1.本发明涉及数据分析应用领域,具体涉及一种统计年鉴数据库构建方法。
背景技术:
2.统计年鉴是各级统计局编印的一种资料性年刊,提供了全面反映全国及各地国民经济和社会发展情况的综合性数据。我国行政管理体系分为省级、地市级、区县级等不同层级,各行政级的统计局每年均会编印各自的统计年鉴。借助于这些统计年鉴数据,是各行业研究者进行各项经济、社会研究的必要前提。但是,所有的数据表均是按二维表格形式保存和处理,每年一份单独保存,因此在对数据的存储和使用中存在以下技术缺陷:(1)由于不同年份的数据表是分开保存的,要查询多个年份的同一指标数据时效率低下;(2)高一层级行政单元的指标数据并不完全是由对应的低层级行政单元指标数据汇总而得,因此需要对每个行政层级的数据表都进行保存,扩展性低;(3)保存不同指标数据的数据表之间缺乏逻辑关联,难于将不同表格中的指标数据进行集中使用。
技术实现要素:
3.本发明意在提供一种统计年鉴数据库构建方法,能够解决现有统计年鉴中查询效率低,拓展性低,难以集中使用的问题。
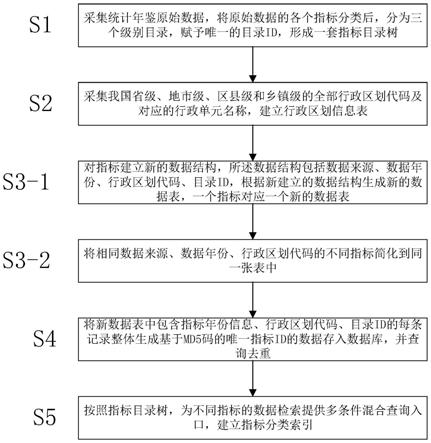
4.本发明提供的技术方案为:一种统计年鉴数据库构建方法,包括以下步骤:
5.s1:采集统计年鉴原始数据,根据分类原则将原始数据的各个指标分类、分级,并赋予唯一的目录id,形成一套指标目录树;
6.s2:采集我国全部行政区划代码及对应的行政单元名称,建立行政区划信息表;
7.s3:建立新的数据结构,所述数据结构包括指标年份信息、行政区划代码、目录id,根据新建立的数据结构生成新的数据表;
8.s4:将新数据表中包含指标年份信息、行政区划代码、目录id的每条记录整体生成唯一的指标id的数据存入数据库。
9.本发明的工作原理及优点在于:根据分类原则将采集的原始数据确定其字符类型再分级,对每个指标赋予唯一的目录id,形成一套指标目录树,目录id的设立实现了目录结构的层级关系的区分。采集并建立行政区划信息表,以便对指标的行政区划进行分类。建立包括指标年份信息、行政区划代码、目录id三类关键信息的数据结构,根据以上新建立的数据结构生成新的数据表。将新数据表中包含指标年份信息、行政区划代码、目录id的每条记录整体生成唯一的指标id的数据存入数据库,每个指标存入数据库时都有相应的指标id。本方法对统计年鉴中的原始数据分类分级后进行信息提取和结构重组,简化和规范数据入库的流程。这样后面查询所需数据时直接检索指标id,能直接查询到多个年份的统一指标数据,查询效率高;保存新数据时,将新数据的关键指标年份信息提取,保存为指标id即可,更简便地录入数据库而不改变原有数据结构,拓展性高;能够更加容易地实现对不同年份、多个指标进行重组排列,按不同用户需求生成新的数据结果,易于集中使用。
10.进一步,所述s1中原始数据的各个指标分为三个级别目录。
11.将指标目录分为一级目录、二级目录、三级目录,共三个级别,适合目前统计年鉴分级标准。
12.进一步,所述s2中行政区划代码包括省级、地市级、区县级、乡镇级的区划代码。
13.全面覆盖上至省级,下至乡镇级的行政区划的统计指标。
14.进一步,所述s3中指标年份信息包括数据来源和数据年份,所述数据来源为采集的统计年鉴名称,数据年份为指标数据对应的年份。
15.当年的统计年鉴是统计上一年的数据得到的结果,因此需要对数据来源和数据年份区分以防混淆。
16.进一步,所述s3具体包括以下步骤:
17.s3
‑
1:对指标建立新的数据结构,所述数据结构包括数据来源、数据年份、行政区划代码、目录id,根据新建立的数据结构生成新的数据表,一个指标对应一个新的数据表;
18.s3
‑
2:将相同数据来源、数据年份、行政区划代码的不同指标简化到同一张表中。
19.将相同数据的不同指标简化到一张表上,以降低信息冗余。
20.进一步,所述s4还包括对数据库存入的数据查询去重。
21.系统对新存入的数据查询后自动去重,使得数据库更精简,提高了查询效率。
22.进一步,所述s4中指标id为基于md5码生成技术构建唯一的hash值id。
23.md5加密算法具有压缩性、易计算性、抗修改性、强抗碰撞性,适合作为生成hash值的指标id。
24.进一步,还包括s5:按照指标目录树,建立指标分类索引。
25.按照指标目录树的格式,建立分类索引,方便用户查询数据。
26.进一步,所述分类索引包括多条件混合查询入口。
27.根据需要检索的多个指标混合查询,更易找到需要的指标数据。
28.进一步,所述查询条件包括关键词和id。
29.通过中文关键词或者指标id,均能查询到需要的指标数据。
附图说明
30.图1为本发明实施例的一种统计年鉴数据库构建方法的逻辑框图。
具体实施方式
31.下面通过具体实施方式进一步详细的说明:
32.实施例:
33.如图1所示,本实施例中公开了一种统计年鉴数据库构建方法,具体包括以下步骤:
34.s1:采集各级统计局每年的统计年鉴的原始数据,本实施例采集2018
‑
2020的统计年鉴数据,将原始数据的各个指标分类。如人口、财政、能源等指标类型,再对各个类型分为三个级别目录,并赋予唯一的目录id,如一级目录为人口,id为01;二级目录为人口数,id为01:三级目录为出生率,id为01,则该人口流动数指标id为010101。多个指标id构成一套指标目录树,如下表所示:
[0035][0036]
s2:采集我国省级、地市级、区县级和乡镇级的全部行政区划代码及对应的行政单元名称,建立行政区划信息表,本实施例参考2019全国行政区划,一共12位,精确到乡镇级,如山东省菏泽市曹县邵庄镇,区划代码为371721115000。采集其行政代码及对应的行政单元名称,建立行政区划信息表。
[0037]
s3
‑
1:对指标建立新的数据结构,包括数据来源、数据年份、行政区划代码、目录id,根据新建立的数据结构生成新的数据表,一个指标对应一个新的数据表。所述数据来源为采集的统计年鉴名称,数据年份为指标数据对应的年份。如2020人口增长率,数据来源为统计年鉴2020,数据年份为2019年。
[0038]
s3
‑
2:将相同数据来源、数据年份、行政区划代码的不同指标简化到同一张表中。整理后如下表所示:
[0039][0040]
s4:将新数据表中包含指标年份信息、行政区划代码、目录id的每条记录整体生成唯一的指标id,如2020北京人口出生率指标id为20202019110000000000010101,将该指标id基于md5码生成技术构建唯一的hash值id,存入数据库。系统会对数据库实时查重,发现重复的id系统会合并去重。
[0041]
s5:按照指标目录树,为不同指标的数据检索提供多条件混合查询入口,建立指标分类索引。所述多条件混合查询的条件包括指标的关键词和id。如用户想查询2019和2020北京市人口出生率进行对比,在查询窗口输入2019、2020、110000000000、出生率,即可查询到2019年北京市人口出生率和2020年北京市人口出生率两条指标,进行对比,方便快捷。
[0042]
以上的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本技术得出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本技术的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本技术要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
