一种基于纳什q学习算法的交叉口联合信号控制方法
技术领域
1.本发明涉及交通信号自适应控制技术,具体而言涉及一种基于纳什q学习算法的交叉口联合信号控制方法。
背景技术:
2.随着人工智能技术不断发展,计算机硬件计算能力不断提升,5g通讯技术的不断完备,交叉口自检测车辆信息并实现信息实时传输成为可能。因此充分利用交叉口实时检测的信息和传输机制,建立数据驱动型控制算法,并考虑利用相邻交叉口间的合作博弈建立协同机制,能极大提高交通网络的运行效率,减缓交通网络的拥挤程度。
3.利用强化学习思想进行交叉口信号控制是一种可行有效的数据驱动型交叉口自适应信号控制算法。已有研究中,中国专利cn202010111549.3将交叉口网格化获取车辆在交叉口位置和速度信息并基于deep q
‑
network强化学习算法对单点十字路口进行信号控制;中国专利cn202010034436.8依据深度循环q学习建立单点交叉口信号控制算法,加入lstm神经网络对交叉口一段时间内的状态进行记录,提高了交叉口控制效率。总体来说,现有研究多针对于将强化学习类算法应用于交叉口控制内,尤其是针对单点信号口控制场景可证明此类方法有很好的控制效果,但少有研究考虑网络区域内多交叉口之前的相互影响,对于多交叉口协调控制的研究还并不成熟。
技术实现要素:
4.为了克服上述现有技术的不足,本发明目的在于提出一种基于纳什q学习算法的相邻交叉口间联合协调信号控制方法,依据交叉口控制间的博弈理论构建纳什q学习网络模型,通过最优化理论求解交叉口信号控制的纳什q值,建立相邻交叉口间的合作协调控制机制,解决由于相邻交叉口信号控制不匹配引起的交通拥堵问题。
5.为实现上述目的,本发明提供如下技术方案:
6.一种基于纳什q学习算法的交叉口联合信号控制方法,包括以下步骤:
7.步骤s1、在目标区域内选择需要进行协调的相邻交叉口,形成协调控制区域,并在协调控制区域内构建协调控制模型,利用协调控制模型分别获得协调控制区域内各个目标交叉口对应的状态集、动作集、以及奖励集,所述状态集为协调控制区域内各个目标交叉口的各个进道口的车辆数量、以及各个目标交叉口当前周期的信号控制相位,所述动作集为协调控制区域内各个目标交叉口下一周期的信号控制相位,所述奖励集为协调控制区域在下一周期内通过各个目标交叉口的车辆数;
8.步骤s2、分别针对协调控制区域内的各个目标交叉口,利用纳什均衡策略,以协调控制区域内的状态集、动作集为输入,以目标交叉口的纳什q值为输出,构建纳什q学习网络模型,获得目标交叉口的纳什q值;
9.步骤s3、针对协调控制区域,结合步骤s2中构建的纳什q学习网络模型,提取与状态集、动作集和奖励集相关的各个目标交叉口的经验数据,并将经验数据随机划分为训练
数据集和测试数据集,利用训练数据集对步骤s2中获得的各个目标交叉口的纳什q学习网络模型进行训练,并保留训练的模型参数,即获得训练好的目标区域的纳什q学习网络模型;
10.步骤s4、根据步骤s3中获得的训练好的纳什q学习网络模型对目标区域内的信号控制相位进行协调控制。
11.进一步地,前述的步骤s1中,利用协调控制模型分别获得协调控制区域内各个目标交叉口对应的状态集、动作集、以及奖励集,具体如下:
12.选择需要进行协调控制并且拓扑关联的相邻交叉口构建协调控制区域i,i=[i1,i2],其中i1表示编号为1的交叉口,i2表示i1交叉口的相邻编号为2的交叉口;
[0013]
控制区域状态集由s表示,其中表示交叉口i1,i2的状态矩阵,单个交叉口的状态主要为交叉口各进口道的车辆数和交叉口当前的信号控制相位,s=[n,c],n是交叉口各进口道存储的车辆数的行向量,c为该交叉口当前信号控制相位;
[0014]
控制区域动作集由a表示,其中表示交叉口i1,i2的动作,单个交叉口的动作为交叉口下一阶段要采用的信号控制相位;
[0015]
控制区域奖励集由r表示,其中表示交叉口i1,i2的奖励矩阵,奖励矩阵r为在s状态下交叉口i1,i2采用动作a1,a2所对应的奖励组合,具体奖励形式为下一阶段通过交叉口的车辆数。
[0016]
进一步地,步骤s2中,针对目标区域内的各个目标交叉口,构建对应的纳什q学习网络模型,包括以下步骤:
[0017]
步骤s2
‑
1、以交叉口的状态集s和动作集a为输入,以当前状态下交叉口的q预测值为输出,构建神经网络模型,构建过程如下:
[0018]
q
i
(s,a)=[σ(fc(s))]
m
,i∈i
[0019]
其中,q
i
(s,a)为目标区域i内的交叉口i在状态集s经过动作集a后的q预测值,σ为神经网络的激活层,fc为神经网络的全连接层,m为神经网络模型全连接层和激活层的数量;
[0020]
步骤s2
‑
2、根据以下约束条件:
[0021][0022]
求解以下规划问题过程:
[0023][0024][0025]
获得纳什均值策略,其中为交叉口i1、i2在状态s下的纳什q值,x、y为列向量,具体为交叉口i1,i2在下一阶段采用各个相位的概率,x
i
,y
i
为列向量x,y的各个分量;
[0026]
步骤s2
‑
3、根据公式:
[0027][0028]
将交叉口i的q预测值q
i
(s,a)更新为q
i
(s,a)
′
,其中,α为学习速率,r
i
(s,a)为在交叉口状态集s下经过与动作集a得到的奖励集,γ为折扣因子,为交叉口i在状态s
′
下的纳什q值,状态s
′
为协调控制区域在状态s下经过联合动作a后转移得到的状态。
[0029]
进一步地,步骤s3中,处理并划分为训练数据集和测试数据集,具体包括:
[0030]
对于每个交叉口建立对应的经验回收池,对于每次动作迭代收集经验数据<s,a,r
i
,s
′
>填入经验回收池,经验回收池设置最大存储容量,采用队列结构存储数据,即当经验回收池中的数据量大于最大存储容量时,最早进入经验回收池中的经验被移除;
[0031]
当需要训练时,从经验回收池随机选取指定数量的随机样本,按照预设比例随机分成训练数据集和测试数据集。
[0032]
进一步地,步骤s3中,利用训练数据集对步骤s2中获得的各个目标交叉口的纳什q学习网络模型进行训练,包括以下步骤:
[0033]
步骤s3
‑
1、设置训练迭代总回合数;
[0034]
步骤s3
‑
2、初始化步骤s2
‑
1构建的神经网络模型参数;
[0035]
步骤s3
‑
3、设置单次训练迭代回合运行时长、以及时间步长;
[0036]
步骤s3
‑
4、每经过一个时间步长,记录当前时间、以及经验数据<s,a,r
i
,s
′
>,并填入经验回收池,根据步骤s2
‑
2求解出的列向量x、y,按概率选择x、y中的分量作为下一阶段两个交叉口的动作a,即下一阶段两个交叉口各自需要切换的相位,经过当前时间步长后记录交叉口的状态s
′
和在这一时间步长内交叉口i得到的奖励r
i
,将<s,a,r
i
,s
′
>填入经验回收池,随后时间步长加1,检查当前时间是否超过运行时长,如果超过,进入步骤s3
‑
5,如果没超过重新进行步骤s3
‑
4;
[0037]
步骤s3
‑
5、按照步骤s3获取训练数据集,按照步骤s2
‑
2、s2
‑
3对建立的网络参数进行迭代更新,当前迭代回合数加1;
[0038]
步骤s3
‑
6、检查当前回迭代合数是否超过训练迭代总回合数,如果超过,结束训练,如果没超过重新进入步骤s3
‑
3。
[0039]
进一步地,步骤s4中,交通网络运行时,在每个时间步长,相邻两个交叉口获取当前联合状态集s,并利用步骤s2构建的神经网络模型加载步骤s3最终训练的模型参数计算各动作组合的q
i
(s,a),并通过步骤s2
‑
2计算两个交叉口各自采取的信号相位概率向量x、y,并选取x和y中的最大分量作为下一阶段交叉口要采取的动作。
[0040]
本发明所述一种基于纳什q学习算法的交叉口联合信号控制方法,采用以上技术方案与现有技术相比,具有以下技术效果:
[0041]
本发明提出的一种基于纳什q学习算法的相邻交叉口间联合协调信号控制方法,充分利用交叉口可获取的道路交通信息和交叉口之间稳定快速的信息传递机制,依据强化学习思想,建立交叉口自适应控制模型,保证对不同状态下的交叉口都能进行实时有效控制;基于一般和博弈原理,使相邻交叉口达到纳什均衡控制,最终实现相邻交叉口间的协调控制。
附图说明
[0042]
图1是本发明实施例的方法流程图;
[0043]
图2是本发明实施例的控制区域示意图;
[0044]
图3是本发明实施例交叉口3的示意图;
[0045]
图4是本发明实施例信号控制方案相位示意图;
[0046]
图5是本发明实施例的神经网络模型结构示意图。
具体实施方式
[0047]
为了更了解本发明的技术内容,特举具体实施例并配合所附图式说明如下。
[0048]
在本发明中参照附图来描述本发明的各方面,附图中示出了许多说明性实施例。本发明的实施例不局限于附图所示。应当理解,本发明通过上面介绍的多种构思和实施例,以及下面详细描述的构思和实施方式中的任意一种来实现,这是因为本发明所公开的构思和实施例并不限于任何实施方式。另外,本发明公开的一些方面可以单独使用,或者与本发明公开的其他方面的任何适当组合来使用。
[0049]
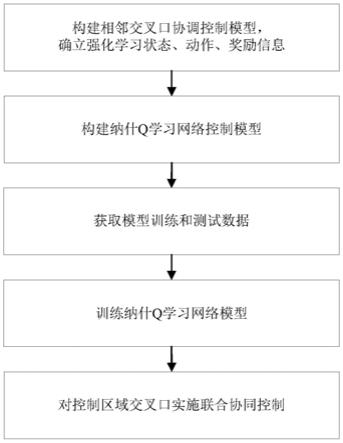
如图1所示,本发明实施例公开的一种基于纳什q学习算法的相邻交叉口间联合协调信号控制方法,包括如下步骤:
[0050]
步骤s1、选择需要进行联合协调控制的相邻交叉口构建协调控制模型,并分别定义强化学习的状态、动作和奖励。
[0051]
具体地如图2所示,选择需要进行协调控制并且拓扑关联的相邻交叉口构建协调控制区域i,此事例中选取交叉口3和4组成协调区域,即i=[i3,i4];
[0052]
控制区域状态集由s表示,在图2示例中,控制区域状态集由s表示,在图2示例中,表示交叉口i3,i4的状态矩阵。单个交叉口的状态主要为交叉口各进口道的车辆数和交叉口当前的信号控制相位,s=[n,c],n是交叉口各进口道存储的车辆数的行向量,c为该交叉口当前信号控制相位。图3为图2中交叉口3的局部图,该交叉口南北为双向3车道,东西方向为双向2车道,每个方向均包含一个左转车道,如图3所示,按照北、东、南、西方向顺序,n=[2,7,3,7],示例中交叉口信号控制相位为两相位,如图4所示,此时图3示例显示当前相位为南北通行相位,对应于图4中的1,即c=1,因此本示例中s=[2,7,3,7,1]。
[0053]
控制区域动作集由a表示,在图2示例中,控制区域动作集由a表示,在图2示例中,表示交叉口i3,i4的动作。单个交叉口的动作为交叉口下一阶段要采用的信号控制相位,若为图4交叉口所示相位,a∈[1,2]。
[0054]
控制区域奖励集由r表示,在图2示例中,控制区域奖励集由r表示,在图2示例中,表示交叉口i3,i4的奖励矩阵,奖励矩阵r为在s状态下交叉口i3,i4采用动作听对应的奖励组合,具体奖励形式为下一阶段通过交叉口的车辆数。在图3示例中,表示当3号交叉口采用信号相位1,4号交叉口采用信号相位1时,通过3号交叉口的车辆数为5;当3号交叉口采用信号相位1,4号交叉口采用信号相位2时,通过3号交叉口的车辆数为4;当3号交叉口采用信号相位2,4号交叉口采用信号相位1时,通过3号交叉口的车辆数为10;当3号交叉口采用信号相位2,4号交叉口采用信号相位2时,通过3号交叉口的车辆数为11。
[0055]
步骤s2、依据强化学习算法和交叉口信号控制间的博弈理论构建纳什q学习网络模型。具体实现包括以下子步骤:
[0056]
步骤s2
‑
1、构建神经网络模型,神经网络模型由多层全连接层fc和激活层σ构成,输入层输入为交叉口的状态集s和联合动作集a的集合,在图3示例中,输入为维度为12的行向量输出层输出为该状态下交叉口3的q值预测值即交叉口3在状态集s下经过联合动作集a后可得到的回报期望值,计算过程如下:
[0057]
q
i
(s,a)=[σ(fc(s))]
m
,i∈i
[0058]
式中,m为神经网络模型全连接层和激活层的数量,在本实例中m为3,σ采用relu激活函数,神经网络模型结构如图5所示。
[0059]
步骤s2
‑
2、求解纳什均衡策略π,求解策略π过程为求解如下规划问题过程,在本示例中:
[0060][0061][0062][0063]
分别为交叉口i3,i4在状态s下的纳什q值;x,y为列向量,具体为交叉口i3,i4在下一阶段采用各个相位的概率;x
i
,y
i
为列向量x,y的各个分量。
[0064]
具体求解方法为:
[0065]
由步骤2.1构建的神经网络模型求解出在s状态下由步骤2.1构建的神经网络模型求解出在s状态下
[0066]
定义松弛变量a3,b4;
[0067][0068][0069]
即:
[0070]
a
31
=1
‑
4y3‑
6y
4 a1
[0071]
a
32
=1
‑
5y3‑
3y
4 a2
[0072]
b
43
=1
‑
3x1‑
x
2 b1
[0073]
b
44
=1
‑
2x1‑
4x
2 b2
[0074]
设置松弛变量为0,在b1约束下将x1扩大至1/3:
[0075][0076]
将x1代入约束方程b2:
[0077][0078]
根据互补条件y3b
43
=0,依据约束a2求解y3:
[0079][0080]
将y3代入约束方程a1:
[0081][0082]
基于x2a
32
=0,依据约束b2
′
求解x2:
[0083][0084][0085]
基于y4b
43
=0,依据约束a1
′
求解y4:
[0086][0087][0088]
因此当前解策略为
[0089]
归一化策略为:即纳什均衡策略π交叉口3在下一相位以的概率采取相位1,以的概率采取相位2;交叉口4在下一相位以的概率采取相位1,以的概率采取相位2。
[0090]
步骤s2
‑
3、更新交叉口i的q
i
(s,a),更新过程如下:
[0091][0092]
式中,α为学习速率,γ为折扣因子,为交叉口i的纳什q值,s
i
′
为交叉口i在状态s
i
下经过与邻接交叉口的联合动作a后转移得到的状态,ri(s,a)为交叉口i在状态s下经过联合动作a所得到的奖励。在图3示例中,经过联合动作a所得到的奖励。在图3示例中,
[0093]
步骤s3、基于实际或仿真场景运行提取与状态、动作和奖励相关的数据,处理并划分为训练数据集和测试数据集。
[0094]
具体地,对于每个交叉口建立对应的经验回收池m
i
,对于每次动作迭代收集经验<s,a,r
i
,s
′
>填入经验回收池。经验回收池设置最大存储容量z,采用队列结构存储数据,即当经验回收池中的数据量大于最大存储容量z时,最早进入经验回收池中的经验被移除。在本示例中z取值为12800。
[0095]
当需要训练时,从经验回收池随机选取指定数量的随机样本,按照α和1
‑
α比例分
成训练数据集和测试数据集。在本示例中,α=0.8。
[0096]
基于训练集数据对实现交叉口协调控制的纳什q学习网络模型进行训练,并保留最终训练的模型参数。具体实现包括以下子步骤:
[0097]
步骤s3
‑
1、设置训练迭代总回合数n,在本示例中n设置为200;
[0098]
步骤s3
‑
2、初始化步骤2.1构建的神经网络模型参数。在本示例中神经网络权重系数初始化为符合正太分布的随机数,纳什q值表中各值初始化为0。
[0099]
步骤s3
‑
3、设置单次训练迭代回合仿真运行时长t,时间步长step。在本示例中,=设置为3600秒,step设置为5秒。
[0100]
步骤s3
‑
4、每经过一时间步长,记录当前仿真时间t,记录相邻交叉口的当前状态s,根据步骤s2
‑
2求解出的列向量x、y,按概率选择x、y中的分量作为下一阶段两个交叉口的动作a,即下一阶段两个交叉口各自需要切换的相位,经过当前时间步长后记录交叉口的状态s
′
和在这一时间步长内交叉口i得到的奖励r
i
,将<s,a,r
i
,s
′
>存入经验回收池mi中
,
时间步长加1,检查当前时间是否超过运行时长,如果超过,进入步骤s3
‑
5,如果没超过重新进行步骤s3
‑
4;
[0101]
步骤s3
‑
5、按照步骤s3获取训练数据集,按照步骤s2
‑
2、s2
‑
3对建立的网络参数进行迭代更新,当前迭代回合数加1;
[0102]
步骤s3
‑
6、检查当前迭代回合数是否超过训练迭代总回合数,如果超过,结束训练,如果没超过重新进入步骤s3
‑
3。
[0103]
步骤4、依据训练好的纳什q学习网络模型对控制区域进行联合协同控制,对各交叉口的信号相位进行合理切换。
[0104]
具体地,交通网络运行时,在每个时间步长,相邻两个交叉口获取当前联合状态集s,并利用步骤s2构建的神经网络模型加载步骤s3最终训练的模型参数计算各动作组合的q
i
(s,a),并通过步骤s2
‑
2计算两个交叉口各自采取的信号相位概率向量x、y,并选取x和y中的最大分量作为下一阶段交叉口要采取的动作。
[0105]
虽然本发明已以较佳实施例揭露如上,然其并非用以限定本发明。本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当视权利要求书所界定者为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。