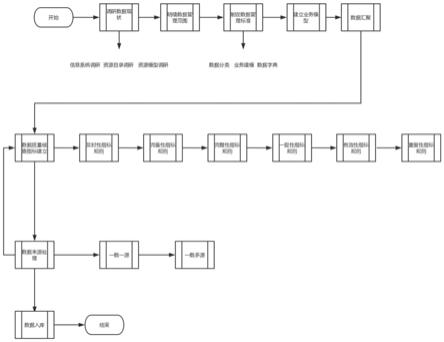
1.本发明涉及一种基于数据质量的基层治理数字化核查指标评价方法。
背景技术:
2.基层治理是国家治理、市域治理的微观基础,是国家治理体系的重要基石。目前,在基层治理过程中存在着如下不足之处:
3.第一,不同的政务部门建设不同的业务系统,导致基层社区存在信息平台重复建设、数据分散且封闭的问题。这样,数据来源众多却缺乏统一的数据标准建立,不仅造成大量的基层资源消耗,还使得基层治理困难重重,无法快速实现闭环管理,导致基层管理情况摸不清,事件顾不及,家底看不全;
4.第二,垂直管理部门的业务系统建设自成体系,基层社区常常充当数据采集终端,为各政务部门业务系统提供业务数据保障服务。因垂直管理部门分别向基层要数据,很多部门下发的表格,内容基本相同,只是格式、体例稍有差别,导致同样的数据反复查、反复核、反复填、反复报,无形中给基层工作增加了工作量;
5.第三,传统的业务系统未考虑数据质量问题,导致业务系统的数据整体质量不高,缺乏面向数据质量的评估机制和数据质量评价方法,导致数据出现不准确、不及时以及相互矛盾等问题,拖延了各政务部门的服务效率。
技术实现要素:
6.本发明的目的是提供一种基于数据质量的基层治理数字化核查指标评价方法,该方法可以减少数据定义的歧义,实现了全要素的分类,保证数据易用性,还可以实现全过程、全时段、全覆盖、全方位的管理;同时,将多方数据资源融合碰撞,大大提升了数据使用价值。
7.为了实现上述目的,本发明提供了一种基于数据质量的基层治理数字化核查指标评价方法,包括:
8.步骤1、调研数据现状,包括政务信息系统和信息资源目录;
9.步骤2、明确数据管理范围;
10.步骤3、制定数据管理标准;
11.步骤4、建立业务模型;
12.步骤5、数据汇聚,在政务外网环境中利用主前置服务器将政务各个部门的前置服务器串联起来,通过数据汇聚接口,把摸底得到的各个业务部门的政务资源目录数据通过数据采集与整合方式统一汇聚到主前置服务器上;
13.步骤6、建立数据质量核查指标;
14.步骤7、利用数据质量评价指标对数据及时性进行评价;
15.步骤8、利用数据质量评价指标对数据完备性进行评价;
16.步骤9、利用数据质量评价指标对数据完整性进行评价;
17.步骤10、利用数据质量评价指标对数据一致性进行评价;
18.步骤11、利用数据质量评价指标对数据有效性进行评价;
19.步骤12、利用数据质量评价指标对数据重复性进行评价;
20.步骤13、数据来源处理,针对政务领域数据使用一数一源、一数多源进行数据来源处理识别;
21.步骤14、数据入库,将源自各部门的数据经过差异比对、清洗后,形成标准的数据格式,再按照不同的需求对数据进行抽取、转换、过滤,实现“人、地、物、事、组织”数据入库。
22.优选地,步骤1中的政务信息系统为政务部门业务应用信息系统,即支撑政府管理和服务职能的信息系统,包括由政府投资建设、政府与社区企业联合建设、政府向社会购买服务或需要政府资金进行维护,用于支撑政府业务应用的各类信息系统,通过梳理信息系统调研模板摸清政府各部门政务信息系统底数;
23.信息资源目录为政务部门在履行职责过程中职责获取并记录、留档的文件数据,由政务部门直接或者通过第三方采集,依托政务信息系统形成的信息资源目录;通过梳理信息资源目录调研模板摸清政府各部门政务信息系统的信息资源目录底数。
24.优选地,在步骤2中通过各级政务机构的行政职能和业务属性,以政务委办局科室为单位、按照三定职责梳理应该有的数据目录和数据项进行识别数据管理范围。
25.优选地,步骤3中包括:
26.步骤3a、对现有各类数据标准进行梳理;
27.步骤3b、完善本地标准,对于业务执行过程中约定速成的各类数据模型进行梳理和提取归纳;
28.步骤3c、标准比对,将已有的政务资源目录数据跟国家标准、地方标准、行业标准进行逐一比对、去重、合成,形成一套可行、完整的数据管理标准体系及数据字典项。
29.优选地,步骤4中,在数据标准中规定相关业务实体的基础元属性建立相应的业务标准模型。
30.优选地,步骤6中包括:
31.在各部门间数据汇聚的基础上,根据业务需要对来自不同部门的基础信息进行数据质量核查,根据比对结果找到部门间数据库差异和问题,并及时反馈给各政务部门;
32.数据质量评估包括对数据部门评估、对数据资源目录评估、数据表行进行记录数量、空数据和重复/非重复数据的分布统计、最小值、最大值、中间值、极值、数据长度/数据方差分析等进行评估;对数据表列的数据结构进行正则表达进行评估;对字段数值的出现频率和分布进行分析;
33.同时,使用数据间的函数依赖和字典规则进行智能发现潜在的数据规则;通过人工定义相关规则对数据进行发现;对所有相关规则进行校验,合并相容规则、剔除冲突规则,形成质量评估的规则集;用户还可以对这些规则集进行筛选,选择合适维度的评估规则;
34.数据质量评价指标从数据及时性、完备性、完整性、一致性、有效性和重复性进行评价。
35.优选地,步骤7中包括:
36.将数据交付的时间和计划数据交付时间作为对比比较,用于检查处理数据的交付
及时性;
37.将处理当前资源目录数据用时和历史处理当前数据资源目录数据用时或一个平均用时进行比较,用于检查处理数据用时情况;
38.将数据实际可供数据使用方消费的时间与计划提供时间进行比较,用于检查数据的及时可用性;
39.步骤8中包括:
40.将输入的大小与以前运行同样的过程时的输入大小、文件记录数据、消息的数目或速率、汇总数据等作比较;
41.将确保关键日期字段的最小和最大日期符合合理性规则,用于检查基于日期标准的数据集的合理性;
42.将评估元数据标准和参考数据进行完备性比较和充分性比较;
43.步骤9中进行跨库跨表数据检查,包括通过确定父表/子表之间的参考完整性以找出无父记录的子记录和值以及通过确定表、父表/子表之间的参考完整性以找出无子记录的父记录和值;
44.步骤10中包括:
45.评估列属性和数据在可被赋予默认值的每个字段中的默认值,用于检查一个字段默认值使用的一致性;
46.将某个聚合日期关联的记录数和百分比与历史记录数和百分比作比较,用于检查按聚合日期汇总的记录数的一致性;
47.将跨多个字段的值的记录数分布和历史百分比作比较,用于检查一致性多列剖析以及测试业务规则;
48.将数据质量测量结果与标准业务模型作比较,用于检查与外部基准比较的一致性。
49.优选地,步骤11中包括:
50.将输入数据的值与一个既定的值域作比较,用于检查单字段和详细结果;
51.汇总有效性检查的详细结果,将卷积的有效/无效值计数和百分比与历史水平作比较,用于有效性检查和卷积汇总检查。
52.优选地,步骤12中包括:
53.将输入数据的值与一个既定的值域数据作比较,用于检查数据是否重复;
54.汇总重复性检查的详细结果,将卷积的重复数据计数和百分比与历史水平作比较,用于重复性检查和卷积汇总检查。
55.优选地,步骤13中,一数一源处理时,指定一个数据提供者提供最为可信的版本或者可信信息,可以直接进行数据入库;一数多源处理时,指定多个数据提供者提供数据,按照数据质量指标评价方法和数据存活规则生成可信数据;其中,一数多源的数据存活规则包括:
56.最新时间优先规则,即针对一个基层治理需要的主数据属性,按照数据创建的时间生成可信数据,时间越近的数据优先;
57.最旧时间优先规则,即针对一个基层治理需要的主数据属性,按照数据创建的时间生成可信数据,时间越旧的数据优先;
58.系统来源优先规则,即针对基层治理需要的主数据属性,确定多个数据提供者的优先级别,按照数据提供者的优先级别生成可信数据,级别越高的数据优先;
59.自定义优先规则,即针对基层治理需要的主数据属性,数据提供者多方协商一个自定义的规则生成可信数据。
60.根据上述技术方案,本发明通过调研基层数据现状,明确数据管理范围,梳理业务模型,通过基于spring boot2.1技术,依赖于hadoop、spark、linkis等大数据中间组件进行数据质量核查,通过配置数据质量规则,分析定位数据质量,实现多源异构数据的集中、统一入库。通过统一数据标准、进行数据整合和治理,做到管理全方位、服务全过程、矛盾全化解、社情全掌握和信息全共享,以地理信息库为依托,联合人、地、事、物、情、组织数据,整合公安、人社、计生、教育、民政、残联、工商等数据,实行指挥、监督、执行适度分离,创新管理体制,再造管理流程。形成统一指挥、监督有力、沟通快捷、分工明确、责任到位、反应快速、处置及时、运转高效的基层数字化治理平台。
61.本发明的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
62.附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:
63.图1是根据本发明提供的一种基于数据质量的基层治理数字化核查指标评价方法的流程图。
具体实施方式
64.以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
65.参见图1,本发明提供一种基于数据质量的基层治理数字化核查指标评价方法,包括:
66.步骤1、调研数据现状,包括政务信息系统和信息资源目录;
67.其中,政务信息系统为政务部门业务应用信息系统,即支撑政府管理和服务职能的信息系统,包括由政府投资建设、政府与社区企业联合建设、政府向社会购买服务或需要政府资金进行维护,用于支撑政府业务应用的各类信息系统,通过梳理信息系统调研模板摸清政府各部门政务信息系统底数;内容包括但不限于:信息系统名称、系统地址、功能、使用范围、使用频率、运行网络、上级部门等,形成政务信息信息系统清单。
68.信息资源目录为政务部门在履行职责过程中职责获取并记录、留档的文件数据,由政务部门直接或者通过第三方采集,依托政务信息系统形成的信息资源目录;通过梳理信息资源目录调研模板摸清政府各部门政务信息系统的信息资源目录底数。内容包括但不限于:信息资源名称、信息资源摘要、信息资源格式、信息资源分类、所属系统名称、共享类型、共享条件、共享方式、更新周期、关联资源代码等。
69.步骤2、明确数据管理范围;
70.由于社区的人、地、事、物、情数据分散在省厅局、市委办局、区县和街道业务系统中,需要通过各级政务机构的行政职能和业务属性,以政务委办局科室为单位、按照三定职
责梳理应该有的数据目录和数据项进行识别数据管理范围。
71.例如,《户口登记条例》中规定中华人民共和国公民都应当依照本条例的规定履行户口登记。公民迁出本户口管辖区,由本人或者户主在迁出前向户口登记机关申报迁出登记,领取迁移证件,注销户口。故公安局有管理户籍数据的职责。又如,《中华人民共和国婚姻法》规定要求结婚的男女双方必须亲自到婚姻登记机关进行结婚登记。符合本法规定的,予以登记,发给结婚证。取得结婚证,即确立夫妻关系。未办理结婚登记的,应当补办登记。故民政有管理婚姻状况数据的职责。
72.步骤3、制定数据管理标准,通过政务信息资源目录梳理,了解信息资源情况,统一标准是各部门之间数据互通社区使用人、地、事、物、情、组织数据的基层,建立大数据标准体系,从根本上解决各系统数据存在的不标准、不完整等痛点问题。
73.具体的,数据标准制定的思路如下:
74.步骤3a、对现有各类数据标准进行梳理,包括业务涉及到的国家标准、地方标准和行业标准。例如,
75.国家标准有《gb/t 2261.1
‑
2003个人基本信息分类与代码第1部分:人的性别代码》、《gb/t 2261.2
‑
2003个人基本信息分类与代码第2部分:婚姻状况代码》、《gb/t 2261.3
‑
2003个人基本信息分类与代码第3部分:健康状况代码》;
76.地方标准有《db37/t 4221.1
‑
2020政务信息资源数据集人口第1部分:出生信息》、《db37/t 4221.2
‑
2020政务信息资源数据集人口第2部分:户籍人口信息》、《db37/t 4221.3
‑
2020政务信息资源数据集人口第3部分:流动人口信息》、《db37/t 4221.4
‑
2020政务信息资源数据集人口第4部分:婚姻登记信息》、《db37/t 4221.5
‑
2020政务信息资源数据集人口第5部分:养老保险信息》;
77.公安行业有《ga 214.1
‑
2004常住人口管理信息规范第1部分:基本数据项》、《ga 214.2
‑
2004常住人口管理信息规范.第2部分:户籍管理信息数据项》、《ga 214.3
‑
2004常住人口管理信息规范第3部分:居民身份证管理信息数据项》;
78.卫健委行业有《ws/t 672
‑
2020国家卫生与人口信息概念数据模型》等。
79.步骤3b、完善本地标准,对于业务执行过程中约定速成的各类数据模型进行梳理和提取归纳;
80.步骤3c、标准比对,将已有的政务资源目录数据跟国家标准、地方标准、行业标准进行逐一比对、去重、合成,形成一套可行、完整的数据管理标准体系及数据字典项。
81.步骤4、建立业务模型,数据标准是数据质量好坏的评价度量指标,数据标准需要根据业务特性进行全方位的集合,支持数据标准的规范化定义,支持数据标准的实时、定时和条件执行,支持以生命周期为管理的。
82.在数据标准中规定相关业务实体(人、地、事、物、情、组织)的基础元属性(如人口的姓名、性别、民族、身份证号码等)建立相应的业务标准模型。具体的,
83.人口类数据来源按照信息来源和信息归属划分,包括公安户籍信息,教育信息,民政信息,人保信息等业务模型;其中,
84.公安户籍信息来源于公安局,包括身份证号码、姓名、性别、民族、出生日期、出生地、户口类别、常住户口所在地、户籍登记地址、户口所在地邮政编码、死亡标识、死亡日期、死亡登记日期、曾用名、籍贯、户主身份证号码、与户主关系、姓氏、名字、曾用姓氏、曾用名
字;
85.教育信息来源于教育局,包括最高学历、最高学历毕业学校、最高学历毕业时间、最高学历毕业专业、学位、学位授予时间、其他所学专业、所学外语语种、外语语种熟练程度、学生学籍号;
86.民政信息来源于民政局,包括婚姻状况、婚姻登记时间、救济人员分类、享受定期定量救济金额、社会福利机构收养人员分类、享受定期抚恤补助状况、定期优抚金额;
87.人保信息来源于人社局,包括劳动就业信息、社会保险信息、医疗保险信息、养老保险信息、失业保险信息、工伤保险信息、生育保险信息。
88.法人信息数据来源按照信息来源和信息归属划分,包括质监部门信息、市场监管部门信息、税务部门信息、编办信息、民政部门信息、发改部门信息、公安部门信息、人社部门信息、卫生部门信息、商务部门信息、统计部门信息、教育部门信息、文化部门信息、安监部门信息、食药监部门信息、海关信息部门等。
89.步骤5、数据汇聚,在政务外网环境中利用主前置服务器将政务各个部门的前置服务器串联起来,通过数据汇聚接口,把摸底得到的各个业务部门的政务资源目录数据通过数据采集与整合方式统一汇聚到主前置服务器上;其主要功能包括:
90.1、支持对各类主流数据库(oracle、db2、sql server、mysql、postgresql、informix等)、外部文件(文本、xml、excel)进行读写访问;
91.2、实现各个采集点之间安全可靠的数据采集;
92.3、及时、自动识别并抽取前置服务器中需要对外发送的数据,交给消息传输系统进行发送;
93.4、及时从消息总线上提取信息,进行解包和转换,保持到前置服务器中;
94.5、提供采集流程定义功能,能够方便、动态地改变数据采集的方式和流程。
95.步骤6、建立数据质量核查指标,包括:
96.在各部门间数据汇聚的基础上,根据业务需要对来自不同部门的基础信息进行数据质量核查,根据比对结果找到部门间数据库差异和问题,并及时反馈给各政务部门;
97.数据质量评估包括对数据部门评估、对数据资源目录评估、数据表行进行记录数量、空数据和重复/非重复数据的分布统计、最小值、最大值、中间值、极值、数据长度/数据方差分析等进行评估;对数据表列的数据结构进行正则表达进行评估;对字段数值的出现频率和分布进行分析;
98.同时,使用数据间的函数依赖和字典规则进行智能发现潜在的数据规则;通过人工定义相关规则对数据进行发现;对所有相关规则进行校验,合并相容规则、剔除冲突规则,形成质量评估的规则集;用户还可以对这些规则集进行筛选,选择合适维度的评估规则;
99.数据质量评价指标从数据及时性、完备性、完整性、一致性、有效性和重复性进行评价。
100.步骤7、利用数据质量评价指标对数据及时性进行评价;其中,
101.将数据交付的时间和计划数据交付时间作为对比比较,用于检查处理数据的交付及时性;例如,公安的户籍迁移登记数据,需要在人口形成或者变更之日起20个工作日内予以公开(计划数据交付时间)。
102.将处理当前资源目录数据用时和历史处理当前数据资源目录数据用时或一个平均用时进行比较,用于检查处理数据用时情况;例如,公安的户籍迁移登记数据,平均需要10个工作日进行公开,当前数据用时12个工作日。
103.将数据实际可供数据使用方消费的时间与计划提供时间进行比较,用于检查数据的及时可用性;例如,公安的户籍迁移登记数据,计划20个工作日进行公开,实际12个工作日可以进行消费。
104.步骤8、利用数据质量评价指标对数据完备性进行评价,包括:
105.将输入的大小与以前运行同样的过程时的输入大小、文件记录数据、消息的数目或速率、汇总数据等作比较;
106.将确保关键日期字段的最小和最大日期符合合理性规则,用于检查基于日期标准的数据集的合理性;
107.将评估元数据标准和参考数据进行完备性比较和充分性比较。
108.步骤9、利用数据质量评价指标对数据完整性进行评价,在该步骤中进行跨库跨表数据检查,包括通过确定父表/子表之间的参考完整性以找出无父记录的子记录和值以及通过确定表、父表/子表之间的参考完整性以找出无子记录的父记录和值。
109.步骤10、利用数据质量评价指标对数据一致性进行评价,包括:
110.评估列属性和数据在可被赋予默认值的每个字段中的默认值,用于检查一个字段默认值使用的一致性;
111.将某个聚合日期关联的记录数和百分比与历史记录数和百分比作比较,用于检查按聚合日期汇总的记录数的一致性;
112.将跨多个字段的值的记录数分布和历史百分比作比较,用于检查一致性多列剖析以及测试业务规则;
113.将数据质量测量结果与标准业务模型作比较,具体做法是把数据质量测量结果与一组基准,如行业或国家标准建立的标准业务模型作比较,用于检查与外部基准比较的一致性。
114.步骤11、利用数据质量评价指标对数据有效性进行评价;其中,
115.主要的检查对象有:数据行数,主要是单字段、详细结果检查,具体做法是将输入数据的值与一个既定的值域作比较。例如,性别存在0
‑
未知的性别、1
‑
男性、2
‑
女性、9
‑
未说明的性别值域;以及汇总数据,主要是有效性检查,卷积汇总检查,具体做法是将汇总有效性检查的详细结果,将卷积的有效/无效值计数和百分比与历史水平作比较。
116.步骤12、利用数据质量评价指标对数据重复性进行评价,包括将输入数据的值与一个既定的值域数据作比较,用于检查数据是否重复;
117.汇总重复性检查的详细结果,将卷积的重复数据计数和百分比与历史水平作比较,用于重复性检查和卷积汇总检查。
118.步骤13、数据来源处理,针对政务领域数据使用一数一源、一数多源进行数据来源处理识别;具体的,
119.在步骤13中,一数一源处理时,指定一个数据提供者提供最为可信的版本或者可信信息,可以直接进行数据入库;一数多源处理时,指定多个数据提供者提供数据,按照数据质量指标评价方法和数据存活规则生成可信数据;其中,一数多源的数据存活规则包括:
120.最新时间优先规则,即针对一个基层治理需要的主数据属性,按照数据创建的时间生成可信数据,时间越近的数据优先;
121.最旧时间优先规则,即针对一个基层治理需要的主数据属性,按照数据创建的时间生成可信数据,时间越旧的数据优先;
122.系统来源优先规则,即针对基层治理需要的主数据属性,确定多个数据提供者的优先级别,按照数据提供者的优先级别生成可信数据,级别越高的数据优先;
123.自定义优先规则,即针对基层治理需要的主数据属性,数据提供者多方协商一个自定义的规则生成可信数据。
124.步骤14、数据入库,将源自各部门的数据经过差异比对、清洗后,形成标准的数据格式,再按照不同的需求对数据进行抽取、转换、过滤,实现“人、地、物、事、组织”数据入库。
125.根据上述技术方案,不仅通过统一的标准定义减少数据定义的歧义,而且通过将分散在各业务系统中涉及“人、地、物、事、组织”等各类社会管理要素,按照街道、社区、建筑物、基本单元等汇聚到基层治理平台,并对数据进行数据质量指标评价体系解决基层底数不清、数据不可用等痛点,保证数据完整、清晰、易用性;实现“人、地、物、事、组织”全要素的分类,可以实现全过程全时段、全覆盖全方位的管理;更进一步的,通过收集社区“人、地、物、事、组织”业务需求,根据不同的业务部门,明确数据管理规范,指定数据标准规则,根据业务发生的时间、地点涉及“人、地、物、事、组织”,通过对各政务部门易源异构数据资源目录数据进行数据质量判断,编制数据标准规范,进行清洗、比对、转换、整合,实现统一的人口、法人等基层模型管理,聚合和承载服务,为跨社区跨部门业务协调提供保障,为社区数据化核查指标提供基本方法。
126.以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
127.另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
128.此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
