1.本发明涉及反讽检测领域,具体涉及一种基于条件融合的多模态反讽检测方法。
背景技术:
2.情感分析结果会受到很多因素的影响,当文本存在反语或讽刺内容时,就会翻转句子的情感极性,这就需要使用反讽检测方法,其旨在检测文本中是否含有讽刺内容。
3.现有的研究大多是基于单一文本模态进行的,模型通过寻找句子中相互矛盾的情感来检测讽刺。在很多场景中,通过文本模态的语言表达不足以找到讽刺的语义线索,而通过与文本对应的视频、语音模态结合可以挖掘出讽刺语义。
技术实现要素:
4.本发明的目的是针对现有的反讽检测方法的不足,提出了一种基于多层transformer编码器架构的多模态反讽检测模型(cf
‑
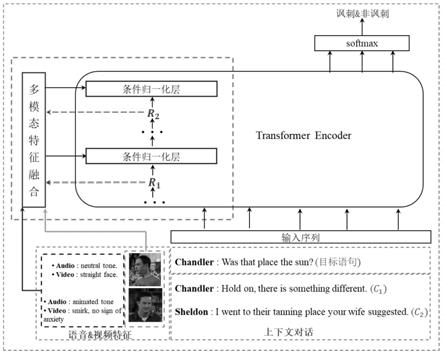
msd)。为了让多模态特征信息能更有效的融合,针对transformer编码器的归一化层提出了一种条件归一化方法,将视频、语音特征通过多头注意力机制获得与情感相关的语境信息,然后以增量参数的形式加入到原始归一化层的增益g(gain)和偏置b(bias)中,再通过transformer编码器的层层迭代,将视频、语音等模态特征融合到文本模态特征中,得到融合后的语义编码,用以来判断目标对话是否含有讽刺。
5.本发明具体实现步骤如下:
6.步骤1、对需要进行反讽检测的数据文本进行预训练;对数据文本对应的视频和音频进行编码,得到视频特征和音频特征;
7.步骤2、将处理好的数据文本馈送到编码器te中;将数据的视频特征和音频特征通过多头注意力机制获得与情感相关的语境信息;
8.步骤3、将语境信息以增量参数的形式加入到编码器的层归一化的增益g和偏置b中,将视频、音频特征融合到文本特征中,获得融合后的语义编码;
9.步骤4、将语义编码通过softmax层进行讽刺的极性分类;
10.步骤1具体实现如下:
11.1.1对于数据文本,每条训练数据都包含上下文对话context和目标对话target,将上下文对话和目标对话联合作为transformer编码器的输入x,计算方式如下:
12.x=context target
ꢀꢀꢀ
(1)
13.1.2使用ekphrasis分词工具对输入x进行分词,然后预训练一个word2vec模型来学习每个词的语义特征以获得词向量表示;
14.1.3对于数据文本对应的音频,通过使用librosa库,提取音频的基础特征;每段音频被切成不重合的小窗,提出不同特征拼接后将每段小窗取平均,对于整段音频就能够得到一个283维的向量;
15.1.4对于数据文本对应的视频,在抽帧后放入一个由imagenet预训练好的resnet
‑
152网络进行提取,然后对视频抽帧取平均,获得一个2048维的向量。
16.进一步的,步骤2具体实现如下:
17.2.1输入序列x馈送到transformer编码器,首先会先经过第一层的多头注意力机制,该多头注意力机制将head数设置为12来,从而生成12个不同的特征矩阵;由于最后的输出矩阵要与输入矩阵大小一致,因此,得到的特征矩阵会按第二个维度拼接起来;然后经过第二层全连接层后得到多头注意力机制层的输出矩阵z;最后,将z与x融合得到矩阵r1,用于后面层归一化的操作;其计算过程如下:
18.z=multihead(q,k,v)=[h ead1;...;h ead
h
]w
o
ꢀꢀꢀꢀ
(2)
[0019][0020][0021]
r1=z x
ꢀꢀꢀꢀ
(5)
[0022]
其中,分别是查询q、键k、值v以及多头注意力机制输出矩阵的的投影矩阵,h是多有注意力机制的头数,h ead
i
是第i个注意力的输出;
[0023]
2.2在每个transformer编码器(te)的子层中都使用两个关系记忆模块rm;rm的核心内容是使用了多头注意力机制,将来自层归一化的输入向量r
t
作为查询q,视频特征和图片特征联合成f={f1,f2,
…
,f
n
}作为键k和值v,通过query和key的相似度来获得关键的特征信息h
t
,并将特征信息通过mlp变换为
△
g
t
和
△
b
t
,此
△
g
t
和
△
b
t
将在下一小节中作为条件融入到原始层归一化的g和b中;其次,将rm模块集成到transformer编码器中,随着多个transformer编码器的层层叠加,rm模块会不断地从上一层的交互信息中保存有效信息并进一步提取更深层次的抽象信息用于调节transforme编码器中文本模态的语境信息提取;其计算过程如下:
[0024]
h
t
=f
multi
‑
h ead
(r
t
,f)
ꢀꢀꢀꢀ
(6)
[0025]
△
g
t
=f
mlp
(h
t
)
ꢀꢀꢀꢀꢀ
(7)
[0026]
△
b
t
=f
mlp
(h
t
)
ꢀꢀꢀꢀꢀ
(8)
[0027]
其中,r
t
为层归一化的输入向量,当t=1时,r1=z x;当t=0时,r0=x,即第一次的query为输入序列x。
[0028]
进一步的,步骤3具体实现如下:
[0029]
3.1在transformer编码器使用的是层归一化ln,特征x通过μ和σ,得到归一化后的值为x',公式可表示为:
[0030][0031]
其中,μ和σ分别表示归一化统计量均值和方差,ε是一个很小的小数,防止除0;
[0032]
在层归一化ln,也需要一组参数来保证归一化操作不会破坏之前的信息,这组参数叫做增益g(gain)和偏置b(bias),ln的输出可表示为:
[0033]
f
ln
(x')=g
☉
x' b
ꢀꢀꢀꢀꢀꢀꢀ
(10)
[0034]
合并上述两个公式,ln层最终输出可表示为:
encoder)和集成到te中的关系记忆模块(rm,renational memory)。关系记忆模块用于其他模态和文本模态进行建模,提取与te模块的隐层状态信息(语境信息)相关的其他跨模态(视频和音频)交互信息。te模块用于对文本模态进行建模,通过多层叠加的编码器来提取文本中的深层次语境信息,本文提出将每层编码层中的无条件归一化替换成条件归一化的方法融合rm模块的跨模态交互信息和文本的隐层信息。条件归一化的融合方式可以有效地融合其他模态特征与文本模态特征,且不会影响文本模态中提取到的某些核心信息。最后通过获取的语义编码来判断目标对话是否含有讽刺。
附图说明
[0051]
图1是本发明所述方法的流程框图。
[0052]
图2是本发明所述模型方法的架构图。
具体实施方式
[0053]
下面结合附图对本发明作进一步描述。
[0054]
参照图1和图2,基于上下文感知嵌入的细粒度情感分析方法,包括以下步骤:
[0055]
步骤1、对需要进行反讽检测的数据文本进行预训练;对数据文本对应的视频和音频进行编码,得到视频特征和音频特征。
[0056]
步骤2、将处理好的数据文本馈送到编码器te中;将数据的视频特征和音频特征通过多头注意力机制获得与情感相关的语境信息。
[0057]
步骤3、将语境信息以增量参数的形式加入到编码器的层归一化的增益g和偏置b中,将视频、音频特征融合到文本特征中,获得融合后的语义编码。
[0058]
步骤4、将语义编码通过softmax层进行讽刺的极性分类。
[0059]
步骤1具体实现如下:
[0060]
1.1对于数据文本,每条训练数据都包含上下文对话(context)和目标对话(target),本文将上下文对话和目标对话联合作为模型的输入x,计算方式如下:
[0061]
x=context target
[0062]
1.2使用ekphrasis分词工具对输入x进行分词,然后预训练一个word2vec模型来学习每个词的语义特征以获得词向量表示。
[0063]
1.3对于数据文本对应的音频,通过使用librosa库,提取了音频的基础特征,如mfcc,过零率等。每段音频被切成不重合的小窗,提出不同特征拼接后将每段小窗取平均,对于整段音频就可以得到一个283维的向量。
[0064]
1.4对于数据文本对应的视频,在抽帧后放入一个由imagenet预训练好的resnet
‑
152网络进行提取,然后,对视频抽帧取平均,获得一个2048维的向量。
[0065]
进一步的,步骤2具体实现如下:
[0066]
2.1模型将输入序列x馈送到编码器中,会先经过第一层的多头注意力机制(本方法中将head数设置为12来生成12个不同的特征矩阵),由于最后的输出矩阵要与输入矩阵大小一致,因此,得到的特征矩阵会按第二个维度拼接起来,然后经过第二层全连接层后得到多头注意力机制层的输出矩阵z,最后,将z与x融合得到矩阵r1,用于后面层归一化的操作。其计算过程如下:
[0067]
z=multihead(q,k,v)=[h ead1;...;h ead
h
]w
o
[0068][0069][0070]
r1=z x
[0071]
其中,分别是查询q、键k、值v以及多头注意力机制输出矩阵的的投影矩阵,h是多有注意力机制的头数,h ead
i
是第i个注意力的输出。
[0072]
2.2在每个te层的子层中都使用了两个关系记忆模块(rm)。rm的核心内容是使用了多头注意力机制,将来自层归一化的输入向量r
t
作为查询q(query),视频特征和图片特征联合成f={f1,f2,
…
,f
n
}作为键k(key)和值v(value),通过query和key的相似度来获得关键的特征信息h
t
,并将特征信息通过mlp变换为
△
g
t
和
△
b
t
,此
△
g
t
和
△
b
t
将在下一小节中作为条件融入到原始层归一化的g和b中。其次,将rm模块集成到te模块中,随着te模块中编码器的层层叠加,rm模块会不断地从上一层的交互信息中保存有效信息并进一步提取更深层次的抽象信息用于调节编码器中文本模态的语境信息提取。其计算过程如下:
[0073]
h
t
=f
multi
‑
h
ead
(r
t
,f)
[0074]
△
g
t
=f
mlp
(h
t
)
[0075]
△
b
t
=f
mlp
(h
t
)
[0076]
其中,r
t
为层归一化的输入向量,例如,当t=1时,r1=z x,特别的,当t=0时,r0=x,即第一次的query为输入序列x。
[0077]
进一步的,步骤3具体实现如下:
[0078]
3.1在te中使用的是层归一化(ln,layer normalization),ln是一个独立于batch size的算法,所以无论样本数多少都不会影响参与ln计算的数据量。可以计算ln的归一化统计量均值μ和方差σ,统计量的计算是和样本数量没有关系的,它的数量只取决于隐层节点的数量,所以只要隐层节点的数量足够多,就能保证ln的归一化统计量足够具有代表性。特征x通过μ和σ,可以得到归一化后的值为x',公式可表示为:
[0079][0080]
其中,ε是一个很小的小数,防止除0。
[0081]
在ln中,也需要一组参数来保证归一化操作不会破坏之前的信息,这组参数叫做增益g(gain)和偏置b(bias),ln的输出可表示为:
[0082]
f
ln
(x')=g
☉
x' b
[0083]
合并上述两个公式,ln层最终输出可表示为:
[0084][0085]
对于transformer编码器来说,已经有现成的、无条件的g和b了,它们都是长度固定的向量。本文将辅助特征信息
△
g
t
和
△
b
t
集成到te中无条件ln的g和b中去,形成条件ln。
为了防止扰乱原来的预训练权重,两个变换矩阵可以全零初始化,这样在初始状态,模型依然保持跟原来的预训练模型一致。公式如下:
[0086][0087][0088]
在此模型中,特征x为归一化层的输入向量r
t
,则通过ln之后获得的特征结果如下:
[0089][0090]
其中,r
t
为上一层的输出;μ和v是分别是平均值和方差。
[0091]
在te中,rm模块会集成到所有的编码层中,将编码层中的归一化都加入条件输入形成条件归一化层,用来动态调节te中的编码过程。
[0092]
进一步的,步骤4具体实现如下:
[0093]
4.1当在te中堆叠多个编码器时,编码器的输入直接用作下一个编码器的输入。由于训练分类器需要向量表示,在最后一个编码器的输出s上应用了全局平均池化。池化向量g∈r
d
用作单层前馈网络的输入,其输出层是计算任务p={0,1}的两类上的概率分布,公式可表示为:
[0094]
o=softmax(max(0,gw1 b1)w2 b2)
[0095]
其中是p上的概率分布,是应用在g上的隐藏层的权重矩阵,是输出层的权重矩阵。针对实验语料库的不平衡性,考虑到训练集中每个类的分布情况,采用加权交叉熵作为网络训练的损失函数。公式可表示为:
[0096][0097]
其中是数据集,是损失函数,f是由θ参数化的模型。我们使用adam作为更新规则,noam作为学习速率衰减的模式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
