1.本发明整体涉及眼科自发荧光图像领域。更具体地,其涉及眼底自发荧光图像中发现的地理萎缩(geographic atrophy,地图状萎缩)区域的分类。
背景技术:
2.年龄相关性黄斑变性(amd)是工业化国家老年人群失明的最常见原因。地理萎缩(ga)是amd的一种晚期形式,其特征是光感受器、视网膜色素上皮(rpe)和脉络膜毛细血管层的丧失。估计全球有500万人受到地理萎缩的影响。ga可导致不可逆的视觉功能丧失,并且是约20%的amd严重视力障碍的原因。迄今为止没有批准的治疗方法来阻碍ga的进展。然而,近年来,在了解ga发病机制方面取得的进展已导致临床试验中的多种潜在疗法。尽管如此,早期识别ga进展对于减缓其影响至关重要。
3.已显示,异常眼底自发荧光(faf)图像的不同表型模式有助于识别ga进展。因此,识别ga病变及其表型可能是确定amd疾病进展和临床诊断的重要因素。使用医务人员目视检查ga病变及其表型的faf图像是有效的,但耗时。已经开发了一些分割算法来帮助评估ga病变,但其中许多算法是半自动的,需要手动输入来分割ga病变。
4.本发明的一个目的是提供一种用于量化(quantification)医学图像中ga病变及其表型模式的全自动方法。
5.本发明的另一个目的是增强ga病变分割算法,其具有识别和分类不同表型模式的能力。
6.本发明的另一个目的是提供一种用于自动分割和识别宽场faf图像中ga表型模式的架构(framework)。
技术实现要素:
7.在一种用于分类(例如识别)眼睛中地理萎缩(ga)的系统/方法中满足了上述目的。例如,ga区域(例如眼底或正面图像中的ga分割)可以被识别为“弥散(diffused)”表型或“带状(banded)”表型。这两种表型均已根据经验确定为高进展率地理萎缩的指示。该系统可以包括眼科诊断装置,诸如用于生成/捕获眼科图像的眼底成像仪或光学相干断层扫描(oct)装置。替代地,眼科诊断装置可以体现为使用计算机网络(例如互联网)从数据存储访问预先存在的眼科图像的计算机系统。眼科诊断装置用于获取眼底图像。优选地,该图像是眼底自发荧光(faf)图像,因为在此类图像中ga病变通常更容易辨认。
8.然后将获取的图像提交给自动ga识别过程,以识别(例如分割)图像中的ga区域。本ga分割方法是完全自动化的,并且可以基于深度学习神经网络。ga分割还可以基于两阶段分割过程,例如将监督式分类器(或像素/图像分割)与主动轮廓算法相结合的混合过程。监督式分类器优选地是机器学习(ml)模型,并且可以实现为支持向量机(svm)或深度学习神经网络,优选地u
‑
net型卷积神经网络。这种第一阶段分类器/分割ml模型识别图像中的
初始ga区域(病变),并将结果馈送到主动轮廓算法(active counter algorithm)以进行第二阶段分割。主动轮廓算法可以实现为改进的chase
‑
vese分割算法,其中将在第一阶段识别的初始ga区域用作chase
‑
vese分割中的起点(例如初始轮廓)。结果是获取的图像的稳健的ga分割。
9.然后提交已识别的ga区域进行分析以识别它们的特定表型。例如,该系统/方法可以使用ga区域的轮廓非均匀性测量值来识别“弥散”表型,并且使用强度均匀性测量值来识别“带状”表型。这两种表型中的任何一种都表明高进展率ga区域。该分析可以在两步过程中进行,其中计算两个测量值中的第一个,并且如果第一测量值高于第一阈值,则可将ga区域归类为高进展率,并且无需计算两个测量值的第二个。然而,如果第一测量值不高于第一阈值,则可以计算第二测量值并与第二阈值进行比较以确定它是否指示高进展率ga。例如,如果轮廓非均匀性测量值大于第一预定阈值(例如ga区域的周边轮廓的非均匀性大于预定阈值),则可将ga区域归类为
‘
弥散’表型,而如果强度均匀性测量值大于第二阈值,则可将ga区域归类为
‘
带状’表型。
10.通过参考以下描述和权利要求并结合附图,本发明的其它目的和成就以及对本发明的更全面理解将变得显而易见和理解。
11.本文公开的实施方式仅为示例,并且本公开的范围不限于此。在一项权利要求类别(例如系统)中提及的任何实施方式特征也可以在另一权利要求类别(例如方法)中要求保护。仅出于形式原因选择所附权利要求中的从属项或回引。然而,也可以要求保护因故意回引任何先前权利要求而产生的任何主题,从而公开并且可以要求保护权利要求及其特征的任何组合,而不管所附权利要求中选择的从属关系。
附图说明
12.在附图中,相同的参考符号/字符指代相同的部分:
13.图1提供了三个真彩色图像的灰度图像,旁边是眼睛相似区域的三个相应的自发荧光图像。
14.图2提供了ga区域的示例faf图像。
15.图3a提供了
‘
弥散’表型ga病变的一些faf图像示例。
16.图3b提供了
‘
带状’表型ga病变的faf示例。
17.图4提供了ga表型模式自动分割和识别的总结架构。
18.图5说明了根据本发明的用于自动分割和识别ga表型模式的更详细的过程。
19.图6显示了人类专家划定的四个ga区域。
20.图7显示了由支持向量机提供的ga划定,并且对应图6的ga区域。
21.图8显示了人类专家划定的五个ga区域。
22.图9显示了由深度学习、神经网络提供的ga划定,并且对应于图8的ga区域。
23.图10示出了
‘
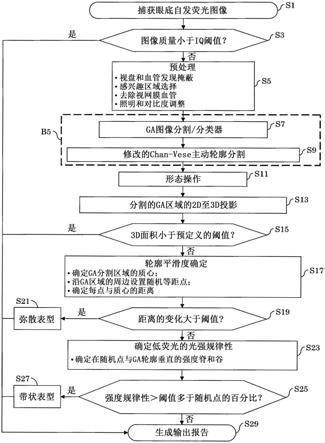
弥散’表型ga区域,其质心用圆圈表示。
24.图11示出了
‘
带状’表型ga区域,质心和十三个随机点集沿ga分割周长等距分开。
25.图12示出了一种用于自动分类眼睛中地理萎缩的示例方法。
26.图13示出了用于对眼底成像的狭缝扫描眼科系统的示例。
27.图14示出了适用于本发明的用于收集眼睛的3
‑
d图像数据的广义频域光学相干断
层扫描系统。
28.图15示出了正面血管系统图像的示例。
29.图16示出了多层感知器(mlp)神经网络的示例。
30.图17示出了由输入层、隐藏层和输出层组成的简化神经网络。
31.图18示出了示例卷积神经网络架构。
32.图19示出了示例u
‑
net架构。
33.图20示出了示例计算机系统(或计算设备或计算机设备)。
具体实施方式
34.早期诊断对于成功治疗各种眼病至关重要。光学成像是视网膜无创检查的首选方法。尽管已知年龄相关性黄斑变性(amd)是视力丧失的主要原因,但通常要等到损伤出现后才能做出诊断。因此,先进的眼科成像设备的目标是提供诊断工具,以帮助检测和监测疾病临床前阶段的病理变化。
35.多种眼科成像系统是本领域已知的,例如眼底成像系统和光学相干断层扫描系统,其均可以与本发明一起使用。下面提供了眼科成像模式的示例,例如参见图13和14。这些装置中的任何一个都可用于提供眼底的图像,眼底是与眼睛晶状体(或晶状体)相对的眼睛内表面,并且可以包括视网膜、视盘、黄斑、中央凹和后极。
36.眼科成像系统可以生成全彩色图像。其它成像技术,例如荧光素血管造影或吲哚青绿血管造影(icg),可用于捕获特定眼科特征(例如血管或病变)的高对比度图像。通过在将荧光染料注入受试者的血流后收集图像并使用选择用来激发荧光染料的特定光频率(例如颜色)捕获图像来获得高对比度图像。
37.替代地,无需使用荧光染料即可获得高对比度图像。例如,以特定频率提供光的单个光源(例如彩色led或激光)可用于在称为自发荧光的技术中激发眼睛中不同的天然存在的荧光团。可以通过滤除激发波长来检测产生的荧光。这可以使眼睛的某些特征/组织比真彩色图像更容易辨别。例如,眼底自发荧光(faf)成像可以用绿色或蓝色激发进行,其激发脂褐素的自然荧光,生成单色图像。出于说明目的,图1提供了真彩色图像的三个灰度图像11a、13a和15a,旁边是眼睛相同区域的三个相应的自发荧光图像11b、13b和15b。很明显,在相应的自发荧光图像11b、13b和15b很容易识别在灰度图像11a、13a和15a中没有很好定义的一些组织特征(例如在每个图像的中心区域)。
38.amd通常从干性(萎缩性)amd开始并发展为湿性(新生血管性)amd。干性amd的特征是在视网膜上(例如黄斑下方)形成玻璃膜疣(例如小的白色或淡黄色沉积物),导致其随着时间的推移而恶化或退化。早期干性amd可通过营养疗法或补充剂治疗,以及湿性amd可通过注射治疗(例如注射雷珠单抗、安维汀和艾力雅),但目前尚无批准的用于晚期干性amd的治疗方法,尽管临床试验正在进行中。地理萎缩(ga)是干性amd的晚期形式,其特征是视网膜中出现退化或死亡的细胞斑块。ga可定义为任何轮廓分明的圆形或椭圆形色素减退区域,或视网膜色素上皮(rpe)的明显缺失,其中脉络膜血管比周围区域更明显,并且具有最小尺寸,例如直径175μm。在过去,将彩色眼底图像用于成像和识别ga,但是彩色眼底成像无法可视化与ga进展相关的病变特征。由于含有脂褐素(自发荧光色素)的rpe细胞丧失,在眼底自发荧光(faf)成像中,萎缩区域显得较暗。这会在萎缩和非萎缩区域之间产生高对比
度,其可以比彩色眼底图像更容易定义ga区域。已发现使用自发荧光是评估ga病变和监测病变结构变化的更有效成像方式。特别是,使用488nm激发波长的faf是目前业界首选的ga病变形态学评估技术。出于说明目的,图2提供了ga区域的示例faf图像。
39.ga的faf图像可以以萎缩区域周围的超自发荧光异常模式为特征。这导致了ga特定表型的分类或识别。bindewald等在“classification of fundus autofluorescence patterns in early age
‑
related macular disease”invest ophthalmol vis sci.,2005,46:3309
‑
14中首次提出了将这种特征性超自发荧光分类为不同模式。随后,发表了多项研究,记录了不同表型模式对疾病进展的影响及其作为预后决定因素的能力,如以下中讨论的:holz f.g.et al.,“progression of geographic atrophy and impact of fundus autofluorescence patterns in age
‑
related macular degeneration,”am j.ophthalmol,2007;143:463
‑
472;fleckenstein m.et al.,“the
‘
diffuse
‑
trickling’fundus autofluorescence phenotype in geographic atrophy,”invest ophthalmol vis sci.,2014,55:2911
‑
20;和jeong,y.j.et al.,“predictors for the progression of geographic atrophy in patients with age
‑
related macular degeneration:fundus autofluorescence study with modified fundus camera,”eye,2014 online,28(2),209
‑
218,doi 10.1038/eye.2013.275。上述参考文献通过引用整体并入本文。
40.特别令人感兴趣的是
‘
弥散’(或
‘
弥散
‑
滴流’(diffuse
‑
trickling))ga表型和
‘
带状’ga表型,这两种表型均已根据经验确定指示ga进展率较高。因此,除了识别ga区域外,对已识别ga区域的正确表型分类同样重要。
‘
弥散’ga区域的特征可在于其周边轮廓的非均匀性程度(例如高于预定非均匀性阈值的轮廓非均匀性测量值)。因此,可以确定图2的ga区域不是
‘
弥散’表型,因为它的轮廓是相对均匀的。相比之下,图3a提供了一些
‘
弥散’表型ga病变的faf图像示例,所有这些示例都表现出高度的轮廓非均匀性。由于ga区域也可在萎缩区域周围具有高浓度的超自发荧光,因此
‘
带状’ga区域的特征可以是沿其周边的超自发荧光强度的变化量。更具体地,如果ga区域的轮廓超自发荧光强度的变化相对均匀(例如强度均匀性测量值高于预定强度阈值),则ga区域可以表征为
‘
带状’表型。例如,可以确定图2的ga区域不是
‘
带状’表型,因为它缺乏沿其轮廓的超自发荧光的均匀性。通过比较,图3b提供了
‘
带状’表型ga病变的faf示例,沿其轮廓具有均匀的超自发荧光。
41.ga病变及其表型模式的自动量化可以极大地帮助确定amd的疾病进展和临床诊断。如上所述,目前有一些用于ga病变评估的分割算法,但这些算法都没有解决识别和分类不同表型模式。也就是说,迄今为止所有可用于ga病变的分割方法都缺乏自动分类不同ga表型模式的能力。文献中报道的大多数分割方法都是半自动的,并且需要手动输入来分割ga病变。此外,所有先前报道的分割方法都是为与标准视场(fov)图像(例如45
°
至60
°
的fov)一起使用而开发的,其中ga病变的位置通常限于标准fov图像的预定义区域。然而,最近对宽场图像(例如具有fov 60
°
至120
°
或更大)越来越感兴趣,强调需要一种适用于宽场图像的自动化ga评估方法。宽场图像的使用使典型ga分割算法的使用复杂化,因为ga病变的位置不能局限于宽场图像的预定义区域,并且患病眼睛中的某些(物理)标志可能没有明确定义。
42.图4提供了用于ga表型模式的自动分割和识别的总结架构。首先,确定图像质量(iq)的测量值(方块b1)。这可包括将图像质量算法应用于faf图像,以拒绝具有不可分级质
量的图像(iq测量值低于预定义值)。如果图像被拒绝,流程可以直接跳到b9。如果iq测量值足以进行评分,则该过程继续至方块b3。
43.方块b3为faf图像提供可选的预处理。这可能包括视盘和/或血管检测、目的区域(roi)选择和直方图校正。自动roi选择(可以基于视盘的检测)限制了需要处理(例如分类)的像素量,从而减少了分割过程的实施时间。
44.方块b5提供了ga病变分割。这可以组合逐像素分类和经修改的chan
‑
vese主动轮廓。例如,分类可由提供初始ga分割的机器学习(ml)模型(例如支持向量机(svm)和/或深度学习神经网络)提供。然后将ga分割作为起点提交给chan
‑
vese主动轮廓算法,该算法进一步细化ga分割。这种混合过程使用监督式像素分类器与主动轮廓的新型组合。
45.然后可以将方块b5的ga分割提交给表型分类方块b7,它识别和分类ga分割区域附近的交界区(例如沿着ga分割的周边交界处)。例如,可以选择彼此等距并沿着ga分割的周边分布的随机点集。然后可以计算每个选择的点到ga分割的质心的距离。然后可以使用这些距离来确定ga分割的周边轮廓平滑度的测量值(例如ga划定的轮廓平滑度)。强度脊和谷可以沿着向外垂直于ga分割周长轮廓的方向计算,例如使用hessian滤波器梯度导数和/或定向高斯滤波器。这可以提供沿ga分割周边的光强度规律性的测量值。这两个参数都可用于对交界区表型进行分类。例如,ga分割的轮廓平滑度测量值可用于识别
‘
弥散’表型,而ga分割的强度规律性测量值可用于识别
‘
带状’表型。
46.替代地,可以将(例如深度学习)神经网络实现为方块b7。在这种情况下,可以训练神经网络以接收方块b5的ga分割并对每个ga分割的特定表型(例如弥散或带状)进行分类。还或者,可以训练神经网络来完成ga病变分割方块b5和表型分类方块b7的功能。例如,一组显示由专家划定的ga区域及由专家识别的其各自表型的图像可用作神经网络的训练输出集,并且原始未划定的图像可用作神经网络的训练输入集。因此,可以训练神经网络以不仅分割(或划定)ga病变区域,而且还识别它们各自的表型(例如,
‘
弥散’或
‘
带状’)。
47.此外,已经发现,视网膜血管可能会导致错误地将某些眼底区域识别为ga分割。这可以通过在应用ga分割之前,例如在方块b5之前,从faf图像中去除视网膜血管(例如,在预处理方块b3中识别的视网膜血管)来避免。在这种情况下,可以可选地从用于训练学习模型(svm或神经网络)的训练图像中移除视网膜血管。
48.最后的方块b9生成一份报告,总结当前架构的结果。例如,所述报告可以说明图像质量是否太低而无法分级、指定已识别的ga病变是否属于
‘
高’进展率类型、指定ga病变的表型和/或建议随访检查日期。
‘
弥散’和
‘
带状’表型均已根据经验确定为指示高进展率ga;尽管
‘
弥散’表型可能比
‘
带状’表型具有更高的进展率。随访检查日期推荐可以基于确定的ga病变类型。例如,较高进展型ga病变可能比低进展或
‘
低’(或非高)进展型ga病变需要更早的随访检查日期。
49.图5示出了根据本发明的用于自动分割和识别ga表型模式的更详细的过程。出了说明目的,本发明被描述为应用于宽场faf图像,但同样可以应用于其它类型的眼科成像形式,例如可以生成提供可视化ga的图像的oct/octa。例如,其可以应用于正面oct/octa图像。本成像系统和/或方法可以通过捕获或以其他方式获取(例如通过访问数据存储的)眼底自发荧光图像开始(步骤s1)。然后使用本领域已知的任何合适的图像质量(iq)算法对获得的眼底自发荧光图像的图像质量进行评估(例如测量值)。例如,图像质量的测量值可以
基于可量化因素例如锐度、噪声、动态范围、对比度、渐晕等的一个或组合。如果图像质量的测量值小于预定义的图像质量阈值(步骤s3=是),则确定该faf图像不适合用于进一步分析,并且流程进行到步骤s29,在该步骤中生成报告,指出不能对当前faf图像进行ga分割或量化。本质上,图像质量iq算法用于拒绝具有不可分级质量的图像。如果图像质量不小于最小阈值(步骤s3=否),则该流程可以进行到可选的预处理步骤s5,或者可以可选的直接进行到ga图像分割步骤s7。
50.预处理步骤s5可以包括多个预处理子步骤。例如,其可以包括视盘和/或血管检测(例如发现面罩),以及将图像识别为来自患者的左眼或右眼。如上所解释的,在患病眼睛中可能难以识别物理标志,但可以通过从其发出的血管结构的集中度(concentration)来识别视盘。例如,可以训练机器学习模型(例如深度学习神经网络,如下面讨论的)来识别宽场图像中的视盘。替代地,可以训练另一种类型的机器学习模型(例如,支持向量机)来识别视盘,例如通过将视盘的位置与具有血管结构集中度起源的位置相关联。在任一情况下,图像外部的附加信息可用于训练,例如通过电子病历(emr)或医学数字成像和通信(dicom)标准提供的信息。
51.如上所述,已经发现视网膜血管可能导致ga分割中的假阳性。因此,预处理还可以包括在应用ga分割之前识别和去除视网膜血管,以减少假阳性的数量,例如减少对假ga区域的识别。如上所述,ga分割可以基于机器学习模型,并且可以从其训练图像集中去除视网膜血管。例如,可以使用具有手动划定的ga区域和手动识别的表型的眼底图像(例如faf图像)的训练输出集,并且使用没有手动划定的ga区域且没有识别的表型的相同眼底图像的训练输入集,训练神经网络。如果在操作阶段(或测试阶段),神经网络要接受已移除视网膜血管的输入测试图像,则可以用也已移除视网膜血管的训练图像来训练神经网络。也就是说,在训练神经网络之前,可以从训练输入集和训练输出集中的眼底图像中去除视网膜血管。
52.预处理步骤s5还可以包括感兴趣区域(roi)选择,以将处理(包括ga分割)限制为faf图像内识别的roi。优选地,识别的roi会包括黄斑。roi选择可以基于界标检测(landmark detection)(视盘和视网膜血管)、图像大小、图像熵和从dicom中提取的眼底扫描信息等自动进行。例如,根据图像是左眼还是右眼,黄斑将位于图像内视盘位置的右侧或左侧。可以理解的是,roi选择限制了需要分类的像素量(例如用于ga分割),从而减少了本过程/方法的实施时间。
53.预处理步骤s5还可以包括光照校正和对比度调整。例如,可以通过使用背景减除来校正不均匀的图像照度,并且可以通过直方图均衡来调整图像对比度。
54.然后将预处理后的图像提交到两阶段病变分割(例如图4的方块b5),包括ga分割和主动轮廓分析。方块b5中的第一阶段是ga分割/分类器阶段(s7),其优选基于机器学习并识别一个或多个ga区域,而方块b5中的第二阶段是应用于已识别的ga区域的主动轮廓算法。ga分割阶段s7可以在逐子图像区域的基础上提供ga分类,其中每个子图像区域可以是一个像素(例如在逐像素的基础上)或每个子图像区域可以是多个像素的组(例如窗口)。以这种方式,每个子图像区域可以单独分类为ga子图像或非ga子图像。主动轮廓分析阶段s9可以基于已知的chan
‑
vese算法。在该情况中,修改了chan
‑
vese算法以改变轮廓增长的能量和运动方向。例如,将基于区域的图像特征用于指示轮廓运动。本质上,ga病变的分割方
块b5使用组合(例如逐像素)分类和chan
‑
vese主动轮廓的混合过程。任选地,该提议的混合算法使用监督式(例如像素)分类器(s7)与几何主动轮廓模型(s9)的新型组合。如本领域技术人员将理解的,几何主动轮廓模型通常以定义初始分割的图像平面中的轮廓(例如起点)开始,然后根据一些演化方程演变轮廓,以停止在前景区域的边界上。在该情况中,几何主动轮廓模型是基于改进的chan
‑
vese算法。
55.ga分割/分类器阶段(s7)优选基于机器学习,并且可以例如通过使用支持向量机或通过(深度学习)神经网络来实现。本文分别描述了每种实现方式。
56.通常,支持向量机(svm)是一种用于分类和回归问题的机器学习、线性模型,并且可用于解决线性和非线性问题。svm的构思是创建将数据分成几类的一条线或超平面。更正式地说,svm在多维空间中定义了一个或多个超平面,其中所述超平面用于分类、回归、异常值检测等。从本质上讲,svm模型是将标记训练样例表示为多维空间中的点,映射使得不同类别的标记训练样例被超平面划分,这可以被认为是分隔不同类别的决策边界。当一个新的测试输入样例被提交到svm模型时,测试输入被映射到相同的空间,并根据测试输入位于决策边界(超平面)的哪一侧来预测它属于哪个类别。
57.在优选的实施方式中,将svm用于图像分割。图像分割的目的是将图像划分为具有不同特征的不同子图像,并提取出目标对象。更具体地,在本发明中,训练svm以分割faf图像中的ga区域(例如,训练以明确定义faf图像中ga区域的轮廓)。用于图像分割的各种svm架构在本领域中是已知的,并且用于该任务的具体svm架构对本发明并不关键。例如,最小二乘svm可用于基于逐像素(或逐子图像区域)分类的图像分割。像素级特征(例如颜色、强度等)和纹理特征都可以用作svm的输入。任选地,可以链接一组svm(每个都提供专门的分类)以获得更好的结果。
58.因此,可以使用svm分类器(例如通过基于svm模型的分割)进行初始轮廓选择。优选地,从灰度共生矩阵(例如,在感兴趣区域内移动的11x11窗口)获得的haralick纹理特征、平均强度和方差参数用于训练svm分类器。如上所解释的,可以任选地从训练图像中去除视网膜血管。无论如何,特征提取限于特定的roi(例如在步骤s5中选择的roi),这比将ga分割/分类应用于整个图像产生了更好的时间性能。以这种方式,svm提供了初始轮廓选择(例如提供初始ga分割作为起点),以提交给步骤s9的主动轮廓算法以获得更好的性能。主动轮廓算法的演进时间严重依赖于初始轮廓选择,如例如chen,q.et al.在“semi
‑
automatic geographic atrophy segmentation for sd
‑
oct images”,biomedical optics express,4(12),2729
‑
2750中所解释的,通过引用将其全部内容并入本文。
59.对svm分类器进行了性能测试和比较。专家评分者在训练中未使用的faf图像中手动划定ga区域,并将结果与svm模型的分割结果进行比较。图6示出了人类专家划定的四个ga区域,并且图7示出了由本svm提供的相应ga划定(例如ga分割的周长)。如图所示,svm模型与专家评分者提供的手动ga分割吻合良好。
60.ga分割/分类器阶段(s7)也可以通过使用神经网络(nn)机器学习(lm)模型来实现。下面参考图16到19讨论了神经网络的各种示例,其中任何一个或它们的组合都可以与本发明一起使用。基于u
‑
net架构构建了使用深度学习神经网络的ga分割/分类器的示例性实现(参见图19)。在这种情况下,使用手动分割的图像(例如具有由人类专家分割的ga区域的图像)作为训练输出和相应的非分割图像作为训练输入来训练nn。
image
‑
a survey”,international journal of modem engineering research,vol.2,issue.5,sep.
‑
oct.2012 pp
‑
3089
‑
3092中提供了从2d眼底图像进行3d重建的其它示例,通过引用将其全部内容并入本文。
67.确定3d空间中的ga尺寸测量值可以利用由眼科成像系统提供的附加信息(如果可获得)。例如,一些眼科成像系统以阵列存储3d位置以及2d图像中每个像素位置的2d坐标。此方法可以包括在医学数字成像和通信(dicom)标准宽场眼科摄影图像模块中。替代地或组合地,某些系统可能存储可以在任意一组2d位置上运行以生成相关3d位置的模型。
68.如果在3d空间中确定的面积小于预定义的阈值(步骤s15=是),则确定ga分割太小而不是真正的ga病变,并且过程进行到步骤s29以生成报告。如果确定的面积不小于预定义的阈值,例如96kμm2,(步骤s15=否),则接受所述ga分割作为真正的ga病变,并且该过程尝试识别已识别的ga分割的表型。
69.识别表型的第一步可以是分析ga分割的轮廓平滑度(步骤s17)。这可以包括多个子步骤。为了识别和分类ga分割区域附近的交界区(例如沿着ga分割区域的边缘),可以从确定ga分割区域的质心开始。此质心计算可应用于ga分割区域的2d图像表示。图10示出了弥散表型ga区域21,其质心由圆圈23表示。下一步可以是识别随机点集,其沿着ga分割的周长等距分开。图11示出了带状表型ga区域25,其具有质心27和沿ga分割的周长等距分布的13个随机点集29(每个点都标识为白色十字准线的中心)。应当理解的是,十三是示例性值并且可以使用足以环绕ga区域的周长的任何数量的点。然后计算从每个点29到质心27的距离(例如线性距离31)。距离31的变化用于区分
‘
弥散’表型与其它表型,例如
‘
带状’表型。
70.在步骤s19中,如果距离变化大于距离
‑
变化阈值(步骤s19=是),则将ga区域识别为
‘
弥散表型’(步骤s21),并且该过程进行到步骤s29,其中生成报告。这种距离变化或轮廓非均匀度测量值可以确定为当前ga分割的平均距离变化,并且距离变化阈值可以定义为(例如弥散的)ga段的标准化平均变化的20%。标准化平均变化可以从ga区域库确定,例如ga病变的faf图像的(标准化)库。然而,如果距离变化不大于距离变化阈值(步骤s19=否),则该过程进行到步骤s23)。
71.在步骤s23中,沿着垂直于ga轮廓的方向为随机点集29(的至少一部分)确定强度脊和谷。这可以使用hessian滤波器梯度导数和/或定向高斯滤波器来完成。如果存在的高于预设强度变化阈值的脊和谷(光强度规律性
‑
低荧光)超过所选点29的预定百分比(例如60%)(步骤s25=是),则将图像(例如ga分割)归类为
‘
带状’表型(步骤27),并且过程进行到步骤s29,其中生成报告。强度脊和谷可以定义强度变化测量值,并且强度变化阈值可以定义为(例如带状)ga段的标准化平均强度变化的33%。这种标准化平均强度变化可以从ga段库确定,例如ga病变的faf图像的(标准化)库。如果光强度规律性
‑
低荧光不大于本强度变化阈值(步骤s25=否),则不能确定表型并且过程进行到步骤s29。
72.如上所述,如上文参考步骤s7所述的,可以训练神经网络以提供ga分割。但是,也可以训练神经网络,例如图19的u
‑
net,以提供表型分类。例如,通过提供训练图像集中每个专家划定的ga病变分割的特定表型的专家标记,可以训练神经网络以提供表型分类以及或附加的ga病变分割识别。在这种情况下,与步骤s17至s25相关联的表型识别/分类步骤可以省略并由神经网络提供。替代地,由神经网络提供的表型分类可以结合步骤s17至s25的表型识别结果,例如通过加权平均数。
73.步骤s29生成总结本过程的结果的报告。对于具有不可分级iq的图像(步骤s3=是),仅报告图像质量,而对于其它图像,生成的报告将具有以下一项或多项:
74.a.当前访问的ga分段面积测量值;
75.b.当前ga的交界区表型(如果可获得);
76.c.进展风险(例如,
‘
带状’和
‘
弥散’表型的进展风险报告为高);
77.d.建议的随访时间。
78.图12示出了用于自动分类眼睛中地理萎缩(ga)的另一示例方法。在本示例中,不是检查表型库中每个特定ga表型(例如,
‘
弥散’表型和
‘
带状’表型),一旦当前ga区域被识别为与高进展率相关的任何表型(例如经验关联),本方法可以停止对当前ga区域分类。然后,当前ga区域可以简单地归类为“高进展率”ga,而不指定其具体ga表型。任选地,如果需要,例如通过使用经由图形用户界面(gui)的用户输入,该过程可以继续将当前ga分割分类为一种或多种特定表型。在这种情况下,所述方法可以进一步将“高进展率”ga识别为
‘
弥散’表型或
‘
带状’表型。任选地,所述方法可以根据哪些表型在特定人群中更普遍(例如患者可能属于哪个)来对ga表型的搜索进行排序,或根据哪些表型已(例如凭经验)被确定为比其它表型与更高的进展率ga相关来对搜索进行排序。例如,根据经验观察,
‘
弥散’表型ga可能被认为比
‘
带状’表型ga具有更高的进展率,因此,所述方法可以首先检查当前ga分割是否属于
‘
弥散’表型,然后仅在确定当前ga分割不是
‘
弥散’表型时才检查
‘
带状’表型。
79.所述方法可以从方法步骤m1开始,通过使用眼科诊断装置来获取眼底的图像。所述图像(如自体荧光图像或正面图像)可由眼底成像仪或oct生成。所述眼科诊断装置可以是生成所述图像的装置,或者替代地可以是通过计算机网络(例如互联网)从此类图像的数据存储中访问图像的计算装置。
80.在方法步骤m3中,将获取的图像提交给自动ga识别过程,该过程识别图像中的ga区域。该自动ga识别过程可以包括ga分割过程,如本领域已知的。然而,优选的分割过程是将ga分类(例如逐像素)与主动轮廓分割相结合的两步分割。该两步过程中的第一步可以是经训练的机器模型,例如svm或(例如深度学习)神经网络,其分割/分类/识别图像中的ga区域。例如,可以使用基于u
‑
net架构的神经网络,其中其训练集可以包括专业划界的荧光图像的训练输出集和相应非划界的荧光图像的训练输入集。不管在这个初始阶段中使用的ga分割/分类的类型,可以将识别出的ga分割作为起点提交给主动轮廓算法(例如chan
‑
vese分割)以进一步细化ga分割。任选地,可以将结果提交给形态学操作(例如侵蚀、膨胀、打开和关闭)以在进入下一方法步骤m5之前进行进一步清洁分割。
81.任选地,在进行步骤m5之前,可以将来自步骤m3的最终ga分割映射到代表眼底形状的三维空间,并确定映射的ga的面积。如果面积小于预定义的阈值,那么可以将ga分割重新分类为非
‑
ga并从进一步处理中删除。假设识别出的ga分割足够大,有资格作为真正的ga区域,则处理可以进行到步骤m5。
82.方法步骤m5通过确定一个或两个不同的测量值来分析所识别的ga区域,每个测量值被设计用于识别与高进展率ga相关的两种不同ga表型中的一种。更具体地,轮廓非均匀性测量值可用于识别
‘
弥散’表型ga,且强度均匀性测量值可用于识别
‘
带状’表型ga。如果第一个确定的测量值确认了
‘
弥散’表型ga或
‘
带状’表型ga(例如该测量值高于预定义的阈值),则方法步骤m7将所识别的ga区域归类为“高进展率”ga。如果第一个确定的测量值不能
确认
‘
弥散’或
‘
带状’表型之一,则可以确定第二测量值以检查两个表型中的另一个是否存在。如果存在另一表型,那么可以再次将所识别的ga区域归类为“高进展率”ga。任选地或替代地,方法步骤m7可以说明为ga区域识别的具体表型分类(
‘
弥散’或
‘
带状’)。
83.眼底成像系统
84.用于对眼底成像的两类成像系统是泛光照明成像系统(或泛光照明成像仪)和扫描照明成像系统(或扫描成像仪)。泛光照明成像仪同时向样本的整个目标视场(fov)泛光,例如通过使用闪光灯,并使用全画幅相机(例如具有二维(2d)照片传感器阵列的相机,其尺寸足以捕获所需的fov,作为一个整体)捕获标本(例如,眼底)的全画幅图像。例如,泛光照明眼底成像仪将光线泛照射到眼睛的眼底,在相机的单次图像采集序列中采集眼底全画幅图像。扫描成像仪提供在对象(例如眼睛)上扫描的扫描束,并且当扫描束在对象上扫描时在不同的扫描位置成像,从而创建一系列可以重建(例如蒙太奇)的图像片段,以创建所需fov的合成图像。扫描光束可以是点、线或二维区域,例如狭缝或宽线。
85.图13示出了用于对眼底f成像的狭缝扫描眼科系统slo
‑
1的示例,该眼底f是与眼睛晶状体(或晶状体)cl相对的眼睛e的内表面并且可以包括视网膜、视盘、黄斑、中央凹和后极。在本示例中,成像系统处于所谓的“扫描
‑
反扫描(scan
‑
descan)”配置中,其中扫描线光束sb穿过要被扫描的眼睛e的光学组件(包括角膜crn、虹膜irs、瞳孔ppl和晶状体cl)穿过眼底f。在泛光眼底成像仪的情况下,不需要扫描仪,并且光一次应用到整个所需的视野(fov)。其它扫描配置是本领域已知的,并且具体的扫描配置对本发明并不关键。如所示的,成像系统包括一个或多个光源ltsrc,优选多色led系统或激光系统,其中展度已被适当调整。可以将任选的狭缝slt(可调或静态)置于光源ltsrc的前面,并且可用于调整扫描线光束sb的宽度。另外,狭缝slt可以在成像期间保持静止,或可以调整为不同的宽度,以允许不同的共焦水平和用于特定扫描或在扫描期间用于抑制反射的不同应用。可以将任选的物镜objl放置在狭缝slt的前面。物镜objl可以是任何一种最先进的镜头,包括但不限于折射、衍射、反射或混合透镜/系统。来自狭缝slt的光通过瞳孔分光镜sm并被导向扫描仪lnscn。可取的是将扫描平面和瞳孔平面尽可能靠近在一起以减少系统中的渐晕。可以包括任选的光学器件dl来操纵两个组件的图像之间的光学距离。瞳孔分光镜sm可以将来自光源ltsrc的照明光束传递到扫描仪lnscn,并将来自扫描仪lnscn的检测光束(例如从眼睛e返回的反射光)反射到相机cmr。瞳孔分光镜sm的任务是将照明光束和探测光束分开,并帮助抑制系统反射。扫描仪lnscn可以是旋转振镜扫描仪或其它类型的扫描仪(例如压电或音圈、微机电系统(mems)扫描仪、光电偏转器和/或旋转多边形扫描仪)。根据瞳孔分光是在扫描仪lnscn之前还是之后完成,可以将扫描分为两个步骤,其中一个扫描仪在照明路径中并且一个单独的扫描仪在检测路径中。在美国专利号9,456,746中详细描述了具体的瞳孔分光布置,该专利通过引用整体并入本文。
86.来自扫描仪lnscn的照明光束穿过一个或多个光学器件,在该情况下是扫描透镜sl和眼科透镜或接目镜ol,其允许将眼睛e的瞳孔成像到系统的成像瞳孔。通常,扫描透镜sl以多个扫描角(入射角)中的任何一个接收来自扫描器lnscn的扫描照明光束,并且产生具有基本平坦表面焦平面(例如准直光路)的扫描线光束sb。眼科透镜ol可以将扫描线光束sb聚焦到眼睛e的眼底f(或视网膜)上并对眼底成像。以这种方式,扫描线光束sb产生穿过眼底f的遍历扫描线。这些光学器件的一种可能配置是开普勒型望远镜,其中选择两个透镜
之间的距离以创建近似远心的中间眼底图像(4
‑
f配置)。该眼科透镜ol可以是单透镜、消色差透镜、或不同的透镜的排列。如本领域技术人员所知,所有透镜都可以是折射的、衍射的、反射的或混合的。眼科透镜ol、扫描透镜sl的焦距以及瞳孔分光镜sm和扫描仪lnscn的大小和/或形状可以不同,这取决于所需的视野(fov),因此,取决于视野,可以设想这样一种布置,其中多个组件可以切换进和切换出光束路径,例如通过使用光学元件、电动轮或可拆卸的光学元件的翻转。由于视野变化导致瞳孔上的光束大小不同,因此瞳孔分光也可以随着fov的变化而变化。例如,45
°
到60
°
的视野是眼底相机的典型或标准fov。更高的视野,例如60
°‑
120
°
或更大的宽场fov也可以是可行的。宽线眼底成像仪(blfi)与其它成像形式如光学相干断层扫描(oct)的组合可能需要宽场fov。视野上限可由可达工作距离结合人眼周围的生理条件确定。由于典型的人类视网膜的fov为水平140
°
和垂直80
°‑
100
°
,因此可能需要非对称视野以在系统上提供尽可能最高的fov。
87.扫描线光束sb穿过眼睛e的瞳孔ppl,并导向视网膜和眼底表面f。扫描仪lnscn1调整光在视网膜或眼底f上的位置,从而照亮眼睛e上的一系列横向位置。反射或散射光(或在荧光成像的情况下发出的光)沿着与照明相似的路径引导返回相机cmr,以在检测路径上定义收集光束cb。
88.在本示例性狭缝扫描眼科系统slo
‑
1的“扫描
‑
反扫描”配置中,从眼睛e返回的光线在通往瞳孔分光镜sm的途中被扫描仪lnscn“反扫描”。也就是说,扫描仪lnscn扫描来自瞳孔分光镜sm的照明光束,以定义穿过眼睛e的扫描照明光束sb,但由于扫描仪lnscn也在相同的扫描位置接收来自眼睛e的返回光,扫描仪lnscn具有反扫描所述返回光的作用(例如取消扫描动作),以定义从扫描仪lnscn到瞳孔分光镜sm的非扫描(例如稳定或静止)收集光束,将所述收集光束折叠到相机cmr。在瞳孔分光镜sm处,反射光(或在荧光成像的情况下发射光)与照明光分离到指向相机cmr的检测路径上,相机cmr可以是具有光传感器以捕获图像的数码相机。成像(例如物镜)透镜imgl可以定位在检测路径中以将眼底成像到相机cmr。与物镜objl的情况一样,成像透镜imgl可以是本领域已知的任何类型的透镜(例如折射、衍射、反射或混合透镜)。额外的操作细节,特别是减少图像伪影的方法,在pct公开号wo2016/124644中进行了描述,其内容通过引用整体并入本文。相机cmr捕获接收到的图像,例如它创建一个图像文件,该文件可以由一个或多个(电子)处理器或计算设备(例如图20中所示的计算机系统)进一步处理。因此,收集光束(从扫描线光束sb的所有扫描位置返回的)由相机cmr收集,并且可以(例如通过蒙太奇)从单独捕获的收集光束的复合体中构建全画幅图像img。然而,还设想了其它扫描配置,包括其中照明光束在眼睛e上扫描并且收集光束在相机的光传感器阵列上扫描的配置。通过引用并入本文的pct公开wo2012/059236和美国专利公开号2015/0131050描述了狭缝扫描检眼镜的多个实施方式,包括其中所述返回光扫过相机的光传感器阵列以及其中所述返回光不扫过相机的光传感器阵列的各种设计。
89.在本示例中,相机cmr连接至处理器(例如处理模块)proc和显示器(例如显示模块、计算机屏幕、电子屏幕等)dspl,两者都可以是成像系统本身的一部分,或者可以是单独的、专用的处理和/或显示单元的一部分,例如计算机系统,其中数据通过电缆或计算机网络(包括无线网络)从相机cmr传递到计算机系统。显示器和处理器可以是一体的。显示器可以是传统的电子显示器/屏幕或触摸屏类型,并且可以包括用于向仪器操作员或用户显示信息和从其接收信息的用户界面。用户可以使用本领域已知任何类型的用户输入设备与显
示器交互,包括但不限于鼠标、旋钮、按钮、指针和触摸屏。
90.在进行成像时,可能希望患者的视线保持固定。实现其的一种方式是提供可以引导患者凝视的注视目标。取决于要成像的眼睛区域,注视目标可以在仪器内部或外部。图13中示出了内部注视目标的一个实施方式。除了用于成像的主光源ltsrc之外,可以放置第二可选光源fxltsrc,例如一个或多个led,以便使用透镜fxl、扫描元件fxscn和反射器/反射镜fxm将光图案成像到视网膜。固定扫描仪fxscn可以移动光图案的位置,并且反射器fxm将光图案从固定扫描仪fxscn引导到眼睛e的眼底f。优选地,使固定扫描仪fxscn定位使其位于系统的瞳孔平面,以便视网膜/眼底上的光图案可以根据所需的固定位置移动。
91.取决于所采用的光源和波长选择性过滤元件,狭缝扫描检眼镜系统能够在不同的成像模式下运行。当使用一系列彩色led(红色、蓝色和绿色)对眼睛成像时,可以实现真彩色反射成像(成像类似于临床医生在使用手持式或裂隙灯检眼镜检查眼睛时所观察到的成像)。可以在每个扫描位置打开每个led的情况下逐步建立每种颜色的图像,或者可以单独完整拍摄每个颜色的图像。可以将三色图像组合显示真彩色图像,或它们可以单独显示以突出视网膜的不同特征。红色通道很好地突出脉络膜,绿色通道突出视网膜,且蓝色通道突出前视网膜层。此外,特定频率下的光(例如单独的彩色led或激光)可用于激发眼睛中的不同荧光团(例如自发荧光),并且可以通过滤除激发波长来检测产生的荧光。
92.眼底成像系统还可以提供红外(ir)反射图像,例如通过使用红外激光(或其它红外光源)。红外(ir)模式的优势在于眼睛对ir波长不敏感。这可以允许用户在不干扰眼睛的情况下连续拍摄图像(例如在预览/对准模式下),以在仪器对准期间帮助用户。此外,ir波长增加了对组织的穿透力,并可以提供脉络膜结构的改善可视化。此外,荧光素血管造影(fa)和吲哚青绿血管造影(icg)成像可以通过在荧光染料注入受试者血流后收集图像来完成。
93.光学相干断层扫描成像系统
94.除了眼底摄影、眼底自发荧光(faf)、荧光素血管造影(fa)之外,也可以通过其它成像方式来创建眼科图像,诸如光学相干断层扫描(oct)、oct血管造影(octa)和/或眼部超声检查。如本领域所理解的,稍加修改的本发明或本发明的至少一部分可以应用于这些其它眼科成像方式。更具体地,本发明还可应用于由产生oct和/或octa图像的oct/octa系统产生的眼科图像。例如,本发明可以应用于正面oct/octa图像。美国专利8,967,806和8,998,411中提供了眼底成像仪的例子,美国专利6,741,359和9,706,915中提供了oct系统的例子,并且美国专利9,700,206和9,759,544中可以找到octa成像系统的例子,所有这些都通过引用整体并入本文。为了完整起见,这里提供示例性oct/octa系统。
95.图14示出了用于收集适用于本发明的眼睛的3
‑
d图像数据的广义频域光学相干断层扫描(fd
‑
oct)系统。fd
‑
oct系统oct_1包括光源ltsrc1。典型的光源包括但不限于具有短时间相干长度的宽带光源或扫频激光源。来自光源ltsrc1的光束通常通过光纤fbr1制定路线以照亮样本,例如眼睛e;典型的样本是人类眼睛中的组织。光源lrsrc1既可以是在光谱域oct(sd
‑
oct)情况下具有短时间相干长度的宽带光源或在扫频源oct(ss
‑
oct)情况下的波长可调激光源。可以扫描光,通常在光纤fbr1和样本e的输出之间使用扫描仪scnr1,以便光束(虚线bm)在要成像的样本区域上横向(在x和y上)扫描。在全场oct的情况下,不需要扫描仪,并且一次将光施加到整个所需的视场(fov)。通常将来自样本的散射光收集到用于为
用于照明的光制定路线的同一光纤fbr1中。来自同一光源ltsrc1的参考光沿单独的路径行进,在这种情况下涉及光纤fbr2和具有可调光延迟的反向反射器rr1。本领域技术人员将认识到,也可以使用透射参考路径,并且可以将可调延迟放置在干涉仪的样本或参考臂中。通常在光纤耦合器cplr1中,将收集的样本光与参考光结合,以在oct光检测器dtctr1(例如光电检测器阵列、数码相机等)中形成光干涉。尽管示出了通往检测器dtctr1的单个光纤端口,但本领域技术人员将认识到,可以将各种设计的干涉仪用于干扰信号的平衡或不平衡检测。来自检测器dtctr1的输出被提供给处理器cmp1(例如计算设备),处理器cmp1将观察到的干涉转换为样本的深度信息。深度信息可以存储在与处理器cmp1相关联的存储器中和/或显示在显示器(例如计算机/电子显示器/屏幕)scn1上。处理和存储功能可以位于oct仪器内,或者可以在外部处理单元(例如图20所示的计算机系统)上执行功能,收集的数据将传输到该处理单元。该单元可以专用于数据处理或者执行其它非常通用且不专用于oct装置的任务。例如,处理器cmp1可以含有现场可编程门阵列(fpga)、数字信号处理器(dsp)、专用集成电路(asic)、图形处理单元(gpu)、片上系统(soc)、中央处理单元(cpu)、通用图形处理单元(gpgpu)或它们的组合,其在传递到主机处理器之前或以并行方式执行一些或全部数据处理步骤。
96.干涉仪中的样本臂和参考臂可以由体光学、光纤或混合体光学系统组成,并且可以具有不同的架构,例如本领域技术人员已知的基于迈克尔逊、马赫
‑
曾德或公共路径的设计。本文使用的光束应解释为任何仔细定向的光路。代替机械扫描光束,光场可以照亮视网膜的一维或二维区域以生成oct数据(参见例如美国专利9332902;d.hillmann et al,“holoscopy
‑
holographic optical coherence tomography”optics letters 36(13):2390 2011;y.nakamura,et al,“high
‑
speed three dimensional human retinal imaging by line field spectral domain optical coherence tomography”optics express15(12):7103 2007;blazkiewicz et al,“signal
‑
to
‑
noise ratio study of full
‑
field fourier
‑
domain optical coherence tomography”applied optics 44(36):7722(2005))。在时域系统中,参考臂需要具有可调的光延迟来产生干扰。平衡检测系统通常用于td
‑
oct和ss
‑
oct系统,而光谱仪用于sd
‑
oct系统的检测端口。本文描述的发明可以应用于任何类型的oct系统。本发明的各个方面可以应用于任何类型的oct系统或其它类型的眼科诊断系统和/或多个眼科诊断系统,包括但不限于眼底成像系统、视野测试设备和扫描激光旋光仪。
97.在傅里叶域光学相干断层扫描(fd
‑
oct)中,每次测量都是实值光谱干涉图(sj(k))。实值光谱数据通常经过多个后处理步骤,包括背景减除、色散校正等。处理的干涉图的傅立叶变换产生复值oct信号输出这个复数oct信号的绝对值|aj|揭示了不同路径长度下的散射强度分布,因此根据样本中深度(z
‑
方向)而散射。类似地,也可以从复数值的oct信号中提取相位根据深度的散射轮廓称为轴向扫描(a
‑
扫描)。在样本中相邻位置测量的一组a
‑
扫描生成样本的横截面图像(断层扫描或b扫描)。在样本的不同横向位置收集的b扫描的收集构成了数据卷或立方体。对于特定的数据卷,术语快轴是指沿单个b
‑
扫描的扫描方向,而慢轴是指沿其收集多个b
‑
扫描的轴。术语“集群扫描”可以指为了分析运动对比度的目的通过在相同(或基本相同)位置(或区域)处重复采集而生成的单个单元或数据块,其可用于识别血流。集群扫描可以由在样本上大致相同位置以相对短时间间
隔收集的多个a扫描或b
‑
扫描组成。由于集群扫描中的扫描在同一区域,静态结构在集群扫描内的各次扫描之间保持相对不变,而满足预定义标准的扫描之间的运动对比度可以被识别为血流。产生b
‑
扫描的多种方式是本领域已知的,包括但不限于:沿水平或x方向,沿垂直或y方向,沿x和y的对角线,或以圆形或螺旋图案。b
‑
扫描可以在x
‑
z维度上,但可以是包括z
‑
维度的任何截面图像。
98.在oct血管造影术或功能性oct中,分析算法可以应用于在不同时间在样本上相同或大致相同的样本位置采集的oct数据(例如集群扫描)以分析运动或流动(参见例如美国专利申请号2005/0171438、2012/0307014、2010/0027857、2012/0277579和美国专利号6,549,801,所有这些都通过引用整体并入本文)。oct系统可以使用多种oct血管造影处理算法(例如运动对比算法)中的任何一种来识别血流。例如,运动对比算法可以应用于从图像数据中导出的强度信息(基于强度的算法)、来自图像数据的相位信息(基于相位的算法)或复杂的图像数据(基于复杂的算法)。正面图像是3d oct数据的2d投影(例如通过平均每个单独a
‑
扫描的强度,这样每个a
‑
扫描定义了2d投影中的像素)。类似地,正面脉管系统图像是显示运动对比度信号的图像,其中对应于深度的数据维度(例如沿a
‑
扫描的z方向)被显示为单个代表值(例如2d投影图像中的像素),通常通过对数据的全部或孤立部分进行求和或积分(参见例如美国专利号7,301,644,通过引用将其整体并入本文)。提供血管造影成像功能的oct系统可称为oct血管造影(octa)系统。
99.图15显示了正面脉管系统图像的例子。在使用本领域已知的任何运动对比度技术处理数据以突出运动对比度之后,与距视网膜内界膜(ilm)表面的给定组织深度相对应的一系列像素可以相加以生成脉管系统的正面(例如正面视图)图像。
100.神经网络
101.如上所讨论的,本发明可以使用神经网络(nn)机器学习(ml)模型。为了完整起见,本文提供了神经网络的一般性讨论。本发明可以单独或组合使用以下描述的神经网络架构中的任何一个。神经网络或神经网是互连神经元的(节点)网络,其中每个神经元代表网络中的一个节点。神经元的组可以分层排列,一层的输出前馈到在多层感知器(mlp)排列中下一层。mlp可以理解为前馈神经网络模型,其将一组输入数据映射到一组输出数据上。
102.图16示出了多层感知器(mlp)神经网络的示例。它的结构可以包括多个隐藏(例如内部)层hl1至hln,它们将输入层inl(接收一组输入(或向量输入)输入_1至输入_3)映射到输出层outl,其产生一组输出(或矢量输出),例如输出_1和输出_2。每层可以具有任何给定数量的节点,本文中示例性地显示为每层内的圆圈。在本示例中,第一隐藏层hl1有两个节点,而隐藏层hl2、hl3和hln各有三个节点。通常,mlp越深(例如mlp中隐藏层数越大),其学习能力就越大。输入层inl接收向量输入(示例性地显示为由输入_l、输入_2和输入_3组成的三维向量),并且可以将接收到的向量输入应用到隐藏层序列中的第一隐藏层hl1。输出层outl接收来自多层模型中最后一个隐藏层(例如hln)的输出,处理其输入,并产生向量输出结果(示例性地显示为由输出_l和输出_2组成的二维向量)。
103.典型地,每个神经元(或节点)产生单个输出,该输出被馈送到紧随其后的层中的神经元。但是隐藏层中的每个神经元都可以接收多个输入,要么来自输入层,要么来自在紧接前一隐藏层中的神经元的输出。通常,每个节点都可以对其输入应用一个函数来为该节点产生一个输出。隐藏层(例如学习层)中的节点可以将相同的函数应用于它们各自的输入
以产生其各自的输出。然而,一些节点,例如输入层inl中的节点仅接收一个输入并且可能是被动的,这意味着它们只是将其单个输入的值转送到其输出,例如它们将其输入的副本提供到它们的输出,如由输入层inl节点内的虚线箭头所示。
104.出于说明目的,图17显示了由输入层inl’、隐藏层hl1’和输出层outl’组成的简化神经网络。输入层inl’显示为具有两个输入节点il和i2,其分别接收输入输入_1和输入_2(例如层inl’的输入节点接收二维的输入矢量)。输入层inl’前馈到具有两个节点h1和h2的一个隐藏层hl1’,该层又前馈到两个节点o1和o2的输出层outl’。神经元之间的互连或链接(说明性显示为实心箭头)的权重为w1到w8。典型地,除了输入层,节点(神经元)可以接收其最近前一层节点的输出作为输入。每个节点可以通过将其每个输入乘以每个输入的相应互连权重,将其输入的乘积求和,添加(或乘以)由可能与该特定节点相关联的另一个权重或偏差(例如分别对应节点h1、h2、o1和o2的节点权重w9、w10、w1l、w12)定义的常数,然后对结果应用非线性函数或对数函数,计算其输出。非线性函数可以称为激活函数或传递函数。多个激活函数是本领域已知的,并且具体激活函数的选择对于本讨论并不关键。然而,需要注意的是,ml模型的操作或神经网的行为取决于权重值,而权重值可以学习以便神经网络为给定输入提供所需的输出。
105.神经网学习(例如被训练来确定)适当的权重值,以在训练或学习阶段为给定输入实现所需的输出。在训练神经网之前,每个权重都可以单独分配初始(例如随机和任选的非零)值,例如随机数种子。分配初始权重的各种方法在本领域中是已知的。然后训练(优化)权重,以便对于给定的训练向量输入,神经网络产生接近于期望(预定)训练向量输出的输出。例如,权重可以通过称为反向传播的技术在数千个迭代循环中进行增量调整。在每个反向传播循环中,训练输入(例如向量输入或训练输入图像/样本)通过神经网络前馈以确定其实际输出(例如向量输出)。然后基于实际神经元输出和该神经元的目标训练输出(例如对应于当前训练输入图像/样本的训练输出图像/样本)计算每个输出神经元或输出节点的误差。然后通过神经网络传播回来(在从输出层返回输入层的方向上),基于每个权重对整体误差的影响程度更新权重,以便神经网络的输出更接近所需训练输出。然后重复这个循环,直到神经网络的实际输出在给定训练输入的期望训练输出的可接受误差范围内。可以理解的是,每个训练输入可能需要多次反向传播迭代才能达到所需的误差范围。通常一个历元是指所有训练样本的一次反向传播迭代(例如一次前向传播和一次后向传播),这样训练神经网络可能需要许多历元。一般来说,训练集越大,训练的ml模型的性能越好,因此可以使用各种数据增强方法来增加训练集的大小。例如,当训练集包括成对对应的训练输入图像和训练输出图像时,可以将训练图像划分为多个对应的图像段(或碎片)。来自训练输入图像和训练输出图像的相应碎片可以配对以从一个输入/输出图像对中定义多个训练碎片对,这扩大了训练集。然而,在大型训练集上的训练对计算资源提出了很高的要求,例如存储和数据处理资源。通过将大型训练集划分为多个小碎片,可以减少计算需求,其中小批量(mini
‑
batch)大小定义了一次向前/向后传递中的训练样本数量。在这情况下,一个历元可包括多个小批量。另一个问题是nn过度拟合训练集的可能性,从而降低了从特定输入泛化到不同输入的能力。可以通过创建神经网络集成体或在训练期间随机删除神经网络中的节点来缓解过度拟合的问题,这有效地从神经网络中删除了丢弃的节点。本领域已知各种丢弃调节方法(dropout regulation method),诸如逆丢弃。
106.应当注意的是,经训练的nn机器模型的操作不是操作/分析步骤的简单算法。事实上,当经训练的nn机器模型接收到输入时,不会对输入进行传统意义上的分析。相反,无论输入的主题或性质(例如定义实时图像/扫描的向量或定义某些其他实体的向量,例如人口统计描述或活动记录),输入将经受与训练神经网络相同的预定义架构构造(例如相同的节点/层排列、训练的权重和偏差值、预定义的卷积/反卷积操作、激活函数、池化操作等),并且可能不清楚经训练的网络的架构构造如何产生其输出。此外,经训练的权重和偏差的值不是确定性的,并且取决于许多因素,例如给予神经网络进行训练的时间(例如训练中的历元数)、训练开始前权重的随机起始值、训练nn的机器的计算机架构、训练样本的选择、训练样本在多个小批次中的分布、激活函数的选择、修改权重的误差函数的选择和甚至训练在一台机器上中断(例如拥有第一计算机架构)并在另一台机器上完成(例如拥有不同的计算机架构)。关键是经训练的ml模型达到某些输出的原因尚不清楚,并且目前正在进行大量研究以试图确定ml模型基于其输出的因素。因此,神经网络对实时数据的处理不能简化为简单的步骤算法。相反,其操作取决于其训练架构、训练样本集、训练序列以及ml模型训练中的各种情况。
107.综上所述,nn机器学习模型的构建可以包括学习(或训练)阶段和分类(或操作)阶段。在学习阶段,神经网络可以针对特定目的进行训练,并且可以提供一组训练示例,包括训练(样本)输入和训练(样本)输出,并且可选地包括一组验证示例来测试训练进度。在这个学习过程中,与神经网络中的节点和节点互连相关的各种权重被增量调整,以减少神经网络的实际输出和期望的训练输出之间的误差。以这种方式,可以使多层前馈神经网络(例如上面讨论的)能够将任何可测量的函数近似到任何所需的准确度。学习阶段的结果是已经学习(例如训练)的(神经网络)机器学习(ml)模型。在操作阶段,可以将一组测试输入(或实时输入)提交给学习(训练)的ml模型,该模型可以应用它所学到的知识,以基于测试输入生成输出预测。
108.与图15和16的常规神经网络一样,卷积神经网络(cnn)也由具有可学习权重和偏差的神经元组成。每个神经元接收输入,执行操作(例如点积),并可选地随后为非线性。然而,cnn可以在一端(例如输入端)接收原始图像像素,并在另一端(例如输出端)提供分类(或类别)分数。因为cnn期望图像作为输入,所以针对处理卷(例如图像的像素高度和宽度,加上图像的深度,例如颜色深度,诸如由三种颜色定义的rgb深度进行了优化:红色、绿色和蓝色)对它们进行优化。例如,可以针对3维排列的神经元对cnn的层进行优化。cnn层中的神经元也可以连接到它之前的层的小区域,而不是连接到全连接的nn中的所有神经元。cnn的最终输出层可以将完整图像缩减为沿深度维度排列的单个向量(分类)。
109.图18提供了一个示例卷积神经网络架构。卷积神经网络可以定义为两层或多层(例如层1到层n)的序列,其中层可以包括(图像)卷积步骤、(结果的)加权求和步骤和非线性函数步聚。可以通过应用滤波器(或内核)对其输入数据执行卷积,例如在跨输入数据的移动窗口上,以生成特征图。每个层和层的分量可以具有不同的预先确定的滤波器(来自滤波器组)、权重(或加权参数)和/或函数参数。在本示例中,输入数据是图像,它可以是图像的原始像素值,具有给定的像素高度和宽度。在本示例中,输入图像被示为具有三个颜色通道rgb(红色、绿色和蓝色)的深度。任选地,输入图像可以经过各种预处理,并且预处理结果可以代替原始输入图像或作为原始输入图像的补充输入。图像预处理的一些示例可以包
括:视网膜血管图分割、色彩空间转换、自适应直方图均衡、连通分量生成等。在层内,可以在给定的权重和它们在输入卷中连接到的小区域之间计算点积。配置cnn的许多方式在本领域中是已知的,但作为示例,可以将层配置为应用逐元素激活函数,例如max(0,x)阈值为零。可以执行池化函数(pooling function)(例如沿x
‑
y方向)以对卷进行下采样。全连接层可用于确定分类输出并产生一维输出向量,这已被发现对图像识别和分类很有用。然而,对于图像分割,cnn需要对每个像素进行分类。由于每个cnn层都倾向于降低输入图像的分辨率,因此需要另一个阶段将图像上采样回其原始分辨率。这可以通过应用转置卷积(或反卷积)阶段tc来实现,该阶段通常不使用任何预定义的插值方法,而是具有可学习的参数。
110.卷积神经网络已成功地应用于许多计算机视觉问题。如上所解释的,训练cnn通常需要大的训练数据集。u
‑
net架构基于cnn,并且通常可以在比传统cnn更小的训练数据集上进行训练。
111.图19示出了一个示例u
‑
net架构。本示例性u
‑
net包括输入模块(或输入层或阶段),其接收任何给定尺寸(例如128x128像素大小)的输入u
‑
输入(例如输入图像或图像碎片)。输入图像可以是眼底图像、oct/octa正面、b
‑
扫描图像等。然而,应当理解的是,输入可以是任何大小和维度。例如,输入图像可以是rgb彩色图像、单色图像、卷图像等。输入图像经过一系列处理层,每个处理层都以示例性大小进行说明,但这些大小仅用于说明目的,并且将取决于例如图像的大小、卷积滤波器和/或池化阶段。本架构由收缩路径(由四个编码模块组成)和扩展路径(由四个解码模块组成)、以及相应模块/阶段之间的四个复制
‑
和
‑
裁剪链接(例如cc1到cc4)组成,所述复制
‑
和
‑
裁剪链接复制收缩路径中一个编码模块的输出,并将其连接到扩展路径中相应解码模块的输入。这产生了典型的u
‑
形,该架构由此得名。收缩路径类似于编码器,并且其基本功能是通过紧凑的特征图捕获上下文。在本示例中,收缩路径中的每个编码模块包括两个卷积神经网络层,其后可以跟随一个最大池化层(例如下采样层)。例如,输入图像u_输入经过两个卷积层,每个层有32个特征图。每次池化时特征图的数量可能会翻倍,从第一方块中的32个特征图开始,第二方块中的64个,以此类推。因此,收缩路径形成了由多个编码模块(或阶段)组成的卷积网络,每个模块提供卷积阶段,然后是激活函数(例如整流线性单元、relu或s函数层)和最大池化操作。扩展路径类似于解码器,并且其功能是提供定位并保留空间信息,尽管在收缩阶段进行了下采样和任何最大池化。在收缩路径中,空间信息减少,而特征信息增加。扩展路径包括多个解码模块,其中每个解码模块将其当前值与相应编码模块的输出连接起来。也就是说,特征和空间信息通过一系列上卷积(例如,上采样或转置卷积或反卷积)和与来自收缩路径的高分辨率特征的连接(例如通过cc1到cc4)在扩展路径中组合。因此,反卷积层的输出与来自收缩路径的相应(任选裁剪的)特征图连接,然后是两个卷积层和激活函数(任选批量归一化)。来自扩展路径中最后一个模块的输出可以馈送到另一处理/训练块或层,例如分类器块,其可以与u
‑
net架构一起训练。
112.收缩路径和扩展路径之间的模块/阶段(bn)可称为“瓶颈”。瓶颈bn可以由两个卷积层组成(具有批量归一化和任选的退出)。
113.计算设备/系统
114.图20示出了一个示例计算机系统(或计算设备或计算机设备)。在一些实施方式中,一个或多个计算机系统可提供本文所述或示例的功能和/或执行本文所述或示例的一
种或多种方法的一个或多个步骤。计算机系统可以采用任何合适的物理形式。例如,计算机系统可以是嵌入式计算机系统、片上系统(soc)、单板计算机系统(sbc)(例如模块计算机(com)或模块系统(som))、台式计算机系统、膝上型计算机或笔记本计算机系统、计算机系统网格、移动电话、个人数字助理(pda)、服务器、平板计算机系统、增强/虚拟现实设备,或这些中两个或更多个的组合。在适当的情况下,计算机系统可以存在在云中,其中可以包括一个或多个网络中的一个或多个云组件。
115.在一些实施方式中,计算机系统可包括处理器cpnt1、内存cpnt2、存储器cpnt3、输入/输出(i/o)接口cpnt4、通信接口cpnt5和总线cpnt6。计算机系统还可任选地包括显示器cpnt7,例如计算机监视器或屏幕。
116.处理器cpnt1包括用于执行指令(例如构成计算机程序的那些)的硬件。例如,处理器cpnt1可以是中央处理单元(cpu)或通用计算图形处理单元(gpgpu)。处理器cpnt1可以从内部寄存器、内部缓存、内存cpnt2或存储器cpnt3检索(或获取)指令,解码和执行指令,并将一个或多个结果写入内部寄存器、内部缓存、内存cpnt2或存储器cpnt3。在特定的实施方式中,处理器cpnt1可以包括一个或多个用于数据、指令或地址的内部缓存。处理器cpnt1可以包括一个或多个指令缓存、一个或多个数据缓存,例如用来保存数据表。指令缓存中的指令可以是内存cpnt2或存储器cpnt3中指令的副本,并且指令缓存可以加速处理器cpnt1对这些指令的检索。处理器cpnt1可以包括任何合适数量的内部寄存器,并且可以包括一个或多个算术逻辑单元(alu)。处理器cpnt1可以是多核处理器;或包含一个或多个处理器cpnt1。尽管本公开描述并说明了特定处理器,但本公开设想了任何合适的处理器。
117.内存cpnt2可以包括主内存,用于存储处理器cpnt1在处理期间执行或保存临时数据的指令。例如,计算机系统可以将指令或数据(例如数据表)从存储器cpnt3或从另一个源(例如另一个计算机系统)加载到内存cpnt2。处理器cpnt1可以将内存cpnt2中的指令和数据加载到一个或多个内部寄存器或内部缓存。为了执行指令,处理器cpnt1可以从内部寄存器或内部缓存中检索和解码指令。在指令执行期间或之后,处理器cpnt1可以将一个或多个结果(可能是中间或最终结果)写入内部寄存器、内部缓存、内存cpnt2或存储器cpnt3。总线cpnt6可以包括一个或多个内存总线(每个可以包括地址总线和数据总线)并且可以将处理器cpnt1耦合到内存cpnt2和/或存储器cpnt3。任选地,一个或多个内存管理单元(mmu)促进处理器cpnt1和内存cpnt2之间的数据传输。内存cpnt2(其可以是快速易失性内存)可以包括随机存取内存(ram),例如动态ram(dram)或静态ram(sram)。存储器cpnt3可以包括数据或指令的长期或大容量存储器。存储器cpnt3可以在计算机系统的内部或外部,并且包括一个或多个磁盘驱动器(例如硬盘驱动器hdd或固态驱动器ssd)、闪存、rom、eprom、光盘、磁光盘、磁带、通用串行总线(usb)可访问驱动器或其它类型的非易失性存储器。
118.i/o接口cpnt4可以是软件、硬件或两者的组合,并且包括一个或多个用于与i/o设备通信的接口(例如串行或并行通信端口),这可以实现与人(例如用户)的通信。例如,i/o设备可以包括键盘、小键盘、麦克风、监视器、鼠标、打印机、扫描仪、扬声器、静态相机、手写笔、平板电脑、触摸屏、轨迹球、摄像机、另一合适的i/o设备或这些中两个或更多个的组合。
119.通信接口cpnt5可以提供网络接口,用于与其它系统或网络进行通信。通信接口cpnt5可以包括蓝牙接口或其它类型的基于数据包的通信。例如,通信接口cpnt5可以包括网络接口控制器(nic)和/或无线nic或用于与无线网络通信的无线适配器。通信接口cpnt5
可以提供与wi
‑
fi网络、自组织网络、个人局域网(pan)、无线pan(例如蓝牙wpan)、局域网(lan)、广域网(wan)、城域网(man)、蜂窝电话网络(例如如全球移动通信系统(gsm)网络)、互联网或这些中两个或更多个的组合的通信。
120.总线cpnt6可以提供计算系统的上述组件之间的通信链接。例如,总线cpnt6可以包括加速图形端口(agp)或其它图形总线、增强型工业标准架构(eisa)总线、前端总线(fsb)、超传输(ht)互连、行业标准架构(isa)总线、无限带宽技术(infiniband)总线、低引脚数(lpc)总线、内存总线、微通道架构(mca)总线、外围组件互连(pci)总线、pci
‑
express(pcie)总线、串行高级技术附件(sata)总线、视频电子标准协会本地(vlb)总线或其它合适的总线或这些中两个或更多个的组合。
121.尽管本公开描述并图示了具有特定数量处于特定布置的特定组件的特定计算机系统,但是本公开设想了具有任何合适数量以任何合适布置的任何合适组件的任何合适的计算机系统。
122.在本文中,在适当的情况下,计算机可读的非暂时性存储介质或介质可以包括一个或多个基于半导体的或其它集成电路(ic)(诸如例如现场可编程门阵列(fpga)或专用ic(asic))、硬盘驱动器(hdd)、混合硬盘驱动器(hhd)、光盘、光盘驱动器(odd)、磁光盘、磁光驱动器、软盘、软盘驱动器(fdd)、磁带、固态驱动器(ssd)、ram驱动器、安全数字卡或驱动器、任何其它合适的计算机可读非暂时性存储介质或这些中两个或更多个的任何合适组合。在适当的情况下,计算机可读的非暂时性存储介质可以是易失性、非易失性、或易失性与非易失性的组合。
123.虽然已经结合多个具体实施方式描述了本发明,但对于本领域技术人员来说明显的是,根据前面的描述,许多进一步的替代、修改和变化将是显而易见的。因此,本文描述的发明旨在涵盖可能落入所附权利要求的精神和范围内的所有替代、修改、应用和变化。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。