1.本发明涉及数据集成技术领域,特别是涉及一种数据汇聚方法及系统。
背景技术:
2.数据汇聚(也称为数据集成)是把不同来源、格式、特点性质的数据(异构数据)在逻辑上或物理上有机地集中(同构数据),从而提供全面的数据共享。通俗而言,就是达到消灭“信息孤岛”,实现信息一统的目标。
3.使用数据集成技术通过汇聚把异构数据同构化以达成数据共享的目的,无疑是正确的途径,但多年实践的结果表明,目前通用的汇聚方法始终在“汇聚——共享——独占——再汇聚——共享——独占......”的模式中循环,只能够实现局部、短期的信息一统,最终仍会形成的“信息孤岛”,达不到消灭“孤岛”,信息一统的目标。
4.现有汇聚方法本质上由图1所示三个工作阶段构成。
5.一、设计阶段:技术人员根据用户需求、相关领域的业务逻辑、需要汇聚的源数据库结构设计出目标数据库结构,并根据源数据库与目标数据库的映射关系设计出对应的映射规则。
6.二、编程阶段:通过使用现有软件技术将映射规则转换为可实现抽取数据、存储数据的方法,形成可自动运行的编码集合——汇聚系统。
7.三、实施阶段:通过将汇聚系统应用到具体场景完成汇聚任务以满足用户的需求。
8.此方法固然能够满足用户的需求,但汇聚效率低、共享范围窄、共享时间短、汇聚难度高、汇聚过程长是其天然的缺陷。
9.(1)目标数据库依赖于需求和源数据库,而时间的延伸和场景的变化,使得需求、源数据库的变化不可避免;因而,目标数据库必然具有不稳定性。
10.(1
‑
1)目标数据库的不稳定性,使得由目标数据库达成的共享短暂而脆弱。当需求或源数据库发生变化,共享的基础极有可能被摧毁,新的“孤岛”产生。
11.(1
‑
2)目标数据库的不稳定性,使得目标数据库必然只能适用于相同或相似的场景,造成数据的共享范围有限,只能是某类业务数据的共享。
12.(1
‑
3)目标数据库的不稳定性,使得编程、实施阶段工作必然重复。汇聚效率低下是必然的结果。
13.(2)同理,映射规则依赖于源数据库、业务逻辑和目标数据库,源数据库、业务逻辑和目标数据库的变化同样会引起映射规则的变化,映射规则具有不稳定性也是必然的。映射规则与目标数据库的不稳定性所产生的后果是相似的。
14.(3)目标数据库和映射规则的不稳定性使得汇聚过程不能采用产品化的方式,而只能采用项目实施的方式,每次汇聚都是设计、编码、实施三个阶段的不断重复,汇聚过程冗长低效。
15.(4)现有汇聚方法对技术人员素质的要求是苛刻的,汇聚者既需要掌握软件技术,又需要精通具体行业业务,加大了汇聚难度。
技术实现要素:
16.本发明提供了一种数据汇聚方法及系统;本发明是基于与需求和源数据库无关的稳定数据模型来构建稳定的目标数据库;基于源数据库表和目标数据库中的数据都可以通过相似结构来表达相同客观事物的特性来构建稳定的映射规则;基于数据可以采用数值和语义(值的含义)分开表达的方式实现的全新汇聚方法。本发明在达到实现信息共享、提高汇聚效率和降低汇聚难度的目的的同时,使得汇聚过程产品化成为现实。
17.本发明并不涉及现有汇聚方法所包含的数据清洗、纠错、消冗等内容,所提供方法及系统仅仅用于解决异构数据同构化的问题。
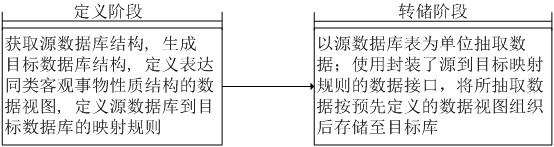
18.第一方面,本发明提供了一种数据汇聚方法;一种数据汇聚方法,包括:定义阶段:获取源数据库结构,生成目标数据库结构,定义数据视图和定义源数据库到目标数据库的映射规则;转储阶段:从源数据库中逐张表抽取源数据库中的数据;使用封装了源数据库到目标数据库映射规则的数据接口,将所抽取数据按照预先定义数据视图进行组织后,存储至目标数据库。
19.第二方面,本发明提供了一种数据汇聚系统;一种数据汇聚系统,包括:部署阶段:依托网络部署web应用服务器、消息服务器、目标数据库服务器和数据汇聚端;配置阶段:在web应用服务器配置汇聚参数;汇聚阶段:启动服务器,接收源数据库数据,转储至目标数据库。
20.与现有技术相比,本发明的有益效果是:(1)实现了数据共享。使用数值与语义分隔(语义类存储语义、其它类存储数值)的方式表达数据,使得汇聚脱离了具体的应用。使用稳定的模型构建目标数据库,使得目标数据库结构稳定不变(表结构一样,表名相异,变化的是表的个数),在存储结构层面实现了数据共享。
21.(2)拓宽了共享范围。不拘泥于某个具体行业的汇聚方法,可以将不同行业的数据汇聚到一个目标数据库中,拓宽了数据共享的范围。
22.(3)降低了汇聚难度。新方法去除了现有方法中的编程阶段,降低了对汇聚者自身技术能力的要求(只需要具有业务能力),相应的也降低了汇聚难度。
23.(4)提高了汇聚效率。本方法可以容易的将汇聚方法产品化,变现有的实施过程为产品应用。当需求或源数据库变化时,需要做的仅仅是修改汇聚的配置参数。
24.本发明附加方面的优点将在下面的描述中部分给出,或通过本发明的实践了解到。
附图说明
25.构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
26.图1为现有技术中汇聚方法流程图;
图2为本技术第一个实施例的汇聚流程图;图3为本技术第一个实施例的目标数据库结构生成图;图4为本技术第一个实施例的语义字典维护流程;图5为本技术第一个实施例的应用视图间和组成应用视图的属性表间的关联;图6为本技术第一个实施例的应用视图生成流程;图7为本技术第一个实施例的语义类应用视图构造图。
27.图8为本技术第一个实施例的源数据表记录转换为应用视图记录。
28.图9为本技术第一个实施例的应用视图存储流程。
29.图10为本技术第一个实施例的示例:设计和建立目标数据库的类。
30.图11为本技术第一个实施例的示例:建立目标数据库的对象表、属性表和生命周期属性表结构。
31.图12为本技术第一个实施例的示例:在目标数据库语义类中生成语义字典。
32.图13为本技术第一个实施例的示例:设计和建立目标数据库的应用视图。
33.图14为本技术第一个实施例的示例:构建汇聚接口。
34.图15为本技术第一个实施例的示例:汇聚数据。
35.图16为本技术第二个实施例的工作流程。
36.图17为本技术第二个实施例的环境部署;图18为本技术第二个实施例的参数设置;图19为本技术第二个实施例的汇聚流程。
具体实施方式
37.实施例一本实施例提供了一种数据汇聚方法;如图2所示,一种数据汇聚方法,包括:s101:定义阶段:获取源数据库结构,生成目标数据库结构,定义表达同类客观事物性质结构的数据视图和定义源数据库到目标数据库的映射规则;s102:转储阶段:以源数据库数据表为单位抽取源数据库的数据;使用封装了源数据库到目标数据库映射规则的数据接口,将所抽取数据按照预先定义数据视图进行组织后,存储至目标数据库。
38.进一步地,所述s101中,获取源数据库结构;具体包括:获取源数据库中要汇聚数据表自身性质数据(如表名、所属域、所属用户等)和要汇聚的数据表中字段的性质数据(如字段名、字段含义,长度、数据类型,主键标志等)。
39.进一步地,所述s101中,生成目标数据库结构,具体包括:s101a1:将源数据库中数据表的字段按表所描述的客观事物分类(如描述人员性质的字段划归人员类、描述单位性质的字段划归机构类,示例见图10),进而得出目标数据库中的类,并为类命名;s101a2:依据稳定数据模型(本原模型)和目标数据库的类生成目标数据库;其中,稳定数据模型(本原模型)与需求和源数据库无关;s101a3:根据源数据库中表字段的含义生成类对应的语义字典,并将语义字典加
载至目标数据库的语义类中。
40.进一步地,如图3所示,所述s101a2:依据与需求和源数据库无关的稳定数据模型(本原模型)和目标数据库的类生成目标数据库;具体包括:s101a21:输入类标识和类名称;s101a22:分别以{类标识,类名,状态=0}、{类标识,开始时间=建立时的日期时间,终止时间=null}为参数,在目标数据库的class_struc[类表](表1)、class_lifeattr[类生命周期属性表](表2)中新建一条记录(示例见图10);进一步地,所述class_struc[类表]、class_lifeattr[类生命周期属性表]是本原模型的组成部分。本原模型具体是指:根据本体论,以图论为技术基础、以软件工程中定义的数据类型为设计标准、与数据存储技术(如oracle、mysql等)不相关、通过有限个、可枚举数据类型构成的相同结构来表达客观事物特性、面向对象的键
‑
值形式的存储模型。
[0041]
本原模型由基础构造表(表1~表9)、语义类(表10~表22)和应用视图的集合组成。
[0042]
进一步地,所述基础构造表,用于建立目标数据库的数据表结构;基础构造表是指:class_struc[类表](表1),用于保存为目标数据库所设计的类;class_lifeattr[类生命周期属性表](表2),用于保存为目标数据库所设计的类的生命周期属性;attr_type[属性种类表](表3),保存了目标数据库中类所包含的属性表的种类;用于生成目标数据库的属性数据表时,界定类所包含的属性表种类与个数(每个类所包含的属性表种类及个数都是一样的);class_object[对象表模板](表4)、class_singleattr[单值属性表模板](表5)、class_doubleattr[双值属性表模板](表6)、class_threeattr[三值属性表模板](表7)、class_blobattr[二进制属性表模板](表8),是建立属性表结构(除生命周期属性表)的模板,在目标数据库中建立的所有属性表结构都是表4~表8的副本;生命周期属性表用于描述类表、对象表和属性表中类、对象、属性的生存时长。life_attr[生命周期属性表模板](表9)是建立生命周期属性表结构的模板,在目标数据库中建立的所有生命周期属性表结构都是表9的副本。
[0043]
进一步地,所述语义类是指:具有相同结构——{代码,语义,多态性标志}的语义字典(客观事物)的集合。语义类是根据本原模型预先定义好的类实例,是本原模型的组成部分。语义类由表10~表17所示数据表(对象表、属性表和生命周期属性表)、语义类语义字典(表18~表22)和语义类应用视图(表23~表24)构成。
[0044]
sema_object[语义类对象](表10)用于存放语义字典的全球唯一标识;sema_id[语义类标识](表11)用于存放语义字典的外在标识(可理解标识)和含义对应的代码集合;sema_name[语义类称谓](表12) 用于存放语义对象(语义字典)的名称和含义代码对应的含义;
sema_bool[语义类布尔](表13)用于存放含义代码对应的含义所表示数值是否可以有多个有效的标志;sema_object_l[语义类对象生命周期]、sema_id_l[语义类标识生命周期]、sema_name_[语义类称谓生命周期]、sema_bool_l[语义类布尔生命周期](表14~表17)是生命周期属性表,用于分别存放语义类对象表、语义类标识表、语义类称谓表、语义类布尔表中记录的生存时长;语义类语义字典(表18~表20)用来说明语义类中数据的含义。也就是语义字典中的数据是如何解释的,与其它类的语义字典不同,语义类语义字典是预先定义的,语义类语义字典同样存放在语义类中,语义字典与语义类的属性表是一一对应的。在语义类中,gmst1005
‑
sema/布尔语义字典[语义](表18)对应sema_bool[语义类布尔](表13)、gm1065
‑
sema/标识语义字典[语义](表19)对应sema_id[语义类标识](表11)、gm1070
‑
sema/称谓语义字典[语义](表20)对应sema_name[语义类称谓](表12)。
[0045]
如图7所示,v_semadict[语义字典目录](表21)、v_semas[语义字典集合](表22)是根据语类对象、属性表预先构建的数据视图,是对语义字典的可理解描述。表21以可理解的方式展示了语义类中所有语义字典的目录,而表22则展示了每个语义字典的内容(语义)。
[0046]
进一步地,所述应用视图是指表达客观事物性质结构的数据视图,由至少一个属性表构成;应用视图除具备数据视图的特征外,还具备:应用视图是对同类数据的可理解描述;应用视图有且仅有一个属性表作为应用视图的主键,作为主键的属性表称之为主属性表(master),构成应用视图的其它属性表称为从属性表(slave);应用视图间、组成应用视图的属性表间的关联如图5所示。
[0047]
主从属性表之间为星型模型,通过slave.parent=master.attrid关联;应用视图之间为树型模型,通过父视图.master.attrid=子视图.master.parent关联,应用视图只能有一个父应用视图(可以没有)。
[0048]
s101a23:以“类标识_object”为类对象表的名称、“类标识_object_l”为类对象生命周期属性表的名称,以class_object[类对象表模板]、life_attr[生命周期属性表模板]为模板在目标数据库中建立类对象表和类对象生命周期属性表(示例见图11);s101a24:从attr_type[属性种类表](表3)表逐条取出属性名、值类型、值数量和值类型;s101a25:根据目标数据库所依赖的数据库管理系统dbms和取出的“值类型”参数获取值对应的实际数据类型,同时更改充当模板的属性结构中的值类型为实际数据类型;s101a26:设置“类标识_属性名”为属性表名称、“类标识_属性名_l”为生命周期属性表名称;s101a27:根据值数量(0,1,2,3)的不同分别以class_blobattr[二进制属性结构]表、class_singleattr[单值属性结构]表、class_doubleattr[双值属性结构]表、class_threeattr[三值属性结构]表为模板,在目标数据库中建立名称为s101a26所设置属性表名称的属性表(示例见图11);s101a28:以life_attr[生命周期属性表模板]表为模板在目标数据库中建立名称
为s101a26所设置生命周期表属性名称的生命周期属性表(示例见图11);s101a29:若attr_type[属性种类表](表3)中的所列属性还有未建立的属性表,则重复s101a24~s101a28直至所有的属性表建立完毕;s101a2a:若attr_type[属性种类表](表3)中的所列属性建立完毕,则跳转至s101a21建立另一个类所包含的对象、属性和生命周期表。
[0049]
进一步地,所述s101a3:根据源数据库中表字段的含义生成类对应的语义字典;具体包括:s101a31:获取源数据库中所有表的字段的含义和数据类型,形成字段含义集合;s101a32:以目标数据库的类表[class_struc]中的类为标准,对字段含义集合分类,形成字段含义分类集合。即,属于同一类的源数据库表中的字段含义作为一个独立集合;s101a33:根据字段含义分类集合在目标数据库的属性种类表[attr_type]中序号<10(基础属性表)的记录集合中查找获取值类型与字段含义对应的数据类型相似的属性表,将字段含义按属性表名分类,形成以“属性表名
‑
类名”命名(语义字典标识)的语义字典。
[0050]
s101a34:按{标识、称谓}格式完善语义字典名称对应的标识;按{代码、语义(含义)、多态标志(表18)}格式完善语义对应代码(缺省代码格式:“类名
‑
属性表名
‑
顺序码”)、多态标志,并根据实际进行调整(如从基础属性表改为扩展属性表、修改语义的描述等)。
[0051]
s101a35:以语义类应用视图(见表21~22)形式组织语义字典后,存入目标数据库中语义类对应的属性表中。
[0052]
生成语义字典的建立流程,如附图4所示,示例见图12。
[0053]
进一步地,所述s101中,定义表达同类客观事物性质结构的数据视图,如图6所示,示例见图13,具体包括:s101b1:输入应用视图参数:视图、归属类、父视图等(见表23),保存到目标数据库的applviews[应用视图集合];s101b2:输入应用视图列参数:列、序号、属性表、列语义、多态标志、关键列标志、关键列类型、关联列标志、关联列类型、关联列、父列、父列类型等(见表24),保存到applview_cols[应用视图列集合];s101b3:从applview_cols[应用视图列集合]中读取应用视图的列参数集合,取出对应的属性表集合;s101b4:选定主属性表master,设置其检索条件为:master.semaobject=对应的语义和master.state=0;s101b5:建立主属性表master和从属性表slave(构成应用视图的主属性表之外的其它属性表)的连接条件,slave.parent=master.attrid、slave.semaobject=对应语义、slave.state=0;s101b6:以主属性表检索条件、主
‑
从属性表的连接条件,各属性表的attrvalue[属性值]为列(按规范命名)和列对应的排列顺序建立生成视图的sql语句;s101b7:运行sql语句生成应用视图。
[0054]
进一步地,所述s101b2,还包括:应用视图列命名规则:不可以有空格、“$”,属性表
为单值属性表时,使用“sss”命名;属性表为非单值属性表时,使用“sss_sssn”命名。sss为不含“$”和“_”的任意字符组合。属性表为双、三值属性表时,n为1、2、3,对应attrvalueup、attrvaluelow、attrvaluemid;属性表为二进制值属性表时n为1、2,对应valueindex、value。
[0055]
进一步地,所述s101中,定义源数据库到目标数据库映射规则;映射规则通过数据接口封装。封装了映射规则的数据接口称为汇聚接口。具体包括:s101c1:输入{汇聚源、接口}到interfaces[汇聚接口集合](表25)所描述的数据表;进一步地,汇聚源是指,包含了源数据库连接串的源数据库唯一标识;接口是指,源数据库的数据表(名),格式为:汇聚源.数据库用户(或数据库域).数据表名。
[0056]
s101c2:输入{字段、数据来源、序号、字段类型、字段长度}到integrationfields[汇聚字段集合](表26)所描述的数据表;进一步地,字段是指,源数据库的数据表(接口)中的字段(名),格式为:数据表名.字段名;数据来源是指,字段所存储的值是直接输入的(用“原生”表示)、是从其它表的字段间接获取的(用“引用”表示)。
[0057]
s101c3:输入{视图列、视图列语义、视图列分组、存储值}到viewcolumnmapps[视图列映射集合](表27)所描述的数据表;进一步地,视图列是指,组成应用视图的列名,格式为:应用视图名.列名,它是字段映射的对象,同一字段可以映射到不同的列,不同字段也可以映射到同一列;视图列语义是指,列值的含义,它取自对应的语义字典;视图列分组是指,当不同字段也可以映射到同一列时,映射的序列;存储值是指,当该项有值(不为空)时,列并不接收映射字段的值,而是接收存储值中的值。
[0058]
进一步地,所述s102:从源数据库中逐张表抽取源数据库中表的数据;使用封装了源数据库到目标数据库映射规则的数据接口,将所抽取数据按照预先定义数据视图进行组织后,分类存储至目标数据库;如图8和图9所示,具体包括:s1021:从所抽取的源数据库数据集合中,逐表取出源表记录集合;s1022:用源表名在汇聚字段集合表integrationfields中,查找获取接口与之相符的接口字段集合;s1023:用接口字段集合在视图列映射集合表viewcolumnmapps中,查找获取字段与之相符的映射列记录集合;s1024:从映射列记录集合抽出视图名集合,从应用视图集合表applviews中检索出符合树型模型的完整视图集合(全树);同时,将完整视图集合组织成{视图1:父视图,视图2:父视图,视图3:父视图,...}(父视图在{视图1,视图2,视图3,...}之中)形式的视图树集合;同时将完整视图集合中的class/归属类追加到对应的映射列记录;s1025:根据映射列记录集合从应用视图列集合表applview_cols中检索,将检索到的应用视图列记录追加到对应的映射列记录;同时,将接口字段集合的数据合并到对应的映射列记录;而后将映射列记录集合按序号colno排序后,组织成{视图1
‑
列性质记录集合,视图2
‑
列性质记录集合,视图3
‑
列性质记录集合,...}形式的视图
‑
列
‑
字段性质集合s1026:自根到叶遍历视图树,取出节点对应的视图名;
s1027:从源表记录集合中取出源表记录,用节点对应的视图名从视图
‑
列
‑
字段性质集合中取出对应的列性质记录集合;s1028:从列性质记录集合逐条取出列性质记录,在源表记录获取字段名与之相同的字段值;s1029:以列性质记录、字段值为参数,构建视图对应的属性表记录;将新建的属性表记录组织成以节点对应视图名命名的应用视图记录;最终形成新建应用视图记录集合。
[0059]
s102a:在目标数据库开启一个存储事务;s102b:自根到叶逐层、逐个节点读取视图树集合,获得视图名;s102c:根据视图名从新建应用视图记录集合中获得视图记录数据,从视图
‑
列
‑
字段性质集合中获取该视图的性质集合;s102d:从视图记录数据中逐条取出视图记录;s102e:根据性质集合从视图记录取出主属性表记录存储并返回存储成功的记录;s102f:根据性质集合从视图记录逐个取出从属性表记录,若需要将主属性表记录的attrid值赋给从属性表记录的parent;s102g:存储从属性表记录,直到所有属性表存储完毕,返回存储成功的视图记录;s102h:若存储的应用视图有子视图,则将该应用视图中关联列的值赋给子视图主属性表的parent,而后存储子视图记录,直到视图树集合所有视图存储完毕;s102i:向目标数据库提交事务。
[0060]
图14为本技术第一个实施例的示例:构建汇聚接口。图15为本技术第一个实施例的示例:汇聚数据。
[0061]
图12中连接线上的数字表示对应流程节点的运行结果。
[0062]
1表示从源数据库数据表中取出人员、机构和岗位类对应的字段含义和数据类型形成pers/人员类、orga/机构类和jobs岗位类对应由含义、数据类型构成的数据集合;2表示以步骤1运行结果为条件,查找获取attr_type/属性种类表中序号<10且值类型与步骤1运行结果中字段数据类型相匹配的基础属性名,进而形成pers/人员类、orga/机构类和jobs岗位类对应的属性名集合;3表示以步骤2运行结果为基础,逐个为属性名增加代码前缀。形成pers/人员类、orga/机构类和jobs岗位类对应的代码前缀(具体类属性名)集合;4表示以步骤3运行结果为基础,逐个为代码前缀(具体类属性名)增加以0或1为标识的多态标志,形成pers/人员类、orga/机构类和jobs岗位类相对于代码前缀(具体类属性名)对应的多态标志集合;5表示将步骤1~4运行结果汇总由代码前缀(具体属性名)、含义、多态标志构成的按代码前缀(具体类属性名)排序的数据集合;6表示以步骤5运行结果为基础,分类取出代码前缀(具体类属性名)相同的数据集合形成具体类属性的语义字典,按照代码格式(代码前缀 自然序号)完善代码前缀形成代码,最终形成以代码前缀命名的pers/人员类、orga/机构类和jobs岗位类对应的各属性的语义字典。
[0063]
实施例二本实施例提供了一种数据汇聚系统,
如图16所示,一种数据汇聚系统,包括:p101:部署阶段:依托网络部署web应用服务器、消息服务器、目标数据库服务器和数据汇聚端;p102:配置阶段:在web应用服务器配置汇聚参数;p103汇聚阶段:启动服务器,接收源数据库数据,转储至目标数据库。
[0064]
进一步地,如图17所示,所述p101中,依托网络部署web应用服务器、消息服务器、目标数据库服务器和数据汇聚端;具体包括:f1011:web应用服务器:用于控制汇聚流程。由元数据库、消息服务器控制组件、汇聚对象获取组件、目标库结构维护组件、语义字典维护组件、视图维护组件、接口维护组件和数据转储组件构成。
[0065]
f10111:元数据库:用于存储属性种类数据(表3)、应用视图元数据(表23~24)、汇聚接口元数据(表25~27)、消息控制元数据等;用于支持web服务器中的组件运行;f10112:消息服务器控制组件:用于维护(增、删、改)消息服务的运行参数,保障消息服务器按预期的方式运行;f10113:汇聚对象获取组件:从数据汇聚端读指定数据库的库结构、表结构;f10114:目标库结构维护组件:维护(增、删、改)目标数据库中的类相关表(表1~2),根据类相关表、目标数据库中的表模板(表4~9),依据元数据服务器上的属性种类(表3)在目标数据上建立或修改对象表、对象生命周期属性表、属性表、属性生命周期属性表的结构;f10115:语义字典维护组件:维护(增、删、改)语义字典,维护结果存入目标数据库的语义类中;f10116:视图维护组件:维护(增、删、改)应用视图构建参数,根据参数在目标服务器上建立视图;f10117:接口维护组件:维护(增、删、改)汇聚接口,维护结果存入元数据服务器(表25~27);f10118:数据转储组件:通过汇聚接口接收消息服务器传来的数据,将其按对应的应用视图组织并存储到目标数据库中。
[0066]
f1012:消息服务器:由消息中间件(使用kafka中间件)和数据接收中间件(使用oracle golden gate[目标端]中间件)组成,用于接收数据汇聚端发送的数据、组织成消息发送至web应用服务器;f1013:目标数据库服务器:由支持任意种类的数据库管理系统的数据库构成,用于存储汇聚后的目标数据。初始安装时,目标数据库仅有class_struc[类表](表1)、class_lifeattr[类生命周期属性表](表2)、对象、属性、生命周期属性表的模板(表4~9)、语义类的52张表(对象表、属性表、生命周期属性表)和2张视图(表21~22);f1014:数据汇聚端:由源数据库拥有者提供。部署时需开启对应的日志模式和安装数据抽取中间件(使用oracle golden gate[源端]中间件)以满足抽取数据的需要;进一步地,如图18所示,所述p102中,在web应用服务器配置汇聚参数;具体包括:f1021:汇聚对象获取组件从汇聚端获取数据库和数据表的结构信息并存放到元数据库中;
f1022:目标库结构生成组件根据所设计的类在目标库自动生成目标数据库的表结构;f1023:根据汇聚端的数据表结构使用语义字典维护组件建立对应于类属性的语义字典集合,并加载到目标库的语义类;f1024:使用视图维护组件输入应用视图的构建参数并存储到元数据库,根据参数在目标数据库中自动建立应用视图;f1025:使用接口维护组件输入汇聚接口的构建参数并存储到元数据库;f1026:使用消息服务控制组件输入消息收发的配置参数并存储到元数据库;进一步地,如图19所示,所述p103中,启动服务器,接收源数据库数据,转储至目标数据库;具体包括:f1031:汇聚端通过数据抽取中间件抽取数据,发送到消息服务器;f1032:启动web应用服务器和消息服务器;f1033:数据接收中间件收到汇聚端数据抽取中间件发送来的数据,转发给消息中间件;f1034:消息中间件将收到数据组织成消息格式发送给web服务器;f1035:web服务器的数据转储组件将收到消息通过汇聚接口按应用视图的格式组织,而后存入目标数据库。
[0067]
附表表1 class_struc[类表]表2 class_lifeattr[类生命周期属性表]表3 attr_type[属性种类表]
表4 class_object[对象表模板]表5 class_singleattr[单值属性表模板]表6 class_doubleattr[双值属性表模板]
表7 class_threeattr[三值属性表模板]表8 class_blobattr[二进制属性表模板]
表9life_attr[生命周期属性表模板]表10sema_object[语义类对象]表11sema_id[语义类标识]表12sema_name[语义类称谓]
表13sema_bool[语义类布尔]表14sema_object_l[语义类对象生命周期]表15sema_id_l[语义类标识生命周期]表16sema_name_[语义类称谓生命周期]表17sema_bool_l[语义类布尔生命周期]
表18bool
‑
sema/布尔语义字典[语义]表19id
‑
sema/标识语义字典[语义]表20name
‑
sema/称谓语义字典[语义]表21v_semadict[语义字典目录]
表22v_semas[语义字典集合]
表23applviews[应用视图集合]表24applview_cols[应用视图列集合]applview_cols[应用视图列集合]表25interfaces[汇聚接口集合]
表26integrationfields[汇聚字段集合]表27viewcolumnmapps[视图列映射集合]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
