1.本发明涉及人工智能技术领域,尤其涉及政务问题生成方法及装置。
背景技术:
2.问题生成(question generation,qg)是指根据文章和答案来生成相关问题,其答案可从文章中获得。主要应用场景有:对话系统中,聊天机器人主动抛出问题增加交互的持续性;在问答和机器阅读理解数据集构建中自动生成问题可减少人工拆解的工作;在构建question
‑
answer语料过程中可自动生成问题,有利于问答系统原始问答数据的快速构建。目前政务领域缺乏统一的问答语料集,为减少人工拆解成本,应用问题生成技术对政务领域数据自动生成问题,帮助构建数据集。
3.目前的政务问题生成方法对于中文数据问题生成效果较差,因此,亟需一种可以克服上述问题的政务问题生成方案。
技术实现要素:
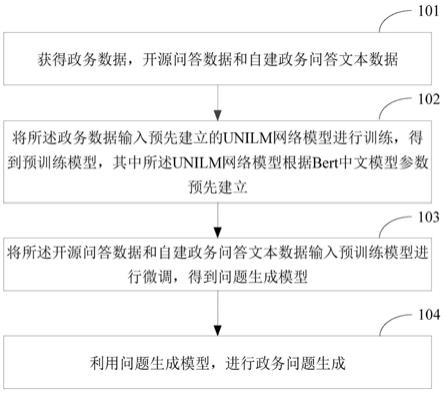
4.本发明实施例提供一种政务问题生成方法,用以提高中文数据问题生成效果,该方法包括:
5.获得政务数据,开源问答数据和自建政务问答文本数据;
6.将所述政务数据输入预先建立的unilm网络模型进行训练,得到预训练模型,其中所述unilm网络模型根据bert中文模型参数预先建立;
7.将所述开源问答数据和自建政务问答文本数据输入预训练模型进行微调,得到问题生成模型;
8.利用问题生成模型,进行政务问题生成。
9.本发明实施例提供一种政务问题生成装置,用以提高中文数据问题生成效果,该装置包括:
10.数据获得模块,用于获得政务数据,开源问答数据和自建政务问答文本数据;
11.模型训练模块,用于将所述政务数据输入预先建立的unilm网络模型进行训练,得到预训练模型,其中所述unilm网络模型根据bert中文模型参数预先建立;
12.模型微调模块,用于将所述开源问答数据和自建政务问答文本数据输入预训练模型进行微调,得到问题生成模型;
13.问题生成模块,用于利用问题生成模型,进行政务问题生成。
14.本发明实施例还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述政务问题生成方法。
15.本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有执行上述政务问题生成方法的计算机程序。
16.本发明实施例通过获得政务数据,开源问答数据和自建政务问答文本数据;将所述政务数据输入预先建立的unilm网络模型进行训练,得到预训练模型,其中所述unilm网
络模型根据bert中文模型参数预先建立;将所述开源问答数据和自建政务问答文本数据输入预训练模型进行微调,得到问题生成模型;利用问题生成模型,进行政务问题生成。本发明实施例对于没有中文开源的unilm网络模型,在建立时采用bert中文模型参数进行初始化,然后将政务数据输入建立好的unilm网络模型进行训练得到预训练模型,通过融合开源问答数据和自建政务问答文本数据来进行下游任务的预训练模型微调,从而有效提升模型效果以及中文数据问题生成效果。
附图说明
17.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。在附图中:
18.图1为本发明实施例中政务问题生成方法示意图;
19.图2为本发明具体实施例中政务问题生成方法流程图;
20.图3为本发明实施例中政务问题生成装置结构图;
21.图4是本发明实施例的计算机设备结构示意图。
具体实施方式
22.为使本发明实施例的目的、技术方案和优点更加清楚明白,下面结合附图对本发明实施例做进一步详细说明。在此,本发明的示意性实施例及其说明用于解释本发明,但并不作为对本发明的限定。
23.首先,对本发明实施例中的技术名词进行介绍:
24.问题生成(question generation,qg):是指根据文章来生成相关问题,其答案可从文章中获得,可预置或者计算得到。
25.nqg(neural question generation):神经网络问题生成。
26.词嵌入(word
‑
embedding):自然语言处理中语言模型与表征技术的统称,把维数为所有次数量的高维稀疏空间嵌入到低维稠密的向量空间汇中。
27.预训练模型:nlp中的预训练模型是在海量语料数据集上学习到能够基于上下文的文本表征信息预测word tokens。可用于解决下游的具体任务。深度学习对于数据尤其是标注数据量要求高,预训练模型可以将强大的表征能力应用到各项任务中,解决了某些任务中缺乏大量标注数据的问题。
28.如前所述,目前的政务问题生成方法对于中文数据问题生成效果较差。问题生成主要分为基于规则(rule
‑
based)和基于神经网络(neural approach)的方法。基于规则主要提取目的句子的相关实体,填入人工编写的模板中(根据规则和语法),再根据排序方法选择一个或几个最合适的模板进行生成问题。优点是很流畅,缺点是很依赖人工模板,质量不高。基于神经网络(neural approach)采用seq2seq模型,将段落和答案编码进入,中文因为缺少相关数据集,相关研究和应用成果较少,效果较差。基于预训练模型在自然语言理解的各项任务中取得绝对的优势效果。
29.为了提高中文数据问题生成效果,本发明实施例提供一种政务问题生成方法,如
图1所示,该方法可以包括:
30.步骤101、获得政务数据,开源问答数据和自建政务问答文本数据;
31.步骤102、将所述政务数据输入预先建立的unilm网络模型进行训练,得到预训练模型,其中所述unilm网络模型根据bert中文模型参数预先建立;
32.步骤103、将所述开源问答数据和自建政务问答文本数据输入预训练模型进行微调,得到问题生成模型;
33.步骤104、利用问题生成模型,进行政务问题生成。
34.由图1所示可以得知,本发明实施例通过获得政务数据,开源问答数据和自建政务问答文本数据;将所述政务数据输入预先建立的unilm网络模型进行训练,得到预训练模型,其中所述unilm网络模型根据bert中文模型参数预先建立;将所述开源问答数据和自建政务问答文本数据输入预训练模型进行微调,得到问题生成模型;利用问题生成模型,进行政务问题生成。本发明实施例对于没有中文开源的unilm网络模型,在建立时采用bert中文模型参数进行初始化,然后将政务数据输入建立好的unilm网络模型进行训练得到预训练模型,通过融合开源问答数据和自建政务问答文本数据来进行下游任务的预训练模型微调,从而有效提升模型效果以及中文数据问题生成效果。
35.实施例中,获得政务数据,开源问答数据和自建政务问答文本数据;将所述政务数据输入预先建立的unilm网络模型进行训练,得到预训练模型,其中所述unilm网络模型根据bert中文模型参数预先建立。
36.本实施例中,将所述政务数据输入预先建立的unilm网络模型进行训练,得到预训练模型,包括:
37.对所述政务数据进行分词处理,得到输入序列,所述输入序列包含多个单词;
38.确定输入序列的表征联合词向量,位置向量和文本段信息;
39.将所述输入序列的表征联合词向量,位置向量和文本段信息输入预先建立的unilm网络模型,输出文本向量表征,其中,所述unilm网络模型中包含多层transformer网络,在所述多层transformer网络中,每一层transformer网络包括:单向语言网络模型,双向语言网络模型和端到端语言网络模型。
40.本实施例中,将所述政务数据输入预先建立的unilm网络模型进行训练,得到预训练模型,还包括:
41.得到输入序列后,利用自注意力掩码矩阵对所述输入序列进行掩盖;
42.确定输入序列的表征联合词向量,位置向量和文本段信息,包括:确定掩盖后输入序列的表征联合词向量,位置向量和文本段信息。
43.下面介绍unilm网络模型结构。首先,进行问题定义:q=argm
q
ax(prob{q|p,a}),q代表生成的问题,p代表一个段落,a表示已知答案。unilm是深度的transformer网络,unilm网络模型中包含多层transformer网络,其预训练过程采用3种无监督的语言模型目标:双向语言网络模型、单向语言网络模型和端到端语言网络模型(sequence
‑
to
‑
sequence lm)。该模型采用一个共享参数的transformer网络的同时还使用了特定的自注意力掩码矩阵(self
‑
attention masks)用以控制预测时候所用到的上下文信息。在下游任务微调时候,可以将unilm网络模型视为单向的编码、双向的编码和端到端模型,以适应不同的下游任务(自然语言理解和生成任务)。在问题生成任务中使用端到端结构,输入文本和问题在文本
中的区间,输出答案。将unilm网络模型与bert模型在glue、squad 2.0和coqa数据集上进行了综合对比。其在3项自然语言生成任务上刷新了记录,其中包括cnn/dailymail摘要生成(rouge
‑
l为40.63,提升了2.16)、coqa的问题生成(f1值为82.5,提升了37.1)、squad的问题生成(bleu
‑
4为22.88,提升了6.5)。
44.具体实施时,在unilm网络模型训练阶段,利用自注意力掩码矩阵对输入序列进行掩盖,随机遮盖一些单词,目标任务是将这些词还原。例如,输入x是一串序列,文本片段,序列表征和bert一样,包括词向量、位置编码、序列编码,序列编码可作为采用单向语言模型、双向语言模型和端到端训练方式。骨干网由24层transformer构成,每一层的输出为下一层的输入。每一层通过掩码矩来控制每个词的注意力范围,以此保证了多个训练目标的联合训练。给定输入序列sequence x=x1
…
xn,(x1为一个单词)通过多层的transformer网络对每个单词得到一个带有上下文信息的向量表征。输入单词序列的表征联合词向量、位置向量和文本段信息。再将输入向量输入到多层transformer网络中,利用其中的自注意力机制联合整个输入序列计算得到文本的表征。在对输入进行遮蔽的时候,遮蔽操作是用预定义的掩码矩阵对其进行替换。再将输入到transformer网络中计算得到输出向量,将输出向量输入到softmax分类器中以预测被遮蔽掉的单词。unilm模型的参数是通过最小化预测的单词和原始真实单词之间的交叉熵损失学习到的。在端到端模式中,结构为“[sos]s1[eos]s2[eos]”,s1(即source segment)在整个segment内部能够注意到任何的单词,s2(target segment)中的单词只能注意到目标部分中上文单词及其自身,还有s1。端到端语言模型的自注意力掩码矩阵,对于源序列掩码矩阵设置为全0,即所有的单词之间是可以相互注意到的。对于目标序列掩码矩阵设置为无穷大,使得源序列看不到目标序列;往下的右上角值设置为无穷大,其他值为0是实现目标段只能注意到上文,忽略其下文。
[0045]
实施例中,将所述开源问答数据和自建政务问答文本数据输入预训练模型进行微调,得到问题生成模型;利用问题生成模型,进行政务问题生成。
[0046]
本实施例中,将所述开源问答数据和自建政务问答文本数据输入预训练模型进行微调,包括:
[0047]
根据所述开源问答数据和自建政务问答文本数据,确定源序列和目标序列;
[0048]
利用自注意力掩码矩阵对所述目标序列进行掩盖;
[0049]
将源序列和掩盖后的目标序列输入预训练模型进行微调。
[0050]
具体实施时,在预训练模型微调中,unilm模型可用于自然语言理解和自然语言生成的下游任务中,通过微调可以使模型更好的应用到下游具体任务中来。自然语言生成任务的微调,类似于使用自注意力掩码进行预训练。令s1和s2分别代表源序列和目标序列。模型的微调是通过随机掩盖s2目标序列中一定比例的单词,让模型学习恢复被掩盖的词,其训练目标是基于上下文最大化被掩盖单词的似然度。问题生成任务是nlg的一种,可表述为一个端到端问题。第一部分是输入文章和答案,第二部分是生成的问题。通过随机掩盖问题中的单词,让模型通过学习如何恢复被掩盖的单词来训练模型参数。我们在训练集上对unilm进行了10个纪元的微调。我们将批量大小设为32,屏蔽概率设为0.7,学习率设为2e
‑
5。标签平滑率为0.1,其他超参数与训练前相同。
[0051]
下面给出一个具体实施例,说明本发明实施例中政务问题生成方案。在本具体实施例中,如图2所示,模型训练阶段:1、进行模型初始化参数,选用官网谷歌开源的bert中文
预训练模型参数作为初始化参数;其表征能力强,模型结构一致;从头训练成本巨大。2、参数更新:用爬取的3个g的政务数据(政务相关的文本数据,不受格式影响)对模型进行预训练更新参数;使得模型对政务领域词汇的表征能力增强。3、预训练和模型本身训练的任务相同,目标分别为单向、双向、端到端任务。
[0052]
模型微调阶段:用开源问答数据(基于百度dureader数据集和wiki百科的问答开源语料)和自建的政务问答数据(通过人工标注和构造的5000对文本数据,数据内容为问题(q)和答案(a))进行微调;混合的原因是开源数据较多但缺乏领域知识,自建数据量较少,实验证明混合可提升模型效果。
[0053]
问题生成阶段:问题生成的过程是使用模型进行decoder解码的过程,输入段落和问题区间,进行encoder编码,解码生成问题。目标数据为我们需要拆解的领域数据,此处为政务数据。数据预处理:将文章和经人工标注的答案进行预处理,获得文段和答案在文段中的区间位置。模型计算:将文段和答案进行unilm模型编码,经过模型计算,解码生成问题。针对不同语言模型的训练目标,设计了四种完形填空任务。在某个完形填空任务中,会随机利用掩码矩阵遮盖一些单词,然后通过transformer网络计算得到相应的输出向量,再把输出向量喂到softmax分类器中,预测被遮盖的单词。unilm参数优化的目标就是最小化被遮盖单词的预测值和真实值之间的交叉熵。
[0054]
具体按如下步骤进行政务问题生成:
[0055]
(1)加载词表,建立分词器;
[0056]
(2)加载bert中文模型,配置网络参数,设置为unilm网络结构;
[0057]
(3)参数更新:加载政务数据,进行模型预训练模型训练。用训练unilm的预训练方法在新数据上进行训练,更新模型参数;
[0058]
(4)下有任务微调:任务为端到端模型结构,目标函数为最大化。开源问答数据(基于百度dureader数据集和wiki百科的问答开源语料)和自建的政务问答数据(通过人工标注和构造的5000对文本数据,数据内容为问题(q)和答案(a))进行微调;混合的原因是开源数据较多但缺乏领域知识,自建数据量较少,实验证明混合可提升模型效果。微调过程:加载q
‑
a数据(开源问答数据(基于百度dureader数据集和wiki百科的问答开源语料)和自建的政务问答数据(通过人工标注和构造的5000对文本数据,数据内容为问题(q)和答案(a))进行微调),问题生成是一种nlg任务,选用端到端结构,微调过程类似于使用自注意掩码进行预训练。令s1和s2分别表示源序列和目标序列,构建出输入[sos]s1[eos]s2[eos]。该模型的微调是通过随机掩盖target序列中一定比例的单词,让模型学习恢复被掩盖的词,其训练目标是基于上下文最大化被掩盖单词的似然度。这点与预训练中略有不同,预训练的时候是随机掩盖掉源序列和目标序列的单词,也就是两端都参与了训练,而微调的时候只有目标序列参与,因为微调更多关注的是目标端。值得注意的是,微调的时候,目标端的结束标识[eos]也可以被掩盖掉,让模型学习预测,这样模型就可以学习出来自动结束nlg任务了。
[0059]
本发明实施例提供的政务问题生成方案可有效的从文档中自动生成问题,帮助解决问答系统的政务领域语料构建问题,减少人工拆解语料的成本,节省时间和成本。对于没有中文开源的unilm模型,选用开源中文bert模型进行初始化,通过在自建政务数据中进行训练微调增强模型对于领域知识的表征。通过融合通用问题生成数据和自建的政务问题生
成数据来进行下游任务的微调来提升模型效果。应用端到端端到端的结构模式,可批量自动生成问题。
[0060]
基于同一发明构思,本发明实施例还提供了一种政务问题生成装置,如下面的实施例所述。由于这些解决问题的原理与政务问题生成方法相似,因此装置的实施可以参见方法的实施,重复之处不再赘述。
[0061]
图3为本发明实施例中政务问题生成装置的结构图,如图3所示,该装置包括:
[0062]
数据获得模块301,用于获得政务数据,开源问答数据和自建政务问答文本数据;
[0063]
模型训练模块302,用于将所述政务数据输入预先建立的unilm网络模型进行训练,得到预训练模型,其中所述unilm网络模型根据bert中文模型参数预先建立;
[0064]
模型微调模块303,用于将所述开源问答数据和自建政务问答文本数据输入预训练模型进行微调,得到问题生成模型;
[0065]
问题生成模块304,用于利用问题生成模型,进行政务问题生成。
[0066]
一个实施例中,所述模型训练模块302进一步用于:
[0067]
对所述政务数据进行分词处理,得到输入序列,所述输入序列包含多个单词;
[0068]
确定输入序列的表征联合词向量,位置向量和文本段信息;
[0069]
将所述输入序列的表征联合词向量,位置向量和文本段信息输入预先建立的unilm网络模型,输出文本向量表征,其中,所述unilm网络模型中包含多层transformer网络,在所述多层transformer网络中,每一层transformer网络包括:单向语言网络模型,双向语言网络模型和端到端语言网络模型。
[0070]
一个实施例中,所述模型训练模块302进一步用于:
[0071]
得到输入序列后,利用自注意力掩码矩阵对所述输入序列进行掩盖;
[0072]
确定输入序列的表征联合词向量,位置向量和文本段信息,包括:确定掩盖后输入序列的表征联合词向量,位置向量和文本段信息。
[0073]
一个实施例中,所述模型微调模块303进一步用于:
[0074]
根据所述开源问答数据和自建政务问答文本数据,确定源序列和目标序列;
[0075]
利用自注意力掩码矩阵对所述目标序列进行掩盖;
[0076]
将源序列和掩盖后的目标序列输入预训练模型进行微调。
[0077]
综上所述,本发明实施例通过获得政务数据,开源问答数据和自建政务问答文本数据;将所述政务数据输入预先建立的unilm网络模型进行训练,得到预训练模型,其中所述unilm网络模型根据bert中文模型参数预先建立;将所述开源问答数据和自建政务问答文本数据输入预训练模型进行微调,得到问题生成模型;利用问题生成模型,进行政务问题生成。本发明实施例对于没有中文开源的unilm网络模型,在建立时采用bert中文模型参数进行初始化,然后将政务数据输入建立好的unilm网络模型进行训练得到预训练模型,通过融合开源问答数据和自建政务问答文本数据来进行下游任务的预训练模型微调,从而有效提升模型效果以及中文数据问题生成效果。
[0078]
基于前述发明构思,如图4所示,本发明还提出了一种计算机设备400,包括存储器410、处理器420及存储在存储器410上并可在处理器420上运行的计算机程序430,所述处理器420执行所述计算机程序430时实现前述政务问题生成方法。
[0079]
基于前述发明构思,本发明提出了一种计算机可读存储介质,所述计算机可读存
储介质存储有计算机程序,所述计算机程序被处理器执行时实现前述政务问题生成方法。
[0080]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
[0081]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0082]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0083]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0084]
最后应说明的是:以上所述实施例,仅为本发明的具体实施方式,用以说明本发明的技术方案,而非对其限制,本发明的保护范围并不局限于此,尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。