基于xgboost的短临雷雨大风的预测方法
技术领域
1.本发明属于机器学习及气象技术领域,涉及基于xgboost的短临(即短时临近)雷雨大风的预测方法。
背景技术:
2.天气预报的发展在对工业、农业、商业贸易、日常生活等发挥着重要的保障作用。雷雨大风即出现雷、雨天气现象时,风力值大于10.8m/s,降雨量大于20mm的一种天气现象。短临即短时临近,捕捉瞬息风雨。相对于短期、中期、长期预报而言,短临预报在天气预报领域中是最“年轻”的成员,发展潜力巨大。雷雨大风是一种典型的灾害性天气过程,属于强对流天气的一种,具有突发性强度大等特点,对社会经济和人民生命安全带来不利影响。另外降雨量的精确预测也有利于水资源的管理和调度。
3.在对雷雨大风预测研究中,目前,雷雨大风短临预报上采用机器学习方法的研究较少,多数都是基于实况场要素对当前时刻降雨和大风进行预报和研究,因此具有计算代价大、依赖专家知识、难以适应错综复杂变化等问题。
技术实现要素:
4.发明目的
5.本发明为解决目前雷雨大风短临预报存在计算代价大、依赖专家知识、难以适应错综复杂变化等问题,本发明将代替人工预测,通过计算机中机器学习方法实现短临雷雨大风天气的自动化预测。
6.技术方案
7.基于xgboost的短临雷雨大风的预测方法,其特征在于:该方法的实现过程分为三步骤:
8.第一步骤:基于多类原始数据的处理并建立样本集;
9.第二步骤:将样本集输入到模型当中进行训练并分析结果;
10.第三步骤:模型布置在实际的气象预报系统中,并且实时得到预测结果。
11.所述第一步骤,找寻两处精准的原始数据,处理并建立样本集;利用地面雷达观测站和环境预报中心每隔几小时采集的数据进行预处理为对应的数据集,再分析两类数据集;
12.所述第二步骤,建立基于xgboost的雷雨大风预测模型,将第一步骤中的训练样本集导入所述模型进行训练并分析结果;
13.1)根据雷雨大风的特征属性,将雷雨大风预测模型的输入确定为ncep中的数据集,即为降雨数据集;输出为地面雷达数据集,即为降雨和大风的数据集;
14.2)对雷雨大风预测模型进行训练,将上述样本在xgboost系统中的预测结果,其训练策略采用贪心策略确定分裂特征及特征值,从而减少在寻找分裂特征时算法的复杂度;并采用交叉验证、分布式训练等特点使模型有较好的训练与预测性能;基于以上,根据降雨
和大风数值,预测是否会发生雷雨大风;
15.3)训练模型拥有降雨和大风两个属性,将其定义为机器学习当中的回归问题,训练两个模型,最终能够得出:大风模型的测试决定系数r2和降雨模型的决定系数r2,决定系数越接近1说明模型效果越好;
16.4)采用气象领域常用的ts评分检验预测效果其值;
17.所述第三步骤,将所述第二步骤中训练得到的模型布置在气象局气象预测系统上,来实时预测雷雨大风情况:
18.1)通过气象局与cimiss系统的对接,生成预测雷雨大风所需要的气象实时数据文件,即为ncep当中的与雷雨大风相关属性的数据,作为输入;
19.2)通过所述训练好的模型,得到输出为降雨和大风的数据值;
20.3)将输出得到的数据值即预测结果,进行可视化处理;
21.优点及效果
22.本发明对雷雨大风的短临预报业务开展及研究具有重要的学术意义和广泛的应用价值。本发明以气象天气中常见的降雨和大风做为研究对象,判断未来3小时之内是否具有雷雨大风天气,此外,本项目将建立两个模型,使用机器学习的方法分别对降雨和大风数据值进行分析,进而对雷雨大风进行预测,为灾害天气的预测预报研究和应用提供一定的参考价值。
23.通过分析不同预警时间下影响降雨和大风的主要气候因素,并采用机器学习方法对降雨和大风短临预报进行研究,并将其应用到实际的预警业务系统中。这对雷雨大风的短临预报业务开展及研究具有重要的学术意义和广泛的应用价值。此外,本项目将建立两个模型,使用机器学习的方法分别对降雨和大风数据值进行分析,进而对雷雨大风进行预测,为灾害天气的预测预报研究和应用提供一定的参考价值。
附图说明
24.图1为本发明的预测与实际分析图;
25.图2为本发明的数据预测可视化结果图;
26.图3为本发明的雷雨大风等级划分图。
具体实施方式
27.下面结合附图对本发明做进一步的说明:
28.基于xgboost的短临雷雨大风的预测方法,该方法的实现过程分为三步骤:
29.第一步骤:基于多类原始数据的处理并建立样本集;
30.第二步骤:将样本集输入到模型当中进行训练并分析效果;
31.第三步骤:模型布置在实际的气象预报系统中,并且实时得到预测结果。
32.过程具体如下:
33.第一步骤,找寻两处精准的原始数据,处理并建立样本集;如利用地面雷达观测站和美国国家环境预报中心(national centers for environmental prediction:ncep)每六小时采集的数据进行预处理为对应的数据集,再分析两类数据集,构建模型训练样本集。
34.1)对利用地面雷达观测和美国国家环境预报中心采集的数据进行数据预处理,即
对采集到的原始数据进行解析处理,形成数据文件。
35.2)处理数据文件,进行去除缺失值及异常值、重复值等一些处理,形成完整的数据文件。
36.3)通过筛选与雷雨大风相关的属性,删除其中不相关或不重要的属性,由于雷雨大风气象数据特征属性有46个,相对较多,遍历特征需要花费很长的时间,而本文采用的xgboost是一个树集成模型,它使用k(树的总数为k)棵树,将每棵树对样本预测值的和作为该样本在xgboost系统中的预测结果,定义的函数表达式如式(1)所示。首先xgboost采用预排序,在迭代之前,对结点的特征做预排序,遍历选择最优分割点,数据量大时,贪心法耗时少,因此能够快速得到所有雷雨大风气象特征的分裂点;
[0037][0038]
式(1)中树的总数为k,表示训练的迭代次数,即xgboost采用迭代算法时需要建立子树的个数,f
k
表示第k次迭代得到的决策树。
[0039]
4)此后将处理好的两类数据文件进行经纬度匹配。
[0040]
5)最后将处理好的两类数据文件通过时间经纬度进行匹配,形成本发明的模型训练样本集。
[0041]
第二步骤,建立基于xgboost的雷雨大风预测模型,将步骤(一)中的训练样本集导入该模型进行训练并分析结果;
[0042]
1)根据雷雨大风的特征属性,将雷雨大风预测模型的输入确定为ncep中的数据集,即为降雨数据集,输出为地面雷达数据集,即为降雨和大风的数据集;
[0043]
2)对雷雨大风预测模型进行训练,将上述样本在xgboost系统中的预测结果,其训练策略采用贪心策略确定分裂特征及特征值,从而减少在寻找分裂特征时算法的复杂度。并采用交叉验证、分布式训练等特点使模型有较好的训练与预测性能。基于以上,根据降雨和大风数值,预测是否会发生雷雨大风。
[0044]
xgboost迭代训练过程中采用的目标函数是关于导数的泰勒二阶展开式,其中未进行泰勒展开的表达式见式(2);其中式(3)ω(f)为式(2)中ω(f
k
)的展开式
[0045][0046][0047]
式(2)中y
i
表示第i个样本的降雨或大风值,表示上一次训练时(上一个时刻决策树)的第i个样本所预测的降雨和大风值,表示关于真实值y
i
和预测值的损失函数,只有当损失函数越低时,即真实的降雨和大风数值与预测的数值越接近,效果才会越好。
[0048]
式(3)中λ表示正则项平衡系数,其目的是为平衡损失函数和每一个构成xgboost的决策树复杂度,t表示第k轮训练得到的构成xgboost的决策树的叶子结点的个数,w表示第k轮构成xgboost的决策树的叶子节点的分数,ξ表示控制叶子节点个数的影响因子。
[0049]
训练时,新的一轮加入一个新的f函数,来最大化地降低目标函数,在第t轮,我们的目标函数为见式(4)。
[0050][0051]
将目标函数进行泰勒展开,取前三项,移除高阶小无穷小项,最后我们的目标函数转化为泰勒展开式如式(5)所示,
[0052][0053]
每棵树的得分(score)只与损失函数的一阶导数和二阶导数相关,式(5)中g
i
为关于上一时刻即第(t
‑
1)次迭代时第i个样本值的一阶导数,h
i
为关于上一时刻即第(t
‑
1)次迭代时第i个样本值的二阶导数,详见式(6)和式(7)。
[0054][0055][0056]
其中为式(2)中函数,i
j
表示第j个节点里样本的集合,表示第x
i
个叶子节点的权重。
[0057]
3)训练模型因为拥有降雨和大风两个属性,将其定义为机器学习当中的回归问题,训练两个模型,最终得出大风模型的测试决定系数为0.94,降雨模型的决定系数为0.67,决定系数越接近1说明模型效果越好。
[0058]
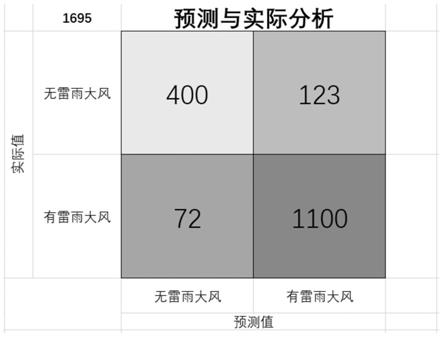
4)采用气象领域常用的ts评分检验预测效果其值为0.849,将所有样本数据集作为模型样本,附图1为所有样本数据1695条所做的预测与实际的分析,根据气象领域,常用的检验预测效果的统计量ts评分为0.849,ts评分越接近1效果越好,而从气象部门了解得知,当前人工的预测效果准确率在50%左右。所以本发明中的模型得到了不错的预测效果。
[0059]
本发明将经过处理后的地面观测数据和再分析数据集中的所有样本数据集以8:2的比例随机进行分离,形成训练集和验证集。其中,数量较多的80%训练数据集被用于输入到xgboost模型之中对模型训练,在每一轮迭代中通过上一轮对降雨和大风的实际值的残差再进行调整,在迭代中不断改变进行修正使得残差值不断变小最终得到对降雨和大风分析效果最优的算法模型。之后用20%的测试值来对模型进行测试,判别效果通过决定系数(coefficent of determination)来判定,也称为拟合优度。决定系数反应了y的波动有多少百分比能被x的波动所描述,即表征变数y的变异中有多少百分比,由控制的自变数x来解释,决定系数越接近1说明模型效果越好。
[0060]
表达式:r2=ssr/sst=1
‑
sse/sst
[0061]
其中:sst=ssr sse,sst(total sum of squares)为总平方和,ssr(regression sum of squares)为回归平方和,sse(error sum of squares)为残差平方和。
[0062][0063][0064][0065][0066][0067]
拟合优度越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比高。观察点在回归直线附近越密集。
[0068]
利用以上表达式得出,大风模型的测试决定系数r2为0.94,降雨模型的r2决定系数为0.67,决定系数越接近1说明模型效果越好。
[0069]
同时将本项目采用的xgboost算法和其他典型的机器学习算法进行比较。其中对比的方法包括linearregression(线性回归模型),线性回归模型也为机器学习的一类模型,同理大风模型的决定系数r2为0.39,降雨模型的决定系数r2为0.28,远低于本项目使用模型。
[0070]
从实验结果可知,综合来看,本项目所采用xgboost算法决定系数远大于线性回归模型,具有较好的分类精度,其中对于降水和大风的预测更加精准。
[0071]
在所有的数据样本中,按照各类比例随机抽样部分样本作为建立模型样本。在训练模型时,选择抽样样本80%作为训练集训练模型,其余20%作为测试集。
[0072]
验证分析结果的模型准确率如表1所示,其中实验结果测试集(20%的未参与训练样本)正确率79.34%。再使用模型对所有数据样本进行测试,正确率为88.50%。
[0073][0074]
表1模型准确率分析
[0075]
所述步骤(二)中将预测结果及时反馈:
[0076]
最后对预测准确率进行分析准确率大部分在80%以上,据了解当前雷雨大风人工预测的准确率多数都在50%以下。为了进一步进行分析,对雷雨大风等级进行了划分,并进行了展示。
[0077]
第三步骤,将所述第二步骤中训练得到的模型布置在气象局气象预测系统上,从而实现实时预测雷雨大风情况:
[0078]
1.通过气象局与cimiss系统的对接,生成预测雷雨大风所需要的气象实时数据文
件,即为ncep当中的与雷雨大风相关属性的数据,作为输入;
[0079]
2.通过前期训练好的模型,得到输出为降雨和大风的数据值。
[0080]
3.将输出得到的数据值即预测结果,进行可视化处理,附图2为以2020年8月2日08时的数据为例进行预测得到的结果的可视化。
[0081]
将所有样本数据集作为模型样本,附图1为所有样本数据1695条所做的预测与实际的分析,根据气象领域,检验预测结果的统计量有:ts评分、命中率、漏报率、空报率、准确率。其中tp为实际有雷雨大风且预测有雷雨大风,fp为实际有雷雨大风而预测无雷雨大风,fn为实际无雷雨大风而预测有雷雨大风,tn为实际无雷雨大风且预测也无雷雨大风,各评价指标公式如下。
[0082]
ts评分公式:tp/(tp fp fn)
ꢀꢀꢀ
(13)
[0083]
命中率公式:tp/(tp fp)
ꢀꢀꢀ
(14)
[0084]
漏报率公式:fn/(tp fn fp tn)
ꢀꢀꢀ
(15)
[0085]
空报率公式:fp/(tp fn fp tn)
ꢀꢀꢀ
(16)
[0086]
准确率公式:(tp tn)/(tp fn fp tn)
ꢀꢀꢀ
(17)
[0087][0088]
表2各评价指标值
[0089]
表2是由公式(10
‑
14)所得,ts评分为0.849,ts评分越接近1效果越好,而与气象部门了解得知,当前人工的预测效果准确率在50%以下,甚至更低。所以本发明中的模型得到了良好的预测效果。
[0090]
最后采用气象领域常用的ts检验预测效果,其值为0.849,ts评分越接近1效果越好,而从气象部门了解得知,当前人工的预测效果准确率在50%左右。所以本发明中的模型得到了良好的预测效果。
[0091]
实施例
[0092]
步骤一:第一类数据集来源于辽宁省沈阳市观测站地面观测数据库文件,为2010年至2013年,选择5月至9月的数据进行导出整理。本发明经过去除缺失值及异常值、重复值等处理,处理完成后有4个数据集。
[0093][0094]
表3为实时下载气象数据文件
[0095]
①
根据降雨量大于20mm大风值大于10.8m/s,确定为风大雨大数据集文件;
[0096]
②
根据降雨量大于20mm大风值小于10.8m/s,确定为风小雨大数据集文件;
[0097]
③
根据降雨量小于20mm大风值大于10.8m/s,确定为风大雨小数据集文件;
[0098]
④
根据降雨量小于20mm大风值小于10.8m/s,确定为风小雨小数据集文件;通过分别对以上4个数据集进行经纬度匹配,生成了第一类数据集文件。
[0099]
第二类数据集来源于ncep每6小时再分析数据集,ncep是美国国家环境预报中心(national centers for environmental prediction)的英文简称。和地面观测数据对应时间选取2010年至2013年中5月至9月的数据,数据格式为grib2格式,grib码是与计算机无关的压缩的二进制编码,主要用来表示数值天气预报的产品资料。现行的grib码版本有grib1和grib2两种格式,雷雨大风项目采用的就是grib2数据格式的,共计2447个文件,首先采集原始气象天气数据,分析与雷雨大风相关的气象要素,然后使用特征分析方法分析气象要素与雷雨大风现象的属性重要性,选取46个特征属性,并对特征属性进行解析,通过经纬度和时间与第一类数据进行匹配,最终建立3小时短临时刻的数据样本集合。
[0100]
步骤二:将经过处理后的地面观测数据和再分析数据集中的所有样本数据集以8:2的比例随机进行分离,形成训练集和验证集。其中,数量较多的80%训练数据集被用于输入到xgboost模型之中对模型训练,在每一轮迭代中通过上一轮对降雨和大风的实际值的残差再进行调整,在迭代中不断改变进行修正使得残差值不断变小最终得到对降雨和大风分析效果最优的算法模型。
[0101]
步骤三:用20%的测试值来对模型进行测试,判别效果通过决定系数(coefficent of determination)来判定,也称为拟合优度。决定系数反应了y的波动有多少百分比能被x的波动所描述,即表征变数y的变异中有多少百分比,可由控制的自变数x来解释,决定系数越接近1说明模型效果越好。
[0102]
大风模型的测试决定系数为0.94,降雨模型的决定系数为0.67,其中对比的方法包括linearregression(线性回归模型),线性回归模型也为机器学习的一类模型,同理大风模型的决定系数为0.39,降雨模型的决定系数为0.28,远低于本项目使用模型。
[0103]
其中使用本项目模型的实验结果测试集(20%的未参与训练样本)正确率79.34%。再使用模型对所有数据样本进行测试,正确率为88.50%。
[0104]
步骤四:通过气象局与cimiss系统的对接,生成预测雷雨大风所需要的气象实时
数据文件,即与雷雨大风相关的属性数据。该产品为txt文件,文件如附图1所示,数据为矩阵形式,数据为micaps中diamond4类格点数据,该数据表头数据说明为:(字符串)、年、月、日、时次、时效、层次(均为整数)经度格距、纬度格距、起始经度、终止经度、起始纬度、终止纬度(均为浮点数)、纬向格点数、经向格点数(均为整数)、等值线间隔、等值线起始值、终止值、平滑系数、加粗线值(均为浮点数)。文件选取时间为2020年6月2日8时的数据,编写数据处理算法,将其转换为表4所示的数据文件。
[0105][0106]
表4为实时气象要素匹配数据
[0107]
步骤五:cimiss系统数据更新功能会根据获取国家站数据来实现更新,其cimiss系统每天更新两次数据,并将更新的结果保存在系统主机中。
[0108]
在获取cimiss系统气象特征数据后,将该数据通过时间和国家站经纬度进行匹配形成实时气象要素数据,该数据如表4所示。该数据表头数据说明为:站点编号、经度、纬度,之后是气象特征(46个cimiss获取的气象要素)。文件中包括的气象特征如下,英文名称(部分)。
[0109]
hgt(位势高度),tmp(温度),pres(压强),vvel(垂直速度)
[0110]
步骤六:在cimiss系统上获取的数据经过解析后得到表4,作为模型的输入,利用模型对数据进行预测。在处理实时数据时,编程设计并实现了监视实时气象数据更新,以实现实时的气象数据的解码与分析,监视结果如下表所示。
[0111]
[0112]
表5为监视结果
[0113]
步骤七:表5为处理后的数据,作为xgboost模型的输入,输出为表6所示的结果数据,选取为2020年8月2日8时数据进行的预测结果,y为有雷雨大风,n为无雷雨大风。
[0114]
步骤八:将表6预测结果进行可视化处理,附图2为2020年8月2日08时的可视化结果呈现图,有雷雨大风的站点标记为红色,没有雷雨大风天气的无标记。
[0115][0116]
表6为预测结果
[0117]
步骤九:对预测准确率进行分析,采用数据分别为三天(8月1日、2日、3日),共计60多个国家站的实时地面观测数据来进行对比分析,其详细准确率如表7所示,每行数据说明为:日期、预测正确的站点/总的站点、准确率。其中第一行解释为日期为2020年8月1日8时往后推12小时的预测结果文件,总共有62个站点,预测正确了53个站点,准确率为85.48%,表中每一行都将预测的数据和实际的地面观测数据进行对比,总共列举了26行结果,每一行有数据62条,即62个国家站的预测结果,准确率在80%以上的有17行,准确率在70%以上有21行,据了解当前雷雨大风人工预测的准确率多数都在50%以下。所以本发明的模型预测效果良好,为气象领域预测雷雨大风提供了新的预测手段。
[0118][0119]
表7为准确率预测
[0120]
步骤十:为了进一步进行分析,对雷雨大风等级进行了划分,并进行了展示。其中根据浦氏风力等级来划分等级,蒲氏风力等级就是用数字(从1到17)描述风力的风级表,描述了从蒲氏零级风(calm)到十二级风(hurricane)的条件并对每级海上及陆上风况作了详细描述。其中风力级7级13.8m/s,9级为20.7m/s,,11级为28.4m/s,13级为大于32.6m/s。如附图3所示为2020年9月19日的雷雨大风等级划分图。
[0121]
级别说明:*型13级,三角形11级,正方形9级,圆形7级。
[0122]
本发明提到的短时临近雷雨大风预测是指根据气象学对预测的时间范围的定义,利用当前时刻已知的相关气象要素数据,通过机器学习方法对辽宁省各地区未来时间内是否发生雷雨大风进行预测。根据气象业务需求,具体来说,就是根据当前时刻的相关气象要素数据预测未来3小时的降雨和大风值。其需要对包含气象要素的数据进行机器学习训练,建立未来3小时短时临近预测机器学习模型,并根据所建立的机器学习模型的雷雨大风预测值对参与预测的气象要素进行分析。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
