1.本发明提供的方案涉及数据存储访问领域,应用于具有多种数据查询引擎的数据访问平台中降低用户访问数据所需要的专业知识门槛;具体涉及一种数据访问请求的路由解析系统及方法。
背景技术:
2.目前大数据领域存储技术层出不穷,常用的就有数据存储查询引擎hive,es,hbase,kudu,clickhouse等以及将这些存储查询引擎作为底层原料而发展出来的新型“存储 计算”型存储引擎如kylin,phoenix等。每个存储引擎为了向上对接业务应用、简化业务应用的使用过程,都会根据自身数据结构设计特点提供相应查询api包供上层应用进行调用,如resthttp,jdbc,javaclient等常用的api包。当数据平台单独采用某一种存储查询引擎作为查询工具一般不存在用户使用需要专业知识门槛的问题。而现实的情况是、由于每种存储查询引擎具有的特性特别贴合某个使用场景,为了同时支持多业务场景,数据平台内往往需要同时采用以上多种数据存储查询引擎对不同的数据进行存储、查询。当同一份数据会存储在多种不同的存储介质上时,不是所有引擎都能访问涉及的每个存储介质,比如数据存储在es中,那只能spark,presto,es可以执行,其他执行引擎是访问不了的。这样当数据平台对外提供数据查询服务时由于采用各存储查询引擎存储的数据不互通,在用户进行数据查询时先要知道目标数据存储在什么地方,再从能够访问这个存储介质的执行引擎中选择最合适的。例如目标数据是存储于hive表还是es索引中、有多个es集群的情况用户查询数据时需要指出具体哪一个es集群。
3.另外目前平台无法联合多个集群的数据进行查询,当目标数据分布于多存储介质中时,只能分别采用不同的数据查询引擎计算并将数据导出后、在本地进行二次计算,这样无疑增加了用户的工作量。
技术实现要素:
4.为了解决具有多种存储查询引擎的数据平台存在的各存储查询引擎存储的数据不互通,用户在进行数据查询时需要了解一定的存储底层专业知识的问题,降低用户使用门槛,扩展平台查询能力。
5.本发明旨在为上述数据平台提供一种根据用户输入sql语句,后台服务自动根据所述sql语句的语言特征参数自动适配具体sql引擎、完成可能的跨集群查询的功能。
6.本发明提供的技术方案,具体实现为:
7.一种数据访问请求的路由解析系统,该系统配置多种数据查询引擎以向外提供数据查询服务,该系统设置有对提供访问的所有数据的元数据进行集中存储管理的元数据信息管理子系统;该路由解析系统根据接收外到的数据查询请求以及所述元数据信息管理子系统中元数据信息解析该数据处理请求;所述路由解析系统根据所述解析结果以及预置的引擎筛选规则,从多种数据查询引擎中自动选出最优的数据查询引擎处理该数据查询请
求。
8.其中、所述元数据管理子系统中存储的提供访问的所有数据的元数据信息包括:各个表资源的存储类型、物理存储分布类型、数据层次、字段信息以及对应的权限人员信息。所述数据查询请求的解析结果中包括目标数据查询类型、目标数据大小、查询所涉及的存储分区的个数以及所涉及的列、该次查询所涉及表资源的元数据信息。
9.具体地、本发明提供的路由解析系统还包括:请求路由服务模块,请求解析服务模块,引擎执行聚合协调模块。所述请求路由服务模块提供多种数据查询入口接收外部的数据查询请求,对接收的数据查询请求进行调度、根据调度结果依次将接收到的数据查询请求发送到所述请求解析服务模块、由所述请求解析服务模块进行解析,并将对应解析结果发送给引擎协调服务模块。所述请求解析服务模块,用于当被所述请求路由服务模块调用对某个数据查询请求进行解析时根据所述元数据管理子系统中的元数据信息对该数据查新进行解析,并将解析结果返回给所述请求路由服务模块。所述引擎执行聚合协调模块,用于根据所述请求路由服务模块发送的所述解析结果结合预置的引擎筛选规则,从多种数据查询引擎中自动选出最优的数据查询引擎处理该数据查询请求。
10.进一步地,所述引擎执行聚合协调模块还根据所述解析结果,结合目标数据分布状况、数据查询引擎历史执行情况、各数据查询引擎实时资源占用情况中一种或多种因素,选择一个最优的执行引擎。
11.与上述数据访问请求的路由解析系统相对应,本发明还提供一种数据访问请求的路由解析方法,该方法包括:预先录入供访问的所有数据的元数据信息,所述元数据信息包括:各个表资源的存储类型、物理存储分布类型、数据层次、字段信息以及对应的权限人员信息;根据接收的数据查询请求以及所述元数据信息解析该数据查询请求以获得对应的解析结果;根据所述解析结果以及预置的筛选规则从可选的多个数据查询引擎中自动选出最优的数据查询引擎对该数据查询请求进行处理。
12.本发明所提供的上述数据访问请求的路由解析方法的具体实现过程与上述数据访问请求的路由解析系统的处理细节相对应。
附图说明
13.图1为本发明提供的数据访问请求的路由解析系统的系统框架示意图;
14.图2为本发明提供的数据访问请求的路由解析系统中元数据管理子系统的部分组成示意图;
15.图3为本发明提供的数据访问请求的路由解析系统中引擎协调服务模块的示意图。
具体实施方式
16.为了使本发明所解决的技术问题、技术方案以及有益效果更加清楚明白,以下结合附图对本发明进行进一步详细说明。应该理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
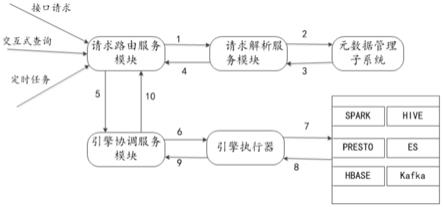
17.如图1所示,本发明提供的数据访问请求的路由解析系统包括请求路由服务模块,请求解析服务模块,元数据管理子系统以及由引擎协调服务模块和引擎执行器组成的引擎
执行聚合协调模块。
18.其中、所述请求路由服务模块提供包括多种数据查询入口接收包括交互式查询、接口请求和定时任务在内的外部数据查询请求,对接收的数据查询请求进行调度、根据调度结果依次将接收到的数据查询请求发送到所述请求解析服务模块、由所述请求解析服务模块进行解析(1),并将对应解析结果发送给引擎协调服务模块(5)。例如,按照接收到的数据查询请求的优先次序,先将优先级高的数据查询请求交由解析服务模块进行解析。
19.所述请求解析服务模块,用于当被所述请求路由服务模块调用对某个数据查询请求进行解析时根据所述元数据管理子系统中的元数据信息(2),获取数据查询请求的目标数据对应的元数据信息对该数据查新进行解析(3),并将解析结果返回给所述请求路由服务模块(4)。所述数据查询请求的解析结果中包括目标数据查询类型、目标数据大小、查询所涉及的存储分区的个数以及所涉及的列、该次查询所涉及表资源的元数据信息。如图2所示,所述元数据管理子系统中用于对提供访问的所有数据的元数据集中存储管理。所述元数据管理子系统中存储的提供访问的所有数据的元数据信息包括:各个表资源的存储类型、物理存储分布类型、数据层次、字段信息以及对应的权限人员信息。
20.所述引擎执行聚合协调模块,用于根据所述请求路由服务模块发送的所述解析结果以及预置的引擎筛选规则(6),从多种数据查询引擎中自动选出最优的数据查询引擎处理该数据查询请求(7)。当执行完该数据查询请求后,将获取的查询结果交由引擎执行器(8)转送引擎协调服务模块(9),最后通过路由服务模块反馈给用户(10)。如图1所示,所述多种数据查询引擎包括spark,hive,presto,es,hbase以及kafka;数据查询引擎的种类不限于上述几种,任何可以用于数据平台提供数据查询服务的引擎都可以包括在内。
21.进一步地,所述引擎执行聚合协调模块根据所述请求路由服务模块发送的所述解析结果以及预置的引擎筛选规则(6)筛选出最优的数据查询引擎包括:根据所述解析结果,结合目标数据分布状况、数据查询引擎历史执行情况、各数据查询引擎实时资源占用情况中一种或多种因素,结合所述预置的引擎筛选规则选择一个最优的数据查询引擎作为执行引擎。如图3所示,所述引擎执行聚合协调模块中引擎协调服务模块还与数据平台的数据查询请求日志以及实时资源监控模块进行通信,用于获取数据查询引擎历史执行情况、各数据查询引擎处理节点实时资源占用情况。
22.所述引擎执行聚合协调模块依据的预置的引擎筛选规则,包括但不限于以下几种情况:当该次数据查询的目标数据存储分布类型是跨集群存储优先选用spark;当该次数据查询类型是简单的历史数据预览则优先选用presto;当该次数据查询只是检索语句则优先选用es;如果该次数据查询是预览实时日志则优先选用kafka;若该次数据查询同时适用于两种以上所列的情况,则根据查询的目标数据的数据量及分区量过滤掉不适合的引擎后(例如presto不适合全表扫描大数据量),对剩余的所有可执行数据查询引擎按预设的数据查询引擎历史执行经验优先次序进行排序得到数据查询引擎优先级队列;然后统计数据查询请求处理日志中与该次数据查询涉及的数据量、分区数量在预设差值范围内,和/或涉及的schema相同的类似历史数据查询请求,根据所述类似历史数据查询请求的各数据查询引擎的处理效率调整所述数据查询引擎优先级队列(例如按照耗时较少的数据查询引擎优先级较高);最后根据各数据查询引擎的处理节点实时资源占用情况从所述优先级队列选出能够处理所述数据查询请求的数据查询引擎作为候选引擎;在所述候选引擎中若最优执行
引擎有空闲则提交,否则选择次优执行引擎、并以此类推。
23.此外,为了防止非授权用户使用数据平台查询无权获取的数据信息,设置所述请求路由服务模块接到数据查询请求对应的解析结果后,先根据所述解析结果中该次查询所涉及的表资源的元数据信息中包含的权限人员信息判断发起该次数据查询请求的用户是否为授权用户,若否、直接丢弃该次数据查询请求。
24.与上述数据访问请求的路由解析系统相对应,本发明还提供一种数据访问请求的路由解析方法,该方法包括:预先录入供访问的所有数据的元数据信息,所述元数据信息包括:各个表资源的存储类型、物理存储分布类型、数据层次、字段信息以及对应的权限人员信息;根据接收的数据查询请求以及所述元数据信息解析该数据查询请求以获得对应的解析结果;根据所述解析结果以及预置的筛选规则从可选的多个数据查询引擎中自动选出最优的数据查询引擎对该数据查询请求进行处理。
25.本发明所提供的上述数据访问请求的路由解析方法的具体实现过程与上述数据访问请求的路由解析系统的处理细节相对应。
26.通过本发明提供的访问请求的路由解析系统及方法,用户在无需知道目标数据存储在什么地方,以及无需知道该采用何种数据查询引擎进行查询的情况下,自动适配最优的数据查询引擎来执行用户的数据查询请求,降低用户使用数据平台进行数据查询的门槛,扩展了数据平台的查询能力。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。