1.本发明涉及人工智能系统,特别是涉及当出现短文本多轮人机对话的生成式对话系统。
背景技术:
2.随着人类社会信息化的不断演进以及人工服务成本的不断上升,人们越来越希望通过自然语言与计算机进行交流,智能对话机器人系统成为这样的历史背景下诞生的产物,尤其是能够像人一样理解话语,能够像人一样在即使有个别错字、语序颠倒等不影响句意理解的情况下,依旧能做出恰当回复,正成为各大公司及学术研究机构研发的方向和重点。
3.目前已有的智能对话系统的研究中,随着模型的性能、参数增强,语料库也越来越标准,模型在训练过程中拟合能力越来越强,但是泛化能力却没有得到提升。
4.对抗训练有两个作用,一是提高模型对恶意攻击的鲁棒性,二是提高模型的泛化能力。对抗训练最初用在图像领域中,其基本方法是通过选取训练数据潜在空间中的元素进行组合,并加入随机噪声作为虚假数据,在训练过程中,将真实数据和虚假数据送入到分类器中,最终使分类器无法区分输入数据是否为真实数据;在计算机视觉任务中,输入是连续的rgb的值,而在自然语言处理任务中,输入是离散的单词序列,一般以one
‑
hot向量的形式呈现,如果直接在输入的文本上进行扰动,那么扰动的值和方向可能都没有意义,因此提出了可以在连续的embedding上做扰动的方法,但是与图像领域中直接在原始输入加扰动不同,在字或词嵌入向量上加扰动会带来这一问题:被构造出来的“对抗样本”并不能映射到某个单词上。因此,在词表中推理或查询字或词时,无法通过修改原始输入数据得到“对抗样本”;根据前人大量的实验工作显示,在自然语言处理任务中,对抗训练在非对抗样本上的表现更好,使模型的泛化能力变强,与视觉任务相反;在自然语言处理任务中,对抗训练的目的不再是为了防御基于梯度的恶意攻击,而是作为一种正则化方式来提高模型的泛化能力。
5.本发明针对此缺陷提出,利用对抗训练的方法解决人机对话系统泛化能力差的问题。
技术实现要素:
6.一种融合对抗训练的生成式对话系统,其特征在于使用基于深度学习的gpt的端到端方式,研究针对提高泛化能力的人机智能对话系统,在即使有个别错字、语序颠倒等不影响句意理解的情况下,依旧能做出恰当回复。
7.本发明提供的技术方案包括如下步骤:在编码部分,直接用hugging face提供的transformers的berttokenizer对历史对话和当前对话编码;解码部分使用的是中文gpt模型,首先将编码后的向量输入到解码部分,进行解码生成回复语句的第一个字,之后将编码后的向量和解码生成的字向量输入到解码部分中,直到生成最后一个字符;中文gpt模型在
训练过程中,使用对抗训练中的投影梯度下降法进行训练,损失函数使用facal损失函数。
附图说明
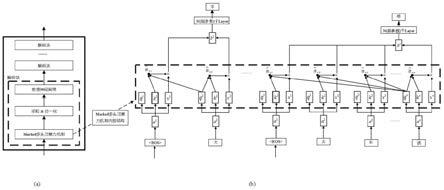
8.图1对话系统的模型架构图。
9.图2对话系统的模型内部结构图。
10.图3对话系统的模型详解图。
具体实施方式
10.第一步利用berttokenizer将当前话语与历史对话进行编码;第二步将编码后的向量输入到中文gpt模型中,利用掩码多头注意力机制生成回复语句;第三步在训练过程中利用对抗训练中的投影梯度下降法进行训练,损失函数为facal损失函数。
11.将多轮对话构建成长文本,并将生成回复话语任务构建为语言模型。首先将多轮对话中的所有对话连接成一个长文本x1,
…
,x
n
(n是序列长度),以[sep]标记文本结尾;将源语句(历史对话)表示为s=x1,
…
,x
m
,目标语句(语料库中真实回复语句即标写为一系列条件概率的乘积为公式1所示;对于多轮对话t1,
…
,t
k
,公式(1)的p(t|s)改成公式(2),因此只对p(t
k
,
…
,t2|t1)进行优化即可,)进行优化即可,
[0012]
在模型训练完之后,得到模型的构造和参数以及训练过程在编码和解码部分。
[0013]
编码部分:直接用hugging face提供的transformers的berttokenizer对历史对话和当前对话编码。
[0014]
解码部分:为中文gpt对话模型,将编码后的文本向量连续化并输入到模型中,gpt生成文本是根据用户特定的提示或无提示随机的方式生成的;在gpt体系结构的基础上训练了gpt对话模型,由12到48层的transformer解码层构成,每层只有掩码多头自注意力机制(masked self
‑
attention)和归一化功能;自注意力机制为公式3,公式4,其中q为查询向量,k为键向量,v为值向量,w
iq
,w
ik
,w
iv
是降维矩阵,比如q,k,v的维度是768,注意力头数是12,那么是字嵌入向量的维度是(768,768/12)即(768,64),d
k
是q和k的维度。考虑了修改模型初始化的深度以及对字而不是词编码。型初始化的深度以及对字而不是词编码。
[0015]
对抗训练:对输入向量添加噪声,如公式5,公式6所示。θ为模型对应的参数,l为损失函数,s为扰动的范围,超参数α为步长。x
t 1
=∏
x s
(x
t
αg(x
t
)/||g(x
t
)||2)
ꢀꢀꢀ
(5)g(x
t
)=
▽
x
l(θ,x
t
,y)
ꢀꢀꢀ
(6)
[0016]
为实现上述目的,本文提出的方案是:一种基于投影梯度下降训的对抗训练算法,具体步骤如下:s1:将离散向量变成连续向量;s2:计算loss值;s3:定义循环次数k;s4:反向传播,得到正常的grad;s5:在字嵌入向量上添加对抗扰动,第一次添加对抗扰动时备份模型参数;s6:循环轮数不等于k
‑
1时,清空梯度,否则保留梯度;s7:计算加入扰动后的loss值;s8:结束循环;s9:在添加扰动前的梯度基础上反向传播,累加对抗训练的梯度;s10:恢复字嵌入向量参数;s11:梯度下降,更新参数;
[0017]
为了提高生僻字的预测能力,进而加快训练速度,采用facal损失函数,其公式为:facal_loss=(1
‑
p(t|s))^g
×
loss
ꢀꢀꢀ
(6)其中,超参数g是调节简单样本权重降低速率的因子,loss为交叉熵损失函数,其公式为:例如某一个常用字和生僻字的概率分别为0.9和0.1,g=2,生僻字的facal损失值是原有损失值的0.81倍,而常用字的facal损失值是原有损失值的0.01倍,使生僻字的facal损失值的占比相对提升,梯度更能沿着生僻字的方向下降。
技术特征:
1.一种基于短文本多轮的生成式对话系统,其特征在于使用基于深度学习的gpt的端到端方式,研究针对提高泛化能力的人机智能对话系统,其包括如下:使用投影梯度下降的对抗训练算法来实现在有噪声但不改变语句意思输入的情况下,中文gpt对话模型依旧能给出合理答复,不会产生乱码;最后使用facal损失函数提高生僻字预测能力,加快训练速度。2.根据权利要求1所述一种基于投影梯度下降训的对抗训练算法,在微调过程中训练中文gpt对话模型,训练过程中,训练算法的输入是中文gpt对话模型。3.根据权利要求1所述一种基于投影梯度下降训的对抗训练算法,包含三个部分,第一部分是对输入的字嵌入向量加入对抗扰动,第二部分是恢复字嵌入向量,第三部分恢复梯度;输入x
t
添加对抗扰动后为:x
t 1
=∏
x λ
(x
t
αg(x
t
)/||g(x
t
)||2)其中,扰动半径为ε,α为扰动空间上的步长,λ=r∈r
d
:||r||2≤ε,g(x
t
)为损失函数l的梯度,即:其中θ为y与x
t
之间映射关系的参数,例如:y=θ
·
x
t
,将中文gpt对话训练模型的输入(源语句和历史对话)表示为s=x1,
···
,x
m
,输出的目标语句t(语料库中真实回复语句即标签)为条件概率的乘积:对于多轮对话,p(t|s)可以改成:4.根据权利要求1中为了提高生僻字的预测能力,进而加快训练速度,采用facal损失函数,其公式为:facal_loss=(1
‑
p(t|s))^g
×
loss其中,超参数g是调节简单样本权重降低速率的因子,loss为交叉熵损失函数,其公式为:例如某一个常用字和生僻字的概率分别为0.9和0.1,g=2,生僻字的facal损失值是原有损失值的0.81倍,而常用字的facal损失值是原有损失值的0.01倍,使生僻字的facal损失值的占比相对提升,梯度更能沿着生僻字的方向下降。
技术总结
神经网络对话生成模型的发展促进了短文本对话建模的研究。对经过清洗的大规模高质量中文会话数据集(large
技术研发人员:王伟 阮文翰 武聪 吕明海
受保护的技术使用者:辽宁工程技术大学
技术研发日:2021.07.13
技术公布日:2021/10/23
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
