明一个实施例的基于司法庭审的提问系统100的示意图;
27.图2示出了根据本发明一个实施例的计算设备200的示意图;
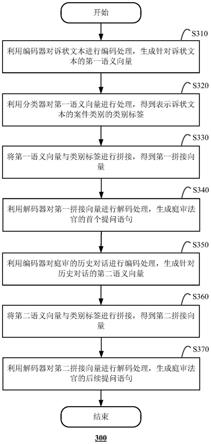
28.图3示出了根据本发明一个实施例的基于司法庭审的问题生成方法300的流程图;
29.图4示出了根据本发明一个实施例的基于司法庭审的问题生成装置400的示意图。
具体实施方式
30.下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
31.图1示出了根据本发明一个实施例的基于司法庭审的提问系统100的示意图。如图
1所示,提问系统100包括终端设备110和计算设备200。
32.终端设备110具体可以是桌面电脑、笔记本电脑等个人计算机,也可以是手机、平板电脑、多媒体设备、智能音箱、智能可穿戴设备等,但不限于此。计算设备200用于向终端设备110提供服务,其可以实现为服务器,例如应用服务器、web服务器等;也可以实现为桌面电脑、笔记本电脑、处理器芯片、平板电脑等,但不限于此。
33.根据一种实施例,计算设备200可以提供智能庭审服务,终端设备110可以经由互联网与计算设备200建立连接,从而使得用户可以经由终端设备110与计算设备200进行人机对话。具体地,计算设备200可以基于诉状文本自动确定案件类别信息,并基于诉状文本和案件类别信息,自动生成庭审法官的首个提问语句,将该提问语句发送到终端设备110,由终端设备110对该提问语句进行播报。
34.终端设备110还可以采集用户的语音数据,例如原被告针对提问语句进行回答的语音数据,并对语音数据进行语音识别处理,得到回答语句,或者,终端设备也可以将语音数据发送到计算设备200,由计算设备200对语音数据进行语音识别处理,得到回答语句。
35.进一步,计算设备200还可以基于历史庭审对话(包括自动生成的提问语句和原被告的回答语句)和案件类别信息,自动生成下一步的提问语句发送到终端设备110。
36.在一个实施例中,基于司法庭审的提问系统100还包括数据存储装置120。数据存储装置120可以是关系型数据库例如mysql、access等,也可以是非关系型数据库例如nosql等;可以是驻留于计算设备200中的本地数据库,也可以作为分布式数据库例如hbase等设置于多个地理位置处,总之,数据存储装置120用于存储数据,本发明对数据存储装置120的具体部署、配置情况不做限制。计算设备200可以与数据存储装置120连接,并获取数据存储装置120中所存储的数据。例如,计算设备200可以直接读取数据存储装置120中的数据(在数据存储装置120为计算设备200的本地数据库时),也可以通过有线或无线的方式接入互联网,并通过数据接口来获取数据存储装置120中的数据。
37.在本发明的实施例中,数据存储装置120适于存储文本生成模型,该文本生成模型适于根据诉状文本和/或庭审对话以及案件类别信息,生成庭审法官的提问语句。文本生成模型是一个序列到序列(seq2seq)模型,包括编码器和解码器,编码器适于对诉状文本或者庭审对话进行编码处理,生成针对诉状文本的第一语义向量或者针对庭审对话的第二语义向量;文本生成模型中还包括分类器,适于对第一语义向量进行处理,得到表示诉状文本的案件类别的类别标签;解码器的输入为第一语义向量与类别标签的第一拼接向量,或者第二语义向量与类别标签的第二拼接向量,对第一拼接向量进行解码,生成庭审法官的首个提问语句,对第二拼接向量进行解码,生成庭审法官的后续提问语句。
38.数据存储装置120还适于存储历史庭审数据,计算设备200可以将历史庭审数据作为训练样本集,来训练上述的文本生成模型。具体地,训练样本集中的每个训练样本包括诉状文本和庭审笔录,诉状文本具有标注的案件类别标签,庭审笔录包括庭审中法官的提问语句和原被告的回答语句。
39.本发明实施例的基于司法庭审的问题生成方法可以在计算设备200中执行。图2示出了根据本发明一个实施例的计算设备200的结构图。如图2所示,在基本的配置202中,计算设备200典型地包括系统存储器206和一个或者多个处理器204。存储器总线208可以用于在处理器204和系统存储器206之间的通信。
40.取决于期望的配置,处理器204可以是任何类型的处理,包括但不限于:微处理器(μp)、微控制器(μc)、数字信息处理器(dsp)或者它们的任何组合。处理器204可以包括诸如一级高速缓存210和二级高速缓存212之类的一个或者多个级别的高速缓存、处理器核心214和寄存器216。示例的处理器核心214可以包括运算逻辑单元(alu)、浮点数单元(fpu)、数字信号处理核心(dsp核心)或者它们的任何组合。示例的存储器控制器218可以与处理器204一起使用,或者在一些实现中,存储器控制器218可以是处理器204的一个内部部分。
41.取决于期望的配置,系统存储器206可以是任意类型的存储器,包括但不限于:易失性存储器(诸如ram)、非易失性存储器(诸如rom、闪存等)或者它们的任何组合。系统存储器106可以包括操作系统220、一个或者多个应用222以及程序数据224。应用222实际上是多条程序指令,其用于指示处理器204执行相应的操作。在一些实施方式中,应用222可以布置为在操作系统上使得处理器204利用程序数据224进行操作。
42.计算设备200还可以包括有助于从各种接口设备(例如,输出设备242、外设接口244和通信设备246)到基本配置202经由总线/接口控制器230的通信的接口总线240。示例的输出设备242包括图形处理单元248和音频处理单元250。它们可以被配置为有助于经由一个或者多个a/v端口252与诸如显示器或者扬声器之类的各种外部设备进行通信。示例外设接口244可以包括串行接口控制器254和并行接口控制器256,它们可以被配置为有助于经由一个或者多个i/o端口258和诸如输入设备(例如,键盘、鼠标、笔、语音输入设备、触摸输入设备)或者其他外设(例如打印机、扫描仪等)之类的外部设备进行通信。示例的通信设备246可以包括网络控制器260,其可以被布置为便于经由一个或者多个通信端口264与一个或者多个其他计算设备262通过网络通信链路的通信。
43.网络通信链路可以是通信介质的一个示例。通信介质通常可以体现为在诸如载波或者其他传输机制之类的调制数据信号中的计算机可读指令、数据结构、程序模块,并且可以包括任何信息递送介质。“调制数据信号”可以这样的信号,它的数据集中的一个或者多个或者它的改变可以在信号中编码信息的方式进行。作为非限制性的示例,通信介质可以包括诸如有线网络或者专线网络之类的有线介质,以及诸如声音、射频(rf)、微波、红外(ir)或者其它无线介质在内的各种无线介质。这里使用的术语计算机可读介质可以包括存储介质和通信介质二者。
44.在根据本发明的计算设备200中,应用222包括基于司法庭审的问题生成装置400,装置400包括多条程序指令,这些程序指令可以指示处理器104执行基于司法庭审的问题生成方法300。
45.图3示出了根据本发明一个实施例的基于司法庭审的问题生成方法300的流程图。方法300适于在计算设备(例如前述计算设备200)中执行。
46.如图3所示,方法300始于步骤s310。在步骤s310中,利用编码器对诉状文本进行编码处理,生成针对诉状文本的第一语义向量。诉状文本可以是上诉状对应的文本或者起诉状对应的文本。若诉状为纸质版,则可以启用ocr自动扫描系统,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式。若诉状为文本格式的电子版,则可以直接进行处理。
47.在将诉状文本输入到编码器前,首先对诉状文本进行分句处理,得到针对诉状文本的多个句子,然后,对每个句子进行分词处理,得到针对每个句子的多个词语,最后将每
个词语转换为词向量(embedding),得到针对诉状文本的词向量序列。将词向量序列中的词向量按照顺序输入到编码器,由编码器输出针对诉状文本的第一语义向量。
48.编码器可以采用基于时间序列的神经网络,例如rnn网络、lstm网络或者gru网络。
49.在一种实现方式中,还可以在编码器中引入注意力机制(attention)。具体地,词向量序列中的每个词向量在编码器中进行处理时,都会对应生成一个隐藏向量,通过获取每个隐藏向量对应的注意力权重,并基于注意力权重对词向量序列对应的隐藏向量序列进行加权求和,能够得到带注意力的第一语义向量。
50.在步骤s320中,利用分类器对第一语义向量进行处理,得到表示诉状文本的案件类别的类别标签。分类器可以采用softmax分类器或者其他公知的分类器,将第一语义向量输入到分类器后,分类器会输出对应的类别标签。分类器可以对诉状文本进行多层次分类,例如案件类别包括民事纠纷、刑事纠纷、行政纠纷等几个大类,民事纠纷又分为财产纠纷、离婚纠纷、损害赔偿纠纷、合同纠纷、著作权纠纷等几个小类,每个类别具有一个类别标签(类别编码)。
51.例如,输入的诉状文本为:“本院诉争的80万元和东阳市人民法院2013东商初字第1881号原告叶小良和被告陈妙珍之间的80万元系同一笔借款,1881号已经调解结案,本案系重复或虚假诉讼,请求法庭驳回原告诉请。”52.则经分类器分类后,确定的案件类别为:民事纠纷-财产纠纷。
53.在步骤s330中,将第一语义向量与类别标签进行拼接,得到第一拼接向量。
54.在步骤s340中,利用解码器对第一拼接向量进行解码处理,生成庭审法官的首个提问语句。解码器可以采用基于时间序列的神经网络,例如rnn网络、lstm网络或者gru网络。解码器每一步解码下一个词在整个词表的概率,选取概率最大的作为下一个要生成的词,最终解码出第一个提问语句。
55.例如,针对上述的诉状文本,生成的首个提问语句为:
[0056]“根据《民诉法》规定谁主张谁举证的规则,依照最高人民法院《关于民事诉讼的若干规定》。原告方有无新的证据提供?”[0057]
计算设备200生成首个提问语句后,将该提问语句发送到终端设备110,由终端设备110对该提问语句进行播报,以便原被告针对该提问语句进行回答。终端设备110可以采集原被告回答的语音数据,该语音数据可以通过终端设备110或者计算设备200进行语音识别(automatic speech recognition,asr),得到回答语句(文本)。asr语音转文字是实时转录,为了避免歧义问题,首先会对庭审话语进行降噪处理。在转录过程中一般转录最小单位为字级别,最大单位为句子级别,然后对asr的结果进行平滑处理,包含消除断句错误、删除口语重复、消除实体识别错误、消除法律用语识别错误等。
[0058]
在步骤s350中,利用编码器对庭审的历史对话进行编码处理,生成针对历史对话的第二语义向量。
[0059]
历史对话是指庭审过程中,到当前时刻为止的庭审对话,包括庭审法官的提问语句和原被告的回答语句,可以从历史对话中获取预定数目(例如5)个最近的对话语句,当历史对话中包括的对话语句的数量小于预定数目时,则获取历史对话中的所有对话语句。
[0060]
在将获取的历史对话输入到编码器前,首先对历史对话进行分句处理,得到多个句子,然后,对每个句子进行分词处理,得到针对每个句子的多个词语,最后将每个词语转
换为词向量(embedding),得到针对历史对话的词向量序列。将词向量序列中的词向量按照顺序输入到编码器,由编码器输出针对历史对话的第二语义向量。
[0061]
词向量序列中的每个词向量在编码器中进行处理时,都会对应生成一个隐藏向量,通过获取每个隐藏向量对应的注意力权重,并基于注意力权重对词向量序列对应的隐藏向量序列进行加权求和,能够得到带注意力的第二语义向量。
[0062]
在步骤s360中,将第二语义向量与类别标签进行拼接,得到第二拼接向量。
[0063]
在步骤s370中,利用解码器对第二拼接向量进行解码处理,生成庭审法官的后续提问语句。
[0064]
重复上述步骤s350~步骤s370,完成庭审,并形成庭审记录。
[0065]
以下介绍本发明实施例中文本生成模型的训练过程。
[0066]
如前所述,文本生成模型是一个序列到序列(seq2seq)模型,包括编码器和解码器,在本发明实施例中,文本生成模型还包括与编码器和解码器连接的分类器。
[0067]
可以将历史庭审数据作为训练样本集,来训练上述的文本生成模型。具体地,训练样本集中的每个训练样本包括诉状文本和庭审笔录,诉状文本具有标注的案件类别标签,庭审笔录包括庭审中法官的提问语句和原被告的回答语句。将训练样本输入到待训练的文本生成模型,根据分类器的输出与标注的类别标签,确定第一损失,根据解码器的输出与训练样本中的提问语句,确定第二损失,基于第一损失与第二损失之和来调整模型参数,直到模型收敛,得到训练好的文本生成模型。
[0068]
图4示出了根据本发明一个实施例的基于司法庭审的问题生成装置400的示意图,装置400驻留在计算设备中。参照图4,装置400包括:
[0069]
编码器410,适于对诉状文本进行编码处理,生成针对所述诉状文本的第一语义向量;
[0070]
分类器420,适于对所述第一语义向量进行处理,得到表示所述诉状文本的案件类别的类别标签;
[0071]
拼接单元430,适于将所述第一语义向量与所述类别标签进行拼接,得到第一拼接向量;
[0072]
解码器440,适于对所述第一拼接向量进行解码处理,生成庭审法官的首个提问语句。
[0073]
编码器410还适于,对庭审的历史对话进行编码处理,生成针对所述历史对话的第二语义向量,其中所述历史对话包括庭审法官的提问语句和原被告的回答语句;
[0074]
拼接单元430还适于,将所述第二语义向量与所述类别标签进行拼接,得到第二拼接向量;
[0075]
所述解码器440还适于,对所述第二拼接向量进行解码处理,生成庭审法官的后续提问语句。
[0076]
编码器410、分类器420、拼接单元元430和解码器440所执行的具体处理,可参照上述方法300,这里不做赘述。
[0077]
以上实施例的应用场景是针对法院设计的一种网上庭审系统。基于类似的原理,本发明实施例的问题生成方法还可以适用于其他应用场景,例如还可以包括公安审讯、检察院等司法机构。在公安审讯场景下,能够自动生成公安人员的提问语句;在检察院审讯场
景下,能够自动生成检察人员的提问语句。
[0078]
在此提供的算法和显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与基于在此的示教一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。
[0079]
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。