基于vr的车身控制系统和方法
技术领域
1.本发明涉及vr技术领域,具体为基于vr的车身控制系统和方法。
背景技术:
2.vr(voice recognition,语音识别技术)技术早在2000年左右已应用于个人计算的机输入法中,当前已广泛使用于各类专业场景,如:家庭智能网关及智能家居控制、手机导航、儿童玩具等。语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等,通过语音识别、语义转换、信息筛选、特征匹配、行为执行、信息反馈的流程,能够有效地降低各领域设备操作难度和复杂度、缩短设备操作时间,并提升设备交互的友好性。随着硬件性能、网络通信能力、云端计算能力及ai能力的大幅度拉升,语音识别技术将继续拓展或进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。还会从单一信息获取方式发展为完整的人机互动交流,整体趋势已不可逆。故汽车控制上若通过语音识别技术对车身空调、天窗、电动背门等进行控制,不仅是技术前沿应用落地;还能降低车辆功能的操作复杂度,提升车身控制的操作友好性;更能缩减驾驶员驾驶过程中操作车身难度,降低驾驶风险。
技术实现要素:
3.本发明的目的在于克服现有技术的不足,提供基于vr的车身控制系统和方法。
4.本发明的目的是通过以下技术方案来实现的:
5.基于vr的车身控制系统和方法,包括以下步骤:
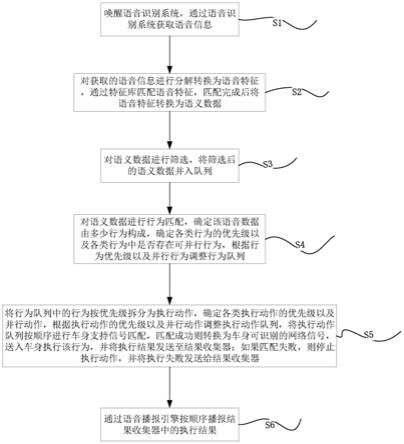
6.s1,唤醒语音识别系统,通过语音识别系统获取语音信息,执行步骤s2;
7.s2,对获取的语音信息进行分解转换为语音特征,通过特征库匹配语音特征,匹配完成后将语音特征转换为语义数据,执行步骤s3;
8.s3,对语义数据进行筛选,将筛选后的语义数据并入队列,执行步骤s4;
9.s4,对语义数据进行行为匹配,确定该语音数据由多少行为构成,确定各类行为的优先级以及各类行为中是否存在可并行行为,根据行为优先级以及并行行为调整行为队列,执行步骤s5;
10.s5,将行为队列中的行为按优先级拆分为执行动作,确定各类执行动作的优先级以及并行动作,根据执行动作的优先级以及并行动作调整执行动作队列,将执行动作队列按顺序进行车身支持信号匹配,匹配成功则转换为车身可识别的网络信号,送入车身执行该行为,并将执行结果发送至结果收集器;如果匹配失败,则停止执行动作,并将执行失败发送给结果收集器,执行步骤s6;
11.s6,通过语音播报引擎按顺序播报结果收集器中的执行结果。
12.进一步的,所述步骤s1中,语音识别系统可通过特征语音唤醒词或者语音按键来唤醒。
13.进一步的,所述步骤s4中,各类行为的优先级和并行行为通过优先级识别语义队
列来确认。
14.进一步的,所述步骤s5中,各类执行动作的优先级和并行动作通过优先级识别行为队列来确认。
15.进一步的,所述语音播报引擎可通过语义数据对每个执行结果的播报次数以及播报音量进行设定。
16.进一步的,所述步骤s4中,调整队列的方式为:确认行为优先级,高优先级置于行为队列顶部,低优先级放入行为队列尾部,并行行为按照其中一个行为的优先级在行为队列中顺序放置;若队列已满且待放置行为为高优先级行为,则抛弃原行为队列的尾部行为,将高优先级行为放入对应优先级位置;若行为队列已满且待放置行为为低优先级行为,则直接抛弃该行为。
17.进一步的,所述步骤s6中,按顺序播报结果收集器中的执行结果的方式为:若执行动作的优先级高于当前结果播报优先级则播报结果入播报队列首位并打断当前语音播报,送入新播报信息;若执行动作优先级不高于当前播报结果优先级,则放入队列中指定优先级的位置;若播报队列满且优先级不高于队列内最低优先级,则丢弃当前需要播报的结果。
18.本发明的有益效果是:
19.本发明通过语义接收、语义筛选、信息匹配、行为拆分、行为执行分发、行为结果采集及结果播报等功能,基于java语言编写,应用于安卓p(9)系统平台开发,面向汽车车身控制。实现了通过汽车娱乐系统语音功能对车身功能进行控制的目的,降低车辆功能的操作复杂度,提升车身控制的操作友好性;缩减驾驶员驾驶过程中操作车身难度,降低驾驶风险。
附图说明
20.图1为本发明vr控制车身的流程图;
21.图2为本发明整体设计框架图;
22.图3为vr层级图;
23.图4为vr系统框图。
具体实施方式
24.下面结合本发明的附图1~4,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施。
25.在本发明的描述中,需要理解的是,术语“逆时针”、“顺时针”“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
26.在本次发明中优先选择双目结构光系统,仅是为了便于描述本发明,而不是指示或暗示本发明只能使用双目结构光系统。
27.基于vr的车身控制系统和方法,包括以下步骤:
28.s1,唤醒语音识别系统,通过语音识别系统获取语音信息,执行步骤s2;
29.s2,对获取的语音信息进行分解转换为语音特征,通过特征库匹配语音特征,匹配完成后将语音特征转换为语义数据,执行步骤s3;
30.s3,对语义数据进行筛选,将筛选后的语义数据并入队列,执行步骤s4;
31.s4,对语义数据进行行为匹配,确定该语音数据由多少行为构成,确定各类行为的优先级以及各类行为中是否存在可并行行为,根据行为优先级以及并行行为调整行为队列,执行步骤s5;
32.s5,将行为队列中的行为按优先级拆分为执行动作,确定各类执行动作的优先级以及并行动作,根据执行动作的优先级以及并行动作调整执行动作队列,将执行动作队列按顺序进行车身支持信号匹配,匹配成功则转换为车身可识别的网络信号,送入车身执行该行为,并将执行结果发送至结果收集器;如果匹配失败,则停止执行动作,并将执行失败发送给结果收集器,执行步骤s6;
33.s6,通过语音播报引擎按顺序播报结果收集器中的执行结果。
34.本方案的工作原理简述:
35.本发明主要分为语音识别、语义接受及筛选、语义匹配、行为拆分机下发,结果播报、信号转换几大模块;
36.语音识别:实时接收mic数据和监听语音按键行为,再收到特征唤醒词或语音按键按下行为后,立即唤醒语音识别系统并开始获取mic语音数据,获取mic语音信息,分解语音信息为语音特征,进行特征库匹配后转换为语义,并根据各路mic数据整体分析计算后确定发声位置;
37.语义接受及筛选:
38.利用线程池接收语义数据并入队,通过优先级识别语义队列,对队列内语义信息进行筛选,确定语义的安全性和有效性,拦截错误语义、异常渠道语义、错误接口的语义输入,保证正确语义入队;开启轻量级线程,收到语义后立即进行入口检查,检查通道信息来源、通道检验值、session id标志等关键字,确定为非法语义则立即剔除,回到接收语义状态;检查语义来源,确定平台关键字、平台校验值是否匹配,平台是否属于已支持类型,若不满足则回到语义接收状态,已满足语义则送入fifo缓冲区。此处采用轻量级线程设计,语义快速筛选及启用回写模式,确保收到的语义包能够在下一个语义数据到来前处理完成并送入fifo缓冲区。异常通道及异常平台信息记录至日志
39.语义匹配:
40.对语义进行行为匹配,确定该语义由多少行为构成,确定各类行为的执行顺序、执行优先级、是否可并行等,对语义特征进行筛选,识别覆盖、替换信号后移除被覆盖语义,并通过优先级识别行为队列调整队列顺序,确保安全相关等高优先级行为能够得到最先执行;启动后获取支持语义特征值,语义筛选线程逐条获取接收fifo缓冲区内语义,通过与语义特征值的异或校验确认是否支持,不支持则抛弃该语义,并界面展示或语音播报不支持操作;拆分语义为单设备或多设备件联动行为,判断行为是否需要覆盖队列中行为,若需覆盖则抛弃队列内需要被覆盖行为后入队;确认匹配语义读取优先级值,高优先级置于行为队列顶部,低优先级放入队列尾部;若队列已满且为高优先级语义,则抛弃行为队列尾部,
将高优先级语义拆分的行为放入对应优先级位置;若队列已满且为低优先级语义,则直接抛弃已拆分行为;
41.行为拆分及下发,结果播报:
42.拆分行为至具体执行动作,确定各类动作的执行顺序、执行优先级、是否可并行等,进行结果等待。收反馈结果后,对结果数据进行确认后,调用结果播报引擎依据要求的结果输出方式进行界面展示及语音播报;各模块后台服务的行为拆分线程从行为缓冲区中取出自身需要执行的行为,依据执行行为拆分为多个具体的执行动作,标识出每个动作的执行先后顺序,是否可以并行,是否强制打断已执行动作,送入执行队列,语义范围、行为优先级、执行行为拆分为执行动作的具体标识将送入执行结果收集器收集结果,执行队列按优先级定义及是否打断已执行的等级定义等全部下发所有执行动作成功后行为拆分线程继续取下一个行为进行拆分,若有行为执行失败则终止执行并发送执行失败至结果收集器;依据语义范围、执行行为拆分信息确定需要收集结果数量,待收到所有结果执行完成后,若行为优先级高于当前结果播报优先级则播报结果入播报队列首位并打断当前ui显示和语音播报,送入新播报信息;若行为优先级不高于当前播报结果优先级,则放入队列中指定优先级的位置;若播报队列满且优先级不高于队列内最低优先级,则丢弃当前需要播报的结果。每个结果都会依据语义要求确定若存在界面显示则弹出对应显示界面,否则仅进行语音播报;根据不同语义要求定义重复语音播报次数;并依据语义定义不同的播报音量,同时送入语音播报引擎;
43.信号转换:
44.将执行步骤转换为车身可识别的网络信号并下发至传输层或将车身网络信号转换为vr引擎可识别信号并传递给结果收集队列;收到执行动作的信号内容,对信号内容与车身信号匹配,匹配失败则直接丢弃,返回执行失败;匹配成功则转换动作信号为车身信号,并将转换后信号送入车身信号发送缓冲区,再由车身信号收发器将其送入车身网络。
45.进一步的,所述步骤s1中,语音识别系统可通过特征语音唤醒词或者语音按键来唤醒。
46.进一步的,所述步骤s4中,各类行为的优先级和并行行为通过优先级识别语义队列来确认。
47.进一步的,所述步骤s5中,各类执行动作的优先级和并行动作通过优先级识别行为队列来确认。
48.进一步的,所述语音播报引擎可通过语义数据对每个执行结果的播报次数以及播报音量进行设定。
49.进一步的,所述步骤s4中,调整队列的方式为:确认行为优先级,高优先级置于行为队列顶部,低优先级放入行为队列尾部,并行行为按照其中一个行为的优先级在行为队列中顺序放置;若队列已满且待放置行为为高优先级行为,则抛弃原行为队列的尾部行为,将高优先级行为放入对应优先级位置;若行为队列已满且待放置行为为低优先级行为,则直接抛弃该行为。
50.进一步的,所述步骤s6中,按顺序播报结果收集器中的执行结果的方式为:若执行动作的优先级高于当前结果播报优先级则播报结果入播报队列首位并打断当前语音播报,送入新播报信息;若执行动作优先级不高于当前播报结果优先级,则放入队列中指定优先
级的位置;若播报队列满且优先级不高于队列内最低优先级,则丢弃当前需要播报的结果。
51.以上所述仅是本发明的优选实施方式,应当理解所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。