1.本发明属于图像处理技术领域,涉及基于深度学习的图像重建方法,尤其涉及基于深度学习的单张图像的运动估计算法。
背景技术:
2.随着深度学习技术的快速发展,越来越多的领域采用深度学习的方法实现指定任务。传统的图像重建技术受限于重建精度与计算成本,也开始采用深度学习的方法来实现图像重建。基于深度学习的图像重建算法,重建精度更高,计算人工成本也随之降低,尤其在医学图像领域颇受欢迎。另外,随着深度学习的进一步发展,复杂的模型与强大的算力让一系列图像重建算法的应用场景更加广泛,尤其是在图像去模糊,图像超分辨率以及图像增强领域,均取得了巨大的进展。
3.此外,本发明涉及的另一领域是运动估计,传统的运动估计的基本思想是将图像序列的每一帧分成许多互不重叠的块,并认为块内所有象素的位移量都相同,然后对每个块,在参考帧的某一给定搜索范围内,根据一定的匹配准则找出与当前块最相似的块,即匹配块,匹配块与当前块的相对位移即为运动矢量(motion vector,mv)。但是,这种运动估计的算法通常用于视频压缩领域,是为了减少数据冗余,是从视频序列抽取运动信息的一整套技术中的部分技术。因而,使用基于深度学习的图像重建技术实现图像运动估计的方法则是更少。
技术实现要素:
4.针对现有技术中存在的不足,本发明提供一种基于深度学习的单张图片的运动估计系统及方法;
5.现有的基于深度学习方法的图像重建技术,多数用于超分辨率领域,去模糊领域,或者图像增强领域。这类基于端到端的图像重建方法,更偏向于像素点位置处的像素值修正,是一种像素级间的处理方法。本发明提供了一种基于深度学习的单张图片的运动估计系统及方法,该方法基于图片级和像素级对指定的输入图片进行重建,并在重建过程中对图片中部分物体的轮廓进行合理偏移,从而实现对单张图片的运动估计,将深度学习技术引入到运动估计领域中。
6.一种基于深度学习的单张图像的运动估计方法,其步骤包括:
7.步骤(1)、构建数据集;
8.拍摄具有运动状态的物体的视频集,制作相同时间戳的前后两帧的运动图片对,构建数据集。
9.步骤(2)、构建场景信息提取网络,并通过数据集进行训练,用于提取输入图片场景信息s
e
;
10.步骤(3)、构建运动信息估计网络,并通过数据集进行训练,用于提取并估计输入图片运动信息m
e
。
11.步骤(4)、构建信息融合网络,并通过数据集进行训练,用于融合场景信息和运动信息估计结果,得到具有运动估计效果的输出图片。
12.步骤(5)、将需要进行运动估计的真实图片分别输入训练好的场景信息提取网络和运动信息估计网络,得到输入图片的场景信息s
e
和运动信息估计结果m
e
,然后通过训练好的信息融合网络对场景信息s
e
和运动信息估计结果m
e
进行融合,得到具有运动估计效果的输出图片。
13.步骤(1)具体方法如下;
[0014]1‑
1:数据收集,拍摄具有运动状态的物体的视频集。拍摄视频数据时将相机位置固定,确保相机位置和相机参数在拍摄同一段视频时不发生改变,即连续拍摄的一段视频只有画面中运动物体的运动状态改变,无其他变量;
[0015]1‑
2:数据集制作,制作相同时间戳的前后两帧的运动图片对。将拍摄的视频按帧分离,在每段视频中挑选具有明显运动状态改变的物体的连续两帧图片作为一组图片,即每组图片的第一帧图片(i
t
)作为初始图片,第二帧图片(i
t 1
)作为基于第一帧图片产生相对运动的图片。其中数据集中的第一帧图片(i
t
)作为模型训练过程的输入数据,数据集中的具有相对运动的第二帧图片(i
t 1
)作为模型训练过程中的用于与模型输出图片进行对比的对比图片。
[0016]
步骤(2)具体方法如下;
[0017]2‑
1:建立场景信息提取任务的理论模型。场景信息指同一对图片中不发生运动状态改变的内容信息,即第一帧图片(i
t
)和第二帧图片(t 1)具有相同像素分布的内容信息。场景信息提取任务的理论模型用公式表示为:
[0018]
s
e
=ψ(i
t
)
[0019]
其中ψ表示场景信息提取函数,i
t
表示数据集中每组图片的第一帧图片。
[0020]2‑
2:构建场景信息提取网络,用于提取输入图片场景信息。场景信息提取网络由卷积层,最大池化层,正则化层和relu非线性激活函数构成。将数据集中的第一帧图片(i
t
)和第二帧图片(i
t 1
)分别作为输入图片送到场景信息提取网络中,并采用l1损失函数进行监督,实现l1(ψ(i
t
)
‑
ψ(i
t 1
))
→
0,即使得输入的第一帧图片(i
t
)和第二帧图片(i
t 1
)经过场景信息提取网络,得到近似相同的输出结果,即场景信息s
e
。场景信息提取网络经过训练具有提取输入图片场景信息的效果后,保持场景信息提取网络的权重不再发生任何改变。
[0021]
步骤(3)具体方法如下;
[0022]3‑
1:建立运动信息估计任务的理论模型。运动信息指同一对图片中发生运动状态改变的内容信息,即第一帧图片(i
t
)和第二帧图片(i
t 1
)具有不同像素分布的运动目标信息。运动信息估计任务是根据给定的第一帧图片(i
t
),能够对图片的运动目标信息进行检测并重新估计目标的像素分布,产生运动目标状态改变的效果。运动信息估计任务的理论模型用公式表示为:
[0023]
m
e
=γ(i
t
)
[0024]
其中γ表示运动信息估计函数,i
t
表示数据集中每组图片的第一帧图片。
[0025]3‑
2:构建运动信息估计网络,用于提取并估计输入图片运动信息。运动信息估计网络由卷积层,最大池化层,正则化层和relu非线性激活函数构成。将数据集中的第一帧图片(i
t
)作为输入图片送到运动信息估计网络中,得到输入图片(i
t
)的运动信息估计结果m
e
。
[0026]
步骤(4)具体方法如下;
[0027]4‑
1:建立信息融合网络的理论模型。信息融合网络用于融合场景信息提取网络的输出场景信息s
e
和运动信息估计网络的输出运动信息估计结果m
e
,信息融合的理论模型用公式表示为:
[0028]
out=θ(s
e
,m
e
)
[0029]
其中s
e
为场景信息提取网络的输出场景信息,m
e
为运动信息估计网络的输出运动信息估计结果,θ为信息融合函数。
[0030]4‑
2:构建信息融合网络,用于融合场景信息和运动信息估计结果,得到具有运动估计效果的输出图片。信息融合网络由卷积层,正则化层和relu非线性激活函数构成。将场景信息提取网络的输出场景信息s
e
和运动信息估计网络的输出运动信息估计结果m
e
在通道维度上进行拼接,作为信息融合网络的输入,数据集中的具有相对运动的第二帧图片(i
t 1
)作为信息融合网络训练过程中的用于与输出图片进行对比的真实图片。信息融合网络采用l1损失函数进行监督,实现l1(out
‑
(i
t 1
))
→
0,即使得信息融合网络输出图片(i
out
)和第二帧图片(i
t 1
)具有近似相同的输出结果。
[0031]
一种基于深度学习的单张图像的运动估计系统,包括场景信息提取模块、运动信息估计模块和信息融合模块:
[0032]
所述的场景信息提取模块采用场景信息提取网络提取输入图片场景信息,所述的场景信息提取网络由卷积层,最大池化层,正则化层和relu非线性激活函数构成。场景信息提取网络经过训练具有提取输入图片场景信息的效果后,保持场景信息提取网络的权重不再发生任何改变。
[0033]
所述的运动信息估计模块采用运动信息估计网络提取并估计输入图片运动信息,所述的运动信息估计网络由卷积层,最大池化层,正则化层和relu非线性激活函数构成。
[0034]
所述的信息融合模块采用信息融合网络融合场景信息和运动信息估计结果,得到具有运动估计效果的输出图片。所述的信息融合网络由卷积层,正则化层和relu非线性激活函数构成。
[0035]
本发明有益效果如下:
[0036]
优点1:创新的提出了基于深度学习的单张图像的运动估计算法,该算法实现了对图像内容的运动估计及图像重建。
[0037]
优点2:创新的提出了基于深度学习的单张图像的运动估计系统,包括场景信息提取模块,运动信息提取模块,图像生成模块。
[0038]
优点3:创新的将基于深度学习的图像重建技术应用到了图片运动估计的新领域,运动估计的输出不再作为视频压缩技术的中间输出。
附图说明
[0039]
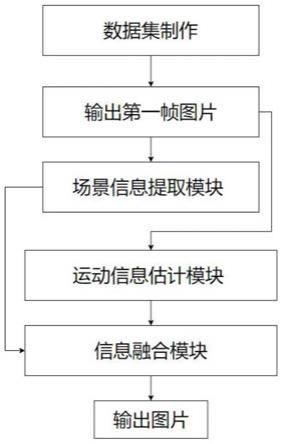
图1为本发明实施例图像运动估计流程图;
[0040]
图2为本发明实施例图像运动估计算法;
[0041]
图3为本发明实施例运动估计系统结构示意图。
具体实施方式
[0042]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0043]
本发明首先进行以下定义及说明:
[0044]
符号i
t
:同一对图片中的第一帧的图片。
[0045]
符号i
t 1
:同一对图片中的第二帧的图片。
[0046]
符号s
e
:输入数据经过场景信息提取网络得到的输出特征图。
[0047]
符号m
e
:输入数据经过运动信息估计网络得到的输出特征图。
[0048]
符号i
out
:输入数据经过信息融合网络得到的输出图片。
[0049]
一种基于深度学习的单张图像的运动估计方法,其步骤如图1所示,包括:
[0050]
步骤(1)、数据预处理;
[0051]1‑
1:数据收集,拍摄具有运动状态的物体的视频集。拍摄视频数据时将相机位置固定,确保相机位置和相机参数在拍摄同一段视频时不发生改变,即连续拍摄的一段视频只有画面中运动物体的运动状态改变,无其他变量;
[0052]1‑
2:数据集制作,制作相同时间戳的前后两帧的运动图片对。将拍摄的视频按帧分离,在每段视频中挑选具有明显运动状态改变的物体的连续两帧图片作为一组图片,即每组图片的第一帧图片(i
t
)作为初始图片,第二帧图片(i
t 1
)作为基于第一帧图片产生相对运动的图片。其中数据集中的第一帧图片(i
t
)作为模型训练过程的输入数据,数据集中的具有相对运动的第二帧图片(i
t 1
)作为模型训练过程中的用于与模型输出图片进行对比的对比图片。
[0053]
步骤(2)、场景信息提取网络构建;
[0054]2‑
1:建立场景信息提取任务的理论模型。场景信息指同一对图片中不发生运动状态改变的内容信息,即第一帧图片(i
t
)和第二帧图片(t 1)具有相同像素分布的内容信息。场景信息提取任务的理论模型用公式表示为:
[0055]
s
e
=ψ(i
t
)
[0056]
其中ψ表示场景信息提取函数,i
t
表示数据集中每组图片的第一帧图片。
[0057]2‑
2:构建场景信息提取网络,用于提取输入图片场景信息。场景信息提取网络由卷积层,最大池化层,正则化层和relu非线性激活函数构成。将数据集中的第一帧图片(i
t
)和第二帧图片(i
t 1
)分别作为输入图片送到场景信息提取网络中,并采用l1损失函数进行监督,实现l1(ψ(i
t
)
‑
ψ(i
t 1
))
→
0,即使得输入的第一帧图片(i
t
)和第二帧图片(i
t 1
)经过场景信息提取网络,得到近似相同的输出结果,即场景信息s
e
。场景信息提取网络经过训练具有提取输入图片场景信息的效果后,保持场景信息提取网络的权重不再发生任何改变。
[0058]
步骤(3)、运动信息估计网络构建;
[0059]3‑
1:建立运动信息估计任务的理论模型。运动信息指同一对图片中发生运动状态改变的内容信息,即第一帧图片(i
t
)和第二帧图片(i
t 1
)具有不同像素分布的运动目标信息。运动信息估计任务是根据给定的第一帧图片(i
t
),能够对图片的运动目标信息进行检测并重新估计目标的像素分布,产生运动目标状态改变的效果。运动信息估计任务的理论模型用公式表示为:
[0060]
m
e
=γ(i
t
)
[0061]
其中γ表示运动信息估计函数,i
t
表示数据集中每组图片的第一帧图片。
[0062]3‑
2:构建运动信息估计网络,用于提取并估计输入图片运动信息。运动信息估计网络由卷积层,最大池化层,正则化层和relu非线性激活函数构成。将数据集中的第一帧图片(i
t
)作为输入图片送到运动信息估计网络中,得到输入图片(i
t
)的运动信息估计结果m
e
。
[0063]
步骤(4)、信息融合网络构建;
[0064]4‑
1:建立信息融合网络的理论模型。信息融合网络用于融合场景信息提取网络的输出场景信息s
e
和运动信息估计网络的输出运动信息估计结果m
e
,信息融合的理论模型用公式表示为:
[0065]
out=θ(s
e
,m
e
)
[0066]
其中s
e
为场景信息提取网络的输出场景信息,m
e
为运动信息估计网络的输出运动信息估计结果,θ为信息融合函数。
[0067]4‑
2:构建信息融合网络,用于融合场景信息和运动信息估计结果,得到具有运动估计效果的输出图片。信息融合网络由卷积层,正则化层和relu非线性激活函数构成。将场景信息提取网络(经过步骤2
‑
2,场景信息提取网络的权重固定不变)的输出场景信息s
e
和运动信息估计网络的输出运动信息估计结果m
e
在通道维度上进行拼接,作为信息融合网络的输入,数据集中的具有相对运动的第二帧图片(i
t 1
)作为信息融合网络训练过程中的用于与输出图片进行对比的真实图片。信息融合网络采用l1损失函数进行监督,实现l1(out
‑
(i
t 1
))
→
0,即使得信息融合网络输出图片(i
out
)和第二帧图片(i
t 1
)具有近似相同的输出结果。
[0068]
步骤(5)、将需要进行运动估计的真实图片分别输入训练好的场景信息提取网络和运动信息估计网络,得到输入图片的场景信息s
e
和运动信息估计结果m
e
,然后通过训练好的信息融合网络对场景信息s
e
和运动信息估计结果m
e
进行融合,得到具有运动估计效果的输出图片。
[0069]
图2为本发明实施例图像运动估计算法;
[0070]
如图3所示,一种基于深度学习的单张图像的运动估计系统,包括场景信息提取模块、运动信息估计模块和信息融合模块:
[0071]
所述的场景信息提取模块采用场景信息提取网络提取输入图片场景信息,所述的场景信息提取网络由卷积层,最大池化层,正则化层和relu非线性激活函数构成。场景信息提取网络经过训练具有提取输入图片场景信息的效果后,保持场景信息提取网络的权重不再发生任何改变。
[0072]
场景信息提取网络由卷积层,最大池化层,正则化层和relu非线性激活函数构成,一共分成3个部分:第一部分包含1个卷积核数量为64的步幅为2*2的7*7的卷积层核一个正则化层;第二部分包含1个步幅为2*2的最大池化层;第三部分包含3个结构参数相同的自定义模块,每个自定义模块内包含一个卷积核数量为64的1*1的卷积层,一个卷积核数量为64的3*3的卷积层,一个卷积核数量为256的1*1的卷积层。每个卷积层后面都接了一个relu非线性激活函数和正则化层;经过场景信息提取网路,图像尺寸h*w变成了(h/4)*(w/4)。
[0073]
所述的运动信息估计模块采用运动信息估计网络提取并估计输入图片运动信息,所述的运动信息估计网络由卷积层,最大池化层,正则化层和relu非线性激活函数构成。
[0074]
运动信息估计网络由卷积层,最大池化层,正则化层,转置卷积层和relu非线性激活函数构成,一共分成2部分:第一部分包含四个双卷积模块,每个双卷积模块包含两个参数相同的卷积层和两个正则化层,四个双卷积模块的参数分别为滤波核尺寸均为3*3,滤波核数量为64,128,256,512,每个双卷积模块后都连接一个步幅为2*2的最大池化层;第二部分包含两个双卷积模块,参数分别为滤波核尺寸均为3*3,滤波核数量为512,256,每个双卷积模块后面都连接一个与双卷积模块具有相同参数的转置卷积层和正则化层。运动信息估计网络采用的卷积层后面都接了一个relu非线性激活函数。经过场景信息提取网路,图像尺寸h*w变成了(h/4)*(w/4)。
[0075]
所述的信息融合模块采用信息融合网络融合场景信息和运动信息估计结果,得到具有运动估计效果的输出图片。所述的信息融合网络由卷积层,正则化层和relu非线性激活函数构成。
[0076]
信息融合网络由卷积层,最大池化层,正则化层,转置卷积层和relu非线性激活函数构成,一共分成2部分:第一部分包含两个双卷积模块,参数分别为滤波核尺寸均为3*3,滤波核数量为256,128,每个双卷积模块后面都连接一个与双卷积模块具有相同参数的转置卷积层和正则化层。第二部分包含两个双卷积模块,参数分别为滤波核尺寸均为3*3,滤波核数量为64,3。运动信息估计网络采用的卷积层后面都接了一个relu非线性激活函数。经过信息融合网路,图像尺寸(h/4)*(w/4)变成了h*w。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
