本发明属于智能交通技术领域,具体涉及一种基于历史误差反向传播的自适应交通信号控制方法。
背景技术:
现有的交通信号灯控制系统已普遍智能化,但较少文献研究红绿灯配置的数学模型,无线传感器网络和排队论都建立了系统数学模型,无线传感器自适应控制,主要采取接收信号强度指示测距算法测试交通灯与等待车辆的排行距离,根据排行距离自动调整交通信号灯指示通行的时间,系统提高了交叉路口车辆通行能力,但因其采用了zigbee无线传感器网络,zigbee具有短距离传输的特点,将zigbee技术应用在传输车流数据传输上,适用范围较小,急剧消耗成本;基于排队论智能控制,该研究是基于排队论并用vissim进行仿真所提出的一种新的交通信号灯智能控制方案,主要通过车辆检测器检测车流量,可编程逻辑控制器处理信息,再将处理后的信息传送给指挥中心计算机,进而调整路口相对应的绿灯时间,该模型在假设的条件下对交通流状况有较好的反馈,但所训练的数据不足会导致模型的参数难以及时修改,自适应能力薄弱,适用路况有限。另外也存在通过实时数据来实现自适应交通信号控制的,车用无线通信技术控制,利用了车联网通讯协议,实现汽车与交通信号灯之间数据的传输,通过分析车速信息和交通信号灯当前状态,实时地控制红绿灯的显示。但这两种方式都无法适应于多样化的交通网络,同时还增加了巨额成本。
技术实现要素:
本发明的主要目的在于克服现有技术的缺点与不足,提出一种基于历史误差反向传播的自适应交通信号控制方法,通过交通部门现有充足的数据集,对数据进行预处理,减少了其他设备的使用,误差小,成本低,构建自适应控制模型,通过反复训练数据集从而得到相对应的阈值和权值,达到在任何交通路口都能自适应调整信号灯时长,适应范围广。
为了达到上述目的,本发明采用以下技术方案:
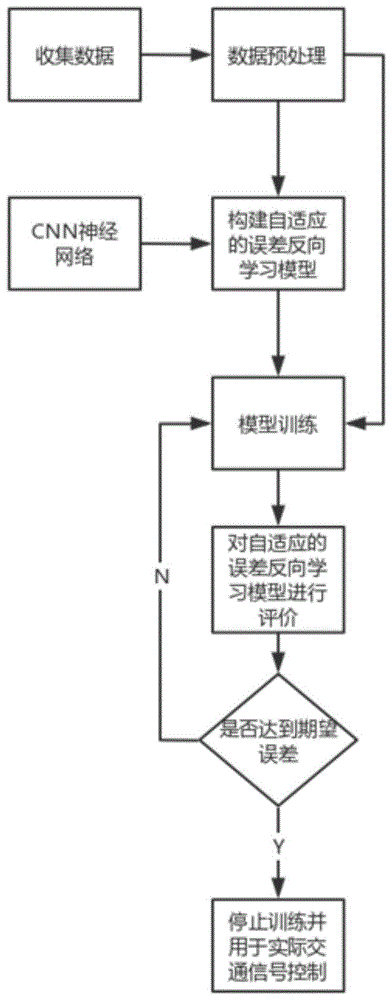
一种基于历史误差反向传播的自适应交通信号控制方法,包括以下步骤:
收集数据;
数据预处理,包括数据清理、数据简化以及数据归一化;
构建自适应的误差反向学习模型,添加cnn神经网络用于捕获未注意到的特征,并进行分类处理;
模型训练,将预处理后的数据集作为自适应的误差反向学习模型的输入进行误差方向学习;
对自适应的误差反向学习模型进行评价,若达到期望误差则停止训练并用于实际交通信号控制,否则继续训练。
进一步的,收集数据具体为采集环境数据、历史数据以及实时数据并作为神经网络模型训练的数据集,用集合d={x|x0,x1,x2}表示;
其中,x0表示环境数据集,x1表示实时数据集,x2表示历史数据集。
进一步的,环境数据集具体包括以下数据因素:
某时间段内天气情况;相邻红绿灯间隔距离;机动车道数量;非机动车流动方向;行人流动方向;
实时数据集具体包括以下数据因素:
机动车车型及两车之间的距离;机动车车流量机器平均行驶速度;非机动车车流量;行人人流量;
历史数据集具体包括以下数据因素:
路口事故发生率;某时间段内道路路况峰值变化,包括车辆平均行驶速度、车流量以及行人人流量;某月内道路路况总峰值变化;某季度内道路路况总峰值变化;某年内道路路况总峰值变化。
进一步的,数据清理具体为剔除收集的数据集中的噪声数据和无关数据,处理遗留数据,去除空白数据域的白噪声;
数据简化用于剔除不相关的随机变量,具体步骤为:
先求数据总集d中各个数据集x的数据因素的算数平均值:
其中,n表示某个数据集x中每个数据因素中的数据种类,xi,1≤i≤n表示对应的数据因素中第i种类型的数据量;若n表示历史数据集x2中的种类数量,则xn表示行人人流量;
根据贝塞尔公式求标准偏差:
若某一随机变量xi满足|xi-m|>3σ,则认为该随机变量含有粗大的坏值,将其剔除;
数据规则化用于将数据无损压缩,以防止数据过大所导致训练速率减慢,使得数据不再杂乱,具体步骤为:
通过遍历经数据简化后的数据总集d中的每一个数据,记录各个数据因素中的最大值max和最小值min,并将max-min作为基数代入归一化标准公式将原数据的数值范围无损压缩到(0,1)的范围内,最后将数据进行排序并装箱,归一化标准公式如下:
其中,x为原数据值,xnormalization为归一化后的数据值。
进一步的,自适应的误差反向学习模型采用bp神经网络,包括输入层、隐含层以及输出层,构建过程如下:
采用x2=[x1,x2,x3]组成输入层,输入层神经元个数为3,x1为总车流量,x2为车速,x3为人流量;采用
隐含层神经元个数的确定公式为:
其中,n为输入层神经元个数,m为输出层神经元个数,a为[1,10]之间的常数。
进一步的,自适应的误差反向学习模型的步骤包括:
在(0,1)范围内随机初始化bp神经网络中输入层,隐含层和输出层各个神经元的权值ω及阈值θ,并对bp神经网络中的各项参数进行初始化,设置训练学习的迭代次数以及学习率η;
将预处理后的数据集x2=[x1,x2,x3]作为输入层的输入进行误差反向学习;
通过前向传播计算绿灯秒数集合y″;
自适应的计算误差以及更新网络中的各神经元的权重ω及阈值θ;
判断是否达到最大迭代次数或达到所设置的学习率η,若达到则停止学习,输出最佳绿灯秒数,若没达到则返回通过前向传播计算绿灯秒数集合步骤。
进一步的,误差反向传播算法实现控时基于以下假设条件:
绿灯持续时间不包含黄灯持续时间,相邻相位之间没有时间延迟;
绿灯秒数始终在[ymin,ymax],其中,ymin和ymax分别表示为绿灯秒数的值域上限值和值域下限值,ymin和ymax的初始值分别为传统交通信号配时方法中固定的绿灯秒数的最小值和最大值;在每次训练结束后所得到的绿灯秒数集合中若有超出该值域上限或下限的值则更新该值域的范围,而最佳绿灯秒数始终在该值域内。
进一步的,对训练好的自适应的误差反向学习模型进行评价,评价指标包括:
决定系数,公式为:
其中,yi为真实值,
误差,公式为:
其中,yj为期望值,
均方误差,公式为:
其中,mse的值越小,说明模型描述实验数据具有更好的精确度。
本发明与现有技术相比,具有如下优点和有益效果:
1、成本低,效益高,本发明可以推广到任何不同的交通运行环境,并且成本低,不需要安装其他摄像头,只要通过交通系统把当地的交通路况数据进行读取即可;整个运行过程,用到了实时、环境、及历史交通信息,使得得出的结果更精确。
2、效率高,本发明可有效减少空等现象,使得交通运行的效率更高;现有的基于无线传感器网络的自适应控制,采用了zigbee无线传感器网络,但因zigbee具有短距离传输的特点,将zigbee技术应用在传输车流数据传输上,适用范围较小,而本发明适用范围较大,不需要根据车流传输数据,只要有交通数据即可;车用无线通信技术利用v2x技术降低了控制指令传输时延,但现今仍存在部分旧车型还未配备车载的情况下,并不能传输准确的车流量数据,本发明不需要考虑到车载问题;无线传感器网络和排队论都建立了系统数学模型,传统的建模方法在简化的路况中有较好的效果,但并不适应复杂交通网络。造成这样的原因是整个交通网络是周期长且非线性的,而本发明能适应各种复杂的交通路面环境。
3、本发明可以改变未来的交通系统运行方式。假设未来应用到整个交通系统后,能够单一化的运用算法把一个路口放到控制器里面,交通局也可以用这个系统来分治不同的控制器。在未来交通系统运行方面奠定了技术基础。
附图说明
图1是本发明方法的流程图;
图2是本发明的技术框架图;
图3是误差方向传播算法流程图;
图4是绿灯时长预测值与期望值的对比图;
图5是绿灯时长预测值与期望值的误差图;
图6是bp神经网络均方误差趋向图;
图7a是训练集的regression系数图;
图7b是验证集的regression系数图;
图7c是测试集的regression系数图;
图7d是总集的regression系数图;
图8a是实施例中四种配时方案平均等待时间的比较示意图;
图8b是实施例中四种配时方案平均停车次数的比较示意图;
图8c是实施例中四种配时方案一次性通过率的比较示意图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1和图2所示,本发明,一种基于历史误差反向传播的自适应交通信号控制方法,包括以下步骤:
s1、收集数据;
在本实施例中,收集数据具体为采集环境数据、历史数据以及实时数据并作为神经网络模型训练的数据集,用集合d={x|x0,x1,x2}表示;其中,x0表示环境数据集,x1表示实时数据集,x2表示历史数据集;各数据集包括如下表1所示的数据因素,实际实施时还可适当增加数据因素项;
表1
在本实施例中,数据采用中华人民共和国交通运输部的珠海市柠溪路与兴业路十字路口数据集,该数据集包括车流量和信号配时方案(原绿灯时长为西南进口车道的信号配时)等数据,时间单位数据统计以30s为记录。截取该数据集中8点43分30秒至8点50分时段作为测试样本,该数据集将这时段的数据以30s为时间单位统计成13个测试数据样本,如下表2所示;
表2
数据集总个数为220组(7点到8点50分),设置训练样本数量为207组(7点到8点43分30秒),测试样本数量为13组(样本编号为时间序号)。
s2、数据预处理,包括数据清理、数据简化以及数据归一化;
数据清理具体为剔除收集的数据集中的噪声数据和无关数据,处理遗留数据,去除空白数据域的白噪声;
数据简化用于剔除不相关的随机变量,具体步骤为:
先求数据总集d中各个数据集x的数据因素的算数平均值:
其中,n表示某个数据集x中每个数据因素中的数据种类,xi,1≤i≤n表示对应的数据因素中第i种类型的数据量;若n表示历史数据集x2中的种类数量,则xn表示行人人流量。
根据贝塞尔公式求标准偏差:
若某一随机变量xi满足|xi-m|>3σ,则认为该随机变量含有粗大的坏值,将其剔除;
数据规则化用于将数据无损压缩,以防止数据过大所导致训练速率减慢,使得数据不再杂乱,具体步骤为:
通过遍历数据简化后的数据总集d中的每一个数据,记录各个数据因素中的最大值max和最小值min,并将max-min作为基数代入归一化标准公式将原数据的数值范围无损压缩到(0,1)的范围内,最后将数据进行排序并装箱,归一化标准公式如下:
其中,x为原数据值,xnormalization为归一化后的数据值。
s3、构建自适应的误差反向学习模型,添加cnn神经网络用于捕获未注意到的特征,并进行分类处理,如图2所示,具体为:
采用x2=[x1,x2,x3]组成输入层,输入层神经元个数为3,x1为总车流量,x2为车速,x3为人流量;采用
隐含层神经元个数的确定公式为:
其中,n为输入层神经元个数,m为输出层神经元个数,a为[1,10]之间的常数;在本实施例中,n取3,m取1,计算得到隐含层神经元个数为3-12之间,因此,选取隐含层神经元个数为5。
在本实施例中,为弥补bp网络在计算机视觉上所存在的局限性,在数据预处理的同时向此加入了cnn神经网络进行深度学习,对各时间段的车型及各环境因素进行可视化处理,为后续决策提供一定的帮助。
s4、模型训练,将预处理后的数据集作为自适应的误差反向学习模型的输入进行误差方向学习,如图3所示,具体为:
自适应的误差反向学习模型的误差反向传播步骤为:
在(0,1)范围内随机初始化bp神经网络中输入层,隐含层和输出层各个神经元的权值ω及阈值θ,并对bp神经网络中的各项参数进行初始化,设置训练学习的迭代次数以及学习率η;
将预处理后的数据集x2=[x1,x2,x3]作为输入层的输入进行误差反向学习;
通过前向传播计算绿灯秒数集合y″;
自适应的计算误差以及更新网络中的各神经元的权重ω及阈值θ;
判断是否达到最大迭代次数或达到所设置的学习率η,若达到则停止学习,输出最佳绿灯秒数,若没达到则返回通过前向传播计算绿灯秒数集合步骤。
在本实施例中,误差反向传播算法实现控时基于以下假设条件:
绿灯持续时间不包含黄灯持续时间,相邻相位之间没有时间延迟;
绿灯秒数始终在[ymin,ymax],其中,ymin和ymax分别表示为绿灯秒数的值域上限值和值域下限值,ymin和ymax的初始值分别为传统交通信号配时方法中固定的绿灯秒数的最小值和最大值;在每次训练结束后所得到的绿灯秒数集合中若有超出该值域上限或下限的值则更新该值域的范围,而最佳绿灯秒数始终在该值域内。
s5、对自适应的误差反向学习模型进行评价,若达到期望误差则停止训练并用于实际交通信号控制,否则继续训练,具体为:
对训练好的自适应的误差反向学习模型进行评价,评价指标包括:
决定系数,公式为:
其中,yi为真实值,
误差,公式为:
其中,yj为期望值,
均方误差,公式为:
其中,mse的值越小,说明模型描述实验数据具有更好的精确度。
在本实施例中,训练次数为25,得出如图4所示的绿灯时长的预测值。期望值为通过后期计算出配备于这个路口的最佳绿灯时长,用于验证绿灯时长预测值的准确性。经过bp神经网络的训练得出13个绿灯时长,这13个时长就是预测绿灯时长集y″。
如图5所示,刚开始训练时的测试样本期望值与预测值有较大的误差,但在样本编号8之后误差逐渐减小,预测值逐渐逼近期望值,最终误差变为0,只有7号样本为偏离点。说明经过训练后精度会提高,能够自适应调整秒数。
如图6所示,为bp神经网络均方误差趋向图,随着迭代次数的增加,训练集和验证集及测试集的均方误差逐渐趋于最佳均方误差值。当迭代次数达到10时,mse减小达到稳定值,在10代以后基本保持不变。
如图7a、图7b、图7c以及图7d所示,刚开始训练时的data圆点不在fit(y=x)曲线上,但经过训练后,大部分data圆点都存在于曲线上,只存在较少偏离点,拟合效果好。决定系数r2(2)均在[0,1]范围内,最大为0.99432,非常接近于1,表明输入车流量,车速及人流量能够准确地预测出绿灯时长。
为验证本发明的先进性,在相同的机器设备和实验环境下,采用同一个数据集,将列举fts(固定相等配时方法)、botf(基于车流量变化配时方法)、bosov(基于车速变化配时方法)三种类似方法与本发明进行比较。针对车辆在路口“空等”问题,算法对比的性能评价指标采用路口一次性通过率、车辆平均停车次数以及平均等待时间,综合三个指标对算法的效率进行评价。其余三种配时方法的特点如下:
fts,每个相位的红绿灯时长是固定的,即呈周期性变化,该方法广泛应用于现实交通中。在对比实验中,绿灯时长固定为50~52秒。
botf,红绿灯时长随路口的车流量变化而进行实时调整,实现红绿灯控制依据实时车流量进行自动调整。
bosov,红绿灯时长随车辆在路口的行驶速度变化而变化,实时地控制红绿灯的显示,实现红绿灯控制依据实时车速进行自动调整。
对比指标如下:
一次性通过率f,表示车辆在没有停车的情况下一次性通过交叉路口的比例,则有:
一次通过率表示为
其中,fi为车辆i是否有停车的情况,si为在该段时间段内车辆i的停车次数,n为该段时间内路口的总车辆数。
平均停车次数savg,表示该时间段内通过交叉路口的车辆的平均停车次数。
其中,si为在该段时间段内车辆i的停车次数,n为该段时间内路口的总车辆数。
平均等待时间davg,表示该时间段内通过交叉路口的车辆的平均等待时间:
其中,di为该段时间内车辆i的等待时间,n为该段时间内路口的总车辆数。
如图8a、图8b以及图8c所示,为四种方法三个指标的对比图;本发明方法与fts相比,一次性通过率提高了13.97%~26.81%,平均停车次数减少了20.43%~44.57%,平均等待时间减少了14.12%~59.26%;
与botf算法相比,一次性通过率提高了4.9%~16.2%,平均停车次数减少了8.2%~15.9%,平均等待时间减少了3.1%~7.7%;
与bosov相比,abhebp平均停车次数减少了7.32%~12.00%,平均等待时间减少了2.55%~7.29%,一次性通过率提高了3.81%~14.73%。
还需要说明的是,在本说明书中,诸如术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。