一种基于多源gps数据的出行阻抗模型标定及校核方法
技术领域
1.本发明涉及智慧交通技术领域,具体而言,涉及一种基于多源gps数据的出行阻抗模型标定及校核方法。
背景技术:
2.出行阻抗模型作为交通需求预测模型的子模型,主要用于描述道路使用者在出行过程中花费在道路上的综合成本,其精度直接影响到交通需求预测的结果。但目前出行阻抗模型的标定一般通过单一源采集相应交通数据,导致最终得到的出行阻抗模型存在一定的片面性;且出行阻抗模型一般在标定后缺乏校核及参数调整的过程,导致其在进行交通需求预测时不可避免地会存在一定的随机误差,从而导致交通需求预测的结果精度较低。
技术实现要素:
3.本发明解决的问题是:如何准确通过模型反映相应交通数据,并减少交通需求预测过程中的随机误差。
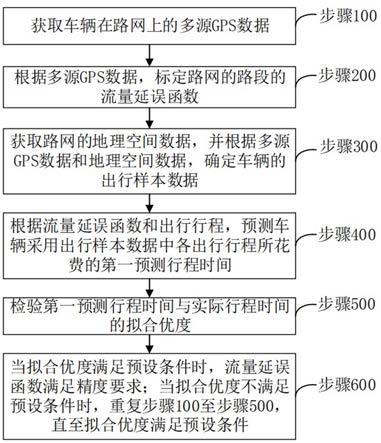
4.为解决上述问题,本发明提供一种基于多源gps数据的出行阻抗模型标定及校核方法,包括:步骤100、获取车辆在路网上的多源gps数据;步骤200、根据所述多源gps数据,标定所述路网的路段的流量延误函数;步骤300、获取所述路网的地理空间数据,并根据所述多源gps数据和所述地理空间数据,确定所述车辆的出行样本数据,其中,所述出行样本数据包括所述车辆的出行行程和所述出行行程所花费的实际行程时间;步骤400、根据所述流量延误函数和所述出行行程,预测所述车辆采用所述出行行程所花费的第一预测行程时间;步骤500、检验所述第一预测行程时间与所述实际行程时间的拟合优度;步骤600、当所述拟合优度满足预设条件时,所述流量延误函数满足精度要求;当所述拟合优度不满足预设条件时,重复所述步骤100至所述步骤500,直至所述拟合优度满足预设条件。
5.可选地,所述步骤200包括:步骤210、根据所述多源gps数据,建立所述路网和所述路段的平均速度融合因子库;步骤220、根据所述多源gps数据和所述平均速度融合因子库,标定所述路段的流量延误函数。
6.可选地,所述步骤210包括:步骤211、根据所述多源gps数据,确定各类所述车辆在不同的所述路段上的运行速度;步骤212、根据所述运行速度,建立所述路网和所述路段的平均速度融合因子库。
7.可选地,所述流量延误函数采用akcelik流量延误函数;所述akcelik流量延误函数为:,其中,为所述路段的行程时间,为所述路段的零流时间,为信号交叉口的无交通流控制延误,为交通需求期望持续时间,为所述路段的饱和度,为修正系数,为所述路段的长度。
8.可选地,所述步骤220包括:步骤221、根据所述多源gps数据和所述平均速度融合因子库,标定所述路段对应的所述akcelik流量延误函数的参数、,并确定所述路段的饱和度及所述路段的行程时间;步骤222、根据所述路段的饱和度、所述路段的行程时间及所述akcelik流量延误函数,标定所述修正系数。
9.可选地,所述步骤300包括:步骤310、获取所述路网的地理空间数据;步骤320、根据所述多源gps数据和所述路网的地理空间数据,确定所述车辆的出行数据;步骤330、根据所述出行数据,筛选出所述出行数据中预定数量的所述出行样本数据。
10.可选地,所述步骤330包括:步骤331、根据所述出行数据进行统计、校核及扩样处理,得到分时段的所述出行数据;步骤332、根据所述流量延误函数和所述分时段的所述出行数据进行高峰时段的交通分配,预测所述路网的每个所述路段的第二预测行程时间;步骤333、根据所述分时段的所述出行数据进行筛选,得到预定数量的所述出行样本数据;所述步骤400包括:根据所述第二预测行程时间,确定所述车辆采用所述出行行程所花费的第一预测行程时间。
11.可选地,所述预设条件为所述拟合优度的决定系数大于0.9。
12.可选地,所述多源gps数据包括出租车gps数据、公交车gps数据、货车gps数据和私家车gps数据。
13.可选地,所述步骤320包括:步骤321、根据所述多源gps数据和所述路网的地理空间数据,识别并聚类各类所述车辆的驻留点;步骤322、根据所述驻留点,确定所述车辆的所述出行数据。
14.本发明与现有技术相比,具有以下有益效果:基于多源gps数据的出行阻抗模型标定及校核方法用于融合多源gps数据挖掘交通流出行特征,并通过交通流出行特征循环标定及校核出行阻抗模型(流量延误函数),最大程度地减少了随机误差造成的影响,保证了最终得到的出行阻抗模型的全面性、可靠性与准确性。而且,基于多源gps数据的出行阻抗模型标定及校核方法通过获取多源gps数据以得到路网交通流出行特征,一方面,相对于通过成本高、精度低、范围小且难以实现的人工调查方法获取交通流出行特征等信息以构建出行阻抗模型而言,gps数据具有体量大、覆盖面广、易于获取且能够全面的分析出各等级道路的交通流出行特征的特点,且能够支撑本地化、精细化的出行阻抗模型的标定及校核以及提高出行阻抗模型的预测精度,使得基于多源gps数据的出行阻抗模型标定及校核方法降低了出行阻抗模型构建(流量延误函数标定)的成本,并具有精度高、范围广且易于实现的特点;另一方面,全面地获取了不同类型的车辆的gps数据,避免了不同类型车辆的gps数据特征存在较大差异及单类gps数据难以客观描述路段交通流特征的问题,提升了最终得到的出行阻抗模型的全面性、可靠性与准确性。
附图说明
15.图1为本发明实施例中基于多源gps数据的出行阻抗模型标定及校核方法的流程图;图2为图1的子流程图;图3为图2的子流程图;图4为图2的另一个子流程图;图5为图1的另一个子流程图;图6为图5的子流程图;图7为图5的另一个子流程图。
具体实施方式
16.为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
17.结合图1所示,本发明实施例提供一种基于多源gps数据的出行阻抗模型标定及校核方法,包括以下步骤:步骤100、获取车辆在路网上的多源gps数据;具体地,gps(全球定位系统)是一种以人造地球卫星为基础的高精度无线电导航的定位系统,它在全球任何地方以及近地空间都能够提供准确的地理位置、车行速度及精确的时间信息等。基于多源gps数据的出行阻抗模型标定及校核方法通过步骤100,以获取车辆在路网上的多源gps数据,即获取不同类型的车辆在路网上的gps数据,其中,多源gps数据包括出租车gps数据、公交车gps数据、货车gps数据和私家车gps数据等。如此,通过全面地获取不同类型的车辆的gps数据(多源gps数据),以避免仅获取部分类型的车辆的gps数据导致最终得到的出行阻抗模型存在片面性,提升了最终得到的出行阻抗模型的可靠性。
18.步骤200、根据多源gps数据,标定路网的路段的流量延误函数;
具体地,通过步骤200,以根据步骤100获取的多源gps数据,进行路网各路段的流量延误函数的标定,即初步构建出行阻抗模型(其由路网各路段的流量延误函数等构建)。
19.步骤300、获取路网的地理空间数据,并根据多源gps数据和地理空间数据,确定车辆的出行样本数据,其中,出行样本数据包括车辆的出行行程和出行行程所花费的实际行程时间;具体地,通过步骤300,获取路网及路段的地理空间数据,并根据地理空间数据和各不同类型车辆的gps数据(多源gps数据),得到各不同类型车辆的出行数据,并从中筛选出一定数量的出行样本数据,得到相应车辆的出行行程及其花费的实际行程时间。
20.步骤400、根据流量延误函数和出行行程,预测车辆采用出行样本数据中各出行行程所花费的第一预测行程时间;具体地,通过步骤400,以根据步骤200标定的流量延误函数(即初步构建的出行阻抗模型)和步骤300得到的出行样本数据,预测车辆采用出行样本数据中各出行行程时所花费的第一预测行程时间,以用于后续步骤中流量延误函数的校核。
21.步骤500、检验第一预测行程时间与实际行程时间的拟合优度;具体地,通过步骤500,将相同行程对应的实际行程时间与第一预测行程时间进行对比校核,以检验拟合优度。
22.步骤600、当拟合优度满足预设条件时,流量延误函数满足精度要求;当拟合优度不满足预设条件时,重复步骤100至步骤500,直至拟合优度满足预设条件。
23.具体地,通过步骤600,对步骤500得到的检验结果进行分析,当步骤500得到的拟合优度满足预设条件时,认为流量延误函数满足精度要求,构建的路网的出行阻抗模型已构建完整。而当步骤500得到的拟合优度不满足预设条件时,认为流量延误函数不满足精度要求,构建的路网的出行阻抗模型不够完整,如此,需要重复步骤100至步骤500,以重新标定路网各路段的流量延误函数,并对重新标定的流量延误函数进行校核,直至相应的拟合优度满足预设条件,即可得到构建完整的出行阻抗模型,得到随机误差更小的流量延误函数。
24.这样,基于多源gps数据的出行阻抗模型标定及校核方法用于融合多源gps数据挖掘交通流出行特征(即出行车辆的交通流特征),并通过交通流出行特征循环标定及校核出行阻抗模型(流量延误函数),最大程度地减少了随机误差造成的影响,保证了最终得到的出行阻抗模型的全面性、可靠性与准确性。而且,基于多源gps数据的出行阻抗模型标定及校核方法通过获取多源gps数据以得到路网交通流出行特征,一方面,相对于通过成本高、精度低、范围小且难以实现的人工调查方法获取交通流出行特征等信息以构建出行阻抗模型而言,gps数据具有体量大、覆盖面广、易于获取且能够全面的分析出各等级道路的交通流出行特征的特点,且能够支撑本地化、精细化的出行阻抗模型的标定及校核以及提高出行阻抗模型的预测精度,使得基于多源gps数据的出行阻抗模型标定及校核方法降低了出行阻抗模型构建(流量延误函数标定)的成本,并具有精度高、范围广且易于实现的特点;另一方面,全面地获取了不同类型的车辆的gps数据,避免了不同类型车辆的gps数据特征存在较大差异及单类gps数据难以客观描述路段交通流特征的问题,提升了最终得到的出行阻抗模型的全面性、可靠性与准确性。
25.可选地,结合图1、图2所示,步骤200具体包括以下步骤:
步骤210、根据多源gps数据,建立路网和路段的平均速度融合因子库;具体地,通过步骤210,以根据各类车辆的gps数据,使用地图匹配算法分别计算各类车辆相应的运行速度,从而建立包括各类车辆相应的运行速度的平均速度融合因子库,便于后续步骤从平均速度融合因子库直接提取相应数据。
26.步骤220、根据多源gps数据和平均速度融合因子库,标定路段的流量延误函数。
27.具体地,通过步骤220,根据步骤210建立的平均速度融合因子库,对各路段的流量延误函数进行标定,初步构建出出行阻抗模型。
28.可选地,结合图1
‑
图3所示,步骤210具体包括以下步骤:步骤211、根据多源gps数据,确定各类车辆在不同的路段上的运行速度;具体地,通过步骤211,以根据各类车辆的gps数据,使用地图匹配算法分别计算各类车辆在路网不同路段上的运行速度。且通过多源gps数据,还可得到相应路段的交通运行指数。
29.步骤212、根据运行速度,建立路网和路段的平均速度融合因子库。
30.具体地,通过步骤212,建立包括由步骤211确定的各类车辆在路网不同路段上的运行速度的平均速度融合因子库,便于后续步骤从平均速度融合因子库直接提取相应数据。
31.可选地,流量延误函数采用akcelik流量延误函数;akcelik流量延误函数为:,其中,为路段的行程时间,为路段的零流时间,为信号交叉口的无交通流控制延误,为交通需求期望持续时间(在一些实施例中,交通需求期望持续时间t取1h),为路段的饱和度,为修正系数,为路段的长度。
32.现有技术中,路段的流量延误函数较为广泛地采用bpr流量延误函数,其并未考虑交叉口延误等影响因素,并不适用于城市道路的交通流量预测。本实施例中,用于构建出行阻抗模型的各路段的流量延误函数采用akcelik流量延误函数,以兼顾交叉口延误等影响因素,保证构建的路网的出行阻抗模型的全面性,且能够真实反应路网的运行状态演变,尤其是拥堵状态下的行程时间变化。
33.可选地,结合图1、图2和图4所示,步骤220具体包括以下步骤:步骤221、根据多源gps数据和平均速度融合因子库,标定路段对应的akcelik流量延误函数的参数、,并确定路段的饱和度及路段的行程时间;具体地,参数为路段的零流时间(自由流速度),根据平均速度融合因子库,使用单位距离(路段行程)除以零流速度即可得到该路段的零流时间,完成的标定。参数为信号交叉口的无交通流控制延误,根据多源gps数据可计算得到车辆经过交叉口的实际平均行程时间,根据《道路通行能力手册hcm2000》中计算交叉口行程时间的方法可计算交叉口的零流行程时间,再用交叉口的零流行程时间减去实际平均行程时间即可得到信号
交叉口的无交通流控制延误,完成的标定。根据平均速度融合因子库可计算得到不同饱和度(即路段的交通饱和度)下对应的路段平均速度,使用单位距离(路段行程)除以路段平均速度即可得到该路段的行程时间。
34.步骤222、根据路段的饱和度、路段的行程时间及akcelik流量延误函数,标定修正系数。
35.具体地,akcelik流量延误函数:,其经步骤221标定参数、后,可得到多组路段饱和度及对应的路段的行程时间。通过多组与相应的,根据akcelik流量延误函数,采用最小二乘法可标定修正系数,从而完成akcelik流量延误函数的标定。
36.可选地,结合图1、图5所示,步骤300具体包括以下步骤:步骤310、获取路网的地理空间数据;具体地,通过步骤310,以获取路网及路段的地理空间数据。
37.步骤320、根据多源gps数据和路网的地理空间数据,确定车辆的出行数据;具体地,通过步骤320,根据地理空间数据和各不同类型车辆的gps数据(多源gps数据),可得到各不同类型车辆的出行数据,其中,出行数据包括车辆出行的起讫点、路径及相应的行程时间。
38.步骤330、根据出行数据,筛选出出行数据中预定数量的出行样本数据。
39.具体地,通过步骤330,从步骤320得到的出行数据中筛选出预定数量(例如1000)的出行样本数据,以用于后续步骤中流量延误函数的校核等。
40.可选地,结合图1、图5和图6所示,步骤330具体包括以下步骤:步骤331、根据出行数据进行统计、校核及扩样处理,得到分时段的出行数据;具体地,通过步骤331,根据出行数据,对车辆行驶轨迹进行切分,并对出行特征进行统计、校核及扩样处理,可得到全市域分时段的出行od(出行起讫点)以及车辆个体的行程时间等信息。
41.步骤332、根据流量延误函数和分时段的出行数据进行高峰时段的交通分配,预测路网的每个路段的第二预测行程时间;具体地,通过步骤332,根据流量延误函数和全市域分时段的出行od,对全市域路网个路段进行高峰时段(例如早高峰时段)的交通分配,推测各路段的交通量,推测每个路段的分配流量及第二预测行程时间(即该路段的行程时间)。
42.步骤333、根据分时段的出行数据进行筛选,得到预定数量的出行样本数据;具体地,通过步骤333,从全市域分时段的出行数据中筛选得到预定数量的出行样本数据,用于后续步骤中流量延误函数的校核等。
43.步骤400包括:根据第二预测行程时间,确定车辆采用出行样本数据中各出行行程所花费的第一
预测行程时间。
44.具体地,通过步骤400,根据步骤332得到的第二预测行程时间,预测车辆采用出行样本数据中各出行行程时所花费的第一预测行程时间,即预测各类型车辆采用出行样本数据中相同类型的车辆的出行行程时所花费的第一预测行程时间。其中,第一预测行程时间可由第一预测行程时间对应的行程各路段(包括信号交叉口)的第二预测行程时间相加得到。
45.可选地,预设条件为拟合优度的决定系数大于0.9。
46.本实施例中,预设条件为第一预测行程时间与实际行程时间的拟合优度的决定系数大于0.9。当步骤500得到的拟合优度的决定系数大于0.9时,认为经步骤200标定的流量延误函数满足精度要求,构建的路网的出行阻抗模型已构建完整。而当步骤500得到的拟合优度的决定系数不大于0.9时,认为经步骤200标定的流量延误函数不满足精度要求,构建的路网的出行阻抗模型不够完整,如此,需要重复步骤100至步骤500,以重新标定路网各路段的流量延误函数,并对重新标定的流量延误函数进行校核,直至相应的拟合优度的决定系数大于0.9,即可得到构建完整的出行阻抗模型,得到随机误差更小的流量延误函数。
47.可选地,多源gps数据包括出租车gps数据、公交车gps数据、货车gps数据和私家车gps数据等。
48.可选地,结合图1、图5和图7所示,步骤320具体包括以下步骤:步骤321、根据多源gps数据和路网的地理空间数据,识别并聚类各类车辆的驻留点;由于通过gps数据识别车辆出行数据的重点在于精准的地图匹配及车辆驻留点识别,不同类型车辆gps数据的地图匹配算法基本一致,但是gps数据结构差异较大,车辆驻留点识别算法有较大的差异。因此,在步骤321中,各类车辆驻留点的识别分类进行。首先,根据多源gps数据和路网的地理空间数据,进行应用数据清洗并采用地图匹配算法计算车辆行驶路径。其后,通过车辆驻留点分割及聚类算法识别车辆驻留点,具体地,出租车的驻留点识别主要基于出租车gps数据的空重载状态位;货车及两客一危的驻留点识别主要基于货车gps数据的时间分割及空间聚类;公交出行驻留点识别主要基于公交gps数据及公交ic刷卡数据等。
49.步骤322、根据驻留点,确定车辆的出行数据。
50.通过步骤322,根据步骤321得到的各类车辆的驻留点,对车辆行驶轨迹进行切分,并对出行特征进行统计、校核及扩样处理,得到全市域分时段的车辆的出行数据以及车辆个体的行程时间等信息。
51.虽然本公开披露如上,但本公开的保护范围并非仅限于此。本领域技术人员在不脱离本公开的精神和范围的前提下,可进行各种变更与修改,这些变更与修改均将落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。