1.本发明涉及一种建立审计专业词库的方法,属于自然语言处理领域。
背景技术:
2.领域词语的抽取算法大致分为以下三类:
3.(1)基于规则的抽取方法:根据词语的自身组成结构和词语外部上下文联系等建立相应的规则,并利用模式匹配来抽取领域词汇。
4.(2)基于统计学方法:赖于词频度、似然比、假设检验和互信息等,对单独的领域词汇和低频领域词汇的识别效果并不是很理想。
5.(3)基于统计和规则结合的方法:鉴于两种方法的不足,融合两种方法的优点进行抽取算法的。这种方法可以分为以下三类:规则作为统计方法中的一个过滤步骤;在统计方法中融入具体的规则;利用上下文的“规则”信息进行统计。许多统计算法都是使用组建一个过滤规则模板来过滤掉不合格的术语组合,而且实践证明这种方式是简单可行的。
6.目前,没有面向审计领域的较为通用且全面的审计专业词库。
技术实现要素:
7.为了解决上述现有技术中存在的问题,本发明提供一种,本发明的技术方案如下:
8.技术方案一:
9.一种建立审计专业词库的方法,包括如下步骤:
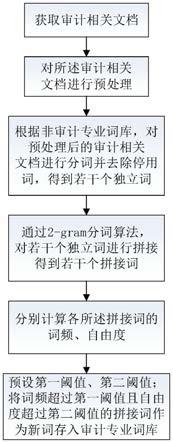
10.s1、获取审计相关文档;
11.s2、对所述审计相关文档进行预处理;
12.s3、根据非审计专业词库,对预处理后的审计相关文档进行分词并去除停用词,得到若干个独立词;
13.s4、通过2
‑
gram分词算法,对若干个独立词进行拼接,得到若干个拼接词;
14.s5、分别计算各所述拼接词的词频、自由度;
15.s6、预设第一阈值、第二阈值;将词频超过第一阈值且自由度超过第二阈值的拼接词作为新词存入审计专业词库。
16.进一步的,步骤s6还包括,通过人工进一步审核新词;将通过审核的新词存入审计专业词库。
17.进一步的,步骤s6还包括,将词频不超过第一阈值或自由度不超过第二阈值的拼接词作为停用词存入非审计专业词库。
18.进一步的,所述预处理具体为:使用poi工具或tika工具,将非结构化文档转换为结构化文档。
19.进一步的,步骤s5中,计算拼接词的自由度的具体步骤为:
20.预设第三阈值;计算所述拼接词内部的互信息;
21.计算互信息大于第三阈值的拼接词的自由度:
22.预设第四阈值;
23.计算互信息大于第三阈值的拼接词的左邻居信息熵,若所述左邻居信息熵不超过第四阈值,则继续向左扩展计算下一左邻居信息熵,直至达到最左边界处或一左邻居信息熵超过第四阈值,记该超过第四阈值的左邻居信息熵为第一标度值;
24.计算所有含有第一标度值的拼接词的右邻居信息熵,若所述右邻居信息熵不超过第四阈值,则继续向右扩展计算下一右邻居信息熵;直至达到最右边界处或右邻居信息熵超过第四阈值,记该超过第四阈值的右邻居信息熵为第二标度值;
25.取第一标度值、第二标度值中的较小者为对应拼接词的自由度。
26.技术方案二:
27.一种建立审计专业词库的方法,包括存储器和处理器,所述存储器存储有指令,所述指令适于由处理器加载并执行以下步骤:
28.s1、获取审计相关文档;
29.s2、对所述审计相关文档进行预处理;
30.s3、根据非审计专业词库,对预处理后的审计相关文档进行分词并去除停用词,得到若干个独立词;
31.s4、通过2
‑
gram分词算法,对若干个独立词进行拼接,得到若干个拼接词;
32.s5、分别计算各所述拼接词的词频、自由度;
33.s6、预设第一阈值、第二阈值;将词频超过第一阈值且自由度超过第二阈值的拼接词作为新词存入审计专业词库。
34.进一步的,步骤s6还包括,通过人工进一步审核新词;将通过审核的新词存入审计专业词库。
35.进一步的,步骤s6还包括,将词频不超过第一阈值或自由度不超过第二阈值的拼接词作为停用词存入非审计专业词库。
36.进一步的,所述预处理具体为:使用poi工具或tika工具,将非结构化文档转换为结构化文档。
37.进一步的,步骤s5中,计算拼接词的自由度的具体步骤为:
38.预设第三阈值;计算所述拼接词内部的互信息;
39.计算互信息大于第三阈值的拼接词的自由度:
40.预设第四阈值;
41.计算互信息大于第三阈值的拼接词的左邻居信息熵,若所述左邻居信息熵不超过第四阈值,则继续向左扩展计算下一左邻居信息熵,直至达到最左边界处或一左邻居信息熵超过第四阈值,记该超过第四阈值的左邻居信息熵为第一标度值;
42.计算所有含有第一标度值的拼接词的右邻居信息熵,若所述右邻居信息熵不超过第四阈值,则继续向右扩展计算下一右邻居信息熵;直至达到最右边界处或右邻居信息熵超过第四阈值,记该超过第四阈值的右邻居信息熵为第二标度值;
43.取第一标度值、第二标度值中的较小者为对应拼接词的自由度。
44.本发明具有如下有益效果:
45.1、本发明应用2
‑
gram技术,实现分词碎片的词拼接,在经过对拼接词的词频统计、自由度计算,实现文本数据内的领域新词发现。
46.2、本发明仅需要人工对少量新词进行筛选,在很大程度上减轻纯人工从文档内提取审计领域专业词汇的工作量,提高审计专业词库构建效率。
47.3、本发明在开始时利用现有的非审计专业词库进行停用词过滤,而在处理一定数量的文档后,能收集到大量的非新词(即词频不超过第一阈值或自由度不超过第二阈值的拼接词)。将非新词存入非审计专业词库进行过滤,能大幅度的降低后续的计算量,从而高效地发现新词。
附图说明
48.图1为本发明的流程图。
具体实施方式
49.下面结合附图和具体实施例来对本发明进行详细的说明。
50.实施例一
51.一种建立审计专业词库的方法,包括如下步骤:
52.s1、获取审计相关文档,包括审计记录、审计底稿、审计报告、审计整改报告等。
53.s2、对所述审计相关文档进行预处理;
54.s3、根据非审计专业词库(jieba词库工具),对预处理后的审计相关文档进行分词并去除停用词,得到若干个独立词;
55.s4、通过2
‑
gram分词算法,对若干个独立词进行拼接,得到若干个拼接词。举例说明:分词得到“任”“中”“审计”,经2
‑
gram分词算法,得到拼接词“任中”“中审计”“任中审计”。
56.s5、分别计算各所述拼接词的词频、自由度。其中,词频=拼接词在文档中出现的总次数/文档的总词数。
57.s6、预设第一阈值、第二阈值(在本实施例中,第一阈值为、第二阈值为);将词频超过第一阈值且自由度超过第二阈值的拼接词作为新词存入审计专业词库。
58.本实施例的有益效果在于,应用2
‑
gram技术,实现分词碎片的词拼接,在经过对拼接词的词频统计、自由度计算,实现文本数据内的领域新词发现。
59.实施例二
60.进一步的,步骤s6还包括,通过人工进一步审核新词;将通过审核的新词存入审计专业词库。
61.本实施例的进步之处在于,仅需要人工对少量新词进行筛选,在很大程度上减轻纯人工从文档内提取审计领域专业词汇的工作量,提高审计专业词库构建效率。
62.实施例三
63.进一步的,步骤s6还包括,将词频不超过第一阈值或自由度不超过第二阈值的拼接词作为停用词存入非审计专业词库。
64.本实施例的进步之处在于,在开始时利用现有的非审计专业词库进行停用词过滤,而在处理一定数量的文档后,能收集到大量的非新词(即词频不超过第一阈值或自由度不超过第二阈值的拼接词)。将非新词存入非审计专业词库进行过滤,能大幅度的降低后续的计算量,从而高效地发现新词。
65.实施例四
66.进一步的,预设第三阈值(在本实施例中,第三阈值为);计算所述拼接词内部的互信息;
67.计算大于第三阈值的拼接词的自由度:
68.预设第四阈值(在本实施例中,第四阈值为);
69.计算互信息大于第三阈值的拼接词的左邻居信息熵,若所述左邻居信息熵不超过第四阈值,则继续向左扩展计算下一左邻居信息熵,直至达到最左边界处或一左邻居信息熵超过第四阈值,记该超过第四阈值的左邻居信息熵为第一标度值;
70.计算所有含有第一标度值的拼接词的右邻居信息熵,若所述右邻居信息熵不超过第四阈值,则继续向右扩展计算下一右邻居信息熵;直至达到最右边界处或右邻居信息熵超过第四阈值,记该超过第四阈值的右邻居信息熵为第二标度值;
71.取第一标度值、第二标度值中的较小者为对应拼接词的自由度。
72.实施例五
73.一种审计专业词库建立设备,包括存储器和处理器,所述存储器存储有指令,所述指令适于由处理器加载并执行以下步骤:
74.s1、获取审计相关文档,包括审计记录、审计底稿、审计报告、审计整改报告等。
75.s2、对所述审计相关文档进行预处理;
76.s3、根据非审计专业词库(jieba词库工具),对预处理后的审计相关文档进行分词并去除停用词,得到若干个独立词;
77.s4、通过2
‑
gram分词算法,对若干个独立词进行拼接,得到若干个拼接词。举例说明:分词得到“任”“中”“审计”,经2
‑
gram分词算法,得到拼接词“任中”“中审计”“任中审计”。
78.s5、分别计算各所述拼接词的词频、自由度。其中,词频=拼接词在文档中出现的总次数/文档的总词数。
79.s6、预设第一阈值、第二阈值(在本实施例中,第一阈值为、第二阈值为);将词频超过第一阈值且自由度超过第二阈值的拼接词作为新词存入审计专业词库。
80.本实施例的有益效果在于,应用2
‑
gram技术,实现分词碎片的词拼接,在经过对拼接词的词频统计、自由度计算,实现文本数据内的领域新词发现。
81.实施例六
82.进一步的,步骤s6还包括,通过人工进一步审核新词;将通过审核的新词存入审计专业词库。
83.本实施例的进步之处在于,仅需要人工对少量新词进行筛选,在很大程度上减轻纯人工从文档内提取审计领域专业词汇的工作量,提高审计专业词库构建效率。
84.实施例七
85.进一步的,步骤s6还包括,将词频不超过第一阈值或自由度不超过第二阈值的拼接词作为停用词存入非审计专业词库。
86.本实施例的进步之处在于,在开始时利用现有的非审计专业词库进行停用词过滤,而在处理一定数量的文档后,能收集到大量的非新词(即词频不超过第一阈值或自由度不超过第二阈值的拼接词)。将非新词存入非审计专业词库进行过滤,能大幅度的降低后续
的计算量,从而高效地发现新词。
87.实施例八
88.进一步的,预设第三阈值(在本实施例中,第三阈值为);计算所述拼接词内部的互信息;
89.计算大于第三阈值的拼接词的自由度:
90.预设第四阈值(在本实施例中,第四阈值为);
91.计算互信息大于第三阈值的拼接词的左邻居信息熵,若所述左邻居信息熵不超过第四阈值,则继续向左扩展计算下一左邻居信息熵,直至达到最左边界处或一左邻居信息熵超过第四阈值,记该超过第四阈值的左邻居信息熵为第一标度值;
92.计算所有含有第一标度值的拼接词的右邻居信息熵,若所述右邻居信息熵不超过第四阈值,则继续向右扩展计算下一右邻居信息熵;直至达到最右边界处或右邻居信息熵超过第四阈值,记该超过第四阈值的右邻居信息熵为第二标度值;
93.取第一标度值、第二标度值中的较小者为对应拼接词的自由度。
94.以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
