1.本发明属于视频问答技术领域,更为具体地讲,涉及一种基于动作捕捉的注意力网络的视频问答方法。
背景技术:
2.视频问答(video question answering,video qa)的主要目标是:输入任意的一个视频和一个对于该视频内容的提问,模型能通过对多模态输入的理解和推理,自动找出问题的答案。解决这个任务的典型方法是先用一个循环神经网络(rnn)处理问题文本,得到问题的特征向量;同时用一个卷积神经网络(cnn)逐帧处理输入视频,得到视频的特征向量;最后将两个模态的特征进行融合,并通过输出模块得到最终预测的答案。
3.现有的一些方法使用视觉或文本注意机制,帮助模型能更精准地关注到视频中的关键帧或问题中的关键单词。其次,为了给模型提供一些额外的知识,另一些方法利用了视频物体中的外部数据(如百科信息),它提供了关于该物体的一些常识信息,从而帮助提升回答问题的准确率。还有一些方法对视频帧中的物体关系进行建模,捕捉物体间关系在时间上的演变情况,从而使模型对输入能有更全面、更深层次的理解。
4.然而在视频帧的层面(粗粒度),现有方法通常对帧的整体变化进行建模,由于视频帧中可能包含多个物体而往往只有少量物体与提问有关,所以这是一种粗粒度的方法,它的识别精确度有限;其次,在视频帧中的物体层面(细粒度),现有的方法通常对同一帧的物体间的关系进行建模,并捕捉这种交互关系的动态变化情况。但是它们忽略了物体自身的动作变化情况,这对于回答问题同样十分关键。
技术实现要素:
5.本发明的目的在于克服现有技术的不足,提供一种基于动作捕捉的注意力网络的视频问答方法,通过设计一个基于动作捕捉的注意力网络(maan),能够同时在细粒度和粗粒度层面捕捉视频中所有物体自身的动作改变情况,并结合提问得到预测的答案。
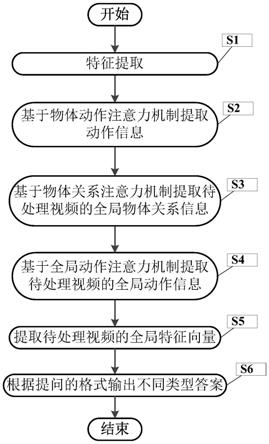
6.为实现上述发明目的,本发明一种基于动作捕捉的注意力网络的视频问答方法,其特征在于,包括以下步骤:
7.(1)、特征提取
8.(1.1)、将待处理视频输入至faster rcnn网络中,提取出每一视频帧中物体的特征,其中,第j帧中第k个物体的特征记为v
j,k
,j=1,2
…
,n,k=1,2,
…
,k,n表示视频的总帧数,k表示每帧画面提取的物体个数;
9.(1.2)、将待处理视频分割成多个视频片段,然后将每一个视频片段输入至resnext网络,提取出每一个视频片段的特征,记为v
i
,i=1,2,
…
,c,c为待处理视频被分割成视频片段的数量;
10.(1.3)、将待处理的提问先后经过bi_lstm网络和自注意力机制的处理,提取出提问的特征,记为q;
11.(2)、基于物体动作注意力机制提取动作信息u;
12.(2.1)、通过双向bi_lstm网络提取物体的动作信息u
j,k
;
13.u
j,k
=bi_lstm(v
j,k
)
14.(2.2)、使用物体动作注意力机制对不同时刻的特征进行加权,得到当前物体k在整个视频内的全局动作信息u
k
;
[0015][0016]
β
j,k
=softmax(w1u
j,k
w2q)
[0017]
其中,w1、w2为权重参数;β
j,k
表示第j帧中第k个物体的重要程度指标;
[0018]
(2.3)、使用物体动作注意力机制提取整个视频与提问有关的动作信息u;
[0019][0020]
α
k
=softmax(w3u
k
w4q)
[0021]
其中,w3、w4为权重参数;α
k
表示第k个物体与提问的关联程度指标;
[0022]
(3)、基于物体关系注意力机制提取待处理视频的全局物体关系信息μ;
[0023]
(3.1)、使用物体关系注意力机制计算当前视频帧j中的物体关系信息μ
j
;
[0024][0025]
γ
j,k
=softmax(w5v
j,k
w6q)
[0026]
其中,w5、w6为为权重参数,γ
j,k
是第j帧中第k个物体的关系值;
[0027]
(3.2)、将不同时刻的物体关系信息μ
j
按先后顺序构成序列,然后输入至bi
‑
lstm网络,从而提取出整个视频的全局物体关系信息μ;
[0028]
μ=bi_lstm(μ1,μ2,
…
,μ
j
,
…
μ
n
)
[0029]
(4)、基于全局动作注意力机制提取待处理视频的全局动作信息u;
[0030]
(4.1)、计算第i个视频片段的特征v
i
的权重值λ
i
;
[0031]
λ
i
=softmax(w7v
i
w8q)
[0032]
其中,w7、w8为权重参数;
[0033]
(4.2)、使用全局动作注意力机制计算整个视频的全局动作信息;
[0034][0035]
(5)、提取待处理视频的全局特征向量f;
[0036]
(5.1)、对三种注意力机制下提取的信息进行融合:表示向量拼接操作;
[0037]
(5.2)、提取整个视频的全局特征向量f;
[0038][0039]
其中,与φ(q)表示统一向量与q的维度,表示向量的对应元素乘积;
[0040]
(6)、根据提问的格式输出不同类型答案;
[0041]
(6.1)、确定待处理的提问的格式,具体包括三种提问格式:选择式、开放式单词、开放式数字;
[0042]
(6.2)、当待处理的提问为选择式时,将待处理的提问视为一个五分类的场景,再利用lstm网络提取每类场景的特征c
τ
,τ=1,2,3,4,5;然后计算出每类场景的概率值最后选出最大的一个概率值作为预测结果;
[0043]
(6.3)、当待处理的提问为开放式单词时,将待处理的提问视为一个n多分类的场景,然后利用softmax函数提取n类场景的概率矩阵p,最后在概率矩阵p中选择最大概率值对应的单词作为预测结果;
[0044]
(6.4)、当待处理的提问为开放式数字时,将待处理的提问视为一个线性回归问题,通过全连接层将全局特征向量f转为实数并取整作为预测结果,即最终预测结构为:
[0045]
本发明的发明目的是这样实现的:
[0046]
本发明基于动作捕捉的注意力网络的视频问答方法,先提取将待处理视频和待处理的提问的特征,然后基于这些特征,通过物体动作注意力机制提取动作信息,通过物体关系注意力机制提取待处理视频的全局物体关系信息,通过全局动作注意力机制提取待处理视频的全局动作信息;接着对三种注意力机制下提取的信息进行融合,提取整个视频的全局特征向量;最后基于全局特征向量根据提问的格式输出不同类型答案。
[0047]
同时,本发明基于动作捕捉的注意力网络的视频问答方法还具有以下有益效果:
[0048]
(1)、本发明通过两个不同的注意力模块来分别引导模型从细粒度、粗粒度角度捕捉视频动作,从而获取视频中全局的和局部的动作信息;
[0049]
(2)、本发明通过物体关系注意力模块额外捕捉视频物体间的动态关系,从而进一步提升回答问题的准确率。
附图说明
[0050]
图1是本发明基于动作捕捉的注意力网络的视频问答方法流程图;
具体实施方式
[0051]
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
[0052]
实施例
[0053]
图1是本发明基于动作捕捉的注意力网络的视频问答方法流程图。
[0054]
在本实施例中,如图1所示,本发明一种基于动作捕捉的注意力网络的视频问答方法,包括以下步骤:
[0055]
s1、特征提取
[0056]
s1.1、将待处理视频输入至faster rcnn网络中,提取出每一视频帧中物体的特征,其中,第j帧中第k个物体的特征记为v
j,k
,j=1,2
…
,n,k=1,2,
…
,k,n表示视频的总帧数,k表示每帧画面提取的物体个数;在本实施例中,n的取值为32,k的取值为20,每一个物
体的特征的维度为2048;
[0057]
c取值为8,d
r
和d
m
的取值都是2048。
[0058]
s1.2、将待处理视频分割成多个视频片段,然后将每一个视频片段输入至resnext网络,提取出每一个视频片段的特征,记为v
i
,i=1,2,
…
,c,c为待处理视频被分割成视频片段的数量;在本实施例中,c的取值为8,每一个视频片段的特征的维度为2048;
[0059]
s1.3、将待处理的提问先后经过bi_lstm网络和自注意力机制的处理,提取出提问的特征,记为q;在本实施例中,提问的特征的维度为1024。
[0060]
为了全面地理解和融合多模态输入,本发明采用多分支注意机制进行特征提取,具体提出了三个不同的注意力模块来分别引导模型从细粒度、粗粒度角度捕捉视频动作,以及物体间的动态关系,过程如下:
[0061]
s2、基于物体动作注意力机制提取动作信息u;
[0062]
s2.1、给定任意一个视频,对视频内容的提问往往是针对于某个视频物体前后的动作变化情况。所以捕捉视频中物体自身的动作演变,对于准确回答问答十分有帮助。为此,本发明首先通过双向bi_lstm网络提取物体的动作信息u
j,k
;
[0063]
u
j,k
=bi_lstm(v
j,k
)
[0064]
s2.2、使用物体动作注意力机制对不同时刻的特征进行加权,得到当前物体k在整个视频内的全局动作信息u
k
;
[0065][0066]
β
j,k
=softmax(w1u
j,k
w2q)
[0067]
其中,w1、w2为权重参数;β
j,k
表示第j帧中第k个物体的重要程度指标,值越大代表越相关,值越小代表越不相关;
[0068]
s2.3、由于提问往往针对于某个视频物体,所以视频中不相关的视频物体对于回答问题会带来额外的干扰。所以,本发明使用物体动作注意力机制使模型能聚焦最相关的物体,屏蔽不相关物体的影响。最后所有物体动作信息的加权和即为整个视频与提问有关的动作信息u;
[0069][0070]
α
k
=softmax(w3u
k
w4q)
[0071]
其中,w3、w4为权重参数;α
k
表示第k个物体与提问的关联程度指标,值越大代表越相关,值越小代表越不相关;
[0072]
s3、基于物体关系注意力机制提取待处理视频的全局物体关系信息μ;
[0073]
s3.1、在一些复杂情况下,提问还会涉及到物体之间的关系,例如”what are the two men do after hugging?”。此时仅仅关注物体自身的运动情况是不够的,还得关注物体之间的交互关系。本发明的物体关系注意力模块先计算当前视频帧j中的物体关系信息μ
j
;
[0074]
[0075]
γ
j,k
=softmax(w5v
j,k
w6q)
[0076]
其中,w5、w6为为权重参数,γ
j,k
是第j帧中第k个物体的关系值;
[0077]
s3.2、将不同时刻的物体关系信息μ
j
按先后顺序构成序列,然后输入至bi
‑
lstm网络,从而提取出整个视频的全局物体关系信息μ;
[0078]
μ=bi_lstm(μ1,μ2,
…
,μ
j
,
…
μ
n
)
[0079]
s4、基于全局动作注意力机制提取待处理视频的全局动作信息u;
[0080]
s4.1、相比之下,s2.1中物体动作注意力模块获取到的是细粒度的动作信息,本发明还设计了第三个分支,它提供粗粒度的全局动作信息,这对于回答问题也很有用。首先,我们为每一个视频片段的特征计算一个权重值,该权重代表该视频段的动作与提问的相关程度,其中,第i个视频片段的特征v
i
的权重值λ
i
;
[0081]
λ
i
=softmax(w7v
i
w8q)
[0082]
其中,w7、w8为权重参数;λ
i
的值越大关联度越高;
[0083]
s4.2、使用全局动作注意力机制将所有视频段的加权和作为整个视频的粗粒度动作信息,即全局动作信息;
[0084][0085]
s5、提取待处理视频的全局特征向量f;
[0086]
s5.1、在上面三个注意力模块都各自完成信息的提取后,本发明设计了一个输出模块对三个分支的信息进行融合:表示向量拼接操作;
[0087]
s5.2、提取整个视频的全局特征向量f;
[0088][0089]
其中,与φ(q)表示统一向量与q的维度,表示向量的对应元素乘积;
[0090]
s6、根据提问的格式输出不同类型答案;
[0091]
s6.1、确定待处理的提问的格式,具体包括三种提问格式:选择式、开放式单词、开放式数字;
[0092]
s6.2、当待处理的提问为选择式时,选择式问题会提供五个候选答案作为选项,其中有且只有一个选项是正确的,如果模型选出正确的那个选项,就代表预测正确。对于此类问题,我们将待处理的提问视为一个五分类的场景,再利用lstm网络提取每类场景的特征c
τ
,τ=1,2,3,4,5;然后计算出每类场景的概率值最后选出最大的一个概率值作为预测结果;
[0093]
s6.3、当待处理的提问为开放式单词时,此时不会提供候选答案,我们先收集最常出现的n个单词作为词汇表,然后将待处理的提问视为一个n多分类的场景,然后利用softmax函数提取n类场景的概率矩阵p,最后在概率矩阵p中选择最大概率值对应的单词作为预测结果;其中,概率矩阵p中每类场景的概率值同样以公式计算,τ=1,2,
…
,n;
[0094]
s6.4、当待处理的提问为开放式数字时,开放式数字类问题也不会提供任何候选项,它的答案是一个[0,10]之间的整数,我们将待处理的提问视为一个线性回归问题,通过
全连接层将全局特征向量f转为实数并取整作为预测结果,即最终预测结构为:
[0095]
本实施例在两个个大型的基准数据集1(tgif
‑
qa)和数据集2(msrvtt
‑
qa)上测试该方法的效果,如表1、表2所示,从实验的效果可以可知,本发明提出的方法优于最高水平的方法。
[0096]
表1数据集1上的实验结果
[0097][0098][0099]
从表中可以得出,本发明提出的模型在绝大多数子任务中取得了最好的表现,在数据集1中的动作转移和视频帧问答两个子任务上分别取得了82.9%和58.3%的最高准确率,在动作计数子任务上取得了3.74的最低均方误差。
[0100]
表2数据集2上的实验结果
[0101]
模型什么谁怎样什么时候什么地点总体准确率空间注意力模型24.541.278.076.534.930.9共内存模型23.942.574.169.042.932.0异构内存模型26.543.682.476.028.633.0时空共注意力模型27.445.483.774.033.234.2问题注意力模型27.945.683.075.731.634.6集联条件关系模型29.444.582.977.133.635.3多交互模型29.545.083.274.742.435.4异构图模型29.245.783.575.234.035.5本专利(maan)30.547.381.576.432.036.8
[0102]
从表中可以得出,本发明提出的模型在数据集2上的取得了36.8%的整体准确率,比现有的方法都更高。
[0103]
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技
术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
