1.本发明涉及计算机技术领域,尤其涉及一种基于电商评论的用户侧商品知识图谱构建方法。
背景技术:
2.知识图谱是一种用图模型来描述知识和建模万物之间关联关系的技术方法。近年来随着互联网的兴起和电子商务的蓬勃发展,面向电商的搜索、推荐等应用的研发也越来越多。知识图谱作为一种描述实体和概念关系的强大工具,也逐渐被引入到电商系统中,以提升对用户查询请求的语义理解和识别效果。但是目前电商平台的知识图谱构建方法,仍以商品提供者的视角为主,抽取商品的信息和基本属性作为知识,几乎没有从用户视角切入构建用户侧商品知识图谱的应用研究。
3.在互联网电商平台上,每天都会产生海量的用户评论数据,这些评论中蕴含的观点信息,会为购买商品的用户提供重要的决策参考。因此,知识图谱作为大型电商系统智能化搜索、推荐的一项基础设施,若能融合用户侧的观点认知信息,将带来巨大的实际价值。然而目前对于电商用户侧知识图谱的构建,尚缺乏一套简单易用、高效的方案。
技术实现要素:
4.为解决上述技术问题,本发明提供了一种基于电商评论的用户侧商品知识图谱构建方法,通过对来自电商平台的用户评论数据进行词性标注以抽取领域词汇,再以此为基础,通过依存句法分析技术挖掘用户的观点意见,最终提取出和该商品细分领域相关的知识,构建知识图谱的方案。该方法可以快速从商品评论中获取到用户对商品某些属性的评价态度,以及用户特别提到的品牌等信息,并利用这些信息构建基于用户侧认知的知识图谱。
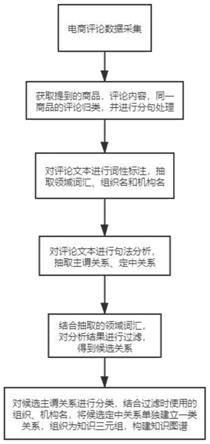
5.具体包括五个步骤:步骤一:从互联网上采集到的电商原始评论数据中,提取用户评论涉及的商品以及评论文本内容。将涉及同一商品的评论汇总,并对分句根据句号、问号、感叹号三种标点对句子进行切分处理,其目的在于方便接下来的句法分析。
6.步骤二:抽取商品细分类目、专业领域相关的词语以及组织和机构等名字,形成领域词典。
7.步骤三:对步骤一的分句结果分别进行依存句法分析,使用hanlp工具包中的依存句法分析api,提取分析结果中的主谓关系和定中关系。
8.步骤四:结合步骤二中得到的领域词典,对步骤三中提取的主谓关系和定中关系进行过滤。若关系中出现了领域词典中的词语,则将其保留,从依存句法关系出发,主谓关系做情感分析分类为好评、差评关系,定中关系结合领域词汇过滤,得到品牌关系(has_part_of),得到构建知识图谱的候选关系。
9.步骤五:对过滤后的主谓关系进行正负面情感分类,得到用于构建知识图谱的实
体关系。具体地,将同一商品、同一主语的候选主谓关系进行归类,检查相应的谓语是否具备明显的情感倾向,若其表达正面情感,则对应的主语得分 1,若其表达负面情感,则对应的的主语得分
‑
1,若该谓语不表达明显的情感倾向,则相应主语得分为0。统计主语总得分,若得分为正数或0,则分类为is_good_at关系,若得分为负数,则分类为is_bad_at关系。结合之前抽取出的组织名、机构名等,对候选定中关系单独建立一类has_part_of关系。将上述关系组织为知识三元组,构建知识图谱。
10.进一步,所述步骤一中,所述电商原始评论数据包括提到的商品、商品细分类目和评论文本内容。将原始数据中引用商品字段、评论正文字段中的内容提取出来,引用相同商品的评论归为一类,得到每个商品对应的评论文本集合。所述用户评论涉及的商品以及所述评论的文本内容,基于所述电商原始评论数据,以所述用户评论涉及的商品为实体单位进行整合。最终将商品作为头实体出现,并由is_good_at和is_bad_at关系指向不同的属性,所以需要把一个商品的所有评论聚集到一起。
11.进一步,所述步骤二中,词性的概念不局限于语法层面,即组织名或机构名也作为一种特殊的词性出现。
12.进一步,所述步骤三中,主谓关系为可能包含用户观点的关系,定中关系为可能包含品牌信息的关系。
13.进一步,所述步骤四中,候选主谓关系的筛选条件为主语在领域词汇中出现,候选定中关系的筛选条件为定语在组织或机构名称中出现。
14.进一步,所述步骤五中,is_good_at与is_bad_at关系的头实体为商品名,尾实体为商品的某些属性,has_part_of关系的头实体为商品名,尾实体为某些品牌或公司名称。
15.本发明所要实现的技术效果在于:本发明中构建商品知识图谱的实体及关系是从电商用户评论中抽取,在电子商务快速发展的背景下,电商平台积累了大量的用户评论数据,且这些数据均为公开,采集技术便利且成熟。同时,本方法简单易行,不需要大量的数据进行复杂模型的训练,使用开源的自然语言处理代码库即可实现,并且可拓展性强,在各个类目的商品评论上均能进行知识抽取。本方法采用电商平台真实有效的文本数据,基于用户对商品的评论来抽取知识,从而在知识图谱中融入用户侧对商品的认知,具有比较大的实际应用价值和现实意义。本方法使用依存句法分析来获取句子中词语之间的关系,再进一步通过领域词典对这些关系进行过滤,将句法关系转化为实体之间的关系,进而构建知识图谱。
16.本发明中构建用户侧知识图谱的方法围绕领域词典展开,不限定领域和文本语言,在各个电商平台都具有通用性,可以满足电商平台运营中对于用户观点的理解、建模的需求。
附图说明
17.图1为本发明的流程示意图;图2为对电商评论文本的依存句法分析示意图;图3为构建的知识图谱示意图。
具体实施方式
18.为了能够更加详尽地了解本发明实施例的特点与技术内容,下面结合附图对本发明实施例的实现进行详细阐述,所附附图仅供参考说明之用,并非用来限定本发明实施例。
19.为清楚地说明本发明的设计思想,下面结合实施例对本发明进行说明。
20.图1为本发明实施例的基于电商在线评论的用户侧商品知识图谱构建方法的流程图,如图1所示,一种基于电商在线评论的用户侧商品知识图谱构建方法,包括:步骤1、通过互联网上的电商平台的评论区采集评论文本数据,为抽取用户侧知识提供数据基础。
21.步骤2、从原始评论数据中,按照字段含义,提取出用户提到的商品,以及评论的文本内容。将提到同一商品的评论汇总,并对分句根据句号、问号、感叹号三种标点对句子进行切分处理,其目的在于方便接下来的句法分析。
22.步骤3、对步骤二分句后的结果进行词性标注,将与商品细分类目相关、专业领域相关的词语、组织和机构名等名词抽取出来,形成领域词典。
23.步骤4、对步骤二分句后的结果,每个句子进行依存句法分析,使用hanlp工具包中的依存句法分析api。提取分析结果中的主谓关系、定中关系,句法分析的效果如图2所示。
24.步骤5、结合步骤三中得到的领域词汇集合,对步骤四中提取的关系进行过滤。若关系中出现了领域词汇中的词语,则将其保留,从依存句法关系出发,主谓关系做情感分析分类为好评、差评关系,定中关系结合领域词汇过滤,得到品牌关系(has_part_of),得到构建知识图谱的候选关系。
25.步骤6、对过滤后的主谓关系进行正负面情感分类,可结合既有情感词典实现,亦可利用既有其它情感分类方法实现,以得到用于构建知识图谱的实体关系。具体地,将同一商品、同一主语的候选主谓关系进行归类,检查相应的谓语是否在情感词典中,若在正面情感词典中,则对应的主语得分 1,若在负面情感词典中,则对应的的主语得分
‑
1,若两种情感词典中均不包含该谓语,则相应主语得分为0。统计主语总得分,若得分为正数或0,则分类为is_good_at关系,若得分为负数,则分类为is_bad_at关系。结合之前抽取出的组织名、机构名等,对候选定中关系单独建立一类has_part_of关系。将上述关系组织为知识三元组,构建知识图谱,效果如图3所示。
26.在本实施示例中,关于数据采集,以从京东电商平台采集的用户评论数据为例,每条数据包含提到的商品、商品类别信息、用户信息、用户评论内容等字段,如今随着电商迅猛发展,电商平台上也积累了海量的用户评论文本,对于网页数据的抓取也有成熟的方法和技术,进一步确保了本方法的可行性与可用性。
27.将采集到的数据按照评论id进行去重,去重后的评论以提到的商品为主键,进行重新分类存储,为接下来抽取和每个商品相关的知识做好准备。对每条评论文本,按照标点符号等规则进行分句,将整条评论文本拆分成单个句子。
28.接下来,使用开源的模型工具,对所有句子进行词性标注,在模型生成的标注序列中,挑选出和商品细分领域相关的词语,以及品牌名和机构名等。例如,商品评论中提到某款电脑,则提取计算机相关专有名词。此外,用户评论中的品牌词也要单独提取出来。例如“这款电脑配的是希捷硬盘,对多线程支持的很好”这一句子,使用开源自然语言处理工具hanlp进行词性标注结果为:“这款/r, 电脑/n, 配/v, 的/ude1, 是/vshi, 希捷/ntc, 硬
盘/n, ,/w, 对/p, 多线程/gi, 支持/v, 的/ude1, 很好/ad”,其中“希捷”词性为“ntc”即公司名,“多线程”词性为“gi”即计算机名词。对所有句子做词性标注,可构建整个语料集的领域词典。
29.对切分好的句子,进行依存句法分析,提取出分析结果中的主谓关系、定中关系。如“这款电脑的处理器不错”中,“处理器”与“不错”呈主谓关系,再如“这款电脑配的是希捷硬盘”中,“希捷”与“硬盘”呈定中关系。调用开源自然语言处理工具hanlp中的依存句法分析接口,保留依存关系为主谓关系、定中关系的词对,并将两种词对分开存储。
30.接下来,对两种句法关系分别进行针对性处理,将句法关系转化为知识图谱中实体之间的关系。对于主谓关系,结合既有的情感词典进行分类。具体地,对每个商品的评论中抽取出的主谓关系,以关系中的主语为关键字进一步归类。遍历该主语下对应的所有谓语,若在正面情感词典中,该主语得分 1;若在负面情感词典中,该主语得分
‑
1;若均不在,该主语得分0。依照上述方法,统计该商品下每一主语的总分。若总得分非负,则分类为is_good_at关系;若总得分为负数,则分类为is_bad_at关系。例如,电脑产品p在主语a下有谓语{“不错”,“挺好”,“不行”},经计算总分为 1 1
‑
1= 1,于是得到关系(p,is_good_at,a)。对于定中关系,检查定语是否在公司名、机构名的词典中,若在词典中,则建立has_part_of关系。如电脑产品p下有定中关系(希捷,硬盘),则建立关系(p,has_part_of,希捷)。由此得到一系列三元组,并构建知识图谱。
31.应用本发明中的商品知识图谱构建方法,可以快速地从电商用户评论中提取出结构化知识,并且构建基于用户侧认知的知识图谱。借助知识图谱融合技术,该方法构建的知识图谱能够与电商系统中比较成熟的商品供给侧知识图谱融合,从而填补电商知识图谱中用户侧认知信息的缺失。
32.本发明中的方法使用原始的电商评论文本即可运行。在互联网和电子商务快速发展的大背景下,电商评论数据能够被方便、及时地收集。同时,本方法不需要大量带标签的数据进行复杂模型的训练,只需要借助一些公开、易获取的词典作为辅助,而领域词典等均可从原始评论中自动抽取。本方法基于电商在线评论,能够真实地反映出电商用户对于某件商品的理解和评价,有比较大的实际应用价值和现实意义。本方法是根据用户的观点态度,对实体打分汇总,来进行实体关系分类,因此随着评论数据的不断积累,用户群体整体的观点倾向可能发生变化,导致实体关系发生变化,从而使得知识图谱具有演化能力。本发明中的知识图谱构建方法具有几个特征:第一,基于电商用户评论,表达用户观点认知;第二,将针对同一商品的评论所蕴含的信息进行汇总,用多数用户的观点来作为实体关系的最终分类,使得知识抽取的可信度更高,能够带来更大的实际价值;第三,使用清晰、明确的知识抽取规则,方法效果确定性高、稳定性强且易于复现。
33.本发明基于电商用户评论,构建用户侧商品知识图谱,方法简单易行,速度和效率高,能够从大规模电商评论数据中快速抽取知识,也可方便地对既有知识图谱进行存量更新与增量更新,因而能够适应当今互联网电商迅速更新迭代的环境。方法可用性强,原理简单,实施简便,同时可以很好地与知识图谱其它技术相融合,应用于更加复杂多变的业务场景。
34.在附图中,图1展示了本方法实施的技术流程路线,图2为句法分析示意图,图3为构建的知识图谱大致效果。
35.以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
