1.本发明属于网络安全技术领域,尤其涉及一种基于软件基因的抗混淆二进制代码克隆检测方法。
背景技术:
2.近年来,随着信息技术的发展进步,各类软件方便人们生活的同时,也带来很多安全问题,比如代码剽窃、软件侵权、恶意代码肆虐。为解决这类问题,逆向工程显得尤为必要,通过识别逆向后的未知代码,并同已知代码库进行比较,检测代码片段的重复率或者相似性,从而解决软件侵权、恶意代码变种等问题。但由于各种混淆工具愈发成熟,混淆策略复杂多样,即便逻辑功能相似的程序,经类似工具混淆之后,逆向出的反汇编代码在结构和逻辑上都差别很大。这些混淆技术虽然在很大程度上保护了软件的版权,但也造成了难以检测代码剽窃、恶意代码变种(m.lindorfer,a.di federico,f.maggi,p.m.comparetti,and s.zanero,“lines of malicious code:insights into the malicious software industry,”in proceedings of the 28th annual computer security applications conference on
‑
acsac’12,orlando,florida,2012,p.349,doi:10.1145/2420950.2421001.)等种种问题。虽然目前也有很多关于研究二进制代码相似性(y.hu,y.zhang,j.li,h.wang,b.li,and d.gu,“binmatch:a semantics
‑
based hybrid approach on binary code clone analysis,”arxiv:1808.06216[cs],aug.2018,accessed:mar.28,2021.[online].available:http://arxiv.org/abs/1808.06216.)的方法,但这些方法都不能很好地抵御混淆技术(l.luo,j.ming,d.wu,p.liu,and s.zhu,“semantics
‑
based obfuscation
‑
resilient binary code similarity comparison with applications to software plagiarism detection,”in proceedings of the 22nd acm sigsoft international symposium on foundations of software engineering
‑
fse 2014,hong kong,china,2014,pp.389
–
400,doi:10.1145/2635868.2635900.)。
技术实现要素:
[0003]
本发明针对现有二进制代码相似性方法存在不能很好地抵御混淆技术的问题,提出一种基于软件基因的抗混淆二进制代码克隆检测方法,能够在抵抗混淆选项的同时,有效地检测二进制代码的相似程度。
[0004]
为了实现上述目的,本发明采用以下技术方案:
[0005]
一种基于软件基因的抗混淆二进制代码克隆检测方法,包括:
[0006]
步骤1:使用obfuscator
‑
llvm编译器对源程序进行编译,得到对应的汇编程序;
[0007]
步骤2:遍历所有的汇编程序文件,解析汇编程序文件的内容,提取汇编程序的程序控制流图,得到多个基本块,并保存到data数据结构中;
[0008]
步骤3:将data数据结构中的基本块分割成软件基因块,去除空的基本块,将细分后的软件基因块转存到gene数据结构中;
[0009]
步骤4:将gene数据结构中的软件基因块进行汇编指令规范化;
[0010]
步骤5:利用随机游走算法遍历程序控制流图中的节点,即基本块,获取软件基因序列作为训练集,所述软件基因序列由多个软件基因块组成,采用word2vec对软件基因序列中的汇编指令进行词嵌入,然后采用doc2vec对软件基因序列进行语义嵌入,提取汇编函数的语义信息,得到包含汇编函数语义信息的数学向量,对同一汇编函数的多个数学向量进行拼接,采用余弦相似度的方法计算拼接后数学向量的相似度,实现汇编函数间的相似度比较,完成二进制代码克隆检测。
[0011]
进一步地,所述步骤2中,遍历所有的汇编程序文件,解析汇编程序文件的内容包括:
[0012]
首先创建一个collections.ordereddict()数据对象data,其中保存所有汇编程序文件的内容,键名为每一个汇编程序文件的文件名,键值是一个新的collections.ordereddict()数据对象,在该新的collections.ordereddict()数据对象中,键名为当前汇编程序文件中的函数名,键值仍然为一个collections.ordereddict()数据对象,在该数据对象中,键名为当前函数中的标号,即每一个基本块的标识,键值是一个列表,列表中存放当前基本块中的汇编指令。
[0013]
进一步地,所述步骤3中,将data数据结构中的基本块分割成软件基因块包括:
[0014]
遍历基本块中的每一条汇编指令,发现当前指令是跳转指令,则当前软件基因块结束,如果该基本块中后面还有其他指令,则新创建一个软件基因块来保存接下来的汇编指令序列。
[0015]
进一步地,所述步骤4包括:
[0016]
寄存器%eax,%ebx,%edx均使用“reg”代替,立即数均使用“imm”代替,访问的内存地址均使用“address”代替,call指令后面的函数名使用“func”代替,变量名使用“var”代替,汇编程序中的标号使用“label”代替。
[0017]
进一步地,在所述步骤4之后,还包括:
[0018]
将提取到的数据保存到文件中,每一个汇编函数保存为两个文件,一个文件*.edge中保存该汇编函数中的所有基本块以及基本块之间的连接关系,另一个文件*.node中保存每一个基本块对应的软件基因块的汇编指令序列。
[0019]
进一步地,所述步骤5中,采用word2vec对软件基因序列中的汇编指令进行词嵌入包括:
[0020]
将汇编指令作为单词,将若干汇编指令组成的软件基因块作为句子,将若干软件基因块组成的软件基因序列作为段落,采用word2vec模型的skip
‑
gram体系架构,以一条完整的汇编指令为单位获取词向量。
[0021]
与现有技术相比,本发明具有的有益效果:
[0022]
1.与从二进制文件逆向到汇编程序不同,本发明采用从正向的角度分析二进制代码,即从源代码编译到汇编程序,二者效果相同,但本发明能显著减少工作量;
[0023]
2.采用随机游走算法将程序控制流图转换为软件基因序列,可以将控制流图转化成顺序的汇编代码序列,巧妙地绕过了图匹配算法,有效降低了计算复杂度,提高了效率;
[0024]
3.通过采用word2vec对软件基因序列中的汇编指令进行词嵌入,然后采用doc2vec对软件基因序列进行语义嵌入的方法对汇编程序进行处理,得到包含汇编程序语
义信息的向量,使得能够在抵抗混淆选项的同时,有效地检测二进制代码的相似程度。
附图说明
[0025]
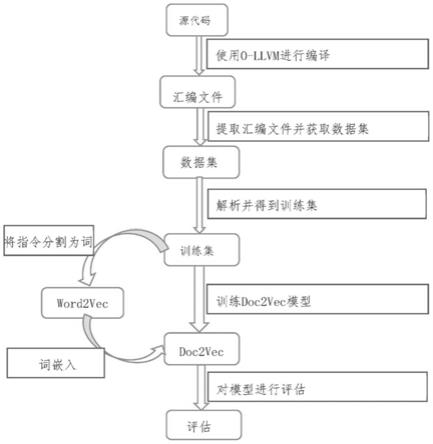
图1为本发明实施例一种基于软件基因的抗混淆二进制代码克隆检测方法的流程图;
[0026]
图2为本发明实施例一种基于软件基因的抗混淆二进制代码克隆检测方法的基本块划分示例图;
[0027]
图3为本发明实施例一种基于软件基因的抗混淆二进制代码克隆检测方法的软件基因块切分示例图;
[0028]
图4为本发明实施例一种基于软件基因的抗混淆二进制代码克隆检测方法的汇编指令规范化过程示例图;
[0029]
图5为本发明实施例一种基于软件基因的抗混淆二进制代码克隆检测方法的词向量提取示例图之一;
[0030]
图6为本发明实施例一种基于软件基因的抗混淆二进制代码克隆检测方法的词向量提取示例图之二;
[0031]
图7为本发明实施例一种基于软件基因的抗混淆二进制代码克隆检测方法的词向量提取效果图之一;
[0032]
图8为本发明实施例一种基于软件基因的抗混淆二进制代码克隆检测方法的词向量提取效果图之二;
[0033]
图9为本发明实施例一种基于软件基因的抗混淆二进制代码克隆检测方法的不同词向量维度对应的函数间的相似度折线图。
具体实施方式
[0034]
下面结合附图和具体的实施例对本发明做进一步的解释说明:
[0035]
如图1所示,一种基于软件基因的抗混淆二进制代码克隆检测方法,包括:
[0036]
步骤s101:使用obfuscator
‑
llvm编译器(o
‑
llvm编译器)对源程序进行编译,得到对应的汇编程序;
[0037]
步骤s102:遍历所有的汇编程序文件,解析汇编程序文件的内容,提取汇编程序的程序控制流图(cfg),得到多个基本块,并保存到data数据结构中;
[0038]
步骤s103:将data数据结构中的基本块分割成软件基因块,去除空的基本块,将细分后的软件基因块转存到gene数据结构中;
[0039]
步骤s104:将gene数据结构中的软件基因块进行汇编指令规范化;
[0040]
步骤s105:利用随机游走算法遍历程序控制流图中的节点,即基本块,获取软件基因序列作为训练集,所述软件基因序列由多个软件基因块组成,采用word2vec对软件基因序列中的汇编指令进行词嵌入,然后采用doc2vec对软件基因序列进行语义嵌入,提取汇编函数的语义信息,得到包含汇编函数语义信息的数学向量,对同一汇编函数的多个数学向量进行拼接,采用余弦相似度的方法计算拼接后数学向量的相似度,实现汇编函数间的相似度比较,完成二进制代码克隆检测。
[0041]
具体地,步骤s101中:
[0042]
obfuscator
‑
llvm是一个支持多平台的llvm编译套件,能够通过代码混淆和防篡改功能保障软件的安全性问题。其主要的混淆功能包含三种:指令替换、虚假控制流、控制流平坦化。分别利用上述的三种主要混淆技术对源程序进行编译。我们选择开源且应用比较广泛的openssl源代码及其他的一些开源代码库,详细信息如表格1所示。然后使用obfuscator
‑
llvm编译器进行编译,得到对应的汇编程序。
[0043]
表格1数据集描述
[0044][0045]
具体地,步骤s102中:
[0046]
遍历所有的汇编程序文件,解析汇编程序文件的内容。解析的过程如下:首先创建一个collections.ordereddict()数据对象data,其中保存所有汇编程序文件的内容,键名为每一个汇编程序文件的文件名,键值是一个新的collections.ordereddict()数据对象,在该新的collections.ordereddict()数据对象中,键名为当前汇编程序文件中的函数名,键值仍然为一个collections.ordereddict()数据对象,在该数据对象中,键名为当前函数中的标号,即每一个基本块的标识,键值是一个列表,列表中存放当前基本块中的汇编指令。完成所有汇编程序文件的解析,就将所有汇编代码保存到了data数据结构中了,这样就划分好了基本块。基本块的划分如图2所示。
[0047]
具体地,步骤s103中:
[0048]
软件基因是根据汇编程序的功能将其划分为一个个代码片段,称之为软件基因。基因这里借鉴软件基因的概念,将原本的基本块切分成一个个“软件基因块”,每一个软件基因块中的控制流程都是顺序执行,仅在最后一条指令是跳转指令或者ret指令。软件基因块与软件基因块之间根据程序的逻辑结构连接。
[0049]
汇编程序文件解析之后的主要数据保存在了data数据结构中,此处主要是针对data数据中每一个基本块,再次进行细化,将基本块分割成软件基因块,并且去除空的基本块,将细分后的软件基因块转存到gene数据结构中。细分的具体过程大致为:遍历基本块中的每一条指令,发现当前指令是跳转指令,则当前软件基因块结束,如果该基本块中后面还有其他指令,那么就新创建一个软件基因块来保存接下来的指令序列。切分软件基因块示意图如图3所示。遍历所有的汇编程序文件中的节点之后,就完成了软件基因块的切分。
[0050]
具体地,步骤s104中:
[0051]
得到gene数据结构之后,我们还需要对其数据进行进一步的处理。对于每一条指令,都是由操作码和操作数组成,但是在指令中,操作数复杂多样,比如立即数中包含各种各样的整数,寄存器包含各种寄存器如%eax、%ebx、%edx等,内存地址也包含各种寻址方式的表达式等等,为了在训练的过程中消除操作数对模型造成的误差,我们需要对每一条进行规范化,从而保证模型训练的质量,减少不必要信息的干扰。规范化的规则主要如下:寄存器比如%eax,%ebx,%edx等均使用“reg”来代替,立即数均使用“imm”来代替,访问的
内存地址均使用“address”来代替,call指令后面的函数名使用“func”来代替,变量名使用“var”来代替,汇编程序中的标号使用“label”来代替。具体规范化过程如图4所示。
[0052]
具体地,在步骤s104之后,还包括:
[0053]
替换之后,将提取到的数据保存到文件中作为数据集,每一个函数保存为两个文件,一个文件(*.edge)中保存该函数中的所有基本块(节点)以及基本块之间的连接关系,另一个文件(*.node)中保存每一个基本块对应的软件基因块的汇编指令序列。
[0054]
具体地,步骤s105中:
[0055]
首先采用随机游走的方法来得到有序的代码序列(软件基因序列)作为训练集数据,然后采用word2vec对软件基因序列中的汇编指令进行词嵌入。此处借鉴自然语言处理的方法,使用word2vec模型来进行处理。word2vec是一组可以产生词向量的机器学习模型,该模型为浅层双层的神经网络,用来训练词文本来以学习词的语义信息。word2vec模型可以将任意一个词映射到一个指定的固定长度的高维特征向量,它有两种体系结构:连续词袋(bag
‑
of
‑
words,cbow)和skip
‑
gram,在cbow体系结构中,该模型从周围上下词的窗口中预测当前词,并且不会考虑词之间的顺序。在skip
‑
gram体系结构中,模型使用固定大小的窗口,并根据窗口中的上下文单词来预测当前单词。这两种体系结构都能将输入的单词表示为固定长度的特征向量,但是cbow模型存在两个明显的弱点:它会丢失句子中词与词之间的顺序并且会忽略词所包含的语义信息。
[0056]
将汇编指令作为单词,将若干汇编指令组成的基因块作为句子,将若干基因块组成的基因序列作为段落,如果使用cbow模型将会忽略这一重要信息,这是我们所不可忍受的,因此采用skip
‑
gram体系架构来训练词向量。最终需要使得获得的词向量具有这样的特点:即意思相近的词映射到的词向量之间的欧式距离也相近。这样,我们就能在词映射到向量的过程中,尽最大可能保留词的语义信息,从而使得最终得到的向量能够尽可能地包含函数的功能信息,以此在作为比较函数相似度的依据。
[0057]
在训练模型中,首先要做的就是获取词向量,参考自然语言处理(nlp)中的word2vec模型,我们可以以汇编指令中的每一个词为单位获取词向量,如图5所示,也可以以一条完整的汇编指令为单位获取词向量,如图6所示。通过后期实验比较,本实施例以一条完整的汇编指令为单位获取词向量。
[0058]
我们在程序控制流图的基础上采用随机漫步算法,选定图中的任意一个节点,从该节点开始,沿着程序控制流的方向,随机选择一个与给定节点直接相连的节点作为下一个节点,并且不断地重复这一过程,直到达到特定的条件:比如固定的序列长度或者程序结束。为了使得随机节点序列的长度不至于太长,我们采用截断随机游走(truncated random walk),即在随机游走算法中得到的随机节点序列的最长长度为10,如果函数的某一条执行路径的长度超过10,则进行截断,从而将控制流图转化为一系列汇编序列,并作为训练数据。
[0059]
然后采用doc2vec对软件基因序列进行语义嵌入,提取汇编函数的语义信息,得到包含汇编函数语义信息的数学向量,采用计算余弦相似度的方法计算各数学向量间的相似度,实现汇编函数之间的相似度比较。doc2vec是一种无监督的机器学习算法模型,能够将变长的文本(比如一个句子,或者一段文本,甚至一篇文章)映射为一个固定长度的特征向量。它能够从文章中预测单词的训练中获得表示文章的向量,并且大量的研究显示,这样生
成的文章向量(paragraph vector)能够弥补词袋模型等其他文章向量表示技术的缺点。在该模型中,文章向量虽然被随机初始化,但是经过doc2vec模型训练之后,在一定程度上能够表示文本中所包含的语义信息。我们将doc2vec模型应用到汇编序列的语义提取中,因为在该模型内部隐式调用了word2vec模型进行词嵌入,我们无需再额外训练word2vec模型获取词向量。
[0060]
为验证本发明效果,进行如下实验:
[0061]
(a)汇编指令切分方法
[0062]
分别使用前述两种汇编指令切分方法对汇编指令进行训练,得到其相应的特征向量。在训练过程中,我们为了更清晰的观察到训练结果,并比较他们之间的优劣性,我们引入了t
‑
sne。t
‑
sne是一个比较常见的高维数据可视化工具。它可以通过模型训练将高维数据转化为二维或者三维数据,然后将转化后的数据使用matplotplib包进行可视化,从而使得我们可以直观的从图中看到获取的词嵌入向量之间的相似度。如图7和图8所示,分别为两种切分方法得到的向量的效果。
[0063]
从图7中,我们可以看到每一个词对应的点之间的距离比较均匀,即使意思相近的词(比如“jle”,“jl”)和意思差别很大的词(比如“popq”)之间的距离差距并不是很明显,因此这种表示方法并不能很好地反映词的语义信息。
[0064]
从图8中,我们可以明显地看到,指令与指令之间不再是均匀分布,而是呈现出若干个指令聚集在一起,又与其他指令相隔较远。对于图中局部放大我们可以看到,具有相似功能的指令映射到二维空间中的点之间的距离也相近,比如指令“cmovlel reg reg”和指令“cmovbel reg reg”,在语义上意思相近,由word2vec模型训练之后得到的词向量之间的距离也较近,由此我们可以认为这样以一条完整的指令作为词在一定程度上能够表示出指令对应的语义信息。
[0065]
从上面的两个探究实验的结果中我们可以看到,采用两种指令分割方法进行词嵌入得到的结果差别很大,将每一条指令分割开来进行词嵌入的方法得到的词向量分布比较均匀,说明词向量中并没有很好地包含汇编指令的语义信息,而使用一条完整的指令作为一个单词进行词嵌入得到的词向量在二维的分布中指令功能相似的指令分布比较集中,说明这样的词向量较好的包含了程序指令的语义信息。这也在一定程度上说明了我们采用nlp的方式对指令序列进行具有一定的科学性和合理性。
[0066]
(b)词向量的维度
[0067]
在doc2vec模型训练过程中,为了研究词向量的维度对实验结果的影响,我们分别使用词向量维度为25、50、100、150、200时进行实验测试,并使用同一函数的相似性指标作为评判实验结果优劣的依据。同时为了节约时间,降低实验成本,在训练doc2vec模型的过程中,我们随机选择训练数据的一小部分作为实验数据。训练完毕之后,使用训练好的模型进行测试,测试结果如图9所示,图9的横轴表示向量维度,纵轴表示函数向量之间的相似度。
[0068]
从图9可以看出,函数向量之间的相似度随向量维度的变化而变化,并且对于一个函数,存在一个最佳的维度值,使得经过混淆和未经混淆的函数的相似度最高。在本次实验中,可以看到,当词向量的维度为150时,相似函数求得的向量之间的相似度最高,因此我们应当选用150作为词向量的维度来训练doc2vec模型。
[0069]
通过上述实验选择最佳的训练参数来训练doc2vec模型,我们得到了表示每一个节点序列的语义的向量,但在一个函数中,必然存在多个节点序列,那么我们在比较两个函数相似度时,实际上就是在比较若干个向量与另外若干个向量之间的相似度。这时我们就可以有多种选择:一种是将这若干个向量相加并求平均值,另一种就是将这若干个向量直接拼接起来。这两种算法各有优劣,我们需要通过具体的实验数据来比较这两种处理方法的科学性。经过反复的实验发现函数的若干向量直接拼接能够获得更高的准确性,因此在接下来的测试中,我们都直接使用这样的处理方法计算函数的相似度。
[0070]
(c)p@n测试
[0071]
p@n测试的含义:假如a和b是一对相似函数,把b跟99个(或者更多)互不相同的随机挑选的函数放在一起,用这100个函数分别跟a计算相似度,并按照相似度由大到小进行排序,其中b的排序在前n位的概率。在我们的实验中,我们选择的相似函数是同一个函数经过o
‑
llvm编译器的不同混淆选项编译得到的汇编函数。比如a函数是经过三种混淆选项中的任意一种混淆得到的汇编函数,而其余要比较的100个函数是未经过任何混淆选项得到的汇编函数。
[0072]
测试一:在本次测试中,使用的是libtomcrypt的数据集,测试集中的函数均是经过相同的混淆选项(分别为指令替换(sub)、虚假控制流(bcf)、控制流平坦化(fla))编译得到的数据集,且函数量为100个。测试过程中,针对每一个经过混淆的函数,和每一个未经过混淆的函数计算相似度,并将得到的相似度进行排序,分别计算p@1、p@3、p@10,得到的测试结果如表格2所示。
[0073]
表格2libtomcrypt的测试结果
[0074][0075]
测试二:在本次测试中,改用使用libgmp的数据集,测试方法和测试一完全相同,得到的测试结果如表格3所示。
[0076]
表格3libgmp的测试结果
[0077][0078]
从实验结果中可以看到,doc2vec模型针对o
‑
llvm编译器的“sub”混淆选项效果最好,甚至p@10测试中概率非常接近1,说明本发明对混淆选项具有很好的抵抗效果。
[0079]
综上,与从二进制文件逆向到汇编程序不同,本发明采用从正向的角度分析二进制代码,即从源代码编译到汇编程序,二者效果相同,但本发明能显著减少工作量;本发明采用随机游走算法将程序控制流图转换为软件基因序列,可以将控制流图转化成顺序的汇编代码序列,巧妙地绕过了图匹配算法,有效降低了计算复杂度,提高了效率;本发明通过采用自然语言处理的方法对汇编程序进行处理,得到包含汇编程序语义信息的向量,使得能够在抵抗混淆选项的同时,有效地检测二进制代码的相似程度。
[0080]
以上所示仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
