用于在植物育种中实施资源的方法和系统
1.相关申请的交叉引用
2.本技术要求2019年3月28日提交的美国临时申请号62/825,513的权益和优先权。以上申请的全部公开内容通过引用并入本文。
技术领域
3.本公开总体上涉及用于在植物育种中实施资源的方法和系统,并且具体地涉及用于在植物育种背景中分配资源的方法和系统,其中所述分配基于种源的表现和/或遗传分布。
背景技术:
4.本部分提供了与本公开相关的背景信息,其不一定是现有技术。
5.在植物发育中,经常通过选择性育种或遗传操作在植物中进行修饰。基于特定的选择或操作,将所得的植物材料引入育种流水线中,然后在育种流水线中产生、生长和测试植株。当植株的表现,例如对于给定表型,处于或高于预期阈值时,或处于最高表现时,或例如,在基因型的频率处于或高于特定阈值时等,可认为所述植株是要推进到进一步开发和/或商业实施的靶标植株。
附图说明
6.本文描述的附图仅用于所选实施方案的说明目的,而不是所有可能的实施方式,并且不旨在限制本公开的范围。
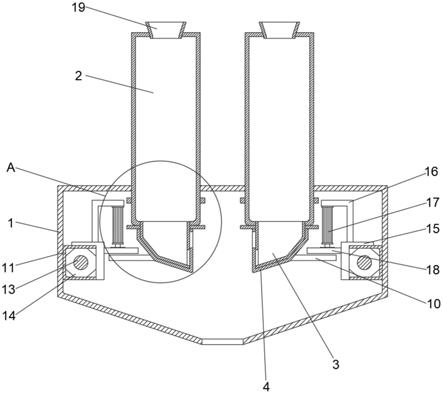
7.图1是适于至少部分地基于表型和/或基因型信息在植物育种流水线内分配资源的本公开的示例性系统;
8.图2是多个种源对的性状表现概率分布的示例性图示,所述性状表现概率分布形成图1的系统中的资源分配的基础;
9.图3是可以在图1的系统中使用的示例性计算设备的框图;以及
10.图4是适用于图1的系统的示例性方法,用于至少部分地基于表型和/或基因型信息在植物育种流水线内分配资源。
11.在整个附图的几个视图中,对应的附图标记指示对应的部件。
具体实施方式
12.现将参考附图更全面地描述示例性实施方案。本文包括的描述和具体实例仅旨在用于说明的目的,而不旨在限制本公开的范围。
13.在农业工业中通常采用各种育种技术来生产所需植株。对于每一种技术,以及与这些技术相关联的每一个过程,都会使用资源,无论是在产生植物材料、生长植物材料还是测试植物材料中。包括在植物育种流水线中的一些这样的资源包括但不限于土地如田地行和田地块、温室空间、基因分型实验室单位和双单倍体单位(dhu)。例如,当选择一定数量的
种源进行双单倍体(dh)过程时,该过程的能力(由运行该过程所需的任何田地、实验室、人力、金钱等或其他资源决定)可分成单个单元(在这种情况下为dhu),然后在所选种源之间均匀分布。例如,在选择200个种源并且1,000个dhu可用的情况下,如果dhu资源在它们之间划分,则每个种源被分配5个dhu。然而,这种均匀分布没有考虑不同种源的潜在值或不同种源内潜在遗传/表型变异的任何变化。
14.独特地,本文的方法和系统基于种源的一个或多个表型和/或基因型特征在育种流水线内分配资源。具体地,决策引擎采用算法,所述算法考虑了种源的性状表现的概率(例如,表达为二项式分布等),以及与所选种源的队列相关联的风险和/或基因型组分和/或多样性。还可以通过模拟遗传/表型变异来预测给定种源的潜在值的变化。通过此算法,用于育种过程的可用资源在种源之间分配,更多的资源专用于以下种源:这些种源具有更高的产生表现高于一个或多个阈值的后代的可能性和/或更高的产生以认为适合和/或期望用于育种流水线的比率表达某些遗传组分的后代的可能性。以这种方式,通过更有效地分配资源来改进育种流水线(作为本文的方法和系统的实际应用),以产生高表现和/或遗传上更适合的后代。
15.因此,后代通常是来自相同物种(即种源)的一个或多个亲本生物体之间杂交的生物体。后代可指例如,来自特定育种程序的所有可能后代的集合、特定于一个或多个种源的所有可能后代的子集、来自给定世代中一个种源的所有后代、来自一种源的某些后代等。此外,如本文所用,术语“种源”是指后代的亲本的集合,并且因此在适用时解释为单数或复数。表型数据、性状分布、原种、遗传序列、商业成功和关于后代的附加信息是已知的或可被模拟并可存储在本文所述的存储器中。
16.如本文所用,“表型数据”包括但不限于关于给定后代(例如一株植株等)或后代群体(例如一组植株等)的表型的信息。表型数据可以包括后代的大小和/或饱满度(heartiness)(例如,植株高度、茎围、茎强度等)、产量、成熟时间、对生物胁迫的抗性(例如,疾病或害虫抗性等)、对非生物胁迫的抗性(例如,干旱或盐度抗性等)、生长气候或任何另外的表型和/或其组合。
17.应当理解,本文的方法和系统通常涉及与一个或多个种源、后代等相关联的表型数据和相关的表型方差。也就是说,应当理解,在一个或多个示例性实施方式中,可以使用基因型数据以代替、结合或组合本文所述的表型数据(或以其他方式)(例如,以进一步补充表型数据和/或进一步通知本文的模型、算法和/或预测等),以帮助选择后代组和/或鉴定符合本文描述的后代集合。这可以采取使用算法的形式,例如,以从与给定杂交相关联的已知或模拟基因型数据预测所述杂交的表型值和/或方差。
18.图1示出了用于至少部分地基于已知或模拟的表型和/或基因型信息在植物育种流水线内分配资源的示例性系统100,并且在所述系统中可以实施本公开的一个或多个方面。尽管在所描述的实施方案中,系统100的各部分以一种布置呈现,但其他实施方案可包括以其他方式布置的相同或不同部分,这取决于(例如)用于分配给后代的可用资源、种源的数量、种源的特定类型、后代的特定类型、感兴趣的基因型和/或感兴趣的表型等。
19.如图1所示,系统100通常包括育种流水线102,其被提供来推进种源、后代等通过测试和选择,至进一步开发和/或商业用途。通常,育种流水线102限定金字塔形进程,其中输入大量潜在种源,然后将其连续减少(例如,向下选择等)至优选或期望数量的种源、后代
或植株。虽然育种流水线102被配置来在其中分配资源,如本文提供的,但是育种流水线102可以被配置来采用一种或多种其他技术,这些技术可以包括本领域已知的多种方法来在育种流水线102内产生、选择或推进种源或后代,这通常取决于为其提供育种流水线102的特定植物和/或生物体。
20.在某些育种流水线实施方案(例如,大型工业育种流水线等)中,测试、选择和/或推进决策可以针对在多个阶段中和在若干年中的若干位置处的成百上千或更多的种源、后代等,以得到一组减少的种源、后代等,然后将其选择用于商业产品开发。简而言之,所说明的育种流水线102通过包括在其中的测试、选择等被配置来将大量的种源、后代等减少到相对少量的表现优异的商业产品。
21.在此示例性实施方案中,育种流水线102可以参考玉米或玉蜀黍及其性状和/或特征进行描述并大体针对玉米或玉蜀黍及其性状和/或特征。然而,应当理解的是,文中公开的系统和方法不限于玉米并且可以用于与其他植物相关的植物育种流水线/程序中,例如以改良任何水果、蔬菜、草、树或观赏作物,包括但不限于玉蜀黍(zea mays)、大豆(glycine max)、棉花(gossypium hirsutum)、花生(arachis hypogaea)、大麦(hordeum vulgare);燕麦(avena sativa);果园草(dactylis glomerata);水稻(oryza sativa,包括籼稻和粳稻品种);高粱(sorghum bicolor);甘蔗(saccharum sp.);高羊茅(festuca arundinacea);草坪草物种(例如,物种:agrostis stolonifera、poa pratensis、stenotaphrum secundatum等);小麦(triticum aestivum)和苜蓿(medicago sativa)、芸苔(brassica)属成员,包括西兰花、卷心菜、花椰菜、油菜和油菜籽、胡萝卜、白菜、黄瓜、干豆、茄子、茴香、四季豆、葫芦、韭葱、莴苣、瓜、秋葵、洋葱、豌豆、胡椒、南瓜、萝卜、菠菜、西葫芦、甜玉米、西红柿、西瓜、蜜瓜、甜瓜和其他瓜、香蕉、蓖麻、椰子、咖啡、黄瓜、杨树、南方松、辐射松、花旗松、桉树、苹果和其他树种、橙子、葡萄柚、柠檬、酸橙和其他柑橘、三叶草、亚麻籽、橄榄、棕榈、辣椒、胡椒和甜椒、甜菜、向日葵、枫香、茶、烟草和其他水果、蔬菜、块茎和块根作物。本文的方法和系统也可与非作物物种,尤其是用作模型方法和/或系统的那些(如拟南芥属(arabidopsis))结合使用。此外,本文公开的方法和系统可以用于植物之外,例如用于动物育种程序或其他非植物和/或非作物育种程序。
22.如图1所示,育种流水线102包括种源开始阶段104和栽培与测试阶段106,它们一起鉴定和/或选择一个或多个种源或后代,用于推进到验证阶段108。然后,在验证阶段108中,将后代作为后代、品系或杂交种引入预商用测试,例如,取决于后代的特定类型,或其他合适的过程(例如,表征和/或商业开发阶段等),最终目标和/或靶标是种植和/或商业化后代。因此,应当理解,在图1所示的三个不同阶段104、106和108中,育种流水线102可以包括本领域技术人员已知的各种常规过程。
23.在种源开始阶段104中,例如基于种源选择系统和/或(至少部分地)基于在申请人共同拥有的题为“methods for identifying crosses for use in plant breeding”的美国专利申请15/618,023(其全部公开内容通过引用并入本文)中公开的方法和系统,将潜在种源库减少到所选的一组种源。应了解,可采用其他选择技术来在种源开始阶段104中选择种源,其可基于与种源相关联的各种数据和/或关于种源的预测等。
24.一旦选择了种源,就将所选的种源引导至栽培与测试阶段106,在这个阶段中,将后代种植或以其他方式引入一个或多个生长空间中,诸如例如温室、阴棚、苗圃、育种地块、
田地(或测试田地)等。应当理解,栽培与测试阶段106包括一定量资源以生长和测试所选种源的后代。这些资源可以包括例如,双单倍体单元或dhu,它们是生长和测试种源的后代所需的资源。应当理解,其他资源可以包括在栽培与测试阶段106中,并适应本文所述的技术。此处,栽培与测试阶段106内的资源通常由分配引擎110分配给在所选种源中鉴定的种源对,如下所述。
25.一旦后代在栽培与测试阶段106中生长,就对每个后代进行测试(在此实例中再次作为栽培与测试阶段106的一部分)以推导和/或收集后代的表型和/或基因型数据,从而将表型和/或基因型数据存储在一个或多个数据结构中。可以通过这样的测试评估的表型的常见实例包括但不限于抗病性、非生物胁迫抗性、产量、种子和/或花的颜色、水分、大小、形状、表面积、体积、质量和/或种子的至少一种组织中的化学物质的量,例如胚、胚乳或其他种子组织中的花色素苷(anthocyanin)、蛋白质、脂质、碳水化合物等。例如,当一种后代(例如,从种子等栽培的)被选择或以其他方式被修饰以产生特定化学物质(例如,药物、毒素、香料等)时,可对所述后代进行测定以量化所需化学物质。
26.当基于表型和/或基因型数据以及各种阈值和/或基础认为后代成功时,将后代推进到验证阶段108,在这个阶段中将后代暴露于预商用测试或其他合适的过程(例如,其表征和/或商业开发阶段等),目标和/或靶标是种植和/或商业化后代。也就是说,然后可以使这组后代经历一种或多种另外的/进一步的测试和/或选择方法、性状整合操作、与其他自交系的杂交和/或膨化技术,以使这些后代或基于其的植物材料准备用于进一步的测试和/或商业活动。
27.再次提及资源的分配,并继续参考图1,分配引擎110包括(和/或与之相关联)至少一个计算设备,其可以是独立的计算服务,或者可以是与一个或多个其他计算设备集成的计算设备。分配引擎110然后通过计算机可执行指令和/或本文提供的一个或多个算法(或其变体或其他)被配置来执行本文所述的操作,例如,作为在育种流水线102中分配资源的一部分。
28.此外,系统100进一步包括耦合到分配引擎110的种源数据结构112。在此示例性实施方案中,种源数据结构112包括与种源以及进一步与原种和/或相关种源、后代等有关的数据。所述数据可以包括与例如植物材料的种源、植物材料的测试等有关的后代、种源等的各种类型的数据。包括在数据结构112中的一种示例类型的数据是种源的遗传标记数据,其追溯到两年、三年、五年、六年、十年或更多年等。更一般地,数据结构112可以包括符合当前生长/测试周期的数据,并且可以包括与先前生长/测试周期有关的数据。例如,数据结构112可以包括指示植株经过栽培与测试阶段106或者包括在育种流水线102内或外的其他生长空间的当前和/或最近一年、两年、五年、十年、十五年或更多年或更少年的植株的各种不同特征和/或性状的数据,并且还呈现来自栽培与测试阶段106的数据。
29.通常,种源数据结构112包括已经对种源进行测量、模拟或两者的表型数据,利用这些数据可以产生每个种源的表型方差。
30.图2中示出了此类方差的示例。曲线202表示第一种源对的已知或模拟表型方差,曲线204表示不同的第二种源对的已知或模拟表型方差。在此实例中,第一种源对包括在所包括的亲本之间的低双亲本遗传相似性,使得所述组合通常将基于可能发生重组的基因座数量产生多样性的一组后代。相反地,第二种源对包括在其亲本之间的相对高的双亲本相
似性,使得所述组合通常将基于可能发生重组的减少的基因座数量产生较少多样性的一组后代(与前一个种源相比)。
31.如图2所示,产生更高表现后代的更大概率(例如通过模拟预测的)与曲线202的种源对相关联,因为所述曲线包括超过表现阈值206的在右端的更大曲线下面积。在此实例中,更大的x轴值指示更高表现的后代,并且曲线202具有超过阈值206的更大曲线下面积的事实指示其具有在该表现区域中产生后代的更大可能性。在分配资源以产生育种群体之前,可以通过模拟来预测此类方差。基于所预测的后代表现,可以以优化的方式分配育种资源,以增加在流水线内产生更高表现后代的概率。
32.在此示例性实施方案中,分配引擎110被配置来依赖于已知或模拟的表型方差,对于给定的一组种源对,在种源对之间分配用于育种过程的可用资源。具体地,分配引擎110被配置来采用下面提供的算法,如方程(1),并且最小化或减少输出(整个资源分配的不同排列)。
[0033][0034]
上述方程被独特地构造来指示资源分配。它包括三个主要项,其分别包括表现风险和多样性λ3‖ti
h
x
‑
ξ‖1,其中对于给定的一组种源,期望将方程(1)最小化或相对最小化。每个项包括加权变量λ1、λ2和λ3,其基于决策标记的偏好、通过历史成功的挖掘、机器学习方法、随机机会和/或任何其他适当的方法来确定。在通过上述方程获得该组种源之后,可以基于每个单独育种群体的已知或模拟的后代表现在种源之间确定资源分配。与此相关,预期x
i
可通过给定群体的方差和育种者对亲本表现的知识来调节,以确保产生所需和/或增强表现的后代。
[0035]
除了权重,方程(1)的第一项描述了第i个种源θ
i
的育种值的表现将大于靶标阈值η的概率。这是性状表现和/或表达某些遗传组分的概率的概率分布。例如,所述项可以表示来自种源θ
i
的后代展现出大于所需产量阈值η
yld
的产量的概率,或来自种源θ
i
的后代展现出大于所需茎直立性阈值η
stlk
的茎直立性的概率。这甚至可以适用于更明显的二元特征,诸如特定单倍型的存在或不存在,在这种情况下,概率分布可以采用二项式形式,而阈值η可以发挥指示二元结果的更微不足道的作用。
[0036]
例如,在图2中,两个给定(种源)群体的性状值的概率分布表示为不同种源的两条曲线202、204,即由曲线202引用的第一种源或种源_1和由曲线204引用的第二种源或种源_2。通过已知或模拟的表型数据获得的值是特定种源产生的后代的潜在分布,其与由所述种源产生的任何给定后代所展现的该值的对应概率一起显示,或通常是二项式分布。例如,沿x轴的值可以是任何感兴趣的性状,诸如例如产量值等,而沿y轴的值可以是在x轴上给定的性状值处的概率密度。继续参考图2,当阈值或η被设置为例如值114时(如虚线参考206所示),基于所示的曲线确定值高于阈值的种源的概率。这通常被理解为在114值处阈值的右侧的曲线下面积。然后将概率乘以x
i
,其是要分配给第i个种源的资源(例如,dhu的数量等)。
[0037]
方程(1)的第二项包括与对第i个种源分配资源相关联的风险。具体地,所述风险再次基于第i个种源θ
i
的育种值将大于靶标阈值η的概率。然而,风险概率被包括作为育种
值的方差(即,),例如,如图2中的曲线所示。这再次乘以x
i
,其是要分配给第i个种源的资源(例如,dhu的数量等),其进一步乘以u
i
,其是第i个种源的基因型和表型学习中的置信水平。此置信水平u
i
可以最好地理解为,基于已经收集的关于第i个种源的多少数据、第i个种源的遗传背景在任何相关训练集中表示程度如何,以及此过程中涉及的任何分析、预测模型等的潜在置信/误差区间,可以给予归因于第i个种源的已知或模拟的基因型和表型值和分布多少置信度(例如,如图2所示)。置信水平u
i
提供量化与对特定种源的资源分配相关联的风险的基础。风险可进一步考虑指示风险的性状,诸如例如稳定性、抗病性等。
[0038]
方程(1)的第三项包括对第i个种源的资源分配所包括的种源的多样性。具体地,将从后代杂种优势群到种源杂种优势群的转移概率矩阵t乘以用于将种源杂种优势群映射到种源的关联矩阵i
h
和所选种源x。然后将此减去育种目标的靶标组合ξ。实际上,第三项表示所选种源与靶标组合的偏差。
[0039]
在所述示例性实施方案中,方程(1)由分配引擎110使用,并受若干条件约束。首先,x是正整数,如下文方程(2)所示,并且在下列方程中使用的y是x的指示符,如方程(3)所示。
[0040][0041]
y∈{0,1}
ꢀꢀꢀ
(3)
[0042]
作为指派给每个第i个种源的资源量的x的总和必须等于n,n是要通过方程(4)指派的资源单位(例如dhu、田地地块、温室中的盆栽、实验室资源等)的总数。换言之,当提供1000个dhu以在方程(1)中分配时,每个dhu必须被指派给一个种源。并且,方程(5)规定y的总和必须等于所选种源的总数m。即,一组种源被标识为要为其分配资源的方程(1),并且方程(1)必须对每个种源分配至少一个资源,使得每个种源以y表示。
[0043]1t
x=n
ꢀꢀꢀ
(4)
[0044]1t
y=m
ꢀꢀꢀ
(5)
[0045]
除上述之外,方程(6)对分配给第i个种源的资源数量施加上限u
upper
和下限u
lower
,并且方程(7)相对于上限对x和y施加限制。
[0046]
u
lower
≤x≤u
upper
ꢀꢀꢀ
(6)
[0047]
x/u
upper
≤y≤x
ꢀꢀꢀ
(7)
[0048]
如下所述,还通过方程(8)和(9)施加了性别限制。具体地,对所分配的资源y求和的种源的雄性关联向量m必须大于或等于所选种源的数量m乘以由育种者或以其他方式设定的雄性性别阈值α
m
。基于育种流水线102的状态和/或未来靶标,将阈值设定为百分比,诸如例如40%、60%或其间的百分比、或另一百分比。同样地,对所指派的资源y求和的种源的雌性关联向量f必须大于或等于所选种源的数量m乘以由育种者或以其他方式设定的雌性性别阈值α
f
。
[0049]
m
t
y≥mα
m
ꢀꢀꢀ
(8)
[0050]
f
t
y≥mα
f
ꢀꢀꢀ
(9)
[0051]
并且最后,在此示例性实施方案中,方程(10)对亲本的出现次数施加了限制,其中对所指派的资源y求和的种源的亲本关联向量i
p
必须小于或等于所选种源的数量m乘以由
育种者或以其他方式设定的亲本阈值α
p
。基于育种流水线102的状态或决策偏好,将亲本阈值α
p
设定为百分比,诸如例如5%或另一百分比,以便确保在育种流水线中存在所需的和/或健康量的多样性,以用于未来的遗传增益。
[0052]
i
p
y≤mα
p
ꢀꢀꢀ
(10)
[0053]
尽管上文在方程的情形中进行了描述,但是在表1中提供了包括在方程(1)
‑
(10)中的变量和/或项以及变量和/或项的定义。应当理解,项和变量不严格限于下面的定义,而是包括任何和所有容易理解的方差,如本领域技术人员所理解的。
[0054]
表1
[0055][0056][0057]
分配引擎110被配置来然后求解上述方程,其实际上基于表现、风险和多样性在种源之间分配资源,例如dhu等。当分配引擎110确定分配时,分配引擎110进一步被配置来按种源向一个或多个育种者输出或传送分配。作为响应,然后育种者在流水线102中对种源使用资源,如分配引擎110提供的分配所定义的那样,从而填充育种流水线102。
[0058]
此外,应当理解,分配引擎110可被配置来提供(例如,生成并使得在育种者的计算设备处显示等)用户界面和/或响应于用户界面,育种者(广义地讲,用户)能够通过所述用户界面提供一个或多个输入,分配引擎110随后依赖于所述一个或多个输入来进行种源之间的资源分配。可提供用户界面来接收输入:直接在与育种者相关联的计算设备(例如,如下所述的计算设备300等)处,在所述计算设备中采用了分配引擎110,或经由远程用户(同样,可能是育种者)能够通过其与分配引擎110交互的一个或多个基于网络的应用程序(例如,应用程序编程接口(api)等),等。
[0059]
图3示出了可以在系统100中,例如与育种流水线102的各个阶段结合,或与分配引擎110和/或后代数据结构112等结合使用的示例性计算设备300。例如,在育种流水线102的不同部分,育种者或其他用户与符合计算设备300的计算设备交互,以在后代数据结构112中输入数据和/或访问数据,以支持由这样的育种者或其他用户做出/完成的育种决策和/或测试。与此相关,系统100的分配引擎110包括符合计算设备300的至少一个计算设备和/或在其中被实施。与此相关,计算设备300可以通过可执行指令独特地或特定地被配置来实
施本文关于分配引擎110所述的各种算法和其他操作。应当理解,如本文所述,系统100可包括符合计算设备300或不同于计算设备300的各种不同的计算设备。
[0060]
示例性计算设备300可包括例如一个或多个服务器、工作站、个人计算机、膝上型计算机、平板计算机、智能电话、其他合适的计算设备、其组合等。此外,计算设备300可包括单个计算设备,或者其可包括位置紧邻的或分布在一个地理区域上并经由一个或多个网络彼此耦合的多个计算设备。这样的网络可以包括但不限于因特网、内联网、专用或公共局域网(lan)、广域网(wan)、移动网络、电信网络、其组合或其他合适的网络等。在一个实例中,系统100的后代数据结构112包括至少一个服务器计算设备,而分配引擎110包括至少一个独立的计算设备,其直接和/或通过一个或多个lan等耦合到后代数据结构112。
[0061]
因此,所示的计算设备300包括处理器302和耦合到处理器302(并与其通信)的存储器304。处理器302可包括但不限于一个或多个处理单元(例如,多核配置等),包括中央处理单元(cpu)、微控制器、精简指令集计算机(risc)处理器、专用集成电路(asic)、可编程逻辑器件(pld)、门阵列和/或能够实现本文所述功能的任何其他电路或处理器。上述列举仅是示例性的,因此不旨在以任何方式限制处理器的定义和/或含义。
[0062]
如本文所述,存储器304是使诸如可执行指令和/或其他数据的信息能够被存储和检索的一个或多个设备。存储器304可以包括一个或多个计算机可读存储介质,诸如但不限于动态随机存取存储器(dram)、静态随机存取存储器(sram)、只读存储器(rom)、可擦除可编程只读存储器(eprom)、固态设备、闪存驱动器、cd
‑
rom、拇指驱动器、磁带、硬盘和/或任何其他类型的易失性或非易失性物理或有形计算机可读介质。存储器304可被配置来存储但不限于后代数据结构112、表型数据、测试数据、种源数据(例如,性状表现分布等)、权重、阈值和/或适于如本文所述使用的其他类型的数据(和/或数据结构)等。在各种实施方案中,计算机可执行指令可存储在存储器304中供处理器302执行,以使处理器302执行本文所述的一个或多个功能,使得存储器304是物理的、有形的和非暂时性计算机可读存储介质。这样的指令通常改善执行本文中各种操作中的一个或多个操作的处理器202的效率和/或性能。应当理解,存储器304可以包括各种不同的存储器,每个存储器在本文所述的一个或多个功能或过程中被实施。
[0063]
在所述示例性实施方案中,计算设备300还包括耦合到处理器302(并与其通信)的输出设备306。输出设备306例如通过显示和/或以其他方式输出来向计算设备300的用户(例如,育种者等)输出或呈现信息,诸如但不限于所选后代、作为商业产品的后代和/或所需的任何其他类型的数据。还应当理解,在一些实施方案中,输出设备306可以包括显示设备,使得各种界面(例如,应用程序(基于网络的或以其他方式的)等)可以显示在计算设备300处,并且具体地显示在显示设备处,以显示这样的信息和数据等。并且,在一些实例中,计算设备300可以使得界面显示在另一计算设备的显示设备处,所述另一计算设备包括例如托管具有多个网页的网站的服务器,或与在所述另一计算设备处采用的web应用程序交互等。输出设备306可以包括但不限于液晶显示器(lcd)、发光二极管(led)显示器、有机led(oled)显示器、“电子墨水”显示器、其组合等。在一些实施方案中,输出设备306可以包括多个单元。
[0064]
计算设备300进一步包括从用户接收输入的输入设备308。输入设备308耦合到处理器302(并与其通信),并且可以包括例如键盘、指点设备、鼠标、触笔、触敏面板(例如,触
摸板或触摸屏等)、另一计算设备和/或音频输入设备。此外,在一些示例性实施方案中,触摸屏,诸如包括在平板计算机或类似设备中的触摸屏,可以用作输出设备306和输入设备308两者。在至少一个示例性实施方案中,可以省略输出设备306和输入设备308。
[0065]
此外,所示的计算设备300包括耦合到处理器302(以及在一些实施方案中还耦合到存储器304)(并与其通信)的网络接口310。网络接口310可以包括但不限于有线网络适配器、无线网络适配器、电信适配器或能够与一个或多个不同网络通信的其他设备。在至少一个实施方案中,网络接口310用于接收计算设备300的输入。例如,网络接口310可以耦合到野外数据采集设备(并与之通信),以便采集如本文所述使用的数据。在一些示例性实施方案中,计算设备300可以包括处理器302和结合到处理器302中或与处理器302结合的一个或多个网络接口。
[0066]
图4示出了在后代鉴定过程中选择后代的示例性方法400。示例性方法400在本文中结合系统100来描述,并且可以全部或部分地在系统100的分配引擎110中被实施。此外,出于说明的目的,还参考图2中的分布和图3的计算设备300来描述示例性方法400。然而,应了解,方法400或本文所述的其他方法不限于系统100、图2中的分布或计算设备300。并且相反,本文所述的系统、数据结构和计算设备不限于示例性方法400。
[0067]
首先,育种者(或其他用户)最初鉴定植物类型(例如玉米、大豆等)和一种或多种所需表型,其可能符合所鉴定植物中待改进的一种或多种所需特征和/或性状,或符合商业植物产品中的所需表现。反过来,基于上述和/或一个或多个其他标准,育种者或用户单独地或通过各种过程选择多个种源作为起点。鉴于上述内容,可以通过任何合适的方式选择种源,再次包括通过本技术人共同拥有的美国申请号15/618,023中描述的方法,所述申请通过引用整体并入本文。
[0068]
在此示例性实施方案中,选择了200个种源,其可被称为“m”,并且可用资源包括1,000个dhu,其可被称为“n”。作为解释,这些数字可以提供1.323
×
10
215
个不同的可能方式来在200个种源之间分配1,000个dhu(其中每个种源包括在至少一个dhu中,并且进一步被允许包括在至多达最大数量的剩余资源中)。
[0069]
对于所选的多个种源,数据结构112包括代表种源的各种数据。在数据中,数据结构112包括性状表现分布,其通常提供种源包括性状的特定值的概率。概率通常基于测试和/或预测模型来确定,例如,所述模型在历史数据上训练,包括过去的遗传产品和感兴趣的特定性状的分布。例如,如图2所示,性状表现分布在曲线202和204处被示为两个种源的二项式分布,其指示相应种源以所指示的值表现的概率。因此,例如,第一种源或种源_1(在曲线202处标识)具有表现为104的0.08的概率,而第二种源或种源_2(在曲线204处标识)具有表现为107的0.03的概率。如图可见,在图2中,第二种源(或种源_2,在曲线204处标识)的高于示例性靶标阈值206(具有114的表现值)的表现的概率大于第一种源(或种源_1,在曲线202处标识)。应当理解,针对多个所选种源中的每一个,在数据结构112中包括本文所述的类型的概率的分布和/或其他表达。
[0070]
此外,数据结构112还包括遗传学习的置信水平,其在上文称为u
i
。此置信水平可以基于与给定种源相似的遗传物质出现在先前在育种流水线102中测试的集合中和/或用于训练在本文所述的整个育种过程和/或资源分配过程中使用的一个或多个合适的预测模型的历史数据集中的频率。置信水平进一步考虑所采用的一个或多个预测模型的稳健性,
其可以基于例如对种源的已知程度和/或种源按分布交付的置信度。简单地讲,此频率可以用于与训练集内的遗传家族的平均频率进行比较,以产生对模型中存在多少置信度的估计。例如,如果某个遗传家族在训练集内的表示频率为平均家族的1.5倍,则1.5可用作此特定品系的置信水平。同样,另一家族可以表示为0.75倍,并且这两个品系之间的杂交可以用u
i
=1.5x0.75=1.125来表征,其中种源的置信水平是亲本中置信水平的简单乘积。重要的是,应注意,遗传置信度也可以以更加复杂的方式推导出。例如,杂交的每个亲本的置信度可以作为整个种质库的贝叶斯分析的结果推导出。随后的种源置信度水平本身可以使用亲本置信度的更复杂的卷积推导出,或者甚至更直接地,可以从任何机器学习算法和/或模拟引擎的置信度输出推导出,所述机器学习算法和/或模拟引擎可能已经用于评估这个种源的预期育种值方差。
[0071]
此外,数据结构112包括例如由育种者在开始阶段104的开始时(或之后)设置的育种目标的靶标组合,其为ξ。靶标组合可以包括定义育种流水线102中的靶标、所需的或理想的种质库可以看起来如何的许多靶标和分布中的任一个。这些靶标中的一些可以包括整个育种流水线102上的性别(杂种优势库)分布、育种流水线102内不同种质簇的分布,以及在育种生命周期的不同阶段中的所需亲本分布(例如,以平衡使用年老的、经证实的亲本与具有较新遗传学的年轻的、未经证实的亲本;等)。对于一个示例概况,一名操作员可以决定流水线应当具有至少45%雄性系和45%雌性系,但是其余的可以按表现来选择,而同时,另一名操作员可以决定流水线中的种源必须是雄性和雌性杂种优势库之间完美的50/50分割。在又一个实例中,靶标概况可以基于特定育种流水线内种源的成熟期的分布。例如,如果流水线负责6天跨度的作物成熟期,则待添加到流水线的材料的潜在靶标成熟期概况可指示所有种源的25%应落在该跨度的最早2天内,50%应落在中间两天内,并且种源的25%应落在跨度的最后两天内。这样的靶标概况将有助于确保由具有这样的中亲本(mid
‑
parent)成熟期(两个亲本个体成熟度的平均值)的种源产生的大部分品系将落在流水线的六天窗口内。尽管有这些具体实例,但是应当理解,靶标概况可以包括育种者和/或与在分配中包括的种源之间分配资源相关联的人员所认为是期望的任何概况。
[0072]
可以以多种方式设置靶标。最简单地,可以通过人工输入以使育种流水线102与某些商业目标或限制一致来设置靶标。这些靶标可以被传送给数据科学家,然后被手动传输到分配引擎110中,或者可以通过使用基于web的用户界面或其他工具将它们存储在数据库或api中。随着更先进的分析和模拟的发展,可以基于计划、路线图或策略以算法方式设置靶标,所述计划、路线图或策略被确定为具有改进、利用和/或最大化育种流水线102和/或与所分配资源相关联的商业表现,并且潜在地,与给定植物的未来市场需求密切一致等的所需的和/或最高的可能性。靶标可以存储在数据库或api中,以便稍后由分配引擎110根据需要和/或要求来检索,以如本文所述执行。
[0073]
如图4所示,在方法400中的402,分配引擎110访问多个所选种源的包括在数据结构112中的数据。所述数据包括例如,每个所选种源的性状表现的概率分布。对于每个种源,其他数据可以包括性别数据、亲本和/或杂种优势数据等。
[0074]
然后,分配引擎110在404处确定多个所选种源的可用资源(即,在此实例中为1,000个dhu)的资源分配。具体地,在此示例性实施方案中,分配引擎110采用方程(1)的分配算法(复制如下)。应当理解,在其他方法实施方案中,可以采用不同的算法(无论是否从方
程(1)推导出)来在一组种源之间分配可用资源。
[0075][0076]
如上所述,方程(1)的算法包括三个项,其通常涉及表现、风险和多样性。
[0077]
重要的是,应注意,本文所述的资源分配过程不仅可以应用于高层决策,例如如何分配dhu或如何分配测试地块,而且还可以应用于辅助决策和子决策。例如,即使如上所述,基于对不同种源的已知或模拟表型数据的表现(例如,产量等)分布如何指示它们的后代将达到或超过某一表现水平的可能性的预期,此方法已经用于在一组种源之间分配dhu,其也可以应用于双单倍体(dh)过程内的子过程。
[0078]
例如,当dh过程内的子过程从dh系产生更多种子时,必须认识到,在被产生之后,例如,可能仅有有限数量的温室空间,dh过程可以正常地在其中进行。在所述过程中将相关的育种值(在图2的叶脉(vein)中)是给定的自交体每株植株产生的籽粒数量的概率分布。基于给定品系每株植株产生多于设定限值(例如180个籽粒)的可能性,可将有限的温室空间分配给不同品系以提高和/或最大化所产生的籽粒的数量,同时确保每个品系在过程结束时具有所需和/或最小数量的籽粒。
[0079]
由于资源分配中涉及的复杂性,在其商业用途中依赖于本文所述的算法和计算技术。然而,出于说明的目的,给出了简化的实例。与此相关,考虑必须在两个dh系之间划分三个温室点以便如上所述产生更多种子的情况是有启发性的。问题的相关值如下:
[0080]
表2
[0081]
项值n3个温室单位(每个单位一株植株)η每株植株180个籽粒p10.3p20.9u10.5u21.25ξ每个品系必须具有至少一个资源λ10.3λ20.3λ30.4
[0082]
通常,此处,第三(多样性)项将施加跨种源的靶标分布,在此实例中,所述目标分布可能是每个种源的所需籽粒数,其将通过另一过程或分析来确定。为了出于说明的目的而简化此实例,将通过把靶标分布设定为“每个品系必须具有向其分配的至少一个资源”来简化此项。对于这个靶标,第三项对于其中一个或另一个品系没有资源投入其中的解将变成 1*λ3,而当两个品系都得到至少一个资源时将变成 0。给定上面定义的其他值,这将阻止具有非零第三项的解产生最小化的解,所以此实例可以仅集中于两个品系都被给予资源的两个可能的解。对总共两个品系(n=2)扩展方程(1)得到:
[0083]
minimize[[
‑
λ1p1x1 λ2(p1(1
‑
p1)u1x1) λ3*0] [
‑
λ1p2x2 λ2(p2(1
‑
p2)u2x2) λ3*0]]
[0084]
对于两种用来分配资源的可能方式中的每一种,将表2中的值插入到此扩展方程中将得到每个潜在解的结果。在这种情况下,使结果最小化将意味着从此方程中选择产生较小数量的资源分配。
[0085]
解1
[0086]
品系1获得两个资源,品系2获得一个资源。
[0087]
[
‑
0.3*0.3*2 0.3*0.3*0.7*0.5*2 0.4*0] [
‑
0.3*0.9*1 0.3*0.9*0.1*1.25*1 0.4*0]=
‑
0.353
[0088]
解2
[0089]
品系1获得一个资源,品系2获得两个资源。
[0090]
[
‑
0.3*0.3*1 0.3*0.3*0.7*0.5*1 0.4*0] [
‑
0.3*0.9*2 0.3*0.9*0.1*1.25*2 0.4*0]=
‑
0.531
[0091]
如上可见,解2(其中品系1获得一个资源且品系2获得两个资源)产生方程(1)的最小解。这表明此解在确保每个品系被给予至少一个资源的同时产生最多种子的可能性更高。此外,可以看出,在这种特定情况下,即使品系2的置信度的不确定性远高于品系1,但其成功概率的较大差异抵消了不确定性。尽管此实例的性质被简化,但出于本文说明的必要性,其仍是所述方法的影响及其在要进行的不同类型的植物育种分配方面的通用性(和实际适用性)的示范。
[0092]
仍然参考图4,分配引擎110然后在406以符合所确定的资源分配的方式为多个所选种源相应地分配dhu。具体地,在上述实例中,关于表2,三个温室单元如下分配:一个分配给品系1,两个分配给品系2,由此符合这些品系的物理材料被物理地布置或种植在特定的温室单元。在实践中,例如,在品系都是玉蜀黍植物的情况下,使用具有
′
诱导
′
基因型的植株(即,当与二倍体玉蜀黍植物杂交时具有相对高的产生单倍体后代的可能性的植株)对来自品系1的一个后代植株和来自品系2的两个后代的须进行授粉(其中每个温室单位分配一株植株)。将所得单倍体后代暴露于有丝分裂抑制剂(例如秋水仙碱等)以破坏正常细胞分裂并引起细胞核中的染色体加倍。因此,所得植株具有两个具有精英遗传学的相同染色体。
[0093]
本领域技术人员将理解,也可分配dhu以在体内通过孤雌生殖(无融合生殖)或假受精;或在体外通过雌核发育和/或雄核发育产生单倍体植株。例如,在欧洲油菜(brassica napus)和芥菜(brassica juncea)育种的情况下,可以使用小孢子培养物、另一种培养物和子房/胚珠培养物来产生单倍体植株,以产生随后的双单倍体植株。还应理解,符合方法400中确定的分配的资源的分配或指派可以是另外的,这取决于例如待分配/指派的资源的类型和待育种的植株。
[0094]
此外,资源的分配可由分配引擎110、由与方法400中406处确定的分配相关联的用户(例如,育种者等)或由其组合来完成。例如,分配引擎110可以输出指示所确定的分配的报告作为方法400中的分配的一部分(例如,其中报告考虑了可用于分配的资源和指派给那些分配的种源等),此后,与育种流水线102相关联的一个或多个用户可以物理地将所确定的分配施加于多个资源。在此实例中,通过分配符合所确定的分配的资源来改变和/或实施育种流水线102中的物理资源,从而提供资源从一般到具体的转变(即,每个资源利用分配中指定的具体种源来实施)。应当理解,分配引擎110和/或一个或多个用户或其组合的参与
可以是不同的,这取决于待分配的资源的特定类型和数量、特定育种流水线102、如本文所述选择和分配的种源等。
[0095]
综上,本文所述的独特系统和方法提供了育种流水线中资源的智能分配。具体地,对于特定育种流水线,资源(及其使用)通常可能是耗时的、昂贵的或甚至是有限的(例如,取决于在给定流水线中育种的植物的类型等)。然而,在本文中,采用了一种或多种算法,其考虑了种源的性状表现的概率(例如,表达为二项式分布等),以及与所选种源相关的风险和/或基因型组分和/或多样性。通过所描述的算法,资源(无论它们包括生长空间(例如,田地地块等)、田间设备、实验室空间、实验室设备、人员等)(或其组合或子集)被分配成更高的产生表现高于一个或多个阈值的后代的可能性和/或更高的产生以认为适合和/或期望用于育种流水线的比率表达某些遗传组分的后代的可能性。因此,依赖于与先前不依赖的种源相关的数据来分配资源(并且通过扩展实施所述数据的过程)(即,使用特定信息和技术),所述育种流水线允许相对于常规的在所识别种源之间均匀的资源分配,实现了本文所述的改进(即,改进用于分配资源的现有技术和过程,以促进所识别种源具有获得更多资源的更大潜力)。
[0096]
因此,应当理解,在一些实施方案中,本文所述的功能可以用存储在计算机可读介质上并可由一个或多个处理器执行的计算机可执行指令来描述。计算机可读介质是非暂时性计算机可读介质。例如而非限制,此类计算机可读介质可包括ram、rom、eeprom、cd
‑
rom或其他光盘存储器、磁盘存储器或其他磁存储设备或可用于携带或存储呈指令或数据结构形式的所需程序代码并可由计算机访问的任何其他介质。上述的组合也应包括在计算机可读介质的范围内。
[0097]
还应了解,本公开的一个或多个方面当被配置以执行本文所述的功能、方法和/或过程时将通用计算设备转变为专用计算设备。
[0098]
如基于前述说明书将进一步理解的,本公开的上述实施方案可以使用包括计算机软件、固件、硬件或其任何组合或子集的计算机编程或工程技术来实施,其中技术效果可以通过执行以下操作中的至少一个来实现:(a)对于多个种源,访问包括代表所述多个种源的数据的数据结构,所述数据包括针对所述多个种源中的每一个的性状表现表达和/或基因型组分;(b)由至少一个计算设备基于与所述种源的所述性状表现表达和/或基因型组分相关联的概率确定资源分配,所述资源分配在所述多个种源之间分配n个资源,其中n是整数;以及(c)基于所确定的资源分配,在育种流水线中为多个种源分配n个资源,从而将种源施加于符合资源分配的资源上;和/或(d)其中:(i)确定所述资源分配包括基于多个潜在资源分配的以下值的比较来确定所述资源分配;
[0099][0100]
(ii)在资源分配中将n个资源中的至少一个分配给多个种源中的每一个;并且其中在资源分配中将n个资源中的每一个分配给多个种源中的一个;(iii)针对雄性和雌性杂种优势库保持分开的杂交作物确定资源分配包括确定资源分配,满足以下条件:
[0101]
m
t
y≥mα
m
,
[0102]
f
t
y≥mα
f
,
[0103]
以及
[0104]
α
m
α
f
≤1;
[0105]
(iv)确定资源分配包括基于预定义的靶标组合确定资源分配,由此基于资源分配与预定义的靶标组合的偏差来减小每个潜在资源分配的相对值;和/或(v)确定资源分配包括基于多个种源中的每一个的性状表现表达和/或基因型组分的置信度来确定资源分配。
[0106]
提供实例和实施方案以便本公开将是完整的,并且将向本领域技术人员充分传达范围。阐述了许多具体细节,诸如特定部件、设备和方法的实例,以提供对本公开的实施方案的完整理解。对于本领域的技术人员将显而易见的是具体细节不需要被采用,示例性实施方案可以以许多不同的形式体现,并且两者都不应被理解为会限制本公开的范围。在一些示例性实施方案中,公知的过程、公知的设备结构和公知的技术未进行详细描述。此外,利用本文公开的一个或多个示例性实施方案可以实现的优点和改进可以提供上述优点和改进中的全部或不提供,并且仍然落入本公开的范围内。
[0107]
本文公开的具体值本质上是例子并且不限制本公开的范围。本文对给定参数的特定值和特定值范围的公开不排除可用于本文公开的一个或多个实例中的其他值和值范围。此外,设想本文所述的特定参数的任何两个特定值可定义也可适用于给定参数的值范围的端点(即,对给定参数的第一值和第二值的公开可解释为公开了第一值与第二值之间的任何值也可用于给定参数)。例如,如果参数x在本文中被例示为具有值a并且还被例示为具有值z,则设想参数x可以具有从约a至约z的值范围。类似地,设想参数的值的两个或更多个范围的公开(无论这样的范围是嵌套的、重叠的还是不同的)涵盖可能使用公开范围的端点要求保护的值的所有可能的范围组合。例如,如果参数x在本文中被例示为具有在1
‑
10、或2
‑
9、或3
‑
8的范围内的值,则还设想,参数x可以具有其他范围的值,包括1
‑
9、1
‑
8、1
‑
3、1
‑
2、2
‑
10、2
‑
8、2
‑
3、3
‑
10和3
‑
9。
[0108]
本文使用的术语仅用于描述特定示例实施方案的目的,而不是为了限制。如本文所用,单数形式“一个(a,an)”和“所述(the)”可旨在同样包括复数形式,除非上下文明确地以其他方式指示。术语“包括(comprises,comprsing,including)”和“具有(having)”是包括性的且因此指明所述特征、整体、步骤、操作、元件和/或部件的存在,但并不排除一个或多个其他特征、整体、步骤、操作、元件、部件和/或其群组的存在或添加。本文所述的方法步骤、过程和操作不应理解为必定需要以所讨论或所图示的特定次序进行,除非特别指出为进行的次序。还应当理解,可采用附加的或替代的步骤。
[0109]
当特征被称为位于另一元件或层“上”、“接合到”、“连接到”、“耦合到”另一元件或层、与另一元件或层“相关联”、“通信”或“包括”在另一元件或层中时,其可直接位于另一特征上、接合、连接或耦合到另一特征、或与另一特征相关联或通信或包括在另一特征中,或者可存在介入特征。如本文所用,术语“和/或”和“中的至少一个”包括相关联的列出项目中的一个或多个的任何和所有组合。
[0110]
权利要求书中陈述的元件都不旨在是35 u.s.c.
§
112(f)含义内的装置加功能元件,除非使用短语“用于......的装置”明确陈述元件,或者在使用短语“用于...的操作”或“用于...的步骤”的方法项权利要求的情况下。
[0111]
尽管在本文中可能使用术语第一、第二、第三等来描述各种特征,但这些特征不应受这些术语限制。这些术语可仅用于区分一个特征与另一个特征。如“第一”、“第二”和其他
数字术语的术语在本文中使用时并不暗示顺序或次序,除非上下文明确指出。因此,在不脱离所述示例性实施方案的教导的情况下,本文所述的第一特征可能被称为第二特征。
[0112]
已出于说明和描述目的提供了实施方案的以上描述。所述描述并非旨在穷举或限制本公开。特定实施方案的单个元件或特征通常不限于该特定实施方案,而是在适当情况下是可互换的并且可用于所选实施方案中,即使没有具体示出或描述。特定实施方案的单个元件或特征也可以以多种方式变化。此类变化不应视为脱离本公开,并且所有这些修改旨在被包括在本公开的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。