1.本发明属于生物技术领域,更具体而言涉及用于抑郁症筛查诊断标志 物、装置、方法及介质。
背景技术:
2.根据世界卫生组织who发布的报告,抑郁症是人类第二大死亡原因、 首要致残原因。目前,全球抑郁症患者3.5亿人,我国成年人的终身患病率 为6.9%,抑郁症患者的自杀率约为10%
‑
15%,因抑郁自杀是15岁至29岁 人群第二大死因。我国的抑郁症诊疗领域存在“三高三低”的特点,“三 高”即高发病率、高复发率、高自杀率;“三低”即低知晓率、低就诊率、 低治疗率。
3.目前,抑郁症的诊断主要面临的问题是诊断缓慢、困难并且主观。目前, 还没有任何可靠的生物标记可以用来诊断精神疾病;精神疾病的诊断依据主 要是国际疾病分类、精神障碍诊断与统计手册,需要有经验的医生依据调查 问卷和自己的经验进行判断。通过医生的询问观察及量表,易受主观因素影 响,而且由于缺乏客观的辅助诊断手段,在治疗、康复过程中不能实时监测 病情的发展变化,无法实现精准评价疗效,更无法做到精准分型、个性化治 疗。近年来在癌症等领域迅速发展的精准医学、个体化诊疗,在抑郁症领域 发展缓慢。目前,国际上已有研究在探索基于脑电、心电、肌电等生理指标, 对精神健康状态进行评估的技术。这些技术能够识别个体情感、压力水平、 情感障碍等因素的变化。但是对于与抑郁症发生、发展密切相关的生化、代 谢、炎症、基因网络等机理反映甚少。
4.因此,本领域中需要建立对抑郁状态进行量化、评估与分类的模型。
技术实现要素:
5.本发明的目标在于建立基于dna甲基化的抑郁特征的客观、量化评价 标记物、装置、方法和介质。
6.因此,在第一方面,本发明提供了一种用于抑郁症筛查诊断的标志物, 所述标志物包括两组基因集的甲基化位点:
7.第一组基因集包括:entpd3、itga4、krt83、laptm4b、lin54、 nefl、nup133、otos、pnldc1、psca、rala和sox14,
8.第二组基因集包括:dcc、dhrs7c、echdc3、nkx2
‑
6、rab4a、 sigirr、syt12、tctn1、wdr89、c6orf72和flj20184;
9.其中所述第一组基因集的dna甲基化特征值是抑郁症筛查诊断的正标 志物,所述第二组基因集的dna甲基化特征值是抑郁症筛查诊断的负标志 物,
10.所述第一组基因集的dna甲基化特征值和所述第二组基因集的dna 甲基化特征值用于预测抑郁症。
11.在一个实施方案中,所述甲基化位点包括基因体gene body区域的甲基 化位点,优选还包括启动子区域promoter的甲基化位点。
12.在一个实施方案中,所述第一组基因集的dna甲基化位点如表2所示。
13.在一个实施方案中,所述第二组基因集的dna甲基化位点如表4所示。
14.在一个实施方案中,每个基因的甲基化特征值包括其基因体gene body 区位点的甲基化水平或它们均值,或者其基因体gene body区位点的甲基化 水平的均值与其启动子区位点的甲基化水平的均值的差值或simpo值。
15.在一个实施方案中,用甲基化抑郁指数(mdi,methyaltion derived depression index)进行抑郁预测,所述甲基化抑郁指数的计算是基于t测试的 t值的衍生结果,即:
[0016][0017]
其中为第一组基因集的甲基化特征值的均值,为第二组基因集的甲基 化特征值的均值,为第一组基因集的甲基化特征值的方差,为第二组基 因集的甲基化特征值的方差,n为第一组基因集的基因数量,m为第二组基 因集的基因数量。
[0018]
在一个实施方案中,mdi值大于0.5,优选大于0.7,更优选大于0.9。
[0019]
在第二方面,本发明提供了一种用于抑郁症筛查诊断的装置,所述装置 包括:
[0020]
数据获取模块,用于对待筛查受试者获取如下两组基因集的各个甲基化 位点的甲基化特征值,
[0021]
第一组基因集包括:entpd3、itga4、krt83、laptm4b、lin54、 nefl、nup133、otos、pnldc1、psca、rala和sox14,
[0022]
第二组基因集包括:dcc、dhrs7c、echdc3、nkx2
‑
6、rab4a、 sigirr、syt12、tctn1、wdr89、c6orf72和flj20184;
[0023]
计算模块,用于计算各个基因的甲基化特征值(如simpo值),并基 于所述两组基因集的simpo值,计算dna甲基化抑郁指数,预测抑郁程度。
[0024]
在一个实施方案中,所述甲基化位点包括基因体gene body区的甲基化 位点,优选还包括启动子区域的甲基化位点。
[0025]
在一个实施方案中,所述第一组基因集的dna甲基化位点如表2所示。
[0026]
在一个实施方案中,所述第二组基因集的dna甲基化位点如表4所示。
[0027]
在一个实施方案中,每个基因的甲基化特征值包括其基因体gene body 区域、启动子promoter区域位点的甲基化水平或它们均值,或者其基因体 gene body区位点的甲基化水平的均值与其启动子区位点的甲基化水平的均 值的差值或simpo值。
[0028]
在一个实施方案中,用甲基化抑郁指数mdi进行抑郁预测,所述甲基 化抑郁指数通过下式进行计算:
[0029][0030]
其中为第一组基因集的甲基化特征值的均值,为第二组基因集的甲基 化特征
值的均值,为第一组基因集的甲基化特征值的方差,为第二组基 因集的甲基化特征值的标准差,n为第一组基因集的基因数量,m为第二组 基因集的基因数量。在一个实施方案中,mdi值大于0.5,优选大于0.7,更 优选大于0.9。
[0031]
在第三方面,本发明提供了一种用于抑郁症筛查诊断的方法,所述方法 包括:
[0032]
(1)对待筛查受试者获取如下两组基因集的甲基化特征值,
[0033]
第一组基因集包括:entpd3、itga4、krt83、laptm4b、lin54、 nefl、nup133、otos、pnldc1、psca、rala和sox14,
[0034]
第二组基因集包括:dcc、dhrs7c、echdc3、nkx2
‑
6、rab4a、 sigirr、syt12、tctn1、wdr89、c6orf72和flj20184;
[0035]
(2)基于所述两组基因集的甲基化特征值,用于预测抑郁症。
[0036]
在一个实施方案中,所述甲基化位点包括基因体gene body区域的甲基 化位点,优选还包括启动子区域的甲基化位点。
[0037]
在一个实施方案中,所述第一组基因集的dna甲基化位点如表2所示。
[0038]
在一个实施方案中,所述第二组基因集的dna甲基化位点如表4所示。
[0039]
在一个实施方案中,每个基因的甲基化特征包括其基因体gene body区 位点的甲基化水平或它们均值,或者其基因体gene body位点的甲基化水平 的均值与其启动子区位点的甲基化水平的均值的差值或simpo值。
[0040]
在一个实施方案中,用甲基化抑郁指数进行抑郁预测,所述甲基化抑郁 指数通过下式进行计算:
[0041][0042]
其中为第一组基因集的甲基化特征值的均值,为第二组基因集的甲基 化特征值的均值,为第一组基因集的甲基化特征值的方差,为第二组基 因集的甲基化特征值的方差,n为第一组基因集的基因数量,m为第二组基 因集的基因数量。
[0043]
在一个实施方案中,mdi值大于0.5,优选大于0.7,更优选大于0.9。
[0044]
在第四方面,本发明提供了用于抑郁症筛查诊断的介质,所述介质包括 实现本发明第三方面的方法的程序。
[0045]
基于dna甲基化指纹图谱的抑郁特征计算的标志物、装置、电子设备 及介质,涉及心理测量学、心理问卷客观化、生物信息学等交叉应用领域。
附图说明
[0046]
从下面结合附图对本发明的具体实施方式的描述中可以更好地理解本 发明。
[0047]
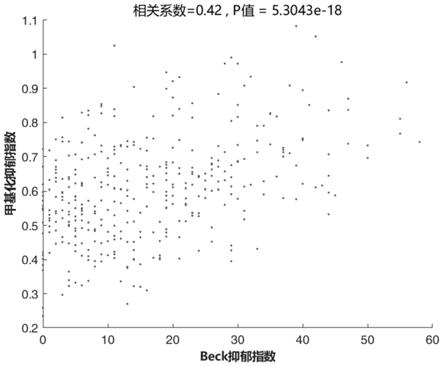
图1示出了甲基化抑郁指数与beck抑郁量表得分的相关性。
[0048]
图2示出了甲基化抑郁指数与多种心理量表得分的相关性。
[0049]
图3示出了利用甲基化抑郁指数对beck抑郁量表得分进行分类(得分 阈值35)。
[0050]
图4示出了利用甲基化抑郁指数对beck抑郁量表得分进行分类(得分 阈值25)。
[0051]
图5示出了标志物基因计算甲基化抑郁指数的稳健性分析。
具体实施方式
[0052]
本发明的抑郁特征标志物为由12个基因组成的正基因集合(见表1)、 11个基因组成的负基因集合(见表3)。所述正基因集的dna甲基化特征 值是抑郁症筛查诊断的正标志物,所述负基因集的dna甲基化特征值是抑 郁症筛查诊断的负标志物。正基因集中基因的dna甲基化特征值(例如 simpo值)与抑郁程度(如beck抑郁量表得分)显著正相关,负基因集中 基因的dna甲基化特征值(例如simpo值)与抑郁程度(如beck抑郁量 表得分)显著负相关,因此所述正基因集的dna甲基化水平和所述负基因 集的dna甲基化水平用于预测抑郁症。
[0053]
甲基化特征表示了基因的甲基化,甲基化特征值表示了基因的甲基化水 平,包括基因甲基化水平甲基化水平测量值及其衍生出的可以表征基因甲基 化水平的值。通常而言,基因体gene body区内的甲基化水平反映了基因的 转录活性,因此,在本发明中,所述甲基化位点包括基因体gene body区域 的甲基化位点。启动子区域的甲基化水平与基因活性有负相关,因此,在本 发明中,优选还包括启动子区域的甲基化位点。因此,每个基因的甲基化特 征值包括其基因体gene body区位点的甲基化水平或它们均值,或者其基因 体gene body区位点的甲基化水平的均值与其启动子区位点的甲基化水平的 均值的差值或simpo值。
[0054]
所述甲基化位点包括基因体gene body区域和甲基化位点和启动子区域 的甲基化位点,正基因集的甲基化位点和负基因集的甲基化位点分别见表3 和表4。对于受试者而言,甲基化位点的甲基化水平可以通过任何已知的方 法测量,例如通过illumina的humanmethylation450全基因组dna甲基化 芯片。在该芯片中,每个甲基化位点的甲基化水平以beta值表示。在本发明 中,每个基因的甲基化特征值包括其基因体gene body区位点的甲基化水平 或它们均值,或者其基因体gene body区位点的甲基化水平的均值与其启动 子区位点的甲基化水平的均值的差值或simpo值。
[0055]
在本发明中,用甲基化抑郁指数mdi进行抑郁预测,例如所述甲基化 抑郁指数是基于t测试的t值的衍生结果,即:
[0056][0057]
其中为第一组基因集的甲基化特征值的均值,为第二组基因集的甲基 化特征值的均值,为第一组基因集的甲基化特征值的方差,为第二组基 因集的甲基化特征值的方差,n为第一组基因集的基因数量,m为第二组基 因集的基因数量。
[0058]
在本发明中,用于抑郁症筛查诊断的方法通过用于抑郁症筛查诊断的装 置进行。所述数据获取模块可以包括甲基化测定装置,或者可以不包括甲基 化测定装置,而是从别处获取数据,例如从实验数据提供商或者从数据库。 所述计算模块可以通过计算机程序进行。
[0059]
表1、正基因列表:
[0060]
基因名称基因描述entpd3ectonucleoside triphosphate diphosphohydrolase 3itga4integrin subunit alpha 4krt83keratin 83laptm4blysosomal protein transmembrane 4betalin54lin
‑
54dream muvb core complex componentneflneurofilament,light polypeptidenup133nucleoporin 133otosotospiralinpnldc1parn like,ribonuclease domain containing 1pscaprostate stem cell antigenralaras like proto
‑
oncogene asox14sry
‑
box 14
[0061]
表2、正性标志物基因的甲基化位点列表
[0062]
[0063]
[0064][0065]
表3、负基因列表:
[0066]
基因名称基因描述dccdcc netrin 1receptordhrs7cdehydrogenase/reductase 7cechdc3enoyl
‑
coa hydratase domain containing 3nkx2
‑
6nk2 homeobox 6rab4arab4a,member ras oncogene familysigirrsingle ig and tir domain containingsyt12synaptotagmin 12tctn1tectonic family member 1wdr89wd repeat domain 89c6orf72chromosome 6open reading frame 72flj20184hypothetical protein loc54848
[0067]
其中syt12为突触结合蛋白synaptotagmin基因家族成员,推测与神经传导 有关。
[0068]
表4、负性标志物基因的甲基化位点列表
[0069]
[0070]
[0071][0072]
在表2和4的中,甲基化位点来自ncbi的人类参考基因组数据库 grch37版本的注释,表示为:illumina甲基化位点代码,染色体号码,染色体 位置,是否为启动子区域(其中p表示启动子promoter区域,o表示基因体 gene body区)。
[0073]
实施例
[0074]
下文中,结合示例性的实施方案更详细地描述本发明。然而,本文公开 的示例性的实施方案仅出于示例的目的,而不应该被认为旨在限定本发明的 保护范围。
[0075]
实施例1、dna甲基化抑郁指数与贝克抑郁自评量表的相关性研究。
[0076]
本实施例将白细胞dna甲基化数据,利用本发明提出的dna甲基化 标志物,根据正基因列表,负基因列表,计算dna甲基化抑郁指数,并与 经典的贝克抑郁自评量表等级分做相关性分析。
[0077]
测试数据包括422例受试者的血细胞dna甲基化数据,数据由illumina 的humanmethylation450全基因组dna甲基化芯片所产生,其中379例志 愿者有有效的贝克抑郁自评量表(beck depression inventory)数据。贝克抑 郁自评量表是经典的专门评测抑郁程度的量表,整个量表包括21组项目, 每组有4句陈述,每句之前标有的阿拉伯数字为等级分。dna甲基化芯片 检测人类基因组中485512个胞嘧啶位置的dna甲基化,其中绝大多数 (482421)个位置是cpg位点。每个甲基化位点的甲基化水平以beta值表 示,beta值代表特定位置胞嘧啶被甲基化的比例。芯片中同一基因的同一功 能区域内分布着多个甲基化位点,不同位点会被检测到不同的甲基化值。对 于芯片中的甲基化值根据制造商的说明书进
行归一化。
[0078]
比较正基因列表中的12个基因的甲基化特征值与负基因列表中的11个 基因的甲基化特征值。所述正基因集和负基因集的基因区甲基化位点见表2 或表4,甲基化抑郁指数是基于t测试的t值的衍生结果,即:
[0079][0080]
其中为第一组基因集的甲基化特征值的均值,为第二组基因集的甲基 化特征值的均值,为第一组基因集的甲基化特征值的方差,为第二组基 因集的甲基化特征值的方差,n为第一组基因集的基因数量,m为第二组基 因集的基因数量。
[0081]
也可以以基因为单位计算dna甲基化抑郁指数,即对每个基因赋予一 个甲基化特征值。对每个基因赋予一个甲基化特征值可以获得更好的结果, 因为这样消除了不同基因甲基化位点数量的影响。对于每个基因赋予一个甲 基化特征值有多种方法,一些示例性方法如下。在本实施例中,发明人比较 了12个基因的基因体gene body区甲基化位点的beta值平均值与负基因列表 中的11个基因的基因体区甲基化位点的beta值的平均值,将二者的差值作 为甲基化特征值。接着,发明人对每个基因的基因体区的甲基化位点的beta 值取平均值作为其甲基化水平,然后对正基因列表中的12个基因的基因体 区的甲基化水平和负基因列表中的11个基因基因体区的甲基化水平分别取 平均值,将二个均值的差值作为甲基化特征值。考虑到启动子区域甲基化对 基因活性的影响,发明人还对于每个基因的启动子区域甲基化水平取平均 值,在基因体区的甲基化水平的平均值中减去启动子区域甲基化水平取平均 值,进行甲基化特征值的计算。
[0082]
将上述经归一化的甲基化芯片数据,即甲基化位点
×
受试者样本矩阵 (cpg sites
×
sample),经上述操作,计算得到受试者的甲基化特征值图谱。 即基因
×
受试者样本矩阵(gene
×
sample)。
[0083]
另外,发明人利用其开发的simpo方法进行ewas(epigenome
‑
wideassociation study,表观基因组关联分析)研究。simpo方法可以将甲基化位 点的beta值,转化为基因的simpo值。simpo方法是基于基因体和启动子 区域的dna甲基化差值与基因的表达值显著相关,相关系数高达0.67,提 示基因体与启动子区域甲基化差值是一种具有明显生物学意义的特征,可以 用来预测基因表达的情况。simpo方法正是基于上述原理,在cpg位点甲 基化底层数据的基础上提取的基因水平的高阶特征。经过这一转化,一个基 因多个甲基化位点的beta值,转化为每个基因只有一个单一的simpo值, 该值与该基因的表达活性相关。以下简称为基因的simpo值。
[0084]
甲基化位点的beta值向simpo值的转化如下:
[0085]
simpo算法基于基因体(body)区域、启动子(promoter)区域的差异特征, 以每个基因的simpo得分来代表基因水平的dna甲基化程度,即甲基化特 征值。
[0086][0087]
位于基因体gene body区域的所有甲基化位点的beta值的平均值; 位于基因启动子promoter区域的所有甲基化位点的beta值得平均值;
[0088]
n:位于基因体gene body区域的甲基化位点数量;
[0089]
m:位于基因启动子promoter区域的甲基化位点数量;
[0090]
位于基因体gene body区域甲基化位点beta值的方差;
[0091]
位于基因启动子promoter区域甲基化位点beta值的方差。
[0092]
将上述经归一化的甲基化芯片数据,即甲基化位点
×
受试者样本矩阵 (cpg sites
×
sample),经simpo方法,计算得到受试者的甲基化特征值 图谱。即基因
×
受试者样本矩阵(gene
×
sample)。
[0093]
进一步采用本发明公开的抑郁特征标志物,即由12个基因组成的正基 因集合、11个基因组成的负基因集合,由到受试者的甲基化特征值图谱,计 算每个受试者的dna甲基化抑郁指数:
[0094]
每个受试者,取正基因集合的基因甲基化特征值(例如simpo值), 是一个12
×
1的变量,记为x,取负基因集合的基因甲基化特征值(例如 simpo值),是一个11
×
1的变量,记为y,用下式进行计算甲基化抑郁指 数:
[0095][0096]
其中为x的均值,为y的均值,为x的方差,为y的方差,n为 x的基因数量,m为y的基因数量。
[0097]
由此,得到甲基化抑郁指数,即抑郁特征的统计值。甲基化抑郁指数越 大表示抑郁程度越强。
[0098]
对于同时具有有效的dna甲基化测量与beck抑郁量表等级分的受试 者,计算甲基化抑郁指数与beck得分的pearson相关系数,以simpo值得 到的甲基化抑郁指数为例,结果如图1所示。二者具有显著的相关性,p值 为5.3e
‑
18,相关系数为0.42。根据甲基化抑郁指数x与beck抑郁量表得分 y建立拟合曲线,建立的函数是y=
‑
5.5547 36.16x。模型的r方为0.18,p 值为5.3e
‑
18。如果以beck得分高于14作为轻度情绪不良的判断点,则对应 的甲基化抑郁指数x的阈值为0.5408。如果以beck得分高于20作为中度抑 郁的判断点,则对应的甲基化抑郁指数x的阈值为0.7067。如果以beck得 分高于29作为重度抑郁的判断点,则对应的甲基化抑郁指数x的阈值为 0.9556。
[0099]
对于各种方法计算的甲基化特征值获得的甲基化抑郁指数与beck得分 均有类似
的相关性,对于对启动子区域甲基化水平值进行减除后的结果明显 优于仅使用基因体区甲基化水平得到的结果。
[0100]
实施例2、dna甲基化抑郁指数的特异性与区分效度研究。
[0101]
为了进一步了解所述甲基化抑郁指数是否特异性的反映了抑郁特征(而 不是其他心理学特征),发明人系统比较了甲基化抑郁指数与多种心理量表 的相关性。
[0102]
测试数据来源同实施例1,除了beck抑郁指数,分别计算了甲基化抑郁 指数与如下心理量表的相关性:创伤后应激障碍症状量表总分、累积压力指 数、社交网络生活压力指数、个人生活压力指数、童年期创伤问卷得分、当 前压力指数。甲基化抑郁指数计算,以及甲基化抑郁指数与心理量表得分的 相关性计算方法同实施例1,计算结果如图2所示。由图2中可以看出,甲 基化抑郁指数与beck抑郁量表得分相关系数最强,为0.42,与第二名的创 伤后应激障碍症状量表总分差别明显,说明发明人计算得到的甲基化抑郁指 数特异性地与beck抑郁指数相关。
[0103]
实施例3、利用甲基化抑郁指数对beck抑郁量表得分进行分类。
[0104]
根据beck抑郁量表得分阈值35为切分点,可以把所有受试者分为a、 b两类,即得分35以上的为a类(高抑郁状态),低于35的为的b类, 利用甲基化抑郁指数对受试者进行分类,绘制roc曲线,计算auc,得到 结果如图3所示,auc为0.79。表示甲基化抑郁指数可以较好地实现心理 量表抑郁程度的分类。
[0105]
为了考察这一方法的稳健性,把分类切分点设置为25,即beck抑郁量 表得分25以上的为a类(高抑郁状态),低于25的为的b类,利用甲基 化抑郁指数对受试者进行分类,绘制roc曲线,计算auc,得到结果如图 4所示,auc为0.76。进一步表明,不管分类阈值如何设置,甲基化抑郁指 数均可以较好地实现心理量表抑郁程度的分类。
[0106]
实施例4、基于标志物基因计算甲基化抑郁指数的稳健性分析。
[0107]
本发明提出的标志物基因是发明人经过多次反复试验研究得到的优化 结果,只用到正基因12个/负基因11个,共23个基因的信息。发明人在全 基因组范围内随机挑选这23个基因以外的基因,组成新的正、负集合,用 同样的方法计算甲基化抑郁指数,并考察其与beck抑郁量表得分的相关性, 上述随机化操作重复进行1000次,计算1000次相关系数的平均值,结果如 图5所示。随着基因集合扩容比例从120%、140%到160%,所得的甲基化 抑郁指数与beck量表得分相关性降到0.3左右。说明所述正、负基因集合是 一种优化组合。
[0108]
应用中,可以把上述算法和标志物固化在计算机系统,或者某终端设备, 读入甲基化测试数据,运算得到甲基化抑郁特征指数,进而辅助神经精神类 疾病的诊断、分型、预后分析。因此,本发明还可以包括一种计算机可读 存储介质,其上存储有计算机程序,所述计算机程序在被处理器执行时实 现本发明的实施例中所述的方法。
[0109]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对 上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这 些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0110]
尽管结合实施例对本发明进行了描述,但本领域技术人员应理解,上 文的描述和附图仅是示例性而非限制性的,本发明不限于所公开的实施 例。在不偏离本发明的精神的情况下,各种改型和变体是可能的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。