1.本发明涉及一种带有缺失标记的不完备数据的多标记分类方法及装置,属于数据分类技术领域。
背景技术:
2.近年来,多标记学习吸引了越来越多来自各个领域学者的研究兴趣。多标记学习解决了每个样本同时与多个语义标记相关联的问题。例如,一篇新闻报道可以属于政治,经济学和文化等多个主题。多标记学习的目标是训练一个分类模型,该模型可以为每个未标记的实例分配一组相关的标记。由于其在真实场景中的重要性,目前,已经提出了许多多标记分类的方法,并在各种应用中取得了不错的结果。通常,大多数多标记分类算法可以大致分为问题转换法和算法适应法。问题转换法常常将多标记分类模型转换为一系列单标记分类问题。算法适应法往往基于最大后验概率估计对传统的单标记分类模型进行改进,从而可以应用于多标记数据集。然而,上述方法通常忽略了多标记数据集中标记之间的相关性。
3.多标记数据集分为完备数据集和不完备数据集。对于完备的多标记数据集,tsoumakes等在文献(grigorios tsoumakas,ioannis katakis.multi
‑
label classification:an overview.international journal of data warehousing and mining,2009,3(3):1
‑
13.)中将多标记学习问题转化为一系列的二元分类问题。br方法在充分利用高性能传统单标记分类方法,这是一种在实践中已广泛使用的简单策略。但是,这种方法需要更多的计算成本,并且忽略了标记之间的相关性,这将影响预测结果。jesse等在文献(jesse read,bernhard pfahringer,geoff holmes,eibe frank.classifier chains for multi
‑
label classification.machine learning,2009,85(3):254
‑
269.)中通过利用标签链,层次聚类和贝叶斯网络结构考虑了高阶标签相关性。然而,该方法并不能较容易地获得标记相关矩阵。甚至在某些情况下,这些假设的结构根本不存在。尽管已经在许多领域设计出了许多完整的多标记数据集的分类方法,但是此类方法存在一个根本的假设,即每个训练实例都给出了一个“完整”的标记集。然而在许多情况下,这种假设很难成立。由于实际环境的复杂性,数据通常可能包含噪音和缺失的特征。早期,以rubin为代表的学者们提出了四种处理缺失数据的方法:直接删除法,基于插值的方法,基于参数似然的方法和基于加权调整的方法。除了上述四种处理缺失数据的方法外,近年来,随着数据挖掘和分析技术的兴起,基于粗糙集的数据补充方法逐渐受到学者关注,应用最为广泛。在这种情况下,越来越多的专家学者将其应用于不完备数据补全领域,并提出了各种改进策略。段鹏等在文献(段鹏,庄红林,何磊,张寒云.不完备数据分析方法(roustida)的改进算法.计算机工程与设计,2009,30(7):1681
‑
1684)中对传统的基于粗糙集的算法进行了改进,以解决缺少属性的对象与任何对象都不相似或与多个对象相似的情况。田树新等在文献(田树新,吴晓平,王红霞.一种基于改进的roustida算法的数据补齐方法.海军工程大学学报,2011,23(5):11
‑
15.)中区分了条件属性和决策属性,扩展了传统的基于粗糙集的算法的应用范围,并通过实例说明改进后的算法可以获得更集中的决策规则。但是,上述改进方法不能直
接用于处理连续属性。
4.由于潜在的不可靠的人类标注以及注释者有时可能容易出错,因此获得完全正确的标记实例相对困难。因此,我们获得的数据集通常包含大量的缺失标记。对于不存在缺失标记的多标记数据集,基于深度神经网络模型,zhang和zhou等在文献(zhang minling,zhou zhihua,multilabel neural networks with applications to functional genomics and text categorization.ieee transactions on knowledge and data engineering,2006,18(10):1338
‑
1351.)中尝试学习一个新颖的特征空间,然后使用顶部的分类器进行预测。但是,它不适用于小型数据集,并且需要手动设置大量的超参数。另外,一些算法还尝试在学习多标记分类器时自动发现和利用标记相关性。通常,由于多个标签之间可能存在复杂的相关性,因此与传统的单标记分类任务相比,多标记学习更具挑战性。尽管这些方法可以有效地应用于多标记数据集,但是当数据集包含缺失标签时,这些方法的分类性能可能会大大降低。
5.为了解决这一缺陷,bi和kwok在文献(bi wei,kwok james t.multilabel classification with label correlations and missing labels.proceedings of the twenty
‑
eighth aaai conference on artificial intelligence,2014:1680
‑
1686.)提出了一种具有标记相关性的缺失标记多标记学习方法。该方法可以有效地解决含有缺失标记的多标记数据集,并自动学习和构建标记相关性矩阵。但是,它仅考虑二阶,对称的标记正相关性。zhu等在文献(zhu yue,james t.kwok,zhihua zhou.multi
‑
label learning with global and local label correlation.ieee transactions on knowledge and data engineering,2018,30:1081
‑
1094.)中设计了一种具有全局和局部标签相关性的多标记分类方法,该方法学习缺失标记的多标记分类并同时利用标记相关性,但它未指定全局和局部标记相关性,而是由标记流形正则化合并。he等在文献(he zhifen,yang ming,gao yang,liu huidong,yin yilong.joint multi
‑
label classification and label correlations with missing labels and feature selection.knowledge
‑
based systems,2019 163:145
‑
158.)中提出了一种新的具有标记相关性,应用于含有缺失标记数据上的特征选择和多标记分类方法。该方法不仅可以使用独立的二分算法进行联合学习,还可以对多标记分类和标记相关性进行联合学习,但是该方法将多标记分类任务视为几个二分类问题,导致较高的时间消耗。zhang等在文献(zhang changqing,yu ziwei,fu huazhu,zhu pengfei,chen lei,hu qinghua.hybrid noise
‑
oriented multilabel learning.ieee transactions on cybernetics,2019,99:1
‑
14.)中提出了一种用于混合噪声数据的统一鲁棒多标记学习框架,它可以有效地同时处理具有噪音特征和缺失标记的多标记数据集。但是,现有的处理含有缺失标记的多标记分类算法通常仅限于特征空间中的线性关系,而忽略了属性集中的非线性关系,这可能导致分类能力下降。
技术实现要素:
6.本发明的目的是提供一种带有缺失标记的不完备数据的多标记分类方法及装置,以解决目前带有缺失标记的不完备数据多标记分类过程中存在的效率低、分类精度不高的问题。
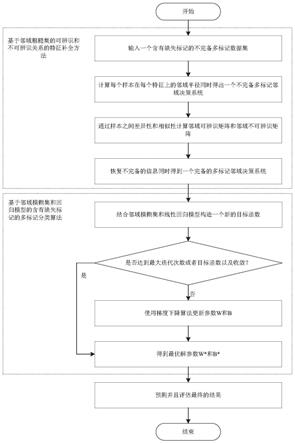
7.本发明为解决上述技术问题而提供一种带有缺失标记的不完备数据的多标记分
类方法,该分类方法包括以下步骤:
8.1)获取含有缺失标记的不完备多标记数据集,并计算数据集中每个样本在每个特征上的邻域半径,得到一个不完备多标记邻域决策系统;
9.2)根据得到的邻域半径,通过样本之间差异性和相似性计算邻域可辨识矩阵和邻域不可辨识矩阵;
10.3)基于邻域可辨识矩阵和邻域不可辨识矩阵,确定样本之间的相似度,由此恢复不完备的信息,并得到所恢复信息的特征权重矩阵;
11.4)根据所述的特征权重矩阵,并结合邻域模糊集和线性回归模型构造新的目标函数;
12.5)采用交替梯度下降策略对新的目标函数进行优化求解,以实现对含有缺失标记的不完备数据的多标记分类。
13.本发明还提供了一种带有缺失标记的不完备数据的多标记分类装置,该装置包括处理器和存储器,所述处理器执行由所述存储器存储的计算机程序,以实现本发明所述的带有缺失标记的不完备数据的多标记分类方法。
14.本发明首先基于邻域粗糙集理论,通过样本之间的差异性和相似性,构造了邻域可辨识和不可辨识矩阵,以此恢复不完备的信息,并得到所恢复信息的特征权重矩阵;然后基样本之间的模糊相似关系,结合模糊相似关系、回归模型以及特征权重矩阵建立考虑特征之间非线性关系的新的目标函数,并通过梯度下降方法对其进行优化求解,从而实现对带有缺失标记的不完备数据的多标记分类。本发明充分考虑了特征之间的非线性关系,大大提高了带有缺失标记的不完备数据的多标记分类的精度和效率。
15.进一步地,减少邻域集中样本数量不平衡的状况同时减少手动设置的时间消耗,所述步骤1)中邻域半径的计算公式为:
[0016][0017]
其中,δ
a
′
(x
i
)为样本x
i
在属性a上的邻域半径,mean(a)是属性a中所有未缺失属性的平均值,f
a
表示属性a中所谓未缺失属性的密度函数,max(f
a
)是密度函数f
a
的最大值,f
a
(x
i
)表示样本x
i
在属性a上所对应的密度函数值。
[0018]
进一步地,所述的特征权重矩阵为:
[0019][0020]
其中,iter代表用于恢复样本x
i
的第j个特征所用的迭代次数,iter
max
表示最大迭代次数。
[0021]
进一步地,所述步骤4)中建立的新的目标函数为:
[0022][0023][0024]
其中α,β,γ和λ是超参数,x∈r
m
×
n
为样本集,y∈r
t
×
n
为标记集,b∈r
t
×
t
和w∈r
t
×
m
分
别是标记相关性矩阵和特定标记特征矩阵,||w||2和||b||2分别是矩阵w和矩阵b的l
‑
2正则项,tr(byl1y
t
b
t
)是矩阵byl2y
t
b
t
的迹,l2=d2‑
s是一个拉普拉矩阵,s是模糊相似矩阵,d2是一个对角矩阵,且有s
ij
表示样本x
i
和样本x
j
之间的模糊相似度,c表示特征权重矩阵,w
i
和w
j
分别表示矩阵w的第i列和第j列的值,b
ij
表示矩阵b中第i行第j列的值,
⊙
表示哈达玛积。
[0025]
进一步地,为提高计算效率,所述步骤5)在求解过程中将新的目标函数划分成w子问题和b子问题,在求解w子问题时,固定b更新w,计算新的目标函数转换成关于w的偏导数,并按照变量w的迭代梯度下降策略进行求解;在求解b子问题时,固定w更新b,计算新的目标函数转换成关于b的偏导数,并按照变量b的迭代梯度下降策略进行求解。
[0026]
所述步骤3)的实现过程如下:
[0027]
a.计算样本的差异性和样本的相似性;
[0028]
b.确定缺失属性集合和缺失属性的对象集合;
[0029]
c.根据缺失属性集合和缺失属性的对象集合确定按照样本差异性升序排列的集合以及按照样本相似性降序排列的集合;
[0030]
d.利用样本差异性升序排列的集合与样本相似性降序排列的集合中共有样本的特征均值作为缺失特征的恢复值。
[0031]
进一步地,所述步骤a中样本的差异性和样本的相似性的计算公式分别为:
[0032][0033][0034]
其中ns(x
i
,x
j
)表示样本x
i
和x
j
的差异性,b为属性集,a
k
∈b,a
k
为样本的属性,m为邻域可辨识矩阵,ps(x
i
,x
j
)表示样本x
i
和x
j
的邻域相似度,表示样本x
i
和x
j
在属性a的邻域半径内的相似性。
[0035]
进一步地,所述步骤b中的缺失属性集合为:
[0036]
mas
i
={a
k
|a
k
(x
i
)=*,k=1,
…
,m},
[0037]
其中a
k
为样本的第k个属性,x
i
和表示样本,符号*代表缺失的特征。
[0038]
进一步地,所述步骤b中的缺失属性的对象集合为:
[0039][0040]
其中mas
i
表示缺失属性集合,表示空集。
附图说明
[0041]
图1是本发明带有缺失标记的不完备数据的多标记分类方法的流程图。
具体实施方式
[0042]
下面结合附图对本发明的具体实施方式作进一步地说明。
[0043]
方法实施例
[0044]
在对本发明的具体实施步骤进行介绍之前,先对本发明所用到的一些基础知识进行介绍,主要是对邻域粗糙集和邻域模糊集的介绍。
[0045]
邻域粗糙集
[0046]
给定一个不完备邻域决策系统inds=<u,c,d,v,f,δ,δ>,其中u={x1,x2,
…
,x
m
}表示样本全集;c和d分别表示条件属性和决策类;v=∪
a∈at
v
a
,且v
a
是属性a的值域;f是一个信息函数并满足映射关系f:u
×
{c∪d}
→
v,f(a,x)是样本x在属性a上的值;符号
‘
*’代表缺失的特征,δ是一个距离函数;0≤δ≤1是邻域参数。这个不完备邻域决策系统可简写为inds=<u,c,d,δ>。则样本x在属性集b上的邻域内样本集合可以表示为:
[0047]
δ
b
(x)={y|x,y∈u,δ
b
(x,y)≤δ,δ≥0},
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0048]
其中表示欧式距离,n是特征集合b中的特征数目。
[0049]
给定一个不完备邻域决策系统inds=<u,c,d,δ>,对于任意的和b=b
c
∪b
n
,其中b
c
是决策属性集合,b
n
是特征属性集合,则在特征集b上的邻域容差关系可以表示为:
[0050][0051]
对于任意x∈u和则邻域容差类可以表示为:
[0052][0053]
邻域模糊集
[0054]
假设nds=<u,c,d,v,f,δ,δ>是一个邻域决策系统。u={x1,x2,
…
,x
m
}是样本集合,c和d分别表示条件属性集合决策类。v
a
是属性a的值域,且v=∪
a∈at
v
a
。f是一个映射函数,且有f:u
×
{c∪d}
→
v,f(a,x)是样本x在属性值a上的取值。δ表示距离函数,δ表示邻域参数,且0≤δ≤1。该邻域决策系统之后简写为nds=<u,c,d,f>。
[0055]
给定一个邻域决策系统nds=<u,c,d,f>,a∈c,其中δ为模糊邻域半径参数,表示样本的相似性。之后对于任意两个样本x,y∈u,其在属性a上的模糊邻域相似关系以表示为:
[0056][0057]
对于任意x,y∈u,在全集u上包含模糊二元关系r
b
,则r
b
分别满足自反性和对称性,即
[0058]
(1)r
b
(x,x)=1,其中x∈u;
[0059]
(2)r
b
(x,y)=r
b
(y,x),其中x,y∈u.
[0060]
给定一个邻域决策系统nds=<u,c,d,f>,对于任意x,y∈u,样本x相对于b的参数化模糊邻域信息颗粒表示为:
[0061][0062]
本发明在上述技术的基础上,首先通过样本之间的差异和相似性构造邻域可识别和不可辨别的矩阵,并基于目标样本与邻域可识别矩阵中的样本之间的差异应尽可能大,目标样本与样本中的样本之间的相似性应尽可能大,邻域不可辨识矩阵应尽可能大的原则进行特征恢复;然后基于高斯核函数对模糊相似关系进行改进,使其可以考虑特征之间的非线性关系。然后,将模糊相似关系与线性回归模型相结合,构造了一个新的损失函数,并采用梯度下降法对其进行了优化。本发明的分类方法除了能够针对文本数据外,还可以有
效应用在图像,生物,音乐等领域上。该方法的实现过程如图1所示,具体实施步骤如下:
[0063]
1.获取含有缺失标记的不完备多标记数据集。
[0064]
本实施例中获取的含有缺失标记的不完备多标记数据集可以是文本数据集,也可以是其他类型的数据集。
[0065]
2.计算数据集中每个样本在每个特征上的邻域半径,得到一个不完备多标记邻域决策系统。
[0066]
假定一个不完备多标记决策系统imds=<u,c,d,v,f>,有对于任意的x
i
∈u,a∈b,样本x
i
在属性a上的邻域半径计算方式如下:
[0067][0068]
其中mean(a)是属性a中所有未缺失属性的平均值,f
a
表示属性a中所谓未缺失属性的密度函数,max(f
a
)是密度函数f
a
的最大值,f
a
(x
i
)表示样本x
i
在属性a上所对应的密度函数值。
[0069]
根据得到的每个样本在每个特征上的邻域半径,可以得到一个不完备多标记邻域决策系统imnds=<u,c,d,v,f,δ'>。
[0070]
3.根据得到的邻域半径,通过样本之间差异性和相似性计算邻域可辨识矩阵和邻域不可辨识矩阵。
[0071]
对于不完备多标记邻域决策系统imnds=<u,c,d,v,f,δ'>而言,有对于任意的a
k
∈b,x
i
,x
j
∈u,δ'
ak
(x
i
)表示样本x
i
在属性a
k
上的邻域半径,则邻域可辨识矩阵m的定义如下:
[0072][0073]
其中,i,j=1,2,
…
,|u|;“*”表示缺失的属性值;n
δ
'
{a}
表示样本x在属性a上的邻域内样本集合,且n
δ
'
{a}
(x)={y∈u|δ
{a}
(x,y)≤δ'
a
(x)∧a(y)≠*}。
[0074]
对于一个不完备多标记邻域决策系统imnds=<u,c,d,v,f,δ'>,有对于任意x
i
∈u,a∈b,δ'
a
(x
i
)表示表示样本x
i
在属性a上的邻域半径,m
a
={x∈u|a(x)≠*}是属性a上的非空样本集,对于任意x,y∈u,a∈b,样本x和y的相似性表示如下:
[0075][0076]
其中,δ
{a}
(x,y)表示样本x和y在属性a上的距离。
[0077]
对于不完备多标记邻域决策系统imnds=<u,c,d,v,f,δ'>,有对于任意x
i
,
x
j
∈u,则样本x
i
和样本x
j
的不可辨识度表示如下:
[0078][0079]
从中可以看出,当ns(x
i
,x
j
)包含更多特征时,样本x
i
和x
j
的可辨识性更强,也就是说,两个样本更有可能是异类的。
[0080]
4.基于邻域可辨识矩阵和邻域不可辨识矩阵,确定样本之间的相似度,并由此确定恢复不完备的信息的特征权重矩阵。
[0081]
给定一个不完备多标记邻域决策系统imnds=<u,c,d,v,f,δ'>,有对于任意两个样本x
i
,x
j
∈u,则样本x
i
和x
j
的邻域相似度可以表示如下:
[0082][0083]
当ps(x
i
,x
j
)的值越大时,样本x
i
和x
j
之间的相似度更大,也就是说,这两个样本更有可能是同类的。
[0084]
缺失属性集合和缺失属性的对象集合可以分别表示为:
[0085]
mas
i
={a
k
|a
k
(x
i
)=*,k=1,
…
,m},
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0086][0087]
缺失的特征无法在一次迭代中完全恢复,它将需要数次迭代才能完成恢复。特征恢复得越早,该特征的置信度就越高,反之亦然。鉴于上述情况,本发明构造了一个特征权重矩阵,即特征恢复越早,其所占权重就越高。
[0088]
对于一个不完备多标记邻域决策系统imnds=<u,c,d,v,f,δ'>,对于任意x
i
∈mos,a
j
(x
i
)∈mas
i
,则特征权重矩阵c的计算方式如下:
[0089][0090]
其中,iter代表用于恢复样本x
i
的第j个特征所用的迭代次数,iter
max
表示最大迭代次数。
[0091]
缺失特征补全和特征权重矩阵的求解的算法流程如下:
[0092][0093][0094]
5.结合邻域模糊集和线性回归模型构造新的目标函数。
[0095]
现有的大多数处理缺失标记的多标记分类方法都是基于线性模型构建的,但是其很难在数据空间中找到特征之间的非线性关系,进而影响分类的精度。为此,本发明基于模糊相似关系,采用高斯核函数和回归模型进行缺失标记多标记分类,以进一步挖掘数据空间中的非线性关系。
[0096]
给定一个含有缺失标记的多标记邻域决策系统mnds=<u,c,d,δ'>,其中b={f1,f2,
…
,f
m
},l={l1,l2,
…
,l
t
}。对于任意x
i
,x
j
∈u,则样本x
i
和样本x
j
在b上的模糊相似关系可以表示为:
[0097][0098]
其中,π
b
(x
i
,x
j
)是通过高斯核函数将样本x
i
和x
j
从原始特征空间中的映射到高维特征空间的距离。
[0099]
π
b
(x
i
,x
j
)=|k
b
(x
i
,x
i
) k
b
(x
j
,x
j
)
‑
2k
b
(x
i
,x
j
)|,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0100]
其中k
b
(x
i
,x
j
)表示样本x
i
和x
j
在特征空间b上的高斯内积,在特征空间b上的高斯内积,且0≤k(x
i
,x
j
)≤1,0≤π
b
(x
i
,x
j
)≤2,其中
[0101]
假设u是全体样本集合,给定一个训练集对于任意x
i
,x
j
∈x,则模糊相似矩阵s中样本x
i
和x
j
的模糊相似度为:
[0102]
s(i,j)=r
b
(x
i
,x
j
),
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0103]
其中s是一个n维方阵表示任意两个样本之间的模糊相似度,显然s是一个对称矩阵,即s(i,j)=s(j,i),且其主对角线的值为0,即s(i,i)=0。
[0104]
给定一个训练数据集x∈r
m
×
n
和其对应的标记集y∈r
t
×
n
,b∈r
t
×
t
和w∈r
t
×
m
分别是标记相关性矩阵和特定标记特征矩阵,则一个通用的目标函数可以写成:
[0105][0106]
其中l(
·
,
·
)和r(
·
)分别是损失函数和正则化函数,λ是超参数。
[0107]
给定一个训练标记集矩阵y∈r
t
×
n
和一个标记相关性矩阵b∈r
t
×
t
。为了保证原始标记矩阵和恢复标记矩阵之间的一致性:
[0108][0109]
其中y
i
∈r
t
×1是属于训练样本x
i
的标记向量,||y
‑
by||
f
表示矩阵y
‑
by的frobenius范数。
[0110]
给定一个特征标记特征矩阵w∈r
t
×
m
和一个标记相关性矩阵b∈r
t
×
t
。为了确保标记之间的相似度越高,特征权重就越近。设计了一个方程:
[0111][0112]
其中b
ij
表示标记i和标记j之间的相似度,w
i
和w
j
分别表示标记i和标记j所对应的模型的权重。l1=d1‑
b是图拉普拉斯矩阵,d1是一个对角矩阵,且有是一个对角矩阵,且有
[0113]
给定一个训练样本集x∈r
m
×
n
和其对应的标记集y∈r
t
×
n
,b∈r
t
×
t
和w∈r
t
×
m
分别是标记相关性矩阵和特定标记特征矩阵,新的目标函数可以写作:
[0114][0115]
其中β,γ和λ是超参数。
[0116]
给定一个训练样本集x∈r
m
×
n
和其对应的标记集y∈r
t
×
n
,b∈r
t
×
t
和w∈r
t
×
m
分别是标记相关性矩阵和特定标记特征矩阵,对于任意两个训练样本x
i
,x
j
∈x,当其具有高度相似性时,应确保相对于x
i
和x
j
的恢复标记向量应更接近。然后,将特征向量与恢复标记向量之间的一致性设计为:
[0117][0118]
其中tr(byl1y
t
b
t
)是矩阵byl2y
t
b
t
的迹,s
ij
的计算方式见公式(16)表示样本x
i
和样本x
j
之间的模糊相似度,l2=d2‑
s是一个拉普拉矩阵,s是模糊相似矩阵,d2是一个对角矩阵,且有
[0119]
给定一个训练样本集x∈r
m
×
n
和其对应的标记集y∈r
t
×
n
,b∈r
t
×
t
和w∈r
t
×
m
分别是标记相关性矩阵和特定标记特征矩阵,一个新的目标函数可以写作:
[0120][0121]
其中α,β,γ和λ是超参数,||w||2和||b||2分别是矩阵w和矩阵b的l
‑
2正则项。
[0122]
给定一个不完备训练样本集x∈r
m
×
n
和其对应的标记集y∈r
t
×
n
,b∈r
t
×
t
和w∈r
t
×
m
分别是标记相关性矩阵和特定标记特征矩阵,考虑到缺失特征的情况,新的目标函数可以写作:
[0123][0124]
其中
⊙
表示哈达玛积,c是基于公式(13)计算出来的权重矩阵。
[0125]
6.优化求解目标函数
[0126]
在对新的目标函数(公式23)优化求解过程中有两个变量w和b,同时由于该目标函数是凸的,因此,本发明采用交替梯度下降策略对目标函数进行优化,将优化问题分为两个子问题,即w子问题和b子问题,即可以选择优化一个变量,同时将另一个变量固定为常量。其具体优化过程如下:
[0127]
w子问题,固定b更新w,则目标函数l(w,b)关于w的偏导数可以写成:
[0128][0129]
其中
⊙
表示哈达玛积,之后对变量w的迭代梯度下降策略可以写成:
[0130][0131]
其中lr是超参数,表示学习速率。
[0132]
b子问题,固定w更新b,则目标函数则目标函数l(w,b)关于b的偏导数可以写成:
[0133][0134]
其中
⊙
表示哈达玛积,之后对变量b的迭代梯度下降策略可以写成:
[0135][0136]
其中lr是超参数,表示学习速率。
[0137]
通过上述方式可以实现对w和b的优化求解,从而可以实现对多标记数据集的分类。
[0138]
装置实施例
[0139]
本发明的带有缺失标记的不完备数据的多标记分类装置,包括处理器和存储器,所述处理器执行由所述存储器存储的计算机程序,以实现本发明实现上述方法实施例的方法。也就是说,以上方法实施例中的方法应理解可由计算机程序指令实现带有缺失标记的
不完备数据的多标记分类方法的流程。可提供这些计算机程序指令到处理器,使得通过处理器执行这些指令产生用于实现上述方法流程所指定的功能。
[0140]
本实施例所指的处理器是指微处理器mcu或可编程逻辑器件fpga等的处理装置;本实施例所指的存储器包括用于存储信息的物理装置,通常是将信息数字化后再以利用电、磁或者光学等方式的媒体加以存储。例如:利用电能方式存储信息的各式存储器,ram、rom等;利用磁能方式存储信息的的各式存储器,硬盘、软盘、磁带、磁芯存储器、磁泡存储器、u盘;利用光学方式存储信息的各式存储器,cd或dvd。当然,还有其他方式的存储器,例如量子存储器、石墨烯存储器等等。
[0141]
通过上述存储器、处理器以及计算机程序构成的装置,在计算机中由处理器执行相应的程序指令来实现,处理器可以搭载各种操作系统,如windows操作系统、linux系统、android、ios系统等。
[0142]
作为其他实施方式,装置还可以包括显示器,显示器用于将分类结果展示出来,以供工作人员参考。
[0143]
实验验证
[0144]
为了进一步地验证本发明的效果,下面将本发明与现有的四个经典的多标记分类算法进行比较。
[0145]
(1)实验准备。
[0146]
本次选择四个多标签文本类数据集进行实验,数据集的具体描述如表3所示。数据集可以下载http://mulan.sourceforge.net/datasets.html。为了评估本发明提出算法的有效性,将其与四个经典的多标记分类算法进行了比较,zhang等人撰写的《hybrid noise
‑
oriented multilabel learning》(ieee transactions on cybernetics,2019,99:1
‑
14)(简写为hnoml),furnkranz等人撰写的《multilabel classification via calibrated label ranking》(machine learning,2008,73(2):133
‑
153)(简写为clr),zhang和zhou撰写的《ml
‑
knn:a lazy learning approach to multi
‑
label learning》(pattern recognition,2007,40(7):2038
‑
2048)(简写为ml
‑
knn)和read等人《classifier chains for multi
‑
label classification》(machine learning,2009,85(3):254
‑
269)(简写为ecc)。这些实验基于具有3.00ghz处理器和8.00gb内存空间的windows 10,在matlab 2016b平台上运行。
[0147]
表3
[0148][0149]
(2)实验设置
[0150]
本实验选取average precision(ap),coverage(cv),hamming loss(hl),ranking loss(rl),one error(oe)这五种评价指标来分析和度量实验结果。
[0151]
average precision(ap):用于考察所有样本的预测标记排序中,排在隶属于该样本标记前面的标记仍属于该样本标记的概率的平均,定义为:
[0152][0153]
其中,ri={l|yil= 1}表示与样本xi相关的标记构成的集合,ri={l|yil=
‑
1}表示与样本xi不相关的标记构成的集合。
[0154]
coverage(cv):用于度量平均每个样本需要查找多少步才能遍历所有与该样本相关的标记,定义如下:
[0155][0156]
hamming loss(hl):用来度量样本在单个类别标记上的误分类的情况,定义为:
[0157][0158]
其中表示异或操作。
[0159]
ranking loss(rl):用来考察所有样本的不相关标记的排序排在相关标记前面的概率的平均,定义为:
[0160][0161]
one error(oe):表示样本类标记排序中,排在前面的标记但不属于相关标记结合的概率:
[0162][0163]
其中,ri={l|yil= 1}表示与样本xi相关标记构成的集合,ri={l|yil=
‑
1}表示样本xi不相关的标记构成的集合。
[0164]
以上5种评价指标中,指标ap的取值越大,表示分类性能越好;指标cv、hl、rl和oe的越小,表示分类性能越好。
[0165]
(3)实验比较
[0166]
将本发明与其他四个多标记分类算法在文本类数据集education、recreation、medical和arts上进行比较,评价指标有average precision(ap),coverage(cv),hamming loss(hl),ranking loss(rl)和one error(oe)。我们每次试验均采用五折交叉验证,所得的均值和方差记录在表中4。
[0167]
表4
[0168][0169][0170]
从表4中可以看出,本发明所提的方法(mcgdo)除了在数据集recreation的oe指标下略次于hnoml,在数据集medical的hl指标下略次于hnoml和ecc,在其余情况下均表现最优,综上所述,本发明所提的mcgdo算法具有良好的分类性能。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
