1.高级辅助驾驶及无人驾驶视场智能响应方法及系统,应用在高级辅助驾驶及无人驾驶领域,解决高级辅助驾驶中驾驶者观测反光镜场景时的低效问题,解决无人驾驶中安全员察看反光镜画面时的低效率问题;同时,适用于智慧城市应急指挥屏幕多窗口场景切换控制领域,解决智慧城市应急指挥中心屏幕多窗口场景手动切换操作时的繁琐问题。
背景技术:
2.目前,当汽车在驾驶中驾驶者通过反光镜或显示器观看后方情况,或通过直视方式观察侧面情况,通过显示器观察时需要提前设置显示的固定场景;同样,对于无人驾驶,驾驶座的安全员也采用上述方式观察道路情况并采取应急措施。显然,现有汽车驾驶中观察周围车辆情况的方式效率低下,并存在行驶安全隐患。
技术实现要素:
3.为解决上述问题,本发明设计了高级辅助驾驶及无人驾驶视场智能响应方法及系统,首先基于驾驶者的面部角度与眼部瞳孔位置计算视线投射点及区域,或通过机器学习方法结合历史数据及实时的面部角度与瞳孔位置预测视线投射区域及操控行为;其次,基于驾驶者视线投射区域,触发汽车计算机系统相应程序,并通过操控台前面板屏幕及音响予以提示。
4.系统包括软件、硬件,其中硬件由摄像头(分为判断视角投射区域的摄像头、采集车身周围环境的外置摄像头)、计算机、屏幕、音响组成(支持计算机、屏幕、摄像头、音响中的任意两个为一体,或三个以上为一体;同时支持计算机、屏幕、摄像头、音响相互分离)。方法分为视角投射区域判断方法、基于视角投射区域的响应方法。基于摄像头及屏幕前方(左前方、正前方、右前方)观看者的视角判断对焦区域,摄像头采集观看者的面部、眼部图像,计算机软件基于图像中的面部及眼部特征判断观看者在屏幕中的视角投射区域,进而触发计算机软件中的控件,控件实现视角投射区域的图像显示、切换以及大小调整操作,同时实现对应视角投射区域图像的音响播放。具体方法为:
5.一、视角投射区域判断方法,分为角度模型判断方法、机器学习判断方法,其中:
6.1、角度模型判断方法
7.第一步,计算观看者与摄像头的距离。根据摄像头焦距、观看者面部图像的大小计算距离,即d是观看者与摄像头的距离,w是观看者面部的宽度,p是观看者面部的像素宽度,f是摄像头焦距,w、p、f为已知。
8.设定屏幕中心点坐标、摄像头(镜头中心点)坐标、反光镜(镜面中心点)坐标,设观看者面部坐标u(x0,y0,z0),基于观看者面部在摄像头拍摄画面中的左右(相对于画面中心点的左右距离c
rl
)、上下(相对于画面中心点的上下距离c
ud
)位置、摄像头角度(摄像头感光元件所在平面与观看者的角度w,即将观看者面部正面看作平面r,平面r与感光元件所在平
面的角度即为w,平面r与基准平面b平行)计算x0、y0,观看者面部到基准面的距离即,观看者面部到基准面的距离即基于d0及设定已知的基准面z轴坐标(假设基准面z轴坐标全部为0)计算z0。假设摄像头感光元件也在基准面上,即感光元件与基准面平行且与基准面重叠。若感光元件与基准面不平行,则上述计算需要参考感光元件与基准面的夹角。基准面是虚拟的平面,例如在高级辅助驾驶领域,取车厢内驾驶与副驾驶前部的面板区域为基准面;在智慧城市应急指挥中心应用领域,取屏幕所在平面为基准面。
9.第二步,基于摄像头感光元件相对基准面的位置、摄像头的感光元件所在平面(假设感光元件在镜头后端,且镜头中心线与感光元件垂直,垂点是感光元件的中心点)相对于屏幕所在平面的夹角、摄像头镜头畸变、观看者在摄像头成像画面中的位置判断观看者面部在基准面上的投影位置即投影点坐标m(x1,y1)。
10.第三步,计算观看者面部(设面部为一平面)相对于基准面的倾斜角α以及观看者眼部瞳孔距离眼眶中心点的相对位置。
11.第四步,结合第一步、第二步、第三步计算观看者在基准面上的视角投射区域的中心点坐标a(x2,y2)。基于线段um、am的距离以及线段ua与um的夹角计算ua距离,根据两点坐标距离公式,进而计算a点坐标。
12.第五步,确定视角投射区域。将基准面分为多个虚拟窗口,a点坐标所在的虚拟窗口区域即为视角投射区域窗口;采用模糊靠近(误差宽松)原则,a点坐标最靠近的虚拟窗口为视角投射区域虚拟窗口。
13.2、机器学习判断方法
14.第一步,建立特征学习数据库。摄像头采集车辆驾驶座操控者的面部及眼部图像数据、车道变化数据,计算机分析学习面部、眼部图像数据,具体过程:1)采集驾驶者面部特征,识别驾驶者。人脸识别驾驶者的面部骨骼轮廓、皱纹线以及眼睛、鼻子、眉毛、嘴巴、眼镜的大小与形状,唯一确定驾驶者身份面部信息,并与乘坐者区分,计算机默认驾驶者为唯一观看者。2)采集驾驶者视角信息,建立模拟数据。驾驶者模拟真实驾驶车辆时的观察反光镜习惯,包括面部倾斜角度以及眼部看向反光镜时的状态。计算机通过摄像头采集驾驶者(即观看者)看向反光镜时的图像数据,并记录面部倾斜图像信息、瞳孔在眼眶中的相对位置图像信息。3)在真实驾驶环境中,计算机采集学习驾驶者视角信息。计算机、摄像头实时记录驾驶者的面部角度及瞳孔位置特征,同时计算机通过外置摄像头采集车身前后车道线及周围车辆图像数据,通过车道线及追踪周围车辆相对于本车的位置变化识别变道超车、归位(返回行驶车道)行为,计算机提取并学习变道超车、归位前的驾驶者面部角度、眼部瞳孔位置变化数据,该变化数据假设为驾驶者观看左、右反光镜时的面部及眼部特征,该特征数据对上述2)中的模拟数据进行纠正。除上述变道超车、归位行为外,也包括减速、加速、刹车行为,在此统称为变道、变速行为。
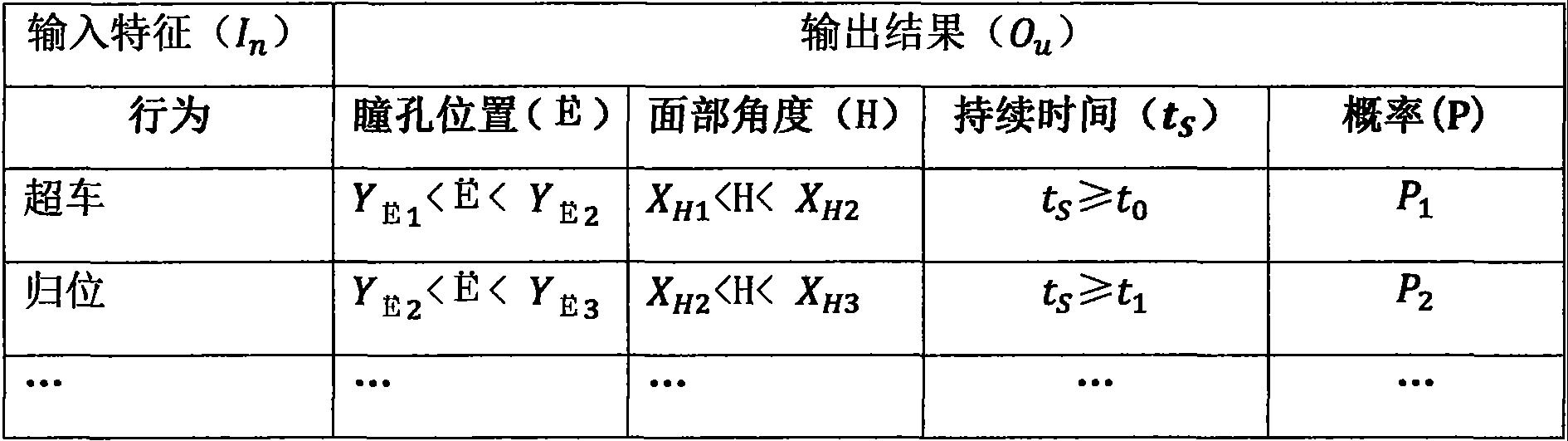
15.与此同时,并基于变道、变速前的驾驶者面部角度、眼部瞳孔位置变化数据,查询行车过程中无变道、变速行为但驾驶者有相似(设定相似度)或相同的面部角度、眼部瞳孔位置的图像数据。将面部角度、眼部瞳孔位置、持续时间(保持相同面部角度、眼部瞳孔位置的连续时间)数据分类,计算相同面部角度与眼部瞳孔位置以及相同持续时间特征时的变道、变速细分行为概率。如表1所示,机器学习输入输出对应表。
16.表1
[0017][0018]
第二步,分析预测,基于驾驶者面部及眼部特征数据预测观看行为。基于机器学习判断方法第一步中的特征学习数据库以及当前驾驶环境中的驾驶者面部角度、瞳孔位置(眼部虹膜瞳孔与眼眶中心点的距离)、持续时间实时数据计算当前驾驶者查看车身侧面及后面的具体行为概率。表2是机器学习预测模型输入输出对应表,输入设定概率、面部角度与眼部瞳孔位置、持续时间特征组合决定输出结果,表2中输入数据中面部角度、瞳孔位置、持续时间为实时数据,概率p0为预先设定值。
[0019]
表2
[0020][0021]
二、基于视角投射区域的响应方法
[0022]
第一种方法,基于上述1、角度模型判断方法,假设车辆反光镜也在基准面内,当视角投射中心点坐标位于车辆反光镜所在的虚拟网格内时,判断结果为视角投射区域是反光镜,并区分左、右反光镜。通过设定观看者的坐标(x0,y0,z0)范围确定驾驶者,基于驾驶者的视角投射区域及持续时间响应相关触发事件,触发事件包括图像显示与音响播放。例如,当视角投射区域为右侧反光镜且大于设定持续时间时,则计算机通过屏幕显示外置摄像头采集到的车身右侧尾部周围道路及车辆图像信息,该图像信息模拟仿真右反光镜图像信息。与此同时,与图像显示关联对应,计算机通过音响播放车身右侧尾部周围的车辆情况(如:右后方5米处有车辆行驶,或不同频率、幅度、长度的鸣笛声代替危险警示级别)。同样原理,当视角投射区域为左反光镜时,显示器将模拟显示左后方的图像信息;当视角投射区域为中反光镜(正后方的镜像)时,显示器模拟显示正后方的图像信息。支持右反光镜、左反光镜、中反光镜虚拟存在,假设其均位于基准面上的某一虚拟窗口,以投射区域所属的具体虚拟窗口作为事件响应触发点,事件响应包括显示器显示内容、音响播放音频。
[0023]
第二种方法,基于上述2、机器学习判断方法,当驾驶者观察反光镜时,基于表2中的输入值输出(预测)结果o
u
,根据超车、归位、减速、加速中的具体一个输出结果,响应对应的触发事件,具体为:当判断结果为超车时,显示器显示车辆左后方(或右后方,根据交通法则)超车道的视频(或模拟动画)画面,同时音响播放特定频率及幅度音频信号;当判断结果
为归位时,显示器显示车辆右后方(或左后方,根据交通法则)行驶车道的视频(或模拟动画)画面,同时音响播放特定频率及幅度音频信号;当判断结果为减速(非变道)时,显示器显示车辆正后方车道的视频(或模拟动画)画面,同时音响播放特定频率及幅度音频信号;当判断结果为行驶车道加速(非超车)时,显示器显示车辆左侧(或右侧,根据交通法则)超车道的视频(或模拟动画)画面,同时音响播放特定频率及幅度音频信号。
附图说明
[0024]
图1是高级辅助驾驶及无人驾驶视场智能响应方法及系统实施示意图,符号释义如下:
[0025]
abcd:基准面(显示器、音响包含于基准面内);
[0026]
ageo:虚拟窗口1,对应图1中的数字1;
[0027]
cheo:虚拟窗口2,对应图1中的数字2;
[0028]
gobf:虚拟窗口3,对应图1中的数字3;
[0029]
ohfd:虚拟窗口4,对应图1中的数字4;
[0030]
u:观看者的面部及眼部;
[0031]
m:驾驶者(观看者)在基准面的视角投影点;
[0032]
a:驾驶者(观看者)在基准面的视角投射区域中心点;
[0033]
v:摄像头;
[0034]
5:计算机。
[0035]
虚线为观看者的面部及眼部u、观看者在基准面的视角投影点m、观看者在基准面的视角投射区域中心点a的连接线,u、m、a三点组成直角三角形δuma,um
⊥
am。
[0036]
图2是高级辅助驾驶及无人驾驶车辆超车示意图,图中的两个v代表车辆v在两个时刻的不同位置,示意车辆v完成一次超车,v2是被超越车辆;黑线b1、b2是道路两侧边界线,虚线l1、l2是车道分界线,b1与l1之间是超车道,l1与l2之间是行车道,l2与b2之间是应急停车道。
具体实施方式
[0037]
如图1所示,假设左反光镜所在区域为虚拟窗口1,摄像头v采集观看者的面部及眼部u的图像信息并将数据传向计算机5,计算机5控制显示器的显示内容及音响的播放内容,具体基于观看者的面部及眼部u在基准面的视角投射区域中心点a坐标及持续时间,当a点坐标位于虚拟窗口1时,则计算机5通过显示器及音响提示车辆左后方车道车辆信息。
[0038]
如图2所示,车辆v在超车过程中,通过机器学习算法学习驾驶者(或驾驶位乘客)的面部角度、瞳孔位置、持续时间与变道、变速具体行为之间的联系,进而基于行驶中驾驶者的面部角度、瞳孔位置、持续时间数据预测具体行为,并通过显示器、音响智能提示与驾驶者行为相关联的必要信息。具体机器学习算法为:
[0039]
应用机器学习方法中的感知机学习算法,即:
[0040]
输入:训练数据集t={(x1,y1),(x2,y2),(x3,y3),...,(x
n
,y
n
)},其中x
i
∈x=r
n
,y∈y={
‑
1, 1},i=1,2,...,n;学习率η(0<η≤1);
[0041]
输出:w,b;感知机模型f(x)=sign(w.x b)。
[0042]
①
选取初值w0,b0[0043]
②
在训练集中选取数据(x
i
,y
i
)
[0044]
③
如果y
i
(w.x
i
b)≤0
[0045]
w
←
w ηy
i
x
i
[0046]
b
←
b ηy
i
[0047]
④
转至
②
,直至训练集中没有误分类点。
[0048]
通过学习历史数据构建最优化问题,即:min l(w,b)=
‑
∑y
i
(w.x
i
b)
[0049]
按照上述感知机学习算法求解w、b,η=1。y
i
是输出分类值,即确定驾驶者看向哪个区域(虚拟窗口)及驾驶者的操控行为,x
i
是输入指标的值,有两种方法确定x
i
,其一:x
i
是系数倍的面部角度与系数倍的瞳孔位置的和,即x
i
=ω
i
h
i
β
i
e
i
;其二:x
i
是面部角度,b是系数倍的瞳孔位置即b=β
i
e
i
。基于已知的面部角度与瞳孔位置数据、驾驶者视线投射区域及操控行为,最终确定w、b、ω
i
、β
i
的最优值。视线投射区域持续时间作为限定指标,即大于某一值有效,小于某一值则无效,学习过程中持续时间t
s
与预测时的触发持续时间t
r
关系为t
r
=μt
s
。μ是配置系数,0<μ<1。
[0050]
基于上述学习模型及实时的面部角度与瞳孔位置数据,预测驾驶者看向区域及操控行为,并基于看向区域及操控行为执行计算机对应程序,最终通过显示器、音响提示,以帮助驾驶者安全高效驾驶。
[0051]
对于公交车及出租车等公共用车,基于多个驾驶者操控习惯与面部及眼部特征之间的对应关系概率,预测当前驾驶者视线聚焦点。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。