基于梯度先验知识和n
‑
s方程的图像去雨方法
技术领域
1.本发明属于图像处理领域,具体涉及一种基于梯度先验知识和n
‑
s方程的图像去雨方法。
背景技术:
2.雨会对户外视觉系统以及后续处理算法的性能造成严重的影响,作为一个重要的研究课题,去除视频和图像中的雨条纹在计算机视觉和模式识别领域备受关注。近年来,非常多的针对视频和单张图片的去雨研究方法不断报道,主要可以分为数据驱动和模型驱动。其中,数据驱动主要是使用深度学习进行视频或者单张图片去雨,模型驱动主要是利用带雨的图像视频的物理属性和先验知识,例如低秩性、稀疏性或色彩属性来实现雨的去除和检测。
3.早期进行去雨方向的研究的的主要思路是修改相机参数,例如增加曝光时间或者减少相机的景深,或利用时空上的相关性去捕捉动态的雨实现检测,然后通过前后帧的平均值对被检测为雨滴的部分进行修复,或利用雨滴的外形特征去识别并去除雨。其中修改相机的参数的方法有一定的限制,对于被捕获的已经有雨的视频,这种思路不总是有使用的条件。同时,这些早期方法修复被雨覆盖的区域的方法只是简单地使用前后帧的平均值,导致在视频背景变化时往往会造成失真。
4.在过去的十年,低秩性和稀疏性备受关注,jie(jie c,chau l p.a rain pixel recovery algorithm for videos with highly dynamic scenes[j].ieee transactions on image processing,2014,23(3):1097
‑
1104.)使用光流法将动态的场景和非动态的场景区分出来,分别进行处理。jie的方法仅仅针对利用前后帧做差来实现对雨的检测,这种检测方法可靠性较低,只适用雨背景几乎没有明显变化的视频,对于动态背景就会失效,也无法处理单张图像。并且,他的修复方法也仅仅是使用前后帧插值而已,这样会导致去雨后的视频变模糊。
[0005]
jiang(jiang t x,huang t z,zhao x l,et al.fastderain:a novel video rain streak removal method using directional gradient priors[j].ieee transactions on image processing,2018:1
‑
1.)通过详细分析雨条纹的稀疏性和干净视频的低秩性,建立了fastderain模型进行去雨。他使用的是线性模型,假设有雨的视频是雨水和无雨背景以及噪音的线性叠加,通过计算直接得出去雨之后的背景,但实际上,雨和背景还有噪音并不是简单的线性叠加,雨对图像的影响是复杂而多方面的。依据简单的线性叠加在去雨的时候,会同时降低图像亮度,并且会去掉很多有用的信息。
[0006]
因此,现有方法存在不能同时处理视频和单帧图片,对于动态背景的视频处理效果欠佳,在检测到雨之后对被雨水影响的部分的修复质量差等问题。
技术实现要素:
[0007]
本发明的目的在于针对现有技术的不足,提供一种基于梯度先验知识和n
‑
s方程
的图像去雨方法,从而对含有雨的单张图片、静态背景的视频和动态背景的视频都进行较为准确的雨检测和图像修复,得到高质量的去雨图像。
[0008]
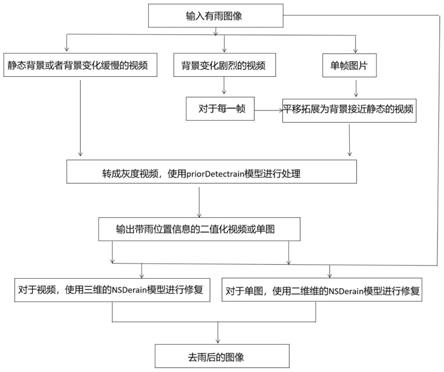
本发明从检测雨和去除雨两个角度着手,首先利用雨条纹的稀疏性,干净背景的低秩性,背景的变化剧烈程度和雨滴的形态学特征进行检测,使用水平方向的轻微平移将剧烈抖动的视频或单张图片转换成背景几乎不移动的视频;再利用分裂增强拉格朗日收缩算法(salsa)求解方程,对雨进行检测;同时基于流体动力学的navier
‑
stokes方程,建立修复模型。本发明方法适用于单张图片和视频,充分利用被雨滴覆盖的图像信息在空间上与时间上的连续性,使用梯度下降法进行快速求解,修复了被雨所遮挡的部分,获得了较为理想去雨图像。
[0009]
本发明提供的基于梯度先验知识和n
‑
s方程的图像去雨方法,包括以下步骤:
[0010]
⑴
采集原始有雨图像,记为o;
[0011]
⑵
对原始有雨图像进行判断,区分为三种,第一种为静态背景或背景缓慢变化的视频,第二种为背景剧烈变化的视频,第三种为单帧图片。
[0012]
⑶
对于单帧图片,通过轻微左右平移制造出前后帧,平移的距离略大于雨滴的水平宽度,构建为一个背景缓慢变化的视频。
[0013]
⑷
对于背景剧烈变化的视频,取出每一帧进行处理,处理方式同步骤(3),得到背景缓慢变化的视频。
[0014]
⑸
将步骤(2)(3)(4)获得的视频转为灰度视频,转换公式为gray=r*0.299 g*0.587 b*0.114。
[0015]
⑹
将步骤(5)中的灰度视频使用模型priordetectrain进行检测,输出含有雨的位置信息的二值图或者二值化的视频,记为rb。
[0016]
⑺
将步骤(2)中获得的视频或图像片和步骤(6)中获得的二值化视频或二值图采用nsderain模型对被雨所遮挡的部分进行修复,得到去雨后的图像b。
[0017]
上述方法,进一步地,步骤(2)中区分视频背景变化的剧烈程度的方法是,通过视频相邻帧的相同位置的像素的差值较大(例如,大于3)的像素占所有像素的比例进行判断,计算这个比例的公式记为d(b)。由于雨的稀疏性,对于背景剧烈变化的视频,背景造成的抖动远大于雨,因此使用有雨的视频的d(o)代替无雨的背景的d(b)进行计算,用以衡量背景的变化剧烈程度,这样可以简化计算的复杂程度(d(o)代表计算有雨的视频相邻帧的相同位置的像素的差值较大的像素占所有像素的比例)。
[0018]
上述方法中,进一步地,步骤(3)所述将单帧图片转化为背景缓慢变化的视频(近似于静态背景的视频)的方法是,将图片通过左右轻微平移构造为一个包含三帧的背景几乎静止的视频,记为pan(o
k
),o
k
代表着视频中的第k帧。这一处理记为f(o),则
[0019][0020]
式中d0为是判断视频为剧烈程度的参数,d(o)大于d0,则视频o被判断为剧烈抖动的视频。
[0021]
上述方法中,进一步地,所述步骤(6)中,检测雨的模型如下:
[0022]
将输入的视频看做是干净背景、雨分量和噪声的叠加,但事实上,有雨的视频中或图像中,被雨覆盖的位置并非雨和背景的简单线性叠加,而是一个复杂的相互影响的结果。假设带雨的视频是无雨的背景、雨和其他噪声的非线性组合,使用公式(2)表示
[0023]
o=ηb βr λn(2)
[0024]
式中,o,b,r,n是三维张量,三个维度分别是视频的高度h,宽度w,和帧数t;o,b,r,n分别表示含雨图像,干净的背景图像、雨分量和噪声。η,β,λ是与输入的视频维度相同的三维张量,分别表示背景、雨和噪声分量的系数。这是一个不适定的问题,要进行求解就需要对雨的特性进行进一步的分析,并依赖于相关的先验知识,结合雨的稀疏性和有向性,干净背景的低秩性,视频帧之间的联系和雨滴的形态学特征,并且使用分裂增强拉格朗日收缩算法(sals a)求解方程。其中,依赖的先验知识包括:
[0025]
①
雨的稀疏性和有向性:在自然界中,除非十分极端的下雨的天气,一般认为雨的条纹是稀疏的。可以使用r的l1范数表征雨的稀疏性。l0范数很难优化求解,l1范数是l0范数的最优凸近似,而且它比l0范数要容易优化求解。在竖直方向上,雨在从上往下掉落的过程中,雨的条纹往往是竖直方向的,因此可以利用竖直方向的差分的l1范数比较小的特点来进行区分。
[0026]
②
干净背景的低秩性:雨滴在图像中会引起急剧的强度变化,在水平方向上这种强度的变化会比竖直方向上更明显,干净的背景在水平上的差分就会相对于有雨图像更小,因此最小化的l1范数将会是一个有效的方式。
[0027]
③
单个雨滴在一张图中的所占的像素大致在一个特定的范围内,并且雨滴的形状往往在视频或照片中为长条状,并且是垂直或略带倾斜的。因此可以排除连通域过大或者过小的部分以及非竖直长条状的部分。
[0028]
则,所述检测雨的测模型表示为,
[0029][0030]
分别代表在水平、竖直方向和时间上进行差分,||*||1代表l1范数,||*||
f
代表f范数。在计算中,张量b和r的维度依据输入的o而确定,由于本算法的目标是检测雨,因此输入的o使用灰度图即可。
[0031]
进一步地,对所述检测雨的模型使用分裂增强拉格朗日收缩算法进行求解,求解过程如下:
[0032]
(a)、引入辅助变量u
i
、v
i
、和拉格朗日算子d
i
,i=1,2,3,4,式(3)改写为公式(4)
[0033][0034]
(b)、公式(4)所述的u
i
用公式(5)表示
[0035][0036]
d1、d2、d3、d4是拉格朗日乘数算子;
[0037]
(c)、公式(4)所述的v
i
(i=1,2,3,4)用公式(6)进行计算,
[0038][0039]
式中,sign()代表符号函数,*代表hadamard积,竖线代表取绝对值,张量减去一个常数代表每个元素都减去该常数,矩阵除以一个常数代表每个位置都除以该常数;u
i
为辅助计算的参数。
[0040]
(d)、对于视频背景,ηb采用公式(7)进行计算
[0041][0042]
(e)、对于雨,βr采用用公式(8)进行计算
[0043][0044]
式中,倒三角上的b代表使用后向差分,不加b代表使用前向差分,这样做是为了在数值计算的过程中尽可能地将被差分位置像素周围的值都利用起来。
[0045]
(f)、拉格朗日算子d的计算方式为:
[0046]
d1=v1-u1[0047]
d2=v2-u2[0048]
d3=v3-u3[0049]
d4=v4-u4[0050]
(g)、将得到的βr二值化,二值化后的二值图记为rb。
[0051]
(h)、将rb中连通域小于minarea和连通域大于maxarea的区域判断为无雨的区域,将连通区域的长宽比小于ratio的连通域判断为无雨区域,并将这些区域的值设置为0,输出rb;minarea表示一个雨滴最小占用多少个像素,其取值可以依据图像中雨滴的大小进行设置,例如20;maxarea表示图像中一个雨滴最多占多少个像素,在雨滴较大的情况下,可设置为1000;ratio表示图像中雨滴的长宽比,设置为5。
[0052]
本发明的上述技术方案中,步骤(6)中所述priordetectrain算法的步骤可总结如下:
[0053]
①
输入灰度视频o,最单个雨滴占用的最大像素maxarea,单个雨滴最小像素minarea,单个雨滴的长宽比;设置辅助计算参数u1=0.001,u2=0.03,u3=0.03,u4=0.01,实际计算过程中使用类似比例的数据也可以;初始化
[0054]
ηb=o,βr,d1,d2,d3,d4初始值设置为维度和o一样的全为0张量;
[0055]
最大执行次数maxstep=100。
[0056]
②
根据公式(5)计算u
[0057][0058]
式中d1、d2、d3、d4是拉格朗日乘数算子。
[0059]
③
根据公式(6)计算v1,v2,v3,v4[0060][0061]
式中,i的值取1,2,3,4,sign()代表符号函数,*代表hadamard积,竖线代表取绝对值,张量减去一个常数代表每个元素都减去该常数,矩阵除以一个常数代表每个位置都除以该常数。
[0062]
④
根据公式(7)计算ηb
[0063][0064]
⑤
根据公式(8)计算βr
[0065][0066]
式中,倒三角上的b代表使用后向差分,不加b代表使用前向差分,这样做是为了在数值计算的过程中尽可能地将被差分位置像素周围的值都利用起来。
[0067]
⑥
计算拉格朗日算子,d1=v1-u1,d2=v2-u2,d3=v3-u3,d4=v4-u4。
[0068]
⑦
重复
②③④⑤⑥
,当执行次数达到maxstep为止。
[0069]
⑧
将βr二值化,二值化的方式为灰度值大于0.01的值设置为1,小于0.01的设置为0,二值化后的二值图记为rb。
[0070]
⑨
将rb中连通域小于minarea和连通域大于maxarea的区域判断为无雨的区域,并将这些区域的值设置为0,输出rb。
[0071]
进一步地,由于处理的对象是视频,尤其是背景变化不剧烈或者静止的视频,时间维度上的信息对于修复缺失区域往往非常有效。雨的出现可以看作是随机的,当一个位置出现了雨,其前后几帧总会存在没有被雨遮挡的情况,这为修复图像提供了十分有效的信息。因此将视频看做是三维空间的流体,三个维度分别是对应的视频的高、宽、和时间方向。在一块很小的灰度空间里,有一个连续的等亮度面u,其法向量为法向量与等亮度面垂直。如果该区域是一个自然连续的状态(即未被破坏的状态),那么与平行,因此其夹角的正弦为0,即
[0072][0073]
为了计算简便,将式(9)转化为余弦的形式,则等价于即
[0074][0075]
对图像的某一个像素值的修复过程可以看作是求出一个像素值u,使其满足方程
(10)。但是在实际的计算过程中,往往有诸多限制,例如,像素的存储为8位无符号整型,其范围为0到255,或者受限于计算精度,该位置可能不存在一个值使方程恰好为0。并且,一个像素与周围像素的差值往往小于统计值i
d
。i
d
表示一张图中像素与周围像素值的差值的绝对值的分布的99%分位处的值,对于背景相邻区域变化较为平缓的单图或视频,可以将值设置为14,对于背景相邻区域变化较为陡峭的单图或视频,可以设置得更大。因此,将方程的求解过程转化为找到一个值u*使方程(11)最小,则步骤(7)所述雨修复模型表示为
[0076][0077]
式中,u*代表求解出来的使方程最小的u值,u是待修复的像素,是哈密顿算子,δ是拉普拉斯算子,w、h、t分表表示视频的宽、高,和时间上的维度。
[0078]
进一步地,在计算最小的u值过程中,将l(u)离散化,使用梯度下降法进行快速求解;对于三维,l(u)离散后的形式为
[0079][0080]
对于每一个待修复的雨滴(连通域)cr逐个进行修复。先按连通域的大小进行排序,先修复较小的雨滴,再修复较大的雨滴。对于每个雨滴中的像素,先修复周围未被雨污染的像素较多的位置。
[0081]
本发明的技术方案中不中步骤(7)所述雨修复过程可以总结为如下步骤:
[0082]
①
输入待去雨的图像o,相邻像素的差值范围统计值i
d
,i
d
的值可以设置为14,或者根据统计的情况调大或调小;输入步骤(6)输出的二值图rb。
[0083]
②
对于每一个待修复的雨滴(连通域)cr逐个进行修复,先按连通域的大小进行排序,先修复较小的雨滴。
[0084]
③
对于雨滴(连通域)cr中的每一个像素的值u,计算其周围已知像素的个数,先修复周围已知像素较多的点。
[0085]
④
对于一个雨滴cr中的每一个像素值u,求出一个u*,满足,
[0086][0087]
并且|u*
‑
u|<i
d
,然后使用计算得出的u*替换u。
[0088]
⑤
重复
④
中的步骤,直到一轮运算中大多数像素值在计算过程中都不发生改变或者重复次数大于i
d
时,就停止对该雨滴区域的修复。
[0089]
⑥
输出修复之后的无雨的背景b。
[0090]
与现有技术相比,本发明具有以下有益效果:
[0091]
1.现有算法往往只针对单帧图片或者视频进行去雨,本发明所提出的检测算法适用于单张图片和视频,使用情况更广,并且充分结合了雨的特性,检测更加准确。
[0092]
2.现有算法在去雨时往往很少区分背景的运动情况,本发明考虑了背景的变化情况,针对不同的情况进行了针对性的处理。
[0093]
3.本发明所提出的修复算法能够对雨进行准确的检测,在修复受雨影响的区域时,充分考虑该区域的前后帧是否变化剧烈,以及该区域周围像素的信息,针对单张图片、静态背景的视频和动态背景的视频采取适当的修复策略,在修复时利用图像和视频信息在空间上与时间上的连续性,尽可能地保留了被雨影响去雨的细节。
[0094]
4.本发明方法适用于三维空间和二维空间,并且基于梯度下降法提出了一种快速求解的方式。所提出的算法基于对图像已有的先验知识的分析,不仅排除了显然不是正确结果的值,也使计算过程中省去了大量无效计算,加快了计算速度。
附图说明
[0095]
图1为本发明的流程框架示意图。
[0096]
图2为平移单帧图片原理示意图。
[0097]
图3为检测雨的结果图。
[0098]
图4为不同方法的检测结果效果图。
[0099]
图5为测试修复和去雨的案例。
[0100]
图6为不同算法的去雨效果图。
具体实施方式
[0101]
下面通过具体实施方式对本发明所述方法做进一步说明。有必要指出,以下实施例只用于对本发明作进一步说明,不能理解为对本发明保护范围的限制,所属领域技术人员根据上述发明内容,对本发明做出一些非本质的改进和调整进行具体实施,仍属于发明保护的范围。
[0102]
实施例1
[0103]
本发明提供的基于梯度先验知识和n
‑
s方程的图像去雨方法,包括以下步骤:
[0104]
⑴
采集原始有雨图像,记为o;
[0105]
⑵
对原始有雨图像进行判断,区分为三种,第一种为静态背景或背景缓慢变化的视频,第二种为背景剧烈变化的视频,第三种为单帧图片。
[0106]
判断视频背景变化的剧烈程度的方法是,通过视频相邻帧的相同位置的像素的差值较大的像素占所有像素的比例进行判断,对于强度差的绝对值小于3的像素点视作没有发生改变,统计发生改变的像素点的个数占总像素点的比例,大于0.4的视作背景发生剧烈变化。计算这个比例的公式记为d(b)。由于雨的稀疏性,对于背景剧烈变化的视频,背景造成的抖动远大于雨,因此使用有雨的视频的d(o)代替无雨的背景的d(b)进行计算,用以衡量背景的变化剧烈程度,这样可以简化计算的复杂程度。
[0107]
⑶
当视频背景剧烈变化或者处理的对象是单张图片时,无法利用时间维度上的信息,因此将待处理的图像稍微平移,构建一个近似于静态背景的视频。对于单帧图片,通过将图片左右轻微平移制造出前后帧,平移的距离略大于雨滴的水平宽度,构建为一个包含
三帧的背景缓慢变化(近似于静态背景的视频)的视频,记为pan(o
k
),o
k
代表着视频中的第k帧。这一处理记为f(o),则
[0108][0109]
式中d0为是判断视频为剧烈程度的参数,计算过程中设置为0.4,d(o)大于d0,则视频o被判断为剧烈抖动的视频。
[0110]
如图2所示,对于第某一帧或者单图frame,雨滴在2号位置上,将图像轻微左右移动,则雨滴偏移位置,前后帧做差之后的差值较大,而对于低秩的背景来说,变化往往较小。
[0111]
⑷
对于背景剧烈变化的视频,取出每一帧进行处理,处理方式同步骤(3),得到背景缓慢变化的视频。
[0112]
⑸
将步骤(2)(3)(4)获得的视频转为灰度视频,转换公式为gray=r*0.299 g*0.587 b*0.114。
[0113]
⑹
将步骤(5)中的灰度视频使用模型priordetectrain进行检测,输出含有雨的位置信息的二值图或者二值化的视频,记为rb。
[0114]
所述检测雨的模型如下:
[0115]
假设带雨的视频是无雨的背景、雨和其他噪声的非线性组合,使用公式(2)表示
[0116]
o=ηb βr λn(2)
[0117]
式中,o,b,r,n是三维张量,三个维度分别是视频的高度h,宽度w,和帧数t;o,b,r,n分别表示含雨图像,干净的背景图像、雨分量和噪声。η,β,λ是与输入的视频维度相同的三维张量,分别表示背景、雨和噪声分量的系数。这是一个不适定的问题,要进行求解就需要对雨的特性进行进一步的分析,并依赖于相关的先验知识,结合雨的稀疏性和有向性,干净背景的低秩性,视频帧之间的联系和雨滴的形态学特征,并且使用分裂增强拉格朗日收缩算法(sals a)求解方程。其中,依赖的先验知识包括:
[0118]
①
雨的稀疏性和有向性:在自然界中,除非十分极端的下雨的天气,一般认为雨的条纹是稀疏的。可以使用r的l1范数表征雨的稀疏性。l0范数很难优化求解,l1范数是l0范数的最优凸近似,而且它比l0范数要容易优化求解。在竖直方向上,雨在从上往下掉落的过程中,雨的条纹往往是竖直方向的,因此可以利用竖直方向的差分的l1范数比较小的特点来进行区分。
[0119]
②
干净背景的低秩性:雨滴在图像中会引起急剧的强度变化,在水平方向上这种强度的变化会比竖直方向上更明显,干净的背景在水平上的差分就会相对于有雨图像更小,因此最小化的l1范数将会是一个有效的方式。
[0120]
③
单个雨滴在一张图中的所占的像素大致在一个特定的范围内,并且雨滴的形状往往在视频或照片中为长条状,并且是垂直或略带倾斜的。因此可以排除连通域过大或者过小的部分以及非竖直长条状的部分。
[0121]
则,所述检测雨的测模型表示为,
[0122][0123]
分别代表在水平、竖直方向和时间上进行差分,||*||1代表l1范数,||*||
f
代表f范数
[0124]
对所述检测雨的模型使用分裂增强拉格朗日收缩算法进行求解,求解过程如下:
[0125]
(a)、引入辅助变量u
i
、v
i
、和拉格朗日算子d
i
,i=1,2,3,4,得到公式(4)
[0126]
(4)
[0127][0128]
(b)、公式(4)所述的u
i
用公式(5)表示
[0129][0130]
(c)、公式(4)所述的v
i
(i=1,2,3,4)用公式(6)进行计算,
[0131][0132]
式中,sign()代表符号函数,*代表hadamard积,竖线代表取绝对值,张量减去一个常数代表每个元素都减去该常数,矩阵除以一个常数代表每个位置都除以该常数;u
i
为辅助计算的参数。
[0133]
(d)、ηb采用公式(7)进行计算
[0134][0135]
(e)、βr采用用公式(8)进行计算
[0136][0137]
式中,倒三角上的b代表使用后向差分,不加b代表使用前向差分,这样做是为了在数值计算的过程中尽可能地将被差分位置像素周围的值都利用起来。
[0138]
(f)、拉格朗日算子d的计算方式为:
[0139]
d1=v1-u1[0140]
d2=v2-u2[0141]
d3=v3-u3[0142]
d4=v4-u4[0143]
(g)、将得到的βr二值化,二值化后的二值图记为rb。
[0144]
(h)、将rb中连通域小于minarea和连通域大于maxarea的区域判断为无雨的区域,并将这些区域的值设置为0,输出rb;minarea表示一个雨滴最小占用多少个像素,其取值为
如20;maxarea表示图像中一个雨滴最多占多少个像素,为了看得更清楚,图片中的雨滴较大,因此设置为1000。ratio表示图像中雨滴的长宽比,设置为5。
[0145]
以上所述priordetectrain算法的步骤可总结如下:
[0146]
①
输入灰度视频o,最单个雨滴占用的最大像素maxarea,单个雨滴最小像素minarea,单个雨滴的长宽比;计算过程中的参数u1=0.001,u2=0.03,u3=0.03,u4=0.01,实际计算过程中使用类似比例的数据也可以;初始化ηb=o,βr,d1,d2,d3,d4初始值设置为维度和o一样的全为0张量;最大执行次数maxstep=100。
[0147]
②
根据公式(5)计算u
[0148][0149]
式中d1、d2、d3、d4是拉格朗日乘数算子。
[0150]
③
根据公式(6)计算v1,v2,v3,v4[0151][0152]
式中,i的值取1,2,3,4,sign()代表符号函数,*代表hadamard积,竖线代表取绝对值,张量减去一个常数代表每个元素都减去该常数,矩阵除以一个常数代表每个位置都除以该常数。
[0153]
④
根据公式(7)计算ηb
[0154][0155]
⑤
根据公式(8)计算βr
[0156][0157]
式中,倒三角上的b代表使用后向差分,不加b代表使用前向差分,这样做是为了在数值计算的过程中尽可能地将被差分位置像素周围的值都利用起来。
[0158]
⑥
计算拉格朗日算子,d1=v1-u1,d2=v2-u2,d3=v3-u3,d4=v4-u4。
[0159]
⑦
重复
②③④⑤⑥
,当执行次数达到maxstep为止。
[0160]
⑧
将βr二值化,二值化的方式为灰度值大于0.01的值设置为1,小于0.01的设置为0,二值化后的二值图记为rb。
[0161]
⑨
将rb中连通域小于minarea和连通域大于maxarea的区域判断为无雨的区域,并将这些区域的值设置为0,输出rb。
[0162]
⑺
将步骤(2)中获得的视频或图像片和步骤(6)中获得的二值化视频或二值图采用nsderain模型对被雨所遮挡的部分进行修复,得到去雨后的图像b。
[0163]
由于处理的对象是视频,尤其是背景变化不剧烈或者静止的视频,时间维度上的信息对于修复缺失区域往往非常有效。雨的出现可以看作是随机的,当一个位置出现了雨,其前后几帧总会存在没有被雨遮挡的情况,这为修复图像提供了十分有效的信息。因此将
视频看做是三维空间的流体,三个维度分别是对应的视频的高、宽、和时间方向。在一块很小的灰度空间里,有一个连续的等亮度面u,其法向量为法向量与等亮度面垂直。如果该区域是一个自然连续的状态(即未被破坏的状态),那么与平行,因此其夹角的正弦为0,即
[0164][0165]
为了计算简便,将式(9)转化为余弦的形式,则等价于即
[0166][0167]
为了对式(10)进行求解,将方程转化为求出一个像素值u,使其满足方程(10)。但是在实际的计算过程中,往往有诸多限制,例如,像素的存储为8位无符号整型,其范围为0到255,或者受限于计算精度,该位置可能不存在一个值使方程恰好为0。并且,一个像素与周围像素的差值往往小于统计值i
d
。i
d
表示一张图中像素与周围像素值的差值的绝对值的分布的99%分位处的值,对于背景相邻区域变化较为平缓的单图或视频,可以将值设置为14,对于背景相邻区域变化较为陡峭的单图或视频,可以设置得更大。因此,将方程的求解过程转化为找到一个值u*使方程(11)最小,则步骤(7)所述雨修复模型表示为
[0168][0169]
式中,u*代表求解出来的使方程最小的u值,u是待修复的像素,是哈密顿算子,δ是拉普拉斯算子,w、h、t分表表示视频的宽、高,和时间上的维度。
[0170]
进一步地,在计算过程中,将l(u)离散化,对于三维,l(u)离散后的形式为
[0171][0172]
对于每一个待修复的雨滴(连通域)cr逐个进行修复。先按连通域的大小进行排序,先修复较小的雨滴,再修复较大的雨滴。对于每个雨滴中的像素,先修复周围未被雨污染的像素较多的位置。
[0173]
上述雨修复过程可以总结为如下步骤:
[0174]
①
输入待去雨的图像o,相邻像素的差值范围统计值i
d
,i
d
的值可以设置为14,或者根据统计的情况调大或调小;输入步骤(6)输出的二值图rb。
[0175]
②
对于每一个待修复的雨滴(连通域)cr逐个进行修复,先按连通域的大小进行排序,先修复较小的雨滴。
[0176]
③
对于雨滴(连通域)cr中的每一个像素的值u,计算其周围已知像素的个数,先修复周围已知像素较多的点。
[0177]
④
对于一个雨滴cr中的每一个像素值u,求出一个u*,满足,
[0178][0179]
并且并且|u*
‑
u|<i
d
,然后使用计算得出的u*替换u。
[0180]
⑤
重复
④
中的步骤,直到一轮运算中大多数像素值在计算过程中都不发生改变或者重复次数大于i
d
时,就停止对该雨滴区域的修复。
[0181]
⑥
输出修复之后的无雨的背景b。
[0182]
为了说明该发明的有效性,将使用模拟的数据和真实雨的数据评估本发明检测雨和去除雨的算法的性能。
[0183]
在纯黑背景的摄影棚拍摄的只有雨的视频,其大小为3840
×
2180,将得到的雨使用屏幕混合模型添加到无雨的视频中得到模拟的带雨视频。为了更便于观察细节和说明效果,仅仅裁剪(不是缩放)其中的一部分来展示实验结果。针对静态背景、有移动物体的静态背景、动态背景分别测试了检测雨的效果。从这些图中识别雨有一定的难度,因为他们有白色的涂料,与周围的强度差类似雨造成的强度差,并且形状很像雨,尤其是当背景是动态时更难分辨。实验结果如图3所示,从左至右分别是静态背景、有移动物体的静态背景和动态背景下的实验结果,从上到下为带雨的图,检测到的雨以及实际的雨的二值图。可见,本发明算法在静态背景下,几乎所有的雨滴都被检测出来了,并且精确地确定了雨滴的位置,百分之九十以上的雨像素被检测出来。在动态背景下也检测除了大多数雨滴。
[0184]
为了更好地定量地评估本发明方法的检测效果,在有移动物体的静态背景下,对不同算法的检测结果进行了测试,检测输出的二值图如图4所示,可以直观看出,本发明方法基本检测到了所有的雨滴,并且误差较小,由于进行了形态学处理,也避免了噪声和其他强度变化造成的错检,因此检测出来的雨滴最接近真实情况。为了定量分析,使用正确检测(cd)到的像素,检测错误(fd)的像素以及漏检(md)的像素数量作为评估依据,并且计算了它们与真实的雨滴像素的个数的比值,其量化结果如表1所示。对比的方法分别是dip(jiang t x,huang t z,zhao x l,et al.a novel tensor
‑
based video rain streaks removal approach via utilizing discriminatively intrinsic priors[c]//computer vision&pattern recognition.ieee,2017.)、mscsc(li m,qi x,qian z,et al.video rain streak removal by multiscale convolutional sparse coding[c]//2018ieee/cvf conference on computer vision and pattern recognition(cvpr).ieee,2018.)、garg’s(garg k,nayar s k.detection and removal of rain from videos[c]//computer vision and pattern recognition,2004.cvpr 2004.proceedings of the2004ieee computer society conference on.ieee,2004.)和jie’s(jie c,chau l p.a rain pixel recovery algorithm for videos with highly dynamic scenes[j].ieee transactions on image processing,2014,23(3):1097
‑
1104.)可以看出,本发明算法正确检测出的雨像素最高,并且同时拥有较低的错误检测率和漏检率。garg和chen的方法正确检测率较低,因为他们忽略了强度变化较小的像素。
[0185]
表1不同算法的检测结果定量比较
[0186]
算法cdfdmd
dip28121(8.03%)13305(40.7)4566(13.97%)mscsc29023(88.79%)13720(42.0%)3664(11.21%)garg’s17303(52.94%)106(0.3%)15384(47.1%)chen’s22133(67.7%)20875(63.7%)10554(22.9%)实施例129892(91.45%)2471(7.6%)2795(8.55%)
[0187]
为了验证本发明提出的修复算法是有效的,首先将文字添加到视频和图片中,进行去除测试。其结果如图5(a)
‑
(d)所示,分别是要添加的文字,添加的结果,使用本发明方法修复的结果和使用现有二维方法(m.bertalmio,a.l.ber tozzi and g.sapiro,"navier
‑
stokes,fluid dynamics,and image and video inpainting,")修复的结果。通过图5(c)和(d)可以看出,文字遮挡的黑色去雨被成功修复了,修复结果和原来没被污染的图基本一模一样。图5(e)
‑
(h)是本发明方法分别在接近静态的背景下和动态拍摄的真实下雨的视频的去除雨效果。可以看到,经过去雨之后,(f)雨明显变小,(h)的雨基本被去除。
[0188]
为了对去雨效果进行定量分析,将本发明方法与近几年提出的现有方法进行对比,使用的是有静止背景视频,但是视频中有一个移动的气球,这会提高检测和修复的难度。其结果如图6所示,可以看出,本发明算法基本将雨滴去除。为了定量评估算法的性能,使用fsim(feature similarity),gmsd(gradient magnitu de similarity deviation),psnr(peak signal
‑
to
‑
noise ratio),ssim(structural simil arity),uiqi(universal image quality index),vif(visual information fidelity)作为衡量指标。结果如表2所示,其中gmsd是越小效果越好,其余都是越大效果越好,加粗的为在该项指标中结果最好的。本发明算法获得三项第一,在没有获得第一的指标中,也是第二好的,总体上去雨效果很好。
[0189]
表2不同算法的去雨结果定量比较
[0190]
方法fsimgmsdpsnrssimuiqivifrainy0.98570.083433.180.96580.90570.8964ddn0.98940.046134.120.97190.89050.7918dip0.95840.038330.960.98210.94810.8238ms
‑
csc0.98770.021138.490.98030.92840.7961spac0.97540.045634.150.97820.93090.7843实施例10.98970.030937.790.98340.94280.8794
[0191]
注:ddn是文章(fu x,huang j,zeng d,et al.removing rain from single i mages via a deep detail network[c]//ieee conference on computer vision&pattern r ecognition.ieee,2017.)所述方法,spac为文章(jie c,tan c h,hou j,et al.rob ust video content alignment and compensation for rain removal in a cnn framework[c]//2018ieee/cvf conference on computer vision and pattern recognition.ieee,2018.)所述方法。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
