自监督和有监督联合训练的ldct图像去噪与分类方法
技术领域
1.本发明属于医学影像分析技术领域,具体涉及一种ldct(低剂量ct)图像的去噪与分类方法。
背景技术:
2.基于计算机断层扫描(ct)的计算机辅助诊断技术引起了学术界和工业界的极大关注,例如,基于低剂量ct图像的肺结节分类,以及基于ct、mri等模态图像的器官/病灶分割等[1]。与正常剂量的ct(ndct)图像相比,低剂量ct(ldct)图像由于辐射剂量较低,从而对患者来说是相对安全的。然而,从ldct重建的图像会产生较多的噪声和伪影,这将不利于辅助临床诊断,即可能导致误诊和漏诊。以肺癌诊断为例,一些小的或磨玻璃状的结节很容易受到ldct图像中噪声的干扰,可能导致该类结节被忽略,从而造成不可挽回的损失。近年来,基于深度学习的监督去噪技术取得了令人瞩目的进展,但ndct图像在实际临床环境中通常很难获得,因此,在只有ldct图像的情况下,监督学习的框架无法用于ldct图像的去噪。因此,如何通过自监督学习的方法(不需要ndct图像)来更好地对ldct图像去噪,且同时能提升ldct图像的去噪性能是一个亟待解决的问题。
[0003]
为了解决这个问题,本发明将去噪和分类任务融合为同一个深度学习框架,其主要包括两个任务:1)自监督ldct图像去噪;2)对去噪后的图像分类。传统的图像去噪方法有k
‑
svd[2]、non
‑
local means[3]、以及bm3d[4]等。这些方法会导致去噪后的图像出现过度平滑、高频信息丢失等问题,而这些问题在基于ldct辅助诊断的过程中至关重要。在深度学习技术兴起后,基于卷积神经网络(cnn)的ldct去噪方法比传统方法显著提高了图像质量[5][6][7][8][9]。但这些方法需要ndct图像作为深度学习模型的监督信息,所以,难以直接应用于只有ldct图像的临床环境。因此,一些代表性的自监督去噪方法也相继被提出,如noise2noise[10]、noise2void[11]和noise2self[12]。这些自监督的去噪方法都是通过噪声图像本身来生成一个新的图像作为模型的监督信息,且实验表明,该类方法的去噪性能与有监督去噪方法相当。在对去噪后的图像进行分类的任务来说,基于cnn的分类网络的性能已经大大优于基于传统手工特征提取的方法[13][14][15][16]。
[0004]
不管是传统的还是深度学习的方法,去噪
‑
分类问题中的这两个任务通常都是分开解决的。文献[17][18]提出了一个统一的框架,将去噪和分类网络结合起来,训练的过程中固定了预训练的分类网络的参数,实验证明了分类任务的语义信息能够提高去噪性能。该联合训练策略的关键点是,需要感知损失来衡量噪声图像和干净图像之间的差异,若应用在低剂量ct图像去噪的任务中,就需要ldct和ndct来构建感知损失,因此,该方法不适用于ldct图像的诊断。
[0005]
与现有的去噪
‑
分类联合训练的方法不同的是,本发明将自监督的方法融入到联合训练中,没有ldct图像的监督信息。同时,本研究的目的在于通过有效的去噪性能来提升ldct的分类性能,且去噪网络与分类网络的参数是联合更新的。这样也提升了整个模型训练的效率
技术实现要素:
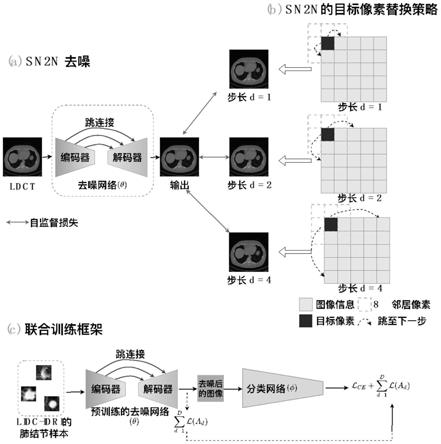
[0006]
本发明的目的在于提出一种自监督和有监督联合训练的ldct图像去噪和分类方法,以提高ldct图像的质量,同时提高其分类的准确率,将有利于ldct的临床辅助诊断。
[0007]
为了将自监督去噪与分类结合起来,本发明设计了一个集成这两个任务的联合训练框架。首先,提出了一种自监督去噪方法,称为noise2 neighbors(简记为n2n),用于ldct去噪,这里的“neighbors”(邻居)是指噪声像素周围的邻居像素。在具体的实现中,n2n通过将所有噪声像素替换为对其邻居的插值来生成自监督信息,即替换噪声像素后的图像。因此,该自监督信息不仅包含真实数据信号,还包含通过插值所产生的减弱的噪声。在noise2self(n2s)和noise2void(n2v)中[11][12],将目标噪声像素替换为一个随机选择的值,这样将失去一些局部图像结构的连续性,因此,本发明采用的插值方法将有效避免这一问题。此外,本发明进一步提出了一个基于步长的n2n(stridden n2n,sn2n),步长控制着自监督信息被插值的目标像素的位置。当步长大于1时,有部分像素并未被插值,这样可以保留一些原始像素中的高频信息。最后,结合分类任务,通过优化交叉熵(cross
‑
entropy,ce)损失[19]和提出的自监督损失来共同训练一个去噪
‑
分类的框架。本发明通过在真实数据集上的大量实验,在定性和定量的方面证明了去噪的优越性能,同时展示了在分类任务上的性能提升。
[0008]
本发明提供的基于自监督和有监督联合训练的低剂量ct图像去噪与分类方法,具体步骤如下:
[0009]
(1)低剂量ct图像存在大量的噪声,影响图像的质量,在没有ndct作为监督信息的情况下,本发明提出自监督图像去噪方法,用于ldct图像去噪。该方法首先通过替换目标噪声像素来构造一个监督信息,作为去噪网络模型的逼近目标;
[0010]
设为低剂量ct图像,大小为h
×
w,为一个噪声像素,其中i∈h,j∈w该像素在图像中的坐标,为了将降低其噪声,采用一个变换a,将的邻居像素信息融合来产生一个新的像素值,替换掉将变换后的像素作为y
i,j
,即该点的逼近目标,该过程描述如下:
[0011][0012]
其中,为噪声像素的变换后的结果,为噪声像素的邻居像素的集合,且从公式(1)可以看出,变换后的位置为在i,j处的值与无关,只与其邻居像素有关。若对整个ldct图像i
ld
做此变换,即a(i
ld
),则所有像素处的连续性将被保持。在本发明中,变换a采用双线性插值方法。
[0013]
(2)构建去噪网络要优化的目标函数;经过步骤(1),得到了去噪网络的逼近目标a(i
ld
),所以,去噪网络要优化的目标函数为均方误差(mean square error,mse),表示如下:
[0014][0015]
其中,f表示去噪网络模型,θ为该网络的参数。通过文献[12]可知,公式(2)遵循自监督去噪的原理,可以有效降低噪声。所以,基于cnn的网络模型可以使噪声像素逼近其邻居的插值,从而达到去噪的效果。本发明的自监督去噪损失函数为:
[0016][0017]
其中,n为训练样本的个数,为mse损失。
[0018]
(3)n2s[12]训练过程中,是按照迭代次数的索引来替换不同位置的像素,即去噪模型的参数更新只依赖于这些替换像素所产生的损失值,而其他未被替换的像素将导致模型的学习过程是一个恒等映射。为了解决这个问题,本发明进一步提出了基于步长的noise2neighbors(stridden n2n,sn2n),使得模型的更新利用到更多的像素信息且不会导致恒等映射。
[0019]
具体方法描述如下:
[0020]
如附图1(b)所示,sn2n根据不同的步长来选择要变换的像素,本发明选择的步长大小为d=1,2,4,即每隔d个像素就变换一个像素值。这样,每个步长d都会产生一个变换后的图像,这些图像将被用作自监督去噪中的监督信息。
[0021]
(a)当d=1时,ldct图像中的所有像素都将被替换,这将使得变换后的图像过于平滑,失去一些高频细节信息,不利于细小病灶的保留,影响诊断的准确率。
[0022]
(b)当d>1时,即不是所有的噪声像素都会被替换,则变换后的图像中将包含原始噪声信号和平滑后的噪声信,这使得模型能够学习到更多的高频信息。此外,随着d的增加,被替换的像素的分布越来越稀疏,并且当d的大小增加到图像的高度(h)或宽度(w)时,只有ldct图像的最边缘像素值被替换,这将导致模型学习到一个恒等映射,从而失去去噪的能力。
[0023]
通过对步长d的讨论,sn2n的损失函数可重写为:
[0024][0025]
其中,a
d
(
·
)表示在步长为d时的插值操作。
[0026]
(4)网络训练;文献[17][18]中的训练方法是将预训练好的分类网路模型的参数固定,将去噪的结果输入到分类网络中,分类网络在训练过程中不更新,且去噪网络需要干净图像的监督。本发明的训练方法与文献[17][18]不同,具体地,自监督去噪选择三种步长:d=1,2,4结合的方式,即损失函数为公式(4);联合训练去噪网络和分类网络,分别用公式(4)和交叉熵作为损失函数;为了同时训练这两个网络,则将二者的损失函数相加,通过梯度反向传播算法同时对两个网络的参数进行更新;在训练的损失中加入自监督去噪的损失可以有效保证ldct图像经过有效地去噪后,再作为分类网络的输入。
[0027]
具体训练方法如下:
[0028]
①
联合训练方法如附图1(c)所示,包含一个去噪网络(参数为θ)和一个分类网络(参数为);
[0029]
②
联合训练将去噪的损失函数和分类的交叉熵损失函数相加作为总的损失函数,表示如下:
[0030][0031]
其中y
n
为类别标签,p
n
为模型的预测值。两个网络通过梯度反向传播算法(back
‑
propagation,bp)同时进行参数更新;
[0032]
③
自监督去噪的损失可以有效保证在分类的过程中排除噪声的干扰,同时不丢掉
有用的细节信息。
[0033]
本发明中,去噪模型使用red
‑
cnn[20]作为主干网络,分类网络使用vgg
‑
16[22]作为骨干网络。
[0034]
本发明将低剂量ct图像的去噪问题建模为自监督学习的问题,即通过低剂量图像本身来产生监督信息,摆脱了用难以获得的正常剂量图像作为监督信息所产生的代价;该自监督信息是通过将低剂量图像中的目标像素值替换为其邻居像素插值的结果;选取目标像素的过程引入了按不同步长选取的机制,结合不同步长所产生的多个自监督信息,有效降低了低剂量ct图像中的噪声;对低剂量ct图像去噪后,将其输入到用于分类的神经网络进行的分类;在训练分类网络的过程中,加入自监督去噪的损失函数,使得去噪网络的输出不受分类损失函数的影响,因此,保证了分类网络的输入为去噪后的完整图像;这种自监督与有监督联合训练的方式,提高了低剂量ct图像分类的准确率;在没有或很难获得患者正常剂量ct图像的条件下,本发明可有效提高基于低剂量ct图像的去噪效果,同时可以提高临床诊断的效率与准确率。
附图说明
[0035]
图1为本发明的整体框架。
[0036]
图2为lidc
‑
idri数据集中肺结节样本的示例。
[0037]
图3为sn2n去噪方法在腹部图像上的去噪结果与其他方法的对比。
[0038]
图4为sn2n方法在肺部图像上的去噪结果与其他方法的对比。
[0039]
图5为sn2n方法与其他自监督去噪方法的训练过程曲线的对比。
具体实施方式
[0040]
介绍了本发明的算法原理和具体步骤之后,下面展示该发明在真实数据上的去噪效果和分类效果,以及与其他去噪和分类方法的对比,包括去噪的质量和量化指标。
[0041]
本发明使用mayo ldct数据来验证sn2n自监督去噪性能,用lidc
‑
idri数据集来验证联合训练方法对肺结节分类性能的提升。mayo ldct和lidc
‑
idri数据集的训练和测试数据分别裁剪为128
×
128和32
×
32
×
32的大小。为了高效训练去噪任务,我们使用red
‑
cnn[20]作为主干。对于分类任务,我们使用vgg
‑
16[22]作为骨干网络,vgg
‑
16的输入是32
×
32
×
32的3d肺结节数据,可将其看作是具有32个通道的,大小为32
×
32的2d切片,因此vgg
‑
16的输入通道数修改为32。我们将sn2n的步长设置为d=1,2,4,并且在实验中变换函数a(
·
)是一个双线性插值。
[0042]
所有实验的超参数设置如下:学习率为0.0001,每80个epoch衰减0.1,总epoch数为200;去噪训练和分类任务的小批量大小分别为64和16。优化器是adam,权重衰减为0.0001。所有的实验都是在pytorch框架下实现的,并使用一个nvidia gtx 2080 ti gpu进行训练,所有实验结果均通过5折交叉验证得到。
[0043]
实验中,采用峰值信噪比(psnr)和结构相似性(ssim)三个指标来度量去噪的实验效果,psnr的定义方式为:
[0044]
[0045]
ssim的定义方式为:
[0046][0047]
psnr代表了算法在去噪结果和正常剂量ct之间像素级别的匹配,ssim则代表了两者结构上的相似性。
[0048]
对于联合训练的分类实验采用准确率(accuracy)、精确率(precision)、召回率(recall)、f1分数(f1 score)来衡量:
[0049][0050][0051][0052][0053]
其中,tp,fp,tn,fn分别表示真阳性、假阳性、真阴性和假阴性。
[0054]
实验例1:自监督去噪的性能对比
[0055]
表1基于red
‑
cnn的不同去噪方法的量化性能指标对比
[0056]
方法psnrssim监督学习39.890.7032k
‑
svd30.290.7020n2n37.880.7032n2v35.540.7020n2s39.290.7025sn2n39.860.7032
[0057]
表1中黑色粗体表示最优结果,从表1可以看出,监督学习仍然取得了最高的psnr和ssim,本发明的方法sn2n在psnr指标上稍微低于监督学习方法,且ssim指标与监督学习相当,即sn2n在像素级的匹配和结构保持两个方面,均优于现有的其他自监督去噪方法,同时与监督学习方法的性能非常接近。k
‑
svd比其他去噪方法弱,并且它在去噪的图像中带来了一些伪影(附图3,附图4)。对于比较的自监督方法,即n2n、n2v和n2s,它们的不同性能取决于它们不同的像素选择和替换机制。n2v随机选择一个与目标像素及其邻居无关的值,这将导致不连续的局部结构,并丢失对去噪至关重要的图像原始信息。特别是对于每个像素都有噪声的ldct图像,原始像素包含噪声信息,在降噪任务中也不能完全忽略。对于n2s,它的实现通过在中心像素的邻居中随机选择一个值来替换中心像素。尽管n2s的性能优于n2v,但它仍然存在随机选择的像素可能与其相邻像素不连续的问题。因此,我们的sn2n可以根据以下两点有效地保持原始像素信息和局部结构:1)sn2n没有替换去噪网络的输入,因此网络可以学习到ldct中所有原始信息;2)sn2n的自监督是通过用双线性插值替换像素来产生的,这保留了局部连续性,保证了去噪图像内的局部结构。因此,sn2n能够取得比监
督方法更好的结果。至于n2n,与n2v相比,它也实现了最佳的ssim值和相对较高的psnr。这是因为n2n也没有对输入图像进行任何修改,保留了原始信息。但是,它没有考虑相邻像素之间的关系。如附图5所示,sn2n和n2n的psnr曲线相对稳定,而n2v和n2s的曲线波动较大。
[0058]
对于定性结果,从附图3的子图(e)、(f)、(g)和(h)可以看出,n2n,n2v,以及n2s比sn2n产生过平滑的图像,这可能导致粗糙纹理或小病灶的一些信息丢失。从这些字图的局部放大图可以看到sn2n显示出比其他更详细的纹理,并且保持相对的平滑。在附图4中,肺区域的ldct比腹部区域包含更明显的粗糙信息。对于n2n、n2v和n2s的结果,它们表现出过度锐化的边缘和更多的不连续像素,即缺乏相邻像素的局部连续性。因此,sn2n在平滑度和粗糙度之间获得了更好的权衡,附图4放大的子图(h)可以看出其更接近监督学习的结果(d)。
[0059]
实验例2:基于联合训练的分类任务性能对比
[0060]
表2不同自监督去噪方法驱动的肺结节分类结果对比
[0061][0062]
本实验旨在验证联合训练框架可以帮助改进lidc
‑
idri数据集上的ldct肺结节分类。由于lidc
‑
idri数据集没有相应的ndct图像作为去噪目标,因此通过从ce损失和相应的自监督损失之和来对去噪
‑
分类网络进行联合训练。实验比较了仅从ce损失反向传播的联合训练方法,即去噪网络和分类网络的参数不受自监督去噪损失的影响。肺结节的输入数据大小为32
×
32
×
32的3d数据,因此在去噪的过程中,将32个2d切片通过串行的方式来逐个去噪,再拼接为32
×
32
×
32的3d数据,将该去噪后的数据输入分类网络。在表2中,与使用任一自监督损失的训练相比,仅使用ce损失的联合训练的准确度最低。另外,ce n2v的表现弱于ce n2s,这是因为输入图像缺乏原始像素信息导致的。更重要的是,这种局部和结构连续性较差的输入也会影响分类性能。另一方面,ce n2s在一定程度上缓解了这个缺点,同时获得了比ce n2v更好的精度。对于ce n2n,去噪和分类网络的前向传播都不会丢失原始信息。因此,n2n降噪器的输出可以保持连续的结构,有利于分类。ce sn2n实现了所有类别的最佳准确度和f1分数。
[0063]
实验例3:联合训练在迁移学习中的性能表现
[0064]
表3利用不同预训练去噪网络的肺结节分类结果
international joint conference artificial intelligence(ijcai)pp.842
‑
848(2017)
[0087]
[18]liu,d.,et al.:connecting image denoising and high
‑
level vision tasks via deep learning.ieee transactions on image processing 29,3695
‑
3706(2020)
[0088]
[19]janocha,k.,czarnecki,w.m.:on loss functions for deep neural networks in classification.schedaeinformaticae 25,49
‑
59(2017)
[0089]
[20]chen,h.,et a1.:low
‑
dose ct with a residual encoder
‑
decoder convolutional neural network.ieee transactions on medical imaging 36(12),2524
‑
2535(2017)
[0090]
[21]liu,d.,et al.:connecting image denoising and high
‑
level vision tasks via deep learning.ieee transactions on image processing 29,3695
‑
3706(2020)
[0091]
[22]simonyan,k.,zisserman,a.:very deep convolutional networks for large
‑
scale image recognition.in:international conference on learning representations(iclr)(2015)
[0092]
[23]wilcoxon,f.:individual comparisons by ranking methods.in:breakthroughs in statis
‑
tics,pp.196
‑
202.springer(1992)。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
