1.本发明涉及智能交通系统领域,具体涉及一种适用于车路协同环境下的实时最优车道选择方法。
背景技术:
2.传统交通系统中,车辆的随意换道是造成交通拥堵和事故的重要原因。大部分司机只能单纯依赖自身经验和视觉判断来达到变换车道的目的,而这种决策背后存在不可预知的风险,尤其是在交通拥堵时,盲目的变换车道将进一步加剧交通拥堵,甚至引发事故。随着感知和通信技术的发展,车路协同系统为解决上述问题提供了一个有效途径,设计可靠的车道决策方法是使其有效运行的关键。
3.博弈论为解决含有竞争倾向的问题提供了研究方法和分析手段。车辆间的换道可以被视为一种非合作博弈行为。车道选择过程中的驾驶员被视为博弈中的局中人,通过博弈的过程实现共赢,参与者可以在外界条件的相互约束下结合自身的期望收益做出最优决策。这不但符合了驾驶员追求最大利益的驾驶心理而且使得换道决策更加合理化,因而驾驶员对博弈协作策略的可接受性高,合作意愿强烈,因此非常适合采用博弈论方法来解决车辆最优车道选择问题。在实际交通网络中,车辆之间的拓扑关系对局势的演化有着重要影响,尤其是邻域内车辆的车道选择对彼此的影响更加直接;同时,车辆在接收数据采集设备的信息时会有时滞,从而影响该车辆对邻居车辆车道选择的判断,这类时滞跟局势有着密不可分的关系,这不得不需要考虑状态依赖型时滞对最优车道选择的影响。
技术实现要素:
4.本发明要解决的技术问题是提供一种车路协同环境下的车道最优选择方法,用于指导驾驶员做出最优的车道选择,从而在保证交通安全的前提下,提高道路通畅性,缓解交通拥堵,具有十分重大的社会价值和工程意义。
5.为了解决上述技术问题,本发明采用的技术方案是:该适用于车路协同环境下的实时最优车道选择方法,具体包括以下步骤:
6.s1:利用混合值逻辑函数,将车路协同环境下的交通模型建立为带有状态依赖时滞的网络演化博弈模型,再利用矩阵方法,推导出策略演化方程;
7.s2:利用道路数据收集设备,获取各个车道有限时间内的历史车辆数据;
8.s3:将车辆速度视为收益,对车道的选择视为策略,将当前所有车辆的所作决策视为局势;存在信息时滞时,分析不同的局势对该车辆速度的影响,进而找到使得该个体车辆实现最大收益时的策略,进而制定最优响应的策略更新规则;
9.s4:利用矩阵方法,构建状态转移矩阵h;并分析状态转移矩阵h的特性,判断该交通系统是否稳定,若稳定则求解均横点策略,找到该交通系统收敛的判据,进而得出稳定点,即所寻求的最佳路径规划。
10.采用上述技术方案,先根据实时交通网络状况进行数学建模;然后根据车主的收
益参数选择,借助车路协同技术进行模型数据的采集工作;之后根据车主的收益参数选择,制定策略更新规则;进而判断系统是否稳定,即博弈能否收敛到均衡点,若系统稳定则直接求解均衡点策略,即最优策略;若系统不稳定则通过系统控制器干预参与者策略实现系统稳定,然后求解均衡点策略,最终给出最优车道选择建议;利用数学公式对车路协同环境中交通模型的建模方法得到一个带有状态依赖时滞的网络演化博弈模型来模拟该车路协同交通模型,以解决个体车辆的最优车道选择问题,一方面帮助车主选择科学的最优车道,最大化车主的利益;另一方面保障了全局最优解的存在,从而缓解整体交通拥堵压力,其核心是利用博弈论的思想解决个体车辆与邻域车辆的博弈问题,找出全局最优解实现最优控制。
11.作为本发明的优选技术方案,还包括步骤s5:若该交通系统不稳定,即无法收敛,则设计状态反馈控制器,对该个体车辆进行路线优化控制,使得该交通系统收敛。
12.作为本发明的优选技术方案,所述步骤s1具体步骤包括:
13.s11:利用混合值逻辑网络将车路协同环境下的交通模型建立为带有状态依赖型时滞的网络演化博弈模型g
d
;
14.假设有n辆车辆构成集合n={1,2,
…
,n},其中个体车辆i可被允许行驶的车道集合为s
i
={k1,k2,...,k
i
},i=1,2,
…
,n,s=s1×
s2×…×
s
n
是局势集合,c
i
:s
→
实数集,其中i=1,2,...,n是个体车辆i的收益函数;车辆之间的拓扑用连接图(n,e)来表示,其中n是点集合代表车辆,e是边集合;每条边连接两个有信息交互关系的车辆,由于相邻的车辆对彼此的影响最大,故本文在车道选择时只考虑一步邻居车辆对彼此的影响;n
i
表示个体车辆i的邻域,其包含车辆i的所有邻居车辆;车辆i和其邻域内的车辆j进行博弈g
ij
;利用混合值逻辑函数f
i
表示个体车辆i的策略更新规则,其中i=1,2,
…
,n,采用τ
i
:s
→
{0,1,...,λ
i
}表示个体车辆i在接收信息时的时滞,τ
i
是一个混合值逻辑函数,该网联车辆g
d
的动态模型可被建立成以下模式:
15.x
i
(t 1)=f
i
(x
j
(t
‑
τ
i
(x(t))|j∈n
i
),i∈n,t=0,1,
…
,
16.其中x
i
(t)为个体车辆i在t时刻的车道选择,x(t)∈s是t时刻的局势,τ
i
(x(t))是个体车辆i在t时刻的状态依赖型时滞,c
i
(t)为个体车辆i的邻居车辆博弈时的平均收益,即车辆i在t时刻时的速度,其公式为:
[0017][0018]
作为本发明的优选技术方案,所述步骤s2中所述道路数据收集设备包括车速传感器、路侧传感器和高精地图;所述步骤s2具体为:基于车速传感器获取的车辆行驶速度,将其作为个体车辆的收益量化指标;基于智能车辆的定位系统、路侧传感器和高精度地图来定位个体车辆所处车道位置;智能车路协同系统保存的t步之内每辆个体车辆的历史车道选择情况,结合个体车辆在接收数据时的信息时滞,为个体车辆的最优决策提供数据支持。
[0019]
作为本发明的优选技术方案,所述步骤s3具体包括:
[0020]
s31:根据个体车辆i的收益函数c
i
(t),寻找t时刻,针对邻居车辆j的选择而使得自己收益最大的车道,构成集合p
i
(t):
[0021]
[0022]
其中,i表示玩家的变量,其取值范围是{1,2,
…
,n},s
i
是玩家i的策略集合,x
i
(t)是玩家i在时间t时刻选择的策略变量;
[0023]
s32:假设p
i
(t)={s1,s2,...,s
r
}∈s
i
,若该车辆的车道选择已经是最佳车道,那么下一时刻将保持行驶在该车道;若该车辆的车道不是应对其邻域内车辆的最佳车道,那么下一时刻选择集合p
i
(t)内具有最小下标的车道,即设计短势最优响应策略更新规则如下:
[0024][0025]
作为本发明的优选技术方案,所述步骤s4具体包括:
[0026]
s41:识别实数集合为向量集合,利用矩阵半张量积方法,将其转化成代数形式z(t 1)=hz(t),λ=max{λ1,λ2,...,λ
n
};通过扩维的方法,把λ 1步局势融合到z(t)中,使上式成为一个标准的逻辑动态系统;状态转移矩阵h吸收了原有的时滞信息,反映了局势转移的能达性,揭示了该博弈的性质,计算并观察计算状态转移矩阵
[0027]
s42:判断该交通系统是否稳定,其判断公式为:
[0028][0029]
其中row
s
(h)表示矩阵h的第s行,row
‑
s
(h)表示矩阵h中除去第s行以外的行,k=k1×
k2×
...
×
k
n
;若存在一个整数s使得其成立,则说明该交通系统稳定,若不存在整数s使得其成立,则说明该交通系统不稳定;
[0030]
s43:若该交通系统稳定,求解得到该交通博弈收敛到均衡点将进行唯一分解可得到:即当个体车辆i选择车道s
i
时,其速度能实现最优,此时该车道s
i
最为通畅且保持稳定,其中i=1,2,
…
,n,从而获得最优车道选择。
[0031]
作为本发明的优选技术方案,所述步骤s5具体为:若该交通系统不稳定,即该交通博弈无法收敛,则通过系统状态反馈控制器对个体路径的选择施加干预,控制个体车辆的车道选择,使该交通系统达到稳定状态;再返回步骤s43,获得最优车道选择。
[0032]
作为本发明的优选技术方案,所述步骤s5中的系统状态反馈控制器对个体路径的选择施加干预的具体方法包括以下三种:
[0033]
s5
‑
1:限制车辆对车道的选择集,即令车辆i可被允许的车道集合为1:限制车辆对车道的选择集,即令车辆i可被允许的车道集合为是集合s
i
的子集,以此来缩小车辆的自由程度;
[0034]
s5
‑
2:令其车道的选择具有优先级,打破原来均匀混合地选择车道模式,优先选择与邻居车辆不同的车道,以此来使系统达到动态平衡;
[0035]
s5
‑
3:直接控制其中一个车辆,对其进行直接的车道选择干预,使它影响邻居车辆的行为,进而影响全局车辆的选择,即:
[0036][0037]
其中t表示时间节点,n
i
表示玩家i的邻居集合,玩家i的取值范围是{1,2,
…
,n},u
(t)表示可输入的外部控制变量,g1是人为设计,完全可控的混合值逻辑函数,f
i
是玩家i的策略更新规则。
[0038]
作为本发明的优选技术方案,所述路侧传感器包括摄像头和毫米波雷达。
[0039]
本发明的有益效果是:提供了一种车路协同环境下车道最优选择方法,用于引导驾驶员做出科学的最优车道选择,从而在保证交通安全的前提下,提高道路通畅性,进而缓解交通拥堵,具有十分重大的社会价值和工程意义。
附图说明
[0040]
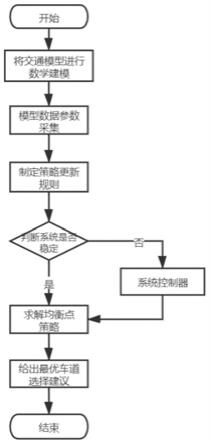
图1是本发明用于车路协同环境下的实时最优车道选择方法的整体流程示意图;
[0041]
图2是本发明用于车路协同环境下的实时最优车道选择方法中车道模拟示意图;
[0042]
图3是本发明用于车路协同环境下的实时最优车道选择方法实施例中的车辆拓扑关系示意图。
具体实施方式
[0043]
下面将结合本发明的实施例图中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。
[0044]
实施例:如图1所示,该适用于车路协同环境下的实时最优车道选择方法,具体包括以下步骤:
[0045]
s1:利用混合值逻辑函数,将车路协同环境下的交通模型建立为带有状态依赖时滞的网络演化博弈模型,再利用矩阵方法,推导出策略演化方程;
[0046]
所述步骤s1具体步骤包括:
[0047]
s11:利用混合值逻辑网络将车路协同环境下的交通模型建立为带有状态依赖型时滞的网络演化博弈模型g
d
;
[0048]
假设有n辆车辆构成集合n={1,2,
…
,n},其中个体车辆i可被允许行驶的车道集合为s
i
={k1,k2,...,k
i
},i=1,2,
…
,n,s=s1×
s2×…×
s
n
是局势集合,c
i
:s
→
实数集,其中i=1,2,...,n是个体车辆i的收益函数;车辆之间的拓扑用连接图(n,e)来表示,其中n是点集合代表车辆,e是边集合;每条边连接两个有信息交互关系的车辆,由于相邻的车辆对彼此的影响最大,故本文在车道选择时只考虑一步邻居车辆对彼此的影响;n
i
表示个体车辆i的邻域,其包含车辆i的所有邻居车辆;车辆i和其邻域内的车辆j进行博弈g
ij
;利用混合值逻辑函数f
i
表示个体车辆i的策略更新规则,其中i=1,2,
…
,n,采用τ
i
:s
→
{0,1,...,λ
i
}表示个体车辆i在接收信息时的时滞,τ
i
是一个混合值逻辑函数,该网联车辆g
d
的动态模型可被建立成以下模式:
[0049]
x
i
(t 1)=f
i
(x
i
(t
‑
τ
i
(x(=(t))|j∈n
i
),i∈n,t=0,1,
…
,
[0050]
其中x
i
(t)为个体车辆i在t时刻的车道选择,x(t)∈s是t时刻的局势,τ
i
(x(t))是个体车辆i在t时刻的状态依赖型时滞,c
i
(t)为个体车辆i的邻居车辆博弈时的平均收益,即车辆i在t时刻时的速度,其公式为:
[0051][0052]
s2:利用道路数据收集设备,获取各个车道有限时间内的历史车辆数据;
[0053]
所述步骤s2中所述道路数据收集设备包括车速传感器、路侧传感器和高精地图;所述步骤s2具体为:基于车速传感器获取的车辆行驶速度,将其作为个体车辆的收益量化指标;基于智能车辆的定位系统、路侧传感器和高精度地图来定位个体车辆所处车道位置;所述路侧传感器包括摄像头和毫米波雷达;智能车路协同系统保存的t步之内每辆个体车辆的历史车道选择情况,结合个体车辆在接收数据时的信息时滞,为个体车辆的最优决策提供数据支持;
[0054]
s3:将车辆速度视为收益,对车道的选择视为策略,将当前所有车辆的所作决策视为局势;存在信息时滞时,分析不同的局势对该车辆速度的影响,进而找到使得该个体车辆实现最大收益时的策略,进而制定最优响应的策略更新规则;
[0055]
所述步骤s3具体包括:
[0056]
s31:根据个体车辆i的收益函数c
i
(t),寻找t时刻,针对邻居车辆j的选择而使得自己收益最大的车道,构成集合p
i
(t):
[0057][0058]
其中,i表示玩家的变量,其取值范围是{1,2,
…
,n},s
i
是玩家i的策略集合,x
i
(t)是玩家i在时间t时刻选择的策略变量;
[0059]
s32:假设p
i
(t)={s1,s2,...,s
r
}∈s
i
,若该车辆的车道选择已经是最佳车道,那么下一时刻将保持行驶在该车道;若该车辆的车道不是应对其邻域内车辆的最佳车道,那么下一时刻选择集合p
i
(t)内具有最小下标的车道,即设计短势最优响应策略更新规则如下:
[0060][0061]
s4:利用矩阵方法,构建状态转移矩阵h;并分析状态转移矩阵h的特性,判断该交通系统是否稳定,若稳定则求解均横点策略,找到该交通系统收敛的判据,进而得出稳定点,即所寻求的最佳路径规划。
[0062]
所述步骤s4具体包括:
[0063]
s41:识别实数集合为向量集合,利用矩阵半张量积方法,将其转化成代数形式z(t 1)=hz(t),λ=max{λ1,λ2,
…
,λ
n
}.;通过扩维的方法,把λ 1步局势融合到z(t)中,使上式成为一个标准的逻辑动态系统;状态转移矩阵h吸收了原有的时滞信息,反映了局势转移的能达性,揭示了该博弈的性质,计算并观察计算状态转移矩阵
[0064]
判断该交通系统是否稳定,其判断公式为:
[0065][0066]
其中row
s
(h)表示矩阵h的第s行,row
‑
s
(h)表示矩阵h中除去第s行以外的行,k=k1×
k2×
...
×
k
n
;若存在一个整数s使得其成立,则说明该交通系统稳定,若不存在整数s使得其成立,则说明该交通系统不稳定;
[0067]
s43:若该交通系统稳定,求解得到该交通博弈收敛到均衡点将进行唯一分
r1(0,0)(3,1)r2(4,1)(2,2)r3(3,2)(1,0)
[0082]
根据短势最优响应规则,车辆进行车道的选择。交通拥堵会导致信息时滞的产生。不同的局势会产生不同的时滞,交通拥堵程度越大,时滞越大。该依赖于局势状态的时滞描述如下:
[0083][0084]
其中r1={(r1,r2,r3),(r2,r1,r3),(r3,r1,r2)};r3={(r2,r2,r2)};r2=s\(r1∪r3);继而可以构造出该交通博弈的演化方程如下:
[0085][0086]
通过计算,我们可以找到t=10,此时h
11
=h
10
;并且row
472
(h
10
) row
1257
(h10)=1
1728
·
;结果表明,该交通博弈可以收敛;即从(r1,r1,r2,r1,r1,r2,r1,r1,r2)出发的车辆最终稳定在局势(r1,r2,r3);从(r2,r1,r3,r2,r1,r3,r2,r1,r3)得的车辆最终稳定在车道(r2,r1,r3)此时各行其道,交通顺畅。
[0087]
以上所述仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。