1.本发明涉及数据存储技术领域,具体涉及一种基于节点评价函数的超融合系统数据本地化存储方法。
背景技术:
2.去中心化的分布式存储系统通常使用哈希算法或其衍生算法计算得到多个数据副本放置的数据节点,以此为基础的超融合系统上的数据分布具有显著的分散性和随机性,虚拟机的数据并不完全存储在虚拟机所在物理节点上。对超融合系统中的每个虚拟机实例,系统每个物理节点均存储其数据的一部分,当虚拟机读取自身数据时,需要频繁通过节点间网络从其他节点复制所需数据块到虚拟机所在物理节点,造成较大的网络带宽占用,同时也带来了巨大的读数据延迟,且这种情况随着系统物理节点数目增大而显著加重。中心化的分布式存储系统具有元数据服务节点和数据服务节点,因此能指定数据保存的数据服务节点,但在选择从节点时采用随机选择的方式,易造成数据失衡,且这种情况在系统物理节点数目较大时更严重。
技术实现要素:
3.(一)要解决的技术问题
4.本发明要解决的技术问题是:如何为超融合系统中的虚拟机提供一种数据就近存储且超融合系统节点间数据均衡分布的数据本地化存储系统及方法。
5.(二)技术方案
6.为了解决上述技术问题,本发明提供了一种基于节点评价函数的超融合系统数据本地化存储系统的设计方法,将该存储系统设计为包括元数据维护模块和节点选择模块;其中,
7.将所述元数据维护模块设计为用于基于节点选择模块的返回值,存储和维护超融合系统中物理节点的状态信息和数据块的元数据;
8.将所述节点选择模块设计为用于在系统创建多个数据副本时,基于物理节点的cpu、内存和数据分布情况计算其评价函数值,并根据物理节点的评价函数值选择多个副本放置的节点。
9.优选地,将所述元数据维护模块进一步设计为:
10.当收到写数据请求时,首先由元数据维护模块检查数据是否存在于分布式存储系统中,若满足条件则将写数据信息传递给节点选择模块,并根据节点选择模块的返回值更新数据块的元数据信息,数据块的元数据结构设计为包括以下字段:
11.blkid字段为超融合系统中虚拟机数据块的id,该字段用于系统索引数据块位置;replicas_num字段为多副本模式下当前数据块副本的序号,该字段与blkid字段结合能够全局唯一性地索引超融合系统中的数据块,该字段的取值为不大于副本复制因子数的正整数;datanode字段表示数据块副本所在的物理节点序号,取值为不大于超融合系统物理节
点数目的非负整数;blk_size字段表示该数据块的大小;ctime字段表示该数据块的创建时间;atime字段表示该数据块的最后一次访问时间,该值的大小应当不小于ctime字段值的大小;mtime字段表示该数据块的最后一次修改时间,该值的大小应当不小于ctime字段的值,且该值的大小应当不大于atime字段的值;local_addr字段表示数据块在所分配的物理节点中的地址。
12.优选地,在三副本模式下replicas_num字段取值为1,2或3,取值为1时,表明该数据块为主副本,取值为2时,表示该数据块副本为当前数据块的第二副本,取值为3时,表示该数据块副本为当前数据块的第三副本。
13.优选地,当datanode字段值为0时,表示分布式存储层尚未为该数据块分配存储的节点。
14.优选地,所述节点选择模块进一步设计为:
15.收到元数据维护模块传递的写数据信息后,节点选择模块计算各个物理节点的评价函数值,并据此选择评价函数值最低的节点作为数据块保存的节点,计算物理节点评价函数值涉及到的参数为:节点的cpu负载、节点的内存负载和节点的相对存储使用率;其中,节点的cpu负载用节点cpu占用率p
cpu
来度量,取值范围为[0,1],此参数值越高,表明当前时段节点中运行的进程越多,节点的cpu使用率越高,该节点计算负载越高;节点的内存负载用节点的内存使用率p
mem
表示,为节点中进程已使用的内存量与节点内存总容量的比值,取值范围为[0,1],此参数值越高,表明该节点的内存负载越高;节点的相对存储使用率μ为节点当前已用存储容量与系统所有节点已用存储容量的比值,取值为大于0的实数,用来度量节点存储使用率与系统所有节点平均存储使用率之间的差别,评价函数值v为这三个参数的线性组合,且每个参数的系数为正数,如下式:
[0016]
v=λ1×
p
cpu
λ2×
p
mem
λ3×
μ
[0017]
λ1、λ2、λ3为对应参数的系数;
[0018]
系统中保存数据块副本的物理节点分为主节点和从节点,其中主节点为虚拟机所在的物理节点,与之相对应地,虚拟机产生的保存在主节点上的数据块的副本为主副本,对于每一个数据块,其主节点且仅有一个;从节点为除主副本外的副本所在的物理节点,在三副本模式中,从节点有两个,分别为第二从节点和第三从节点,相应地,第二、三从节点上保存的数据块副本分别为第二、三从副本。
[0019]
本发明又提供了一种利用所述方法设计得到的数据本地化存储系统。
[0020]
本发明又提供了一种基于所述的系统实现的一种基于节点评价函数的超融合系统数据本地化存储方法。
[0021]
优选地,包括以下步骤:
[0022]
步骤1、创建并更新主副本元数据
[0023]
在收到超融合系统虚拟化层的写数据请求时,元数据维护模块首先检查该数据块是否已存在与集群中,若已存在,则拒绝写入;若不存在,则生成该数据块的blkid并为该数据块创建元数据并分配其在主节点保存的存储空间地址,同时初始化相关字段:
[0024]
blkid:赋值为生成的blkid;
[0025]
replicas_num;赋值为1,表明该数据块为主副本;
[0026]
datanode:赋值为写数据请求来源物理节点的序号;
[0027]
blk_size:赋值为该数据块大小;
[0028]
ctime:赋值为当前时间;
[0029]
atime:赋值为当前时间;
[0030]
mtime:赋值为当前时间;
[0031]
local_addr:赋值为在主副本节点中为该数据块分配的地址;
[0032]
创建主副本元数据完成后,由元数据服务节点通过心跳信息将主副本元数据发送给该数据块主节点上的分布式数据节点;
[0033]
步骤2、为数据块选择副本保存的从节点:
[0034]
元数据维护模块为数据块分配主节点后,节点选择模块开始为数据块分配从节点;
[0035]
节点选择模块从分布式存储元数据服务节点读取物理节点的cpu、内存以及存储空间使用情况,计算除该数据块主节点外的其他节点的综合评价函数值v,之后选择出其中综合评价函数值最小的两个数据服务节点分别作为该数据块的第二从节点和第三从节点,并将其返回给元数据维护模块;
[0036]
步骤3、创建从节点的元数据
[0037]
收到节点选择模块的返回值之后,元数据维护模块分别为数据块的第二、第三从副本创建元数据,其元数据各字段如下:
[0038]
blkid:赋值为该数据块的blkid,该数据块的副本具有相同的blkid);
[0039]
replicas_num;该数据块的第二、三从副本的该值分别赋值为2和3;
[0040]
datanode:分别赋值为该数据块第二、三从副本节点的序号;
[0041]
blk_size:赋值为该数据块大小;
[0042]
ctime:赋值为当前时间;
[0043]
atime:赋值为当前时间;
[0044]
mtime:赋值为当前时间;
[0045]
local_addr:分别赋值为在第二、三副本节点中为该数据块分配的地址;
[0046]
步骤4、元数据服务节点向写请求客户端返回数据服务节点信息
[0047]
选择出数据块的主副本节点、第二从副本节点和第三从副本节点后,由分布式存储元数据服务节点通过心跳信息将三个数据服务节点返回给写数据请求客户端。
[0048]
本发明又提供了一种所述的方法在数据存储技术领域中的应用。
[0049]
(三)有益效果
[0050]
为了在实现虚拟机数据的本地化读取的同时,避免节点数据分布失衡,本发明提出了一种基于节点评价函数的超融合系统数据本地化存储系统及方法。使用中心化的分布式存储系统作为其底层存储设备,采用本地物理节点和多个远端物理节点共同维护数据副本的方式,使系统中虚拟机实例的数据块在其所在物理节点保存一个主副本,并考虑节点间数据均衡分布,综合考虑物理节点的硬件性能和相对存储使用率选择另外两个远端物理节点保存第二、三数据副本,保证虚拟机数据的完全本地化存储,从而虚拟机读取数据时,能够直接从其所在物理节点读取所需数据,缩短虚拟机的读数据i/o路径,避免跨物理节点读取,降低虚拟机的读数据延迟。
附图说明
[0051]
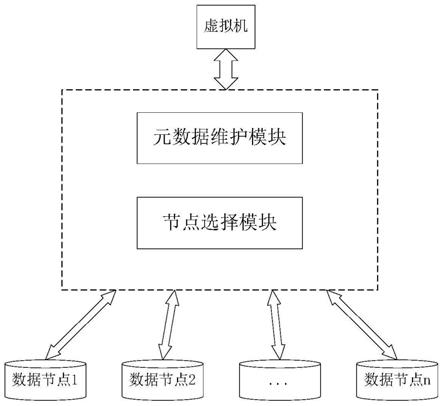
图1为本发明的超融合系统数据本地化存储系统设计框图;
[0052]
图2为本发明中的数据块的元数据结构设计原理图;
[0053]
图3为本发明中的节点选择模块的节点选择流程图。
具体实施方式
[0054]
为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
[0055]
本发明设计了一种基于节点评价函数的超融合系统数据本地化存储系统及方法。该设计旨在为超融合系统中的虚拟机提供一种数据就近存储且超融合系统节点间数据均衡分布的数据本地化存储系统及方法。该系统及方法应用于超融合系统底层分布式存储系统的元数据服务节点。
[0056]
如图1所示,该系统设计为包括元数据维护模块和节点选择模块;其中,所述元数据维护模块用于基于节点选择模块的返回值,存储和维护超融合系统中物理节点的状态信息和数据块的元数据;节点选择模块用于在系统创建多个数据副本时,综合考虑物理节点的cpu、内存和数据分布情况计算其评价函数值,并根据物理节点的评价函数值选择多个副本放置的节点,以保证虚拟机所在物理节点持有虚拟机数据,使虚拟机的读数据i/o均通过本地节点,避免跨网络读取数据的带宽占用和时间消耗。
[0057]
元数据维护模块设计:
[0058]
本发明中,元数据维护模块用于基于节点选择模块的返回值,存储和维护超融合系统中物理节点的状态信息和数据块的元数据。在超融合系统中,虚拟机数据镜像以块数据的形式存在于底层分布式存储中,当收到写数据请求时,首先由元数据维护模块检查数据是否存在于分布式存储系统中,若满足条件则将写数据信息传递给节点选择模块,并根据节点选择模块的返回值更新数据块的元数据信息。数据块的元数据结构设计如图2所示。
[0059]
其中,blkid字段为超融合系统中虚拟机数据块的id,该字段用于系统索引数据块位置;replicas_num字段为多副本模式下当前数据块副本的序号,该字段与blkid字段结合能够全局唯一性地索引超融合系统中的数据块,该字段的取值为不大于副本复制因子数的正整数,如三副本模式下取值为1,2或3,取值为1时,表明该数据块为主副本,取值为2时,表示该数据块副本为当前数据块的第二副本,取值为3时,表示该数据块副本为当前数据块的第三副本;datanode字段表示数据块副本所在的物理节点序号,取值为不大于超融合系统物理节点数目的非负整数,如0,1,2,3等,特别地,当该值为0时,表示分布式存储层尚未为该数据块分配存储的节点;blk_size字段表示该数据块的大小;ctime字段表示该数据块的创建时间;atime字段表示该数据块的最后一次访问时间,该值的大小应当不小于ctime字段值的大小;mtime字段表示该数据块的最后一次修改时间,该值的大小应当不小于ctime字段的值,且该值的大小应当不大于atime字段的值;local_addr字段表示数据块在所分配的物理节点中的地址。
[0060]
节点选择模块设计:
[0061]
本发明中,收到元数据维护模块传递的写数据信息后,节点选择模块会计算各个物理节点的评价函数值,并据此选择评价函数值最低的节点作为数据块保存的节点。计算
物理节点评价函数值涉及到的参数为:节点的cpu负载、节点的内存负载和节点的相对存储使用率;其中,节点的cpu负载用节点cpu占用率p
cpu
来度量,取值范围为[0,1],此参数值越高,表明当前时段节点中运行的进程越多,节点的cpu使用率越高,该节点计算负载越高;节点的内存负载用节点的内存使用率p
mem
表示,为节点中进程已使用的内存量与节点内存总容量的比值,取值范围为[0,1],此参数值越高,表明该节点的内存负载越高;节点的相对存储使用率μ为节点当前已用存储容量与系统所有节点已用存储容量的比值,取值为大于0的实数,用来度量节点存储使用率与系统所有节点平均存储使用率之间的差别。评价函数值v为这三个参数的线性组合,且每个参数的系数为正数,如下式:
[0062]
v=λ1×
p
cpu
λ2×
p
mem
λ3×
μ
[0063]
λ1、λ2、λ3为对应参数的系数;
[0064]
系统中保存数据块副本的物理节点分为主节点和从节点,其中主节点为虚拟机所在的物理节点,与之相对应地,虚拟机产生的保存在主节点上的数据块的副本为主副本,对于每一个数据块,其主节点且仅有一个;从节点为除主副本外的副本所在的物理节点,在三副本模式中,从节点有两个,分别为第二从节点和第三从节点,相应地,第二、三从节点上保存的数据块副本分别为第二、三从副本。
[0065]
节点选择的流程如图3所示。
[0066]
本发明使用自定义类为超融合系统分布式存储层元数据服务节点提供调用接口,以类调用的方式实现块数据副本放置节点的选择。
[0067]
基于上述系统实现的一种基于节点评价函数的超融合系统数据本地化存储方法包括以下步骤:
[0068]
步骤1、创建并更新主副本元数据
[0069]
在收到超融合系统虚拟化层的写数据请求时,元数据维护模块首先检查该数据块是否已存在与集群中,若已存在,则拒绝写入;若不存在,则生成该数据块的blkid并为该数据块创建元数据并分配其在主节点保存的存储空间地址,同时初始化相关字段:
[0070]
blkid:赋值为生成的blkid;
[0071]
replicas_num;赋值为1,表明该数据块为主副本;
[0072]
datanode:赋值为写数据请求来源物理节点的序号;
[0073]
blk_size:赋值为该数据块大小;
[0074]
ctime:赋值为当前时间;
[0075]
atime:赋值为当前时间;
[0076]
mtime:赋值为当前时间;
[0077]
local_addr:赋值为在主副本节点中为该数据块分配的地址。
[0078]
创建主副本元数据完成后,由元数据服务节点通过心跳信息将主副本元数据等信息发送给该数据块主节点上的分布式数据节点。
[0079]
步骤2、为数据块选择副本保存的从节点:
[0080]
元数据维护模块为数据块分配主节点后,节点选择模块开始为数据块分配从节点。
[0081]
节点选择模块从分布式存储元数据服务节点读取物理节点的cpu、内存以及存储空间使用情况,计算除该数据块主节点外的其他节点的综合评价函数值v,之后选择出其中
综合评价函数值最小的两个数据服务节点分别作为该数据块的第二从节点和第三从节点,并将其返回给元数据维护模块。
[0082]
步骤3、创建从节点的元数据
[0083]
收到节点选择模块的返回值之后,元数据维护模块分别为数据块的第二、第三从副本创建元数据,其元数据各字段如下:
[0084]
blkid:赋值为该数据块的blkid(该数据块的副本具有相同的blkid);
[0085]
replicas_num;该数据块的第二、三从副本的该值分别赋值为2和3;
[0086]
datanode:分别赋值为该数据块第二、三从副本节点的序号;
[0087]
blk_size:赋值为该数据块大小;
[0088]
ctime:赋值为当前时间;
[0089]
atime:赋值为当前时间;
[0090]
mtime:赋值为当前时间;
[0091]
local_addr:分别赋值为在第二、三副本节点中为该数据块分配的地址。
[0092]
步骤4、元数据服务节点向写请求客户端返回数据服务节点信息
[0093]
选择出数据块的主副本节点、第二从副本节点和第三从副本节点后,由分布式存储元数据服务节点通过心跳信息将上述三个数据服务节点返回给写数据请求客户端。
[0094]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
