技术特征:
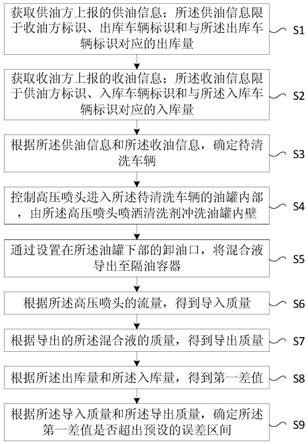
1.一种自动驾驶汽车决策方法,其特征在于,包括:获取不同驾驶场景下的标准驾驶演示数据,根据标准驾驶演示数据进行模仿学习,得到不同驾驶场景下的最优奖励函数;基于所述最优奖励函数对对应的驾驶动作进行强化学习训练,得到下层驾驶动作决策模型;根据所述驾驶场景获取对应的交通状态,通过所述交通状态基于强化学习确定与所述下层驾驶动作决策模型对应的上层驾驶场景决策模型;检测到汽车处于自动驾驶模式中,获取所述自动驾驶模式的实时交通状态,根据所述实时交通状态,输入所述上层驾驶场景决策模型,输出匹配的实时驾驶场景,根据所述实时驾驶场景确定对应的下层驾驶动作决策模型,并确定实时车辆数据输入至所述下层驾驶动作决策模型,得到所述下层驾驶动作决策模型输出的驾驶动作并执行。2.根据权利要求1中所述的自动驾驶汽车决策方法,其特征在于,所述根据标准驾驶演示数据进行模仿学习,得到不同驾驶场景下的最优奖励函数,包括:步骤1.1:获取所述不同驾驶场景下的标准驾驶演示数据,计算所述标准驾驶演示数据的特征统计期望;步骤1.2:初始化状态特征权重;步骤1.3:更新奖励函数;步骤1.4:采用最大熵逆强化学习的方法, 利用正向强化学习的方法寻找多组最/次优的轨迹,用概率较大的多组轨迹估计当前奖励函数下的轨迹的期望特征统计量;步骤1.5:构建拉格朗日函数最大化专家轨迹的出现概率,利用最大似然法对求解梯度,利用梯度下降法更新;步骤1.6:重复上述步骤1.3至步骤1.5,直至梯度值到达收敛阈值,收敛至最优权重;步骤1.7:得到该驾驶场景下的最优奖励函数。3.根据权利要求2中所述的自动驾驶汽车决策方法,其特征在于,所述采用最大熵逆强化学习的方法, 利用正向强化学习的方法寻找多组最/次优的轨迹,用概率较大的多组轨迹估计当前奖励函数下的轨迹的期望特征统计量,包括:步骤2.1:在所述更新奖励函数下进行正向强化学习训练,将训练时的n组次优轨迹及奖励保存至轨迹库;步骤2.2: 用训练好的模型测试,生成m组测试轨迹及其奖励并加入轨迹库;步骤2.3:在轨迹库中选取奖励最大的前h组数据作为当前奖励函数下的最/次优轨迹输出,对这些轨迹运用最大熵逆强化学习的原理求解每一个轨迹的概率,然后估计轨迹的期望特征统计量。4.根据权利要求1中所述的自动驾驶汽车决策方法,其特征在于,所述基于所述最优奖励函数对对应的驾驶动作进行训练,得到下层驾驶动作决策模型,包括:
步骤3.1:选择一种驾驶场景下训练得到的最优奖励函数;步骤3.2:初始化网络模型参数;步骤3.3:初始化环境、车辆状态;步骤3.4:基于车辆当前的状态s,利用贪婪策略在网络模型估计出的最优动作和随机动作之间随机选取动作;步骤3.5:在当前状态s采取动作后得到新的状态s’,对s’进行特征统计;步骤3.6:利用特征统计得到的特征向量与模仿学习训练出的特征权重相乘,即奖励函数表达式,可以得到该状态采取该动作后的奖励r;步骤3.7:将初始状态s、动作、奖励值r以及更新状态s’作为样本(s,,r,s’)保存至经验回放池;步骤3.8:智能体在经验回放池中通过批次采样训练驾驶动作决策模型,计算损失函数,通过梯度下降的方法优化决策模型参数;步骤3.9:重复上述步骤3.4至步骤3.8,发生碰撞或到达终止时间即终止,终止后从步骤3.3开始新回合训练直至模型收敛,训练回合结束;步骤3.10:输出该驾驶场景下的下层驾驶动作决策模型。5.根据权利要求1中所述的自动驾驶汽车决策方法,其特征在于,所述方法还包括:所述上层驾驶场景决策模型的决策时间的时间间隔为所述下层驾驶动作决策模型的决策时间的时间间隔的3倍。6.根据权利要求1中所述的自动驾驶汽车决策方法,其特征在于,所述交通状态,包括:自车速度、自车横纵向位置、自车与周围车辆的相对位置。7.根据权利要求1中所述的自动驾驶汽车决策方法,其特征在于,所述特征统计量,包括:速度特征、加速度特征、加加速度特征、跟车距离特征、碰撞时间特征。8.一种自动驾驶汽车决策装置,其特征在于,所述装置包括:获取模块,用于获取不同驾驶场景下的标准驾驶演示数据,根据标准驾驶演示数据进行模仿学习,得到不同驾驶场景下的最优奖励函数;第一训练模块,用于基于所述最优奖励函数对对应的驾驶动作进行强化学习训练,得到下层驾驶动作决策模型;第二训练模块,用于根据所述驾驶场景获取对应的交通状态,通过所述交通状态基于强化学习确定与所述下层驾驶动作决策模型对应的上层驾驶场景决策模型;自动驾驶模块,用于检测到汽车处于自动驾驶模式中,获取所述自动驾驶模式的实时交通状态,根据所述实时交通状态,输入所述上层驾驶场景决策模型,输出匹配的实时驾驶场景,根据所述实时驾驶场景确定对应的下层驾驶动作决策模型,并确定实时车辆数据输入至所述下层驾驶动作决策模型,得到所述下层驾驶动作决策模型输出的驾驶动作并执行。9.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算
机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至7任一项所述自动驾驶汽车决策方法的步骤。10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现如权利要求1至7任一项所述自动驾驶汽车决策方法的步骤。
技术总结
本发明实施例提供一种自动驾驶汽车决策方法及装置,所述方法包括:获取不同驾驶场景下的标准驾驶演示数据,根据标准驾驶演示数据进行模仿学习,得到不同驾驶场景下的最优奖励函数;基于最优奖励函数对对应的驾驶动作进行强化学习训练,得到下层驾驶动作决策模型;根据驾驶场景获取对应的交通状态,基于强化学习确定与下层驾驶动作决策模型对应的上层驾驶场景决策模型;检测到汽车处于自动驾驶模式中,通过上层驾驶场景决策模型,输出匹配的实时驾驶场景,然后确定对应的下层驾驶动作决策模型,输出对应的驾驶动作并执行。采用本方法能够更精确地对驾驶数据等进行规划,增加驾驶行为与人类驾驶行为的匹配度。行为与人类驾驶行为的匹配度。行为与人类驾驶行为的匹配度。
技术研发人员:裴晓飞 杨哲
受保护的技术使用者:武汉理工大学
技术研发日:2021.08.18
技术公布日:2021/10/28
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。