1.本发明属于计算机视觉领域,主要涉及场景三维重建及理解,将物体表示为各个组成部分的集合,例如,椅子由腿和座位及椅背组成,应用一个图结构来表示这个物体,以达到更为精细的场景理解,并有助于后续的交互工作。
背景技术:
2.三维重建是指对三维物体建立适合计算机表示和处理的数学模型,是在计算机环境下对其进行处理、操作和分析其性质的基础,也是在计算机中建立表达客观世界的虚拟现实的关键技术。
3.在计算机视觉中,三维重建是指根据单视图或者多视图的图像重建三维信息的过程.由于单视频的信息不完全,因此三维重建需要利用经验知识.而多视图的三维重建(类似人的双目定位)相对比较容易,其方法是先对摄像机进行标定,即计算出摄像机的图象坐标系与世界坐标系的关系.然后利用多个二维图象中的信息重建出三维信息。
4.近年来,消费级rgb
‑
d传感器的广泛使用,如微软kinect、英特尔real sense以及谷歌探戈使得rgb
‑
d重建取得了显著进展。在取得了较好的重建效果后,下一步的工作就是对重建好的场景进行理解,包括语义分割,实例分割等。最近,在rgb
‑
d扫描环境的大规模数据收集和3d重建标注工作的推动下,结合对诸如稀疏或密集体积网格(体素),点云,mesh等3d表示的3d深度学习方法的探索,3d语义分割和3d实例分割都取得了重大进展。这些都为物体层面的3d感知提供了基础,这对于语义理解至关重要,但缺乏对实现与物体的交互和功能推理至关重要的更精细的理解(例如,椅子的座位部分是用来坐着的,旋钮或手柄可以打开门或抽屉)。能够将物体解析成part组成对于人类理解世界和与世界互动至关重要。人们根据对物体各部分的了解来识别、分类和组织物体。人们在现实世界中采取的许多行动都需要检测零件并对零件进行推理。例如,用门把手开门,抓住把手拉出抽屉。因此,教机器分析出物体的part组成部分对于许多视觉、图形和机器人应用来说是必不可少的。同时,在物体的part分割方面已经取得了显著的进展。然而,这些方法是在合成数据集上开发的,如shapenet,物体是孤立的且完整的,不会受到周边因素的干扰及重建效果的限制,因此,这种情况比在现实环境中观察到的物体要简单得多。在真实世界3d环境中,重建场景通常是杂乱的和几何上不完整的(例如,由于遮挡、传感器限制导致的重建效果噪声等)。这严重限制了三维重建领域的上层要求,三位场景理解的性能,当今学界急需一种能够解决或跳过上述问题完成更高层次的理解甚至于交互的方法。
5.目前研究学界还没有合适的方法能够完美解决基于真实三维重建场景的part级分割理解问题的方法。
6.relu:relu函数其实是分段线性函数,把所有的负值都变为0,而正值不变,这种操作被成为单侧抑制。有了这种单侧抑制,神经网络中的神经元也具有了稀疏激活性。尤其体现在深度神经网络模型(如cnn)中,当训练一个深度分类模型的时候,和目标相关的特征往往并不多,因此通过relu实现稀疏后的模型能够更好地挖掘相关特征,拟合训练数据。
7.体素:体素是体积元素(volume pixel)的简称,包含体素的立体可以通过立体渲染或者提取给定阈值轮廓的多边形等值面表现出来。相当于rgb图中的像素,可将二维图像中的预测热图方法以同样的原理迁移到三维空间中,完成两个三维物体的匹配。
8.one
‑
hot:one
‑
hot向量将类别变量转换为机器学习算法易于利用的一种形式的过程,这个向量的表示为一项属性的特征向量,也就是同一时间只有一个激活点(不为0),这个向量只有一个特征是不为0的,其他都是0,非常稀疏。好处是不同特征表示会有很好的区分。
技术实现要素:
9.传感器在获取扫描数据时,往往会受到噪声,以及传感器自身运动所带来的模糊等影响,导致得到的场景3d扫描会出现噪声,缺失等现象,这种情况不仅会导致重建效果变差,更会对更高一级的场景理解及交互造成不小的困扰,因为机器人对于场景的交互需要考虑到场景物体的功能空间,而物体的功能空间几乎都是part级别的(例如门把手,椅子座位等等)。
10.因此,本发明提出一种组件级别的三维场景理解方法,从场景的rgb
‑
d扫描中,检测出由3dbounding box和类别标签表征的物体,并且对于每个物体,基于训练集中物体part部分的掩模来构造part先验,并学习到一个树形图来表示其结构组成,每一个节点代表一个组成部分(part),边代表part之间的关系(是否相邻),有了这样一个学习到的完整的物体结构组成部分作为先验,就可以对实际场景中物体缺失和未观察到的part进行可靠的预测(例如,对于具有未观察到的一条腿的四条腿的桌子,基于通常观察到的桌子part模式,缺失的腿易于预测)。这样的话,可以对每个扫描场景中的物体寻找找相似的part先验来预测part掩模,并对预测的part掩模进行细化以产生最终的part掩模预测。这使得能够将场景的rgb
‑
d扫描鲁棒地分解成其组成对象及其组成部分,包括未被观察到的物体区域。
11.一种组件级别的三维场景理解方法,包括以下步骤:
12.步骤1:利用rgb
‑
d传感器获得室内三维场景的3d扫描数据;
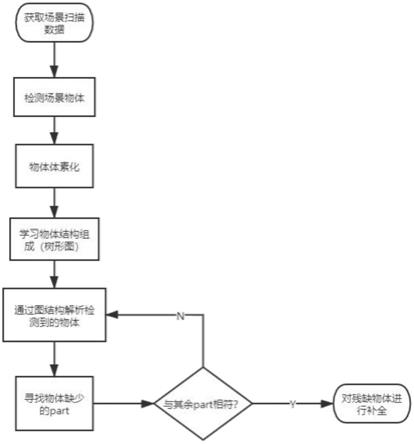
13.步骤2:检测出室内三维场景中的物体,用bouding box框出,并加上语义标签;
14.步骤3:将每一个检测的物体用占据网格表示;
15.步骤4:对一类物体的普遍组成部分应用树形图表示,每一个节点代表part类型;通过树形结构来完整的表现出物体part结构表示,以作为先验。
16.步骤5:根据步骤4获得的part先验生成扫描场景中物体完整的part掩码预测,并学习找到相似的几何零件先验,然后应用part先验对扫描场景中物体缺失的部分进行补全。
17.步骤2具体方法如下:
18.将获得室内三维场景的3d扫描数据采样为点云,采用votenet作为检测物体位置的主干网络,提取出n
p
个带有d
p
维特征的bounding box,将室内三维场景中的物体特征总体表示为,通过该特征预测d
b
维的box参数,包括中心坐标,尺寸,角度,语义标签l和物体标签得分s
obj
。根据获得的中心坐标计算box和任何gt物体中心点的距离,得到box的物体得分,当距离≤0.3m时为正值,当距离>0.3m为负值。最后通过2层
mlp回归box参数。每一个属于的特征f
p
代表了一个box的语义和几何信息。
19.进行dropout,通过box的物体得分选出最大概率正确框出物体的bounding box。
20.步骤3具体方法如下:
21.对于从扫描中检测到的物体集合o={o
i
}中的元素,将o
i
表示为其预测box内的323个占据网格,采用四个3d卷积块对占据网格进行编码,并提取维度为128的特征编码zi,用于下一步的part分解获取信息。所述的四个3d卷积块中第一个3d卷积块包括一层卷积层和relu激活层,之后的三个3d卷积块的结构包括一层卷积层、group normalization和relu激活层。
22.步骤4具体方法如下:
23.首先将步骤3提取的特征编码zi解码为part树预测,构建一个零件树ti,每个节点由其预测的part类别和对应的零件特征编码表示。利用消息传递图神经网络进行part树预测。从zi开始,使用mlp预测树子节点,以预测对应于o
i
的潜在部分的潜在向量{z
′
k
},即每个子节点的元组t
k
=(e
k
,s
k
),其中e
k
是子节点存在的概率,s
k
是part类别标签的one
‑
hot表示。对于每对子节点,预测它们是否相邻,通过消息传递网络强制学习结构特征。使用交叉熵损失作为part类别标签,采用二进制交叉熵损失作为节点存在和邻接关系。获得o
i
的高级部分总结,其中子节点上的潜在向量{z
′
k
}表示o
i
的part语义信息,利用该part语义信息完成最终物体part分解。
24.步骤5具体方法如下:
25.根据步骤4得到的子节点上的part语义信息从part数据集中寻找出符合语义标签的part,再采用2层3dcnn通过物体其他已经识别出的部分对寻找出的符合语义标签的part信息进行调整,防止生成的part与整体的物体差别过大,即使得补全后的物体更真实,选用同一语义标签且与现已经识别出的物体其余part部分最为接近的part数据集的部分。
26.本发明有益效果如下:
27.创新点1:对于三维场景中的物体,使用树形图表示其物体的结构,预测真实世界扫描场景中物体的零件图信息,作为一种中间表示,以实现物体的鲁棒的、基于零件的表示形式。
28.创新点2:利用训练集中预测的一种语义标签物体的通常结构来作为先验知识,以便于为扫描场景中的物体更有效的推断出part级别的表示。
29.创新点3:通过预测出的part图来补全扫描物体的缺失部分,即,这个物体与模板物体是否相似(识别物体的时候会有语义标签,指的是几何上是否相似),如果是的话,会通过先验结构(代表了模板物体的组成部分)来对扫描物体缺失的部分的语义标签进行预测,并通过其他部分的(例如,一个桌子缺了一个腿,可以参考其他三个腿的形状)形状作为参考进行补全。
附图说明
30.图1为本发明方法的整体流程图。
具体实施方式
31.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实
施方式对本发明作进一步详细的说明。
32.如图1所示,步骤1:利用rgb
‑
d传感器获得室内三维场景的3d扫描数据;
33.步骤2:检测出室内三维场景中的物体,用bouding box框出,并加上语义标签;
34.将获得室内三维场景的3d扫描数据采样为点云,采用votenet作为检测物体位置的主干网络,提取出n
p
个带有d
p
维特征的bounding box,将室内三维场景中的物体特征总体表示为通过该特征预测d
b
维的box参数,包括中心坐标尺寸角度语义标签l和物体标签得分s
obj
。根据获得的中心坐标计算box和任何gt物体中心点的距离,得到box的物体得分,当距离≤0.3m时为正值,当距离>0.3m为负值。最后通过2层mlp回归box参数。每一个属于的特征f
p
代表了一个box的语义和几何信息。
35.上面的过程执行完毕后,场景中会生成很多个bounding box,还需要最后进行dropout,通过box的物体得分选出最大概率正确框出物体的bounding box,例如没有/很少点或者远离任何物体的box将会被剔除。
36.步骤3:将每一个检测的物体用占据网格(体素)表示;
37.对于从扫描中检测到的物体集合o={o
i
}中的元素,将o
i
表示为其预测box内的323个占据网格,采用四个3d卷积块对占据网格进行编码,并提取维度为128的特征编码zi,用于下一步的part分解获取信息。所述的四个3d卷积块中第一个3d卷积块包括一层卷积层和relu激活层,之后的三个3d卷积块的结构包括一层卷积层、group normalization和relu激活层。
38.步骤4:对一类物体的普遍组成部分应用树形图表示,每一个节点代表part类型(例如:椅子腿,椅子背);通过树形结构来完整的表现出物体part结构表示,以作为先验。
39.对于从扫描中检测到的物体o
i
,表示为在其预测的边界框内的323个占据网格,我们的目标是从其混乱和部分观察中捕获其高级部分结构。这一步预测物体的part树结构,有助于通过预测物体的高级结构来完成该物体的表示,能够进行先验引导的part几何预测。
40.首先将步骤3提取的特征编码zi解码为part树预测,构建一个零件树ti,每个节点由其预测的part类别和对应的零件特征编码表示。参考structurenet,利用消息传递图神经网络进行part树预测。从zi开始,使用mlp预测树子节点,以预测对应于o
i
的潜在部分的潜在向量{z
′
k
},即每个子节点的元组t
k
=(e
k
,s
k
),其中e
k
是子节点存在的概率,s
k
是part类别标签的one
‑
hot表示。对于每对子节点,预测它们是否相邻,通过消息传递网络强制学习结构特征。使用交叉熵损失作为part类别标签,采用二进制交叉熵损失作为节点存在和邻接关系。获得o
i
的高级部分总结,其中子节点上的潜在向量{z
′
k
}表示o
i
的part语义信息,利用该part语义信息完成最终物体part分解。
41.步骤5:根据步骤4获得的part先验生成扫描场景中物体完整的part掩码预测,并学习找到相似的几何零件先验,然后应用part先验对扫描场景中物体缺失的部分进行补全。
42.根据步骤4得到的子节点上的part语义信息从part数据集中寻找出符合语义标签的part,再采用2层3dcnn通过物体其他已经识别出的部分对寻找出的符合语义标签的part信息进行调整,防止生成的part与整体的物体差别过大,即使得补全后的物体更真实,选用
同一语义标签且与现已经识别出的物体其余part部分最为接近的part数据集的部分,这一部分简单应用2层3dcnn即可,因为物体part部分的几何信息并不丰富,因此比较易于识别。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
