1.本发明涉及计算机应用技术领域,尤其涉及面向并发数据分析任务的性能瓶颈分析系统。
背景技术:
2.随着各领域数据量和用户数量的不断增加,数据分析系统在处理并发任务时会出现任务执行时间过长、系统响应速度慢等性能问题,这些问题将直接关系到用户体验和企业利益。
3.随着大数据时代的到来,用于分析和挖掘数据内部规律的产品层出不穷,但只有高质量的产品及高效的软件服务才能为企业保持顾客粘性,由独立厂商olap研究机构提出的fasmi(fast analysis of shared multi
‑
dimensional information)特征表明:对于用户的大部分数据分析要求,系统应该能够在5秒内作出反应;对于简单的分析要求,系统应该能够在1秒内作出反应;而对于极少数的分析要求,响应时间可能超过20秒。
4.传统的性能分析仅仅通过观察系统资源(cpu、io、内存)的使用情况对系统性能进行研究,停留在狭义的性能指标表象阶段。这样的方法缺乏对性能瓶颈更深层次的挖掘,运维人员往往还需要结合性能指标与系统内部运行情况(系统日志)进行更深层次的性能瓶颈相关性分析。
5.而数据分析系统支持多用户并发操作,并发任务会产生集cpu、io、内存瓶颈于一体的混合瓶颈;在现有技术中,由于性能瓶颈具有持续时间不定,不可复现等特点,运维人员难以准确还原瓶颈产生时系统的运行情况,导致无法准确定位性能瓶颈并提供瓶颈分析报告。
技术实现要素:
6.为了解决现有技术存在的上述技术缺陷,本发明提供了一种面向并发数据分析任务的性能瓶颈分析系统,可以有效解决背景技术中的问题。
7.为了解决上述技术问题,本发明提供的技术方案具体如下:
8.本发明实施例公开了一种面向并发数据分析任务的性能瓶颈分析系统,所述系统包括:pebao框架,用于对数据分析系统提供性能指标异常检测、任务性能瓶颈判定、瓶颈相关性分析和瓶颈优化建议功能。
9.在上述任一方案中优选的是,pebao框架包括:
10.时间序列异常检测模块,用于对数据分析系统采集性能指标数据,识别异常时间序列,并将异常时间序列输出至性能瓶颈判定模块;
11.性能瓶颈判定模块,用于收集异常时间段内执行的所有数据分析任务,将查询语句的结构特征和执行特征输入随机森林分类算法,判定每个任务的性能瓶颈等级,并将中等级性能瓶颈和高等级性能瓶颈类别的任务集合发送至性能瓶颈相关性分析及优化模块;
12.性能瓶颈相关性分析及优化模块,用于对任务与瓶颈的相关程度和查询操作与瓶
颈的相关程度进行了量化,并结合启发式规则为每个数据分析任务提供查询优化建议。
13.在上述任一方案中优选的是,时间序列异常检测过程包括性能指标监控、时间序列数据获取、异常检测算法、时间序列异常判定和异常时间序列的输出。
14.在上述任一方案中优选的是,异常检测算法的处理流程如下:
15.在时间序列异常检测模块获取一段数据分析系统的性能指标数据后,对性能指标数据进行数据清洗;
16.对清洗完成的性能指标数据进行模式分片处理,将整段时序数据划分为若干时间窗口,每一个时间窗口为一个模式;其中,模式分片包含了固定分片和动态分片两种方法;
17.提取每一个模式的时序特征,并根据相似性度量方法计算模式之间的距离;
18.根据模式之间的距离求取所有模式的相关因子和异常因子,用于量化每一个模式的异常程度。
19.在上述任一方案中优选的是,时间序列异常判定可设置参数m和r,用于过滤异常时间序列;过滤过程为:对于连续的m个模式,其异常程度总是大于r,则将m个模式组成的时间序列区间输出为异常时间序列。
20.在上述任一方案中优选的是,输出异常时间序列后,性能瓶颈判定模块获取异常时间区间内正在执行的数据分析任务进行性能瓶颈等级判定。
21.在上述任一方案中优选的是,通过建立任务性能瓶颈判定模型对任务与性能瓶颈的相关性进行分析,任务性能瓶颈判定模型通过查询语句的性能特征判定查询语句的性能瓶颈等级,性能特征包括结构特征和执行特征。
22.在上述任一方案中优选的是,性能瓶颈相关性分析及优化模块包括查询解析器和性能优化器;查询解析器包括sql解析器和explain解析器。
23.在上述任一方案中优选的是,性能优化器包括启发式规则库和性能瓶颈相关性量化方法;其中,启发式规则库中存储中众多数据库运维人员的运维经验和基本的数据库优化原则。
24.在上述任一方案中优选的是,性能瓶颈相关性分析及优化模块将sql语句解析结果传输至启发式规则库中进行筛选,得出相应的sql改写优化建议和索引优化建议。
25.与现有技术相比,本发明的有益效果:
26.本发明提供了一种面向并发数据分析任务的性能瓶颈分析系统,通过pebao框架,用于对数据分析系统提供性能指标异常检测、任务性能瓶颈判定、瓶颈相关性分析和瓶颈优化建议;能够准确的分析任务与性能瓶颈的相关性,解决了运维人员难以准确还原瓶颈产生时的运行情况的问题,能够准确的定位性能瓶颈,并提供瓶颈分析报告。
附图说明
27.附图用于对本发明的进一步理解,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
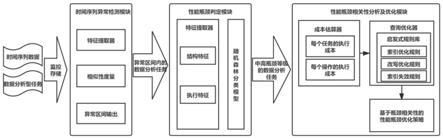
28.图1是本发明一种面向并发数据分析任务的性能瓶颈分析系统的pebao框架结构示意图;
29.图2是本发明一种面向并发数据分析任务的性能瓶颈分析系统中时间序列异常检测过程的流程图;
30.图3是本发明一种面向并发数据分析任务的性能瓶颈分析系统中任务性能瓶颈判定模型的示意图;
31.图4是本发明一种面向并发数据分析任务的性能瓶颈分析系统中性能瓶颈优化模块整体结构示意图;
32.图5是本发明一种面向并发数据分析任务的性能瓶颈分析系统中explain关键字查询结果的示意图;
33.图6是本发明一种面向并发数据分析任务的性能瓶颈分析系统中explain查询成本结构示意图;
34.图7是本发明一种面向并发数据分析任务的性能瓶颈分析系统中基于启发式规则的索引优化算法的流程图。
具体实施方式
35.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
36.为了更好地理解上述技术方案,下面将结合说明书附图及具体实施方式对本发明技术方案进行详细说明。
37.本发明提供了一种面向并发数据分析任务的性能瓶颈分析系统,所述系统包括pebao框架,用于对数据分析系统提供性能指标异常检测、任务性能瓶颈判定、瓶颈相关性分析和瓶颈优化建议功能。
38.具体的,pebao框架是一种自动化性能瓶颈分析框架,用于对数据分析系统提供性能指标异常检测、任务性能瓶颈判定、瓶颈相关性分析和瓶颈优化建议功能;如图1所示,pebao框架包括时间序列异常检测模块、性能瓶颈判定模块、性能瓶颈相关性分析及优化模块。
39.进一步的,在数据分析系统的运行过程中,pebao框架中的时间序列异常检测模块可以对数据分析系统的资源利用情况进行实时监控并识别异常的性能指标以识别系统性能问题,当检测出某一段时间序列存在异常时,pebao框架中的性能瓶颈判定模块会提取异常时间段中的所有数据分析任务,然后通过性能瓶颈相关性分析及优化模块计算每个任务与性能瓶颈的相关程度,并给出性能瓶颈的优化建议。
40.进一步的,时间序列异常检测模块用于对数据分析系统采集性能指标数据,识别异常时间序列,并将异常时间序列输出至性能瓶颈判定模块;
41.性能瓶颈判定模块用于收集异常时间段内执行的所有数据分析任务,将查询语句的结构特征和执行特征输入随机森林分类算法,判定每个任务的性能瓶颈等级,并将中等级性能瓶颈和高等级性能瓶颈类别的任务集合发送至性能瓶颈相关性分析及优化模块;
42.性能瓶颈相关性分析及优化模块用于对任务与瓶颈的相关程度和查询操作与瓶颈的相关程度进行了量化,并结合启发式规则为每个数据分析任务提供查询优化建议。
43.更为具体的,pebao框架通过telegraf工具实时采集数据分析系统的性能指标数据,并将性能指标数据发送至时间序列异常检测模块,时间序列异常检测模块主要对采集完成的性能指标数据进行异常识别,进而判定性能瓶颈。
44.进一步的,如图2所示,时间序列异常检测过程包括性能指标监控、时间序列数据获取、异常检测算法、时间序列异常判定和异常时间序列的输出;其中,异常检测算法的处理流程如下:
45.(i)在时间序列异常检测模块获取一段数据分析系统的性能指标数据后,由于性能指标采集工具不乏会出现数据错误,数据缺失等情况,需要对性能指标数据进行数据清洗;
46.(ii)对清洗完成的性能指标数据进行模式分片处理,将整段时序数据划分为若干时间窗口,每一个时间窗口为一个模式;其中,模式分片包含了固定分片和动态分片两种方法;固定分片是指将整个数据等分为大小相同的子序列;动态分片是指根据需求动态设定每个子序列的长度;
47.(iii)提取每一个模式的时序特征,并根据相似性度量方法计算模式之间的距离;其中,计算方法包括欧几里得距离计算方法,余弦相似度计算方法;
48.(iv)根据模式之间的距离求取所有模式的相关因子和异常因子,用于量化每一个模式的异常程度。
49.进一步的,为了区分随机误差导致的数据异常和真实的数据分析系统性能异常,时间序列异常判定可设置参数m和r,用于过滤异常时间序列;过滤过程为:对于连续的m个模式,其异常程度总是大于r,则将m个模式组成的时间序列区间输出为异常时间序列。
50.进一步的,输出异常时间序列后,性能瓶颈判定模块会获取异常时间区间内正在执行的数据分析任务进行性能瓶颈等级判定。
51.更为具体的,由于在并发环境下,瓶颈的产生往往涉及资源的竞争,因而分析并发数据分析任务中sql语句的结构特征和执行过程,有助于深入了解分析任务的资源竞争关系,以实现能够准确判定瓶颈是由单个分析任务引起的,还是由多个分析任务共同作用导致的,即任务与性能瓶颈的相关性。
52.进一步的,通过建立任务性能瓶颈判定模型对任务与性能瓶颈的相关性进行分析,如图3所示,任务性能瓶颈判定模型基于查询语句的性能特征使用随机森林分类算法判定查询语句的性能瓶颈等级,性能特征包括结构特征和执行特征。根据查询语句的执行时间动态设定任务的性能瓶颈等级,例如执行时间在0~20秒时判定为低等级瓶颈,执行时间在20~100秒时判定为中等级瓶颈,执行时间大于100秒时判定为高等级瓶颈。
53.进一步的,性能瓶颈等级判定完成后,性能瓶颈判定模块将中等级瓶颈和高等级瓶颈任务的sql语句发送至性能瓶颈相关性分析及优化模块,进而性能瓶颈相关性分析及优化模块分析性能瓶颈相关性,并给出瓶颈优化建议。
54.更为具体的,性能瓶颈相关性分析及优化模块主要对中等级瓶颈和高等级瓶颈任务进行性能瓶颈相关程度量化,并使用查询优化建议的优化效果,可进一步体现查询操作与性能瓶颈的相关性。
55.进一步的,如图4所示,性能瓶颈相关性分析及优化模块包括查询解析器和性能优化器;查询解析器包括sql解析器和explain解析器;其中,sql解析器,使用antlr(another tool for language recognition,一个可以解析众多数据库查询语言和其他自定义语言的语法分析工具)可实现对sql语句的关键字解析;explain解析器与sql语法解析器功能相似,主要解析查询sql语句的执行计划;sql语句的执行计划包括sql执行过程中数据库的扫
描行数、数据库使用的扫描算法等信息,sql语句能够准确表示sql语句的执行过程。
56.性能优化器包括启发式规则库和性能瓶颈相关性量化方法;其中,启发式规则库中存储着众多数据库运维人员的运维经验和基本的数据库优化原则。
57.进一步的,性能瓶颈相关性分析及优化模块将sql语句解析结果传输至启发式规则库中进行筛选,得出相应的sql改写优化建议和索引优化建议。性能瓶颈相关性分析基于mysql等数据库系统的查询代价模型,通过计算任务的查询代价占比量化任务与性能瓶颈的相关性。
58.其中,对于单个数据查询分析任务,使用启发式规则可满足查询语句的优化需求,在并发环境下,由于查询语句较多,启发式规则库得出的索引优化建议和sql改写优化建议数量会明显增多,通过性能瓶颈分析及优化模块可对并发环境下启发式规则产生的优化建议进行重要程度排序,筛选优化效果最好的查询优化建议,且查询优化建议的优化效果也能体现出优化建议所涉及的查询操作与性能瓶颈的相关程度。
59.在另一个实施例中,由于时间序列特征能够准确描述某段时间内的数据波动特性,例如某段时间序列数据的均值、方差、趋势强度、周期性、线性强度等;进而可通过开源时序数据特征提取包tsfresh提取时间序列的统计特征。tsfresh是一个专门用于提取时间序列数据特征的python工具库,它包含了许多特征提取方法和强大的特征选择算法,能够提取64种时间序列特征,时间序列有较多的统计特征,但大多数特征无法适用于异常时间序列的分析与识别,而tsfresh内置了特征过滤功能,能够评估每个特征对于当前分类或回归任务的解释能力和重要性。
60.如表1所示,采用以下特征作为计算时间序列模式相似程度的基础特征。
61.表1时间序列特征提取
[0062][0063][0064]
在上述时间序列特征中,方差和样本熵与时间序列的波动情况有关,若某段时间序列波动较大,则表示系统有可能产生了性能上的问题导致了性能指标的异常波动;均值、
中位数、最大值、最小值和线性回归方程的斜率主要研究时间序列的波动范围以及整体的趋势;自相关性为序列相关性,是研究一个信号与其自身在不同时间点的相关系数,即时间序列在不同时期的数据相关程度,它可用于测量时间序列后期数据受前期数据的影响程度大小;k阶自相关系数的计算公式为:
[0065]
其中z
t
为一组时间序列数据。
[0066]
更为具体的是,时间序列异常检测模块包括时间序列异常程度量化模型,时间序列异常程度量化模型使用固定分片的方法,将时间序列进行分段分析,每一段时间序列作为一个模式;其中,固定分片需要设置分片大小参数p,用户可以根据对异常检测精细程度的要求动态设定这一参数;进而异常程度量化模型对所有模式进行特征相似度比较,获取每个模式的异常程度。
[0067]
更为具体的是,时间序列异常程度量化模型使用tsfresh工具包对时序数据特征进行计算,然后采用基于时间序列特征距离的异常检测算法求取每个模式的异常程度。
[0068]
异常检测算法使用余弦相似度公式计算模式与模式之间的距离,进一步计算每个模式的相关系数、相关因子和异常因子。
[0069]
进一步的,相关系数能够体现每一个模式与其他所有模式的相关性。相关系数的计算方法如下:首先将每个模式的相关系数置零,然后通过相似性距离度量计算每一个模式与其他所有模式的距离,提取与当前模式距离最小的k个模式作为当前模式的可达邻居。接着将当前模式的k个可达邻居的相关系数进行自增操作(即相关系数的值增加一),最后计算出所有模式相对于其他模式的相关系数。
[0070]
优选的是,k的取值为整体模式分片数量的1/3。
[0071]
进一步的,相关因子是对相关系数进行归一化处理得出的结果;通过最大最小归一化方法,将相关程度转换到[0,1]范围内,其计算公式为:
[0072][0073]
异常因子:异常因子根据每个模式的相关因子计算得出,用于衡量每个模式的异常程度;其计算公式为:
[0074]
其中k表示模式的可达邻居数量。relationi表示与当前模式距离最近的第i个模式的相关因子。
[0075]
更为具体的是,基于时间序列特征距离的异常检测算法的伪代码如表2所示,
[0076]
表2时间序列特征提取
[0077][0078]
表2(续)
[0079][0080]
其中,第2行至第7行为异常检测算法的距离度量方法,首先通过余弦相似度公式计算所有模式之间的相似程度作为距离度量,然后将每个模式与其他模式的距离度量存储在二维数组distance[i][j]中,其中每个模式与自己的距离设定为一个较大的常数值,保证模式不会选择自己作为自己的可达邻居;第8行表示循环遍历每一个模式求取所有模式的相关系数;第9行至11行用于获取与当前模式距离最近的k个模式,作为当前模式的可达邻居;第12行至13行用于遍历当前模式的所有可达邻居,将所有可达邻居的相关系数进行自增操作,遍历完成所有模式后,即可得出每个模式的相关系数;第14行至15行表示使用公式计算每个模式的相关因子,模式的相关因子较高表明与它相似度较高的模式较多;第16行至18行则根据每个模式的相关因子求取异常因子。
[0081]
综上所述,时间序列相关程度量化模型首先通过提取性能指标数据的时序特征,比较了所有模式与其他模式的相似程度,然后分析出了时间序列中与其他模式差异较大的模式,最后结合了异常序列判定方法,能够有效地区分性能指标数据中的随机性误差和真实的性能异常。
[0082]
在另一个实施例中,性能瓶颈判定模块包括性能瓶颈判定模型,性能瓶颈判定模
型首先根据任务的执行时间将瓶颈等级划分为了高、中、低三类,然后对数据分析系统中的数据分析任务进行性能特征提取,并使用随机森林模型对所有任务的瓶颈等级进行分类,最后排除类别为低等级瓶颈的任务,将中等级瓶颈和高等级瓶颈任务的分析型查询语句输出至性能瓶颈相关性分析与优化模块。
[0083]
更为具体的是,由于不同的分类特征与分类结果的相关程度不同,且不同查询语句的特征差异较大,而随机森林分类模型具有良好的泛化能力,对噪声和异常值有较好的容忍性;性能瓶颈判定模型可通过随机森林算法构造出多个决策树对任务的瓶颈等级进行分类,能够对分类的特征进行重要性评估,综合比较多棵决策树下不同特征对分类结果的贡献程度,进而得出最终的分类结果。
[0084]
如图5所示,性能瓶颈判定模块使用explain关键字获取数据库查询优化器的执行计划,执行计划能够直观地体现查询语句在数据库中的执行过程和资源消耗情况,explain关键字能够获取查询优化器的详细执行信息,包括查询语句执行过程中表的读取顺序、数据读取操作类型、表索引分布情况、查询语句使用索引情况以及每张表的查询结果条数,这些信息有助于分析并发任务中数据查询操作之间的资源竞争关系;explain相关字段解释如表3所示。
[0085]
表3 explain查询结果解释
[0086][0087]
更为具体的是,查询语句的结构特征由查询解析器对sql语句进行关键字解析得出,特征包括了参与连接操作的表的个数、是否使用索引、表连接数量、子查询类型以及是否存在排序等,如表4所示。
[0088]
表4数据分析任务的结构特征
[0089][0090][0091]
表4(续)
[0092][0093]
查询语句的执行效率主要与查询过程中数据的扫描次数和比较次数有关;数据扫描次数是指进行数据查询需要扫描的数据行数,即explain查询结果中rows字段的累加次数;比较次数标识进行表连接操作和字段筛选操作所需要对数据进行数值比较的次数。对于两表连接,比较次数即为explain查询计划中rows字段的乘积;而在多表连接中,由于无法在数据查询语句执行之前获取数据表的连接结果,性能瓶颈判定模型无法准确得出多表连接的数据比较次数;性能瓶颈判定模块使用最大比较次数和普通比较次数来近似表示多表连接的比较次数;查询语句的最大比较次数和普通比较次数计算公式如下:
[0094][0095][0096]
在上述公式中,rows
i
代表了sql语句执行过程中对第i个表的数据扫描行数,最大比较次数表示表连接操作的最坏情况下得出的数据比较次数,而普通比较次数是将两表连接中数据扫描次数的最大值作为两表连接的结果数据量,其他的执行特征如表5所示,包括数据的扫描次数、比较次数、查询成本等;其中,各类查询成本由数据库查询计划得出。
[0097]
表5数据查询语句的执行特征
[0098][0099]
在另一个实施例中,性能瓶颈相关性分析及优化模块中的性能瓶颈相关性量化方
法是一种基于数据库查询代价模型来量化性能瓶颈相关程度的方法。
[0100]
通过统计sql语句中每个查询操作的执行代价,该方法计算了每个任务和每个查询操作的执行代价占比,用于表示任务与性能瓶颈的相关程度和查询操作与性能瓶颈的相关程度;性能瓶颈相关程度计算公式为:
[0101][0101][0102]
其中,taskrelation
i
表示n个并发任务中第i个任务与性能瓶颈的相关程度;operationrelation
i
表示查询操作与性能瓶颈的相关程度;querycost
i
表示第i个数据分析任务的查询代价;operationcost
i
表示第i个任务中具体操作的查询代价,例如数据读取操作、查询过滤操作、查询连接操作。
[0103]
更为具体的,由于同一条查询语句有多种执行方案,数据库的查询优化器比较了各类执行方案的查询代价,最终可筛选出查询代价最小的执行方案作为查询语句的实际执行方案,不同的关系型数据库将查询代价分为了io查询代价和cpu查询代价,例如postgresql数据库可以在配置文件中设定各类操作的io成本和cpu成本,而mysql数据库在源码上对查询代价模型进行了大量重构,将查询代价分为了server层查询代价和engine层查询代价,server层查询代价涉及了与cpu资源相关的查询操作的执行代价,而engine层查询代价涉及与io资源相关的查询操作的执行代价,相关查询代价信息如表6和表7所示。
[0104]
表6 server层查询代价
[0105][0106]
表7 engine层查询代价
[0107][0108]
更为具体的,各类关系型数据库所提供的获取查询语句执行方案和查询代价的工具大同小异,例如postgresql数据库和mysql数据库均使用explain format json关键字获
取sql语句的执行计划和查询代价。
[0109]
如图6所示,该关键字能够获取数据查询语句的总查询代价以及每个表的数据读取代价、条件过滤代价和表连接代价;其中,数据查询语句的总代价是所有步骤中查询代价的最大值。
[0110]
通过获取并发任务下每个数据分析任务的执行代价,相关性量化方法可以统计每个任务的查询代价以及并发任务中每一类操作的查询代价,并使用查询代价占比代表每个任务和每类查询操作与性能瓶颈的相关性。在并发任务环境下,不同sql语句的执行过程可能存在对同一个数据表相同的查询操作,量化此类查询操作的瓶颈相关性则需要将该操作在不同查询语句中的查询代价求和后计算得出。
[0111]
更为具体的,性能瓶颈相关性分析及优化模块包括基于启发式规则和性能瓶颈相关性的性能瓶颈优化策略,以实现在分析瓶颈问题的同时对具体的性能瓶颈问题提出性能优化建议。
[0112]
更为具体的,基于启发式规则的性能优化策略首先参考数据库运维人员提供的数据库查询优化经验,然后将这些经验推演为逻辑算法并添加到启发式规则库中,通过使用文本解析的方法提取sql语句的关键字和相关数据表的结构信息,并将解析结果发送至启发式规则库,然后使用启发式规则对查询语句结构特点进行逐一检查,最后自动化给出索引优化建议和查询改写优化建议。
[0113]
索引优化建议包括据库查询操作的索引添加规则以及查询优化器的索引选择原则,例如表连接、条件筛选、排序等。sql改写优化建议是对sql的基本书写规范进行审查,或是将查询语句中较为复杂的查询逻辑改写为简单的查询方式,例如某些相关子查询可改写为两表连接的方式。
[0114]
更为具体的,表8和表9展示了部分查询优化建议,包括提供各类优化建议的条件,并举例说明了具体优化方法。
[0115]
表8索引优化建议
[0116][0117]
表9查询改写优化建议
[0118][0119]
更为具体的,基于启发式规则的索引优化算法分析了sql语句的详细结构和执行过程,算法流程如图7所示,详细步骤如下:步骤
①
表示使用算法sql解析器和explain解析器将sql语句和查询计划进行解析,获取各类关键字与其对应的表字段信息;步骤
②
表示算法根据解析结果判定查询语句是否存在子查询,并设置标识变量f用于区分主查询和子查询;步骤
③
表示针对每个查询语句的表连接、条件查询、文件排序等操作进行启发式规则筛选;步骤
④
表示算法结合各类操作所涉及的字段以及表结构等信息提出相应的索引优化建议。
[0120]
更为具体的,为条件筛选字段提出索引优化建议时,需要考虑当前表是否参与连接操作,是否已经提出了相应的表连接索引优化建议;
[0121]
若排序字段由函数计算得出,则为排序操作添加的索引将会失效;
[0122]
条件查询中出现like关键字的前向通配符(like
″
%a”),索引失效;
[0123]
条件查询中参数比较包含隐式转换,即比较前后的字段类型不一致时索引失效;
[0124]
条件查询中使用函数修饰字段,索引失效;
[0125]
负向查询,例如not in,not like。负向查询不会使用到索引扫描。
[0126]
更为具体的,当同一张表中出现多个同类型优化建议的情况,例如当优化建议中出现了对同一张表中两个不同字段的等值查询优化建议时,优化策略首先会计算两个等值查询优化建议涉及的字段的索引基数,例如mysql数据库中的cardinality值,表示数据表字段中不同数值的个数,然后结合索引基数和瓶颈相关性对优化建议重要程度进行排序。
[0127]
与现有技术相比,本发明提供的一种面向并发数据分析任务的性能瓶颈分析系统的有益效果是:
[0128]
本发明提供了一种面向并发数据分析任务的性能瓶颈分析系统,通过pebao框架,用于对数据分析系统提供性能指标异常检测、任务性能瓶颈判定、瓶颈相关性分析和瓶颈优化建议;能够准确的分析任务与性能瓶颈的相关性,解决了运维人员难以准确还原瓶颈产生时的运行情况的问题,能够准确的定位性能瓶颈,并提供瓶颈分析报告。
[0129]
以上仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和
原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
