[0001][0002]
本发明涉及情感识别领域,尤其涉及一种基于深度学习的眼动信号情感识别方法。
背景技术:
[0003]
近年来,计算机和人工智能等领域飞速发展,现代教育技术也在快速发展与变革,为教育方式与教育手段带来了新的技术。随着国家对教育的投入,教育信息化进程日新月异,在线教育作为线下教育的补充,已经成为了一种突破时间和空间的阻碍的学习方式。每年在线学习的人数都以递增的趋势发展,在线教育越来越受到大众的欢迎与认可。在在线视频学习过程中,学习者会受学习材料产生不同的情感状态,而情感对于人类的认知、学习、记忆、思维和社交都有很大的影响。关联主义学习理论者西蒙斯(george siemens)指出,在学习过程中,学习者的思维方式和情感状态会相互影响。相关心理学研究表明,学习过程中的认真、高兴、满意等积极正向的情感状态有助于激发学习兴趣,促进认知活动;而厌倦、困惑、厌恶等消极负向情感则会影响学习者的专注程度、耐心指标,阻碍认知活动。综上所述,学习者在学习过程中的情感状态会对学习者的学习效率产生一定的影响。而现有的在线网络学习环境研究重“知”轻“情”,注重学习者认知层面的适应性和个性化,即根据学习者的认知能力和知识状态提供合适的学习内容、学习路径和问题解答等,而较少考虑情感、兴趣、动机、意志等非智力因素在学习活动中的作用,忽视智慧学习环境中和谐情感交互的理论和实践研究,以致其缺少情感层面的适应性和个性化,学习者在智慧学习过程中缺少情感支持。因此,在线视频学习环境中情感层面自适应交互的研究及实现成为急需解决的现实问题。该研究能够推动基于生物信息的情感识别在人机交互、教育、心理学以及认知科学中的发展,具有重要的科研价值及社会实践意义。
[0004]
在传统教学中,师生面对面直观的交流,教师满意的表情、称赞的话语、鼓励的手势可给学习者传递积极的情感,以影响学习者的学习兴趣和态度。智慧学习环境中师生由于时空上的准分离,将难以感受对方的情感和状态,普遍存在“情感缺失”的问题。如果能够精准的识别学习者的情感成为解决这一问题的关键。
[0005]
视觉系统是人们获取外部信息最重要的通道,能客观反映出人脑的信息加工机制。人的认知加工过程很大程度上依赖于视觉系统,约有80%~90%的外界信息是通过人眼获取的。然而,通过视觉信息对情感进行识别的研究并不多。因此,通过眼动行为信息探索眼动信息与表达的情感状态关系是一种较新颖的研究方式。眼动追踪(eye tracking)实验法是指利用眼动仪对人的眼球运动进行记录并分析人们在注视过程中的各项眼动指标,并以此揭示人们的心理加工过程和规律的一种研究方法。眼动追踪实验法能够通过追踪用户眼部特征数据,更为客观的预测用户的信息需求,为微观角度细致分析用户的心理和情感变化提供了可行的研究路径。与其它的研究方法相比,眼动追踪方法在记录的过程中更加自然、干扰较小,有其特殊的优越性。在教育领域,眼动数据的测量可以反映学习者的认
知过程、阅读理解机制和视觉加工过程,是学习状态的第一手资料。由于眼动的视觉信息与人的心理活动有着直接或间接的关系,因而眼动特征能真实的反映学习者当时的情感等心理状态。眼动追踪正在成为一种越来越流行的认知和情感信息处理的测量方法。
[0006]
因此,通过眼动信息快速精准的识别学习者的情感状态,当出现负向情感状态时,及时进行情感关怀,能够帮助学习者高效完成学习课程。如何设计一个能够精准识别学习者的情感状态的网络模型是当下需要解决的技术难题。
技术实现要素:
[0007]
本发明所要解决的技术问题:针对现有不足,本发明提出一种基于深度学习的眼动信号情感识别方法,所提出的方法包括:
[0008]
本发明的技术方案:
[0009]
s1、自建眼动数据库,以学习视频作为刺激材料,获取眼动数据。并对数据标注、预处理、数据集设置、数据类型转换、数据扩增和数据集划分等操作。
[0010]
s2、设计一个基于卷积神经网路的子卷积块;
[0011]
s3、将网络设计成一个具有五个大层的网络结构;
[0012]
s4、对训练过程可视化并通过评价指标对所提出的网络结构评价,以检测所提出的网络的优劣。
[0013]
进一步地,所述步骤s1具体包括以下步骤:
[0014]
自建实验数据集,使用学习视频作为刺激材料,诱发被试者在学习过程中的情感状态,采集过程中的眼动信息;
[0015]
采用离散型的情感标注模型对数据进行标注,将情感标注词分为正向和负向情感两种情感状态;
[0016]
对采集的眼动数据进行预处理,预处理包括:高质量数据筛选,去除异常值和缺省值;
[0017]
把数据集的时间窗口大小设置为5秒;
[0018]
将眼动信息中的瞳孔直径数字型数据转换为图像数据类型;
[0019]
对数据进行扩增,主要为反转和加噪处理;
[0020]
图像数据划分为训练集、验证集和测试集,划分比例为70%,10%,20%;
[0021]
进一步地,步骤s2构建基于卷积神经网络的子卷积块结构如下:
[0022]
将该卷积块设计为一个四路的并联结构;
[0023]
首层为1*1的卷积层,卷积计算过程为:
[0024][0025]
其中,l代表层数,mj代表第j个特征图,b代表偏置。
[0026]
后面并上一个上述的四路子网络结构,四路结构如下面步骤所示;
[0027]
第一路为一个3*3的最大池化层和一个3*3的卷积层,其池化操作可以通过kronecker 乘积来得到:
[0028][0029]
其中,l代表卷积层,up()代表池化操作。
[0030]
第二路为一个3*3的平均池化层和一个1*1的卷积层;
[0031]
第三路为一个3*3的卷积层;
[0032]
第四路为两个3*3的卷积层;
[0033]
将首层与第四路通过contcat运算进行融合;
[0034]
将四路子网络结构通过contcat运算进行融合,以获取高层和低层的特征信息;
[0035]
所有的卷积层后面都跟一个relu激活函数,该函数缓解梯度消失,也能在一定程度上解决梯度爆炸,从而加快训练速度;
[0036]
relu激活函数表达式如下所示:
[0037][0038]
将上述的四路子网路作为一个块,一个块后面跟一个最大池化层作为一个大层。
[0039]
进一步地,步骤s3将步骤s2构建的子卷积块后面加一个最大池化层成为一个完整的一个层,并通过堆叠这样的五个层,从而构建成一个完整的一个网络结构。
[0040]
进一步地,步骤s4将训练过程可视化,采用精度(accuracy)、精准率(precision)、召回率(recall)和f1分数(f1
‑
score)衡量所设计的网络结构性能效果。
[0041]
这个需要定义几个基本概念,n
tp
:分类器将正样本判断为正样本的个数,n
fp
:分类器将负样本判断为正样本的个数,n
tn
:分类器将负样本判断为负样本的个数,n
fn
:分类器将正样本判断为负样本的个数。
[0042]
精度是用来说明分类模型在总体测试样本上的识别率,一般来说,算法的性能也就越好。
[0043][0044]
精准率定义为正样本中分类正确的样本个数占所有被分类为正样本个数的比例,公式为:
[0045][0046]
召回率定义为正样本中分类正确的样本个数占所有实际分类为正样本个数的比例,它衡量分类将正样本分类正确的能力,公式为:
[0047][0048]
f1分数定义为准确率和召回率调和均值的两倍,f1分数综合考虑分类器的准确率和召回率能力,公式为:
[0049][0050]
使用上述评价指标对所设计的网络进行评价。
附图说明
[0051]
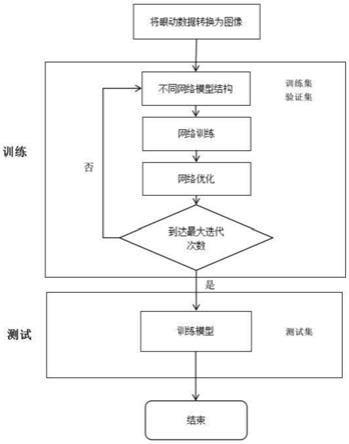
图1为本发明一一种基于深度学习的眼动信号情感识别方法的流程图。
[0052]
图2为本发明中子卷积块网络结构图。
[0053]
图3为本发明用于情感识别的网络结构图。
[0054]
图4为本发明训练损失与迭代次数间的变化关系。
[0055]
图5为本发明训练精度与迭代次数间的变化关系。
具体实施方式
[0056]
下面结合实例和附图对本发明做进一步的说明,但本发明的实施方式不限于此。
[0057]
本技术的发明思路是,输入的眼动瞳孔直径数据样本;然后对数据进行扩增,减小噪声;接着,使用fcnns网络对数据进行提取和分析眼动特征,最后输出情感类别,实现对情感状态的识别。
[0058]
如图1所示,本实施例提供一种基于深度学习的眼动信号情感识别方法流程图,包括以下步骤:
[0059]
s1、自建眼动数据库,以学习视频作为刺激材料,获取眼动数据。并对数据标注、预处理、数据集设置、数据类型转换、数据扩增和数据集划分等操作。
[0060]
更具体的,自行制备眼动数据集,采用学习视频a作为刺激材料,a视频主题为计算机历史,讲述了计算机的前期发展、计算机雏形等,视频时长11分21秒。整个眼动数据采集实验过程:在实验进行前,要求被试者进行知识问卷测试,测量被试者的先前知识,其内容与实验材料内容相关。然后对被试者进行眼部校准,以检查被试者是否作为合格被试者。在学习视频前需要观看注视点,即出现在屏幕正中的十字准星,时长为180s,加入注视点后可以获得眼动的数据的基线值。被试者在计算机屏幕上观看播放的教学视频,在视频播放结束后,被试会有短暂的休息并完成后测检验,再进行第二个视频的观看。整个试验结束后,由实验人员为被试者讲解标注模型,确保被试者完全理解上述模型后,让被试者观看回顾视频,包括教学视频及被试本人观看教学视频时的录像,由被试回顾当时产生的情感状态划分事件,并根据分类情感模型中的正向和负向情感词选择自己当时所处的情感状态,对两个视频进行标注。
[0061]
数据采集实验中的情感状态采用“暗示回顾”法和被试主观报告方式获取,即被试者观看学习视频后,回放学习视频及同步录制的被试者面部表情视频,刺激被试者回忆当时的情感状态,将同步视频分割成事件片段,并从情感分类模型中的情感词集中选择自己的情感状态,有正向情感状态和负向情感状态。正向的情感状态包括快乐、兴趣和流状态;负向的情感状态包括无聊、困惑、沮丧和走神。其中,“流状态”是指学习过程中学习者的能力与学习任务难度相匹配的情况下出现的一种情感状态,学习者对学习任务不会感到过于轻松也不会产生强烈的畏难情绪。
[0062]
数据预处理:去掉实验过程中视线跟踪丢失的被试的眼动数据,将获取的数据按不同步长划分数据。最后保留的眼动特征包括左右眼瞳孔直径,注视,眼跳,眨眼数据和眼动角速度。将所有被试数据加上情感属性标签
‘
label’,将量表所标注得的正向情感状态标为
‘1’
,标注负向情感状态标为
‘0’
。
[0063]
数据集设置:通过实验5秒、10秒和15秒的时间窗口的数据集对实验结果的影响,最终发现在时间窗口为5秒的数据集下,实验结果最好,因此我们将数据集时间窗口设置为5 秒。
[0064]
数据类型转换:由于深度学习网络对处理图像类型具有较高的优势度,因此我们将采集到的眼动信息中瞳孔直径数据转换为图像类型的数据,便于所设计的网络进行训练。
[0065]
数据集扩增和数据集划分:将时间窗口为5秒的数据集进行数据扩增,对图像数据进行反转和加噪操作,并将扩增好的数据集进行划分,将训练集、验证集和测试集按70%、10%和 20%进行划分。
[0066]
步骤s2,如图2所示,设计一个基于卷积神经网路的子卷积块;具体的,将该卷积块设计为一个四路的并联结构;首层为1*1的卷积层,后面并上一个上述的四路子网络结构,四路结构如下面步骤所示;第一路为一个3*3的最大池化层和一个3*3的卷积层;第二路为一个3*3的平均池化层和一个1*1的卷积层;第三路为一个3*3的卷积层;第四路为两个3*3 的卷积层;将首层与第四路通过contcat运算进行融合;将四路子网络结构通过contcat运算进行融合,以获取高层和低层的特征信息;所有的卷积层后面都跟一个relu激活函数,该函数缓解梯度消失,也能在一定程度上解决梯度爆炸,从而加快训练速度;将上述的四路子网作为一个卷积块块,一个块后面跟一个最大池化层,一个卷积块后面加一个最大池化层构成一个大层。
[0067]
s3、如图3所示,将大层进行堆叠,形成一个具有五个大层的fcnns网络结构,并用来训练模型。
[0068]
s4、更进一步地,对训练过程可视化并通过评价指标对所提出的网络结构评价,以检测所提出的网络的优劣。
[0069]
更进一步地,通过实验发现,我们所提出的fcnns网络在5秒的时间窗口大小的数据集下,得到最好的结果。因此,我们对所提出的fcnn网络进行了模型的有效性验证,可视化训练fcnn网络过程中。训练损失与迭代次数的变化关系曲线以及训练精度与迭代次数的变化关系曲线如下图4和图5所示。通过实验发现,训练损失随着迭代次数慢慢下降到一个较低的水平,并趋于稳定,训练精度随着迭代次数逐渐的上升,并趋于一个稳定的小区间。为了进一步验证算法的优越性,使用精度、准确率、召回率和f1分数对该网络结构综合分析。得到如下结果如表1所示。
[0070]
表1 fcnn网络在5秒数据集时间窗口下分类结果
[0071][0072]
在我们所提出的fcnns网络中可以得到91.62%的分类精度,通过各评价指标测评,我们所提出fcnns网络具有很好商用的价值。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
