为文档的来源观点生成并提供附加内容
背景技术:
1.用户可能对阅读文档有兴趣,但对文档的来源(例如,作者、创建者和/或发布者)几乎不知道或一无所知。例如,用户可以阅读新闻文章,而不知道文章的作者、作者的背景和/或文档的预定受众。在一些实例中,文档包括不一定基于客观推理而替代地基于特定于来源的经历和/或主观意见的信息。文档的内容中包括的来源观点的一些实例可以是由用户在没有附加信息的情况下可识别的。然而,一些内容可以具有无法由读者容易地可辨识为包括来源观点的实例。此外,文档的内容是否被认为包括来源观点能够是由用户进行的主观确定,并且结果,能够从用户到用户变化。例如,一个用户能够认为某个内容包括来源观点,然而另一用户可以不认为某个内容包括来源观点。
2.在一些实例中,文档的来源可以是另外的文档的来源,来源可以是其他文档的主提,并且/或者相关来源的经历的另外的信息可以是可用的。用户能够试图人工地识别这些另外的文档和/或信息。然而,用户能够需要相当多的计算和网络资源来搜索并识别与来源相关的相关的附加信息,以便决定来源的任何陈述是否指示来源观点。例如,用户可能不得不切换到他们的计算设备上的另一应用,使用另一应用来发出对关于来源的另外的信息的一个或多个搜索,并且审查这种信息。这能够消耗计算设备的资源(例如,切换到另一应用并审查信息)和网络资源(例如,在发出搜索并检索信息时)两者。进一步地,当查看文档的多个用户均执行对来源信息的类似的搜索和审查时,资源的这种消耗被加剧。更进一步地,当确定来源的(多个)陈述是否指示来源观点时,不同的用户能够识别不同的另外的信息。这能够是由于不同的用户执行不同的搜索、选择不同的搜索结果、查看所选择的(多个)搜索结果文档的不同的部分等而导致的。作为不同的另外的信息的结果,不同的用户能够关于陈述是否确实指示来源观点得出不同的结论。
技术实现要素:
3.本文中描述的实施方式为给定文档确定给定文档的内容(例如,句子、短语、段落等)的可能受到与内容的(多个)部分相关联的给定来源的来源观点影响的一个或多个部分。此外,那些实施方式确定与给定来源相关(例如,也来自给定来源和/或描述给定来源)并且与给定文档的内容的(多个)部分相关的一个或多个附加文档。更进一步地,那些实施方式中的一些利用(多个)附加文档来确定为给定文档的内容的可能受到给定来源的来源观点影响的部分提供上下文的附加内容。附加内容与给定文档的部分之间的关系能够被定义。基于关系被定义,附加内容能够被使得在客户端设备处响应于该客户端设备访问给定文档而被渲染。例如,给定文档的渲染能够被修改以结合到附加内容,附加内容能够被呈现在弹出窗口中,或者附加内容的可选择的指示能够被提供,并且在被选择的情况下,能够使附加内容被呈现。如本文中所述,确定内容的一部分是来源观点部分能够是客观确定。进一步地,确定(多个)附加文档和/或基于(多个)附加文档确定附加内容同样地能够是客观确定。因此,实施方式呈现用于确定文档的(多个)部分是否包括来源观点和/或用于确定与包括来源观点的内容的来源相关的(多个)附加文档和/或附加内容的统一(例如,独立于用户
的分析)处理。
4.作为一个示例,用户能够访问与文档的作者的旅行经历相关的文档。该文档可能包括短语“泰国是亚洲最好的国家”(“thailand is the best country in asia”)。基于短语的一个或多个词语(例如,“最好”(“best”)是暗示意见的词语),短语能够被识别为可以包括作者的来源观点的短语。与作者相关联的附加文档能够包括由作者编写的其他文章、作者的公开可用的传记信息和/或详述作者的经历的其他文档。附加文档和潜在来源观点短语作为输入能够被提供给训练后的机器学习模型,以生成短语与每个附加文档之间的相关性分数。例如,文档中的一个能够包括与作者已经旅游过的其他国家相关的信息。基于生成的附加文档与识别的短语之间的相关性分数指示附加文档的内容和短语的关联性,附加内容能够基于附加文档被确定。例如,附加内容能够包括到附加文档的链接、附加文档的概要和/或从附加文档中识别的相关作者的其他信息。例如,附加内容能够包括与短语“泰国是亚洲最好的国家”相关联的弹出框,其中弹出框指示泰国是作者已经旅游过的亚洲唯一国家,如从相关附加文件中识别的那样。
5.如本文中所用,“文档”将被广义地解释并且能够包括例如文章、新闻项目、博客条目、社交媒体发布、网页、电子邮件、图像、音频剪辑、视频剪辑、引述、广告、新闻组发布、字处理文档、便携式文档格式文档和/或其他文档。进一步地,本文中描述的实施方式能够被应用于文档的全部或部分。文档的一部分能够包括例如句子、短语、标题、脚注、广告、图像、引述、音频剪辑、视频剪辑、文档的元数据和/或其他部分。如本文中所述,文档能够被存储在一个或多个语料库中,并且一个或多个文档、其(多个)来源和/或其他实体之间的关系能够被定义在知识图中。
6.如本文中所用,“来源观点”将被广义地解释并且能够包括例如特定观点、基本或在先立场、倾向、经历、偏向、趋向、偏好、特定假设、意见和/或将内容的表示从纯粹客观观点向主观观点更改的其他观点。进一步地,来源观点能够通过附加文档的明确内容(例如,附加文档的(多个)部分)和/或附加文档的不明确内容(例如,基于附加文档的(多个)部分而推断)而被解释。
7.上述是作为本文中公开的一些实施方式的概述而被提供的。在下面提供这些和其他实施方式的进一步描述。
8.在一些实施方式中,提供了一种由一个或多个处理器执行的方法,并且该方法包括:识别目标电子文档和生成了该目标电子文档的来源。该方法还包括:处理目标电子文档以确定目标电子文档的来源观点部分;以及搜索一个或多个语料库以识别与来源相关的多个附加资源。该方法进一步包括,对于识别的与来源相关的附加资源中的每一个:处理附加资源中的对应的一个的对应的附加资源特征和来源观点部分的特征以生成对应的相关性分数。对应的相关性分数指示来源观点部分与附加资源中的对应的一个之间的相关性程度。在各个实施方式中,(多个)来源观点部分与附加电子文档中的对应的一个之间的相关性分数指示它提供用于理解(多个)来源观点部分的(多个)来源观点的基础而不是仅提供关于(多个)来源观点部分的(多个)基础专题的更多细节的意义上的相关性。因此,相关性分数能够表示附加电子文档中的每一个对于目标电子文档的(多个)来源观点部分的解释程度。例如,对于“泰国很棒”(“thailand is great”)的来源观点部分,描述来源如何由与泰国相关联的旅游委员会资助的第一附加资源与提供关于泰国的事实信息的第二附加资
源比能够具有较高的相关性程度。能够在确定此类相关性分数时利用各种技术,诸如本文中公开的基于机器学习的技术和/或基于知识图的技术。该方法进一步包括,响应于确定附加资源中的给定附加资源的相关性分数满足阈值:在一个或多个数据库中定义目标电子文档与基于给定附加资源而生成的附加内容之间的关系。该方法进一步包括,在定义关系之后,并且响应于关系被定义:使正在渲染目标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染附加内容的至少一部分和/或到附加内容的链接。
9.本文中公开的技术的这些和其他实施方式能够可选地包括以下特征中的一个或多个。
10.在一些实施方式中,定义目标电子文档与基于给定附加资源而生成的附加内容之间的关系包括定义目标电子文档的来源观点部分与附加内容之间的关系。在那些实施方式中的一些中,使正在渲染目标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染附加内容的至少一部分包括:使计算设备连同渲染附加内容的至少一部分与来源观点部分相关的指示一起渲染附加内容的至少一部分。在那些实施方式的一些版本中,对于目标电子文档,附加内容的至少一部分被定义为具有与仅来源观点部分的关系。在那些版本中的一些中,附加内容的至少一部分与来源观点部分相关的指示是附加内容与仅来源观点部分相关的指示。
11.在一些实施方式中,使正在渲染目标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染附加内容的至少一部分包括:使计算设备最初渲染指示与来源观点相关的附加内容是可用的可选择的界面元素,而不最初渲染附加内容的至少一部分;以及使计算设备响应于针对可选择的界面元素的肯定用户界面输入而渲染附加内容的至少一部分。
12.在一些实施方式中,该方法进一步包括基于给定附加资源生成附加内容。在那些实施方式中的一些中,生成附加内容包括:在附加内容中包括到给定附加资源的链接,在附加内容中包括来自给定附加资源的短语,并且/或者在附加内容中包括给定附加资源的概要。
13.在一些实施方式中,该方法进一步包括基于给定附加资源并且基于附加资源中的进一步的附加资源生成附加内容。基于进一步的附加资源生成附加内容能够响应于进一步的附加资源的对应的相关性分数满足阈值。
14.在一些实施方式中,处理附加资源中的对应的一个的对应的附加资源特征和来源观点部分的特征以生成对应的相关性分数包括:将对应的附加资源特征和来源观点部分的特征作为输入应用于训练后的机器学习模型;以及基于使用训练后的机器学习模型来处理对应的附加资源特征和来源观点部分的特征而生成对应的相关性分数。
15.在一些实施方式中,与来源相关的附加资源包括:由来源编写的其他文档;包括对来源的引用的文档;和/或知识图中被映射到知识图的与来源相对应的一个或多个条目;和/或包括对目标电子文档中的一个或多个词语的引用的文档。
16.在一些实施式中,该方法进一步包括:处理目标电子文档以确定目标电子文档的附加来源观点部分;以及生成指示附加来源观点部分与给定附加资源之间的相关性程度的附加相关性分数。生成附加相关性分数基于对应的附加资源特征和附加来源观点部分的附加特征的处理。在那些实施方式中的一些中,该方法进一步包括确定附加相关性分数未能
满足阈值,并且定义目标电子文档与基于给定附加资源而生成的附加内容之间的关系包括:基于相关性分数满足阈值来定义目标电子文档的来源观点部分与附加内容之间的关系;以及基于附加相关性分数未能满足阈值,避免定义目标电子文档的附加来源观点部分与附加内容之间的任何关系。
17.在一些实施方式中,使正在渲染目标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染附加内容的至少一部分包括:使计算设备连同渲染附加内容与来源观点部分相关的指示一起渲染附加内容的至少一部分。
18.在一些实施方式中,来源是作者、创建者和/或发布者。
19.在一些实现方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包括:识别目标电子文档和生成了该目标电子文档的来源;处理目标电子文档以确定目标电子文档的来源观点部分;搜索一个或多个语料库以识别与来源相关的多个附加资源;确定附加资源中的每一个与目标电子文档的来源观点部分之间的相关性分数;以及为目标电子文档的来源观点部分生成来源观点概要。来源观点概要是基于附加资源中的一个或多个以及对应的一个或多个附加资源的相关性分数而被生成的。该方法进一步包括响应于来自计算设备的对目标电子文档的请求:使计算设备渲染包括具有可选择的部分的目标电子文档的界面,该可选部分当被选择时使来源观点概要连同目标电子文档一起被渲染。
20.本文中公开的技术的这些和其他实施方式能够可选地包括以下特征中的一个或多个。
21.在一些实施方式中,可选择的部分包括来源观点部分,并且进一步包括使来源观点部分与目标电子文档的非来源观点部分图形地划出界线。
22.在一些实施方式中,当用户选择目标电子文档的可选择的部分时,来源观点概要当被渲染时在单独的界面部分中被渲染。
23.在一些实施方式中,可选择的部分由来源观点部分构成。
24.在一些实施方式中,来源观点概要当被渲染时在界面的与目标电子文档单独的部分中被渲染,并且当被渲染时选择来源观点概要使一个或多个附加资源的至少一部分被渲染。
25.在一些实施方式中,来源观点概要是基于至少附加资源中的一个或多个中的第一附加资源和第二附加资源而生成的。
26.在一些实施方式中,提供了一种由一个或多个处理器实现的方法,该方法包括:识别目标电子文档;处理目标电子文档以确定目标电子文档的来源观点部分;识别目标电子文档的至少一个来源;以及基于识别目标电子文档的至少一个来源,搜索一个或多个语料库以识别作为目标电子文档的来源观点部分的解释的多个附加资源。该方法进一步包括,为作为目标电子文档的来源观点部分的解释的识别的附加资源中的每一个,处理附加资源中的对应的一个的对应的附加资源特征和来源观点部分的特征以生成对应的相关性分数。例如,对应的相关性分数能够表示附加资源中的对应的一个对目标电子文档的来源观点部分的解释程度。该方法进一步包括基于相关性分数并且从识别的附加资源中选择作为目标电子文档的来源观点部分的解释的至少第一附加资源和第二附加资源。该方法进一步包括基于该至少第一附加资源的第一内容和第二附加资源的第二内容,生成至少一个来源的来源观点概要。该方法进一步包括,在生成至少一个来源的来源观点概要之后,使正在渲染目
标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染至少一个来源的来源观点概要。
27.本文中公开的技术的这些和其他实施方式能够可选地包括以下特征中的一个或多个。
28.在一些实施方式中,至少一个来源包括写作目标电子文档的作者,并且来源观点概要包括作者观点概要。
29.在那些实施方式的一些版本中,至少基于至少第一附加资源的第一内容和第二附加资源的第二内容生成至少一个来源的偏向概要包括分析该至少第一附加资源的第一内容和第二附加资源的第二内容以确定作者对目标电子文档的来源观点部分的解释,并且将作者对目标电子文档的来源观点部分的解释包括在作者观点概要中。
30.在那些实施方式的一些另外的版本中,作者对目标电子文档的来源观点部分的解释包括目标电子文档的来源观点部分的自然语言解释或目标电子文档的来源观点部分的来源观点度量。在那些实施方式的更进一步的版本中,基于至少第一附加资源的第一内容和第二附加资源的第二内容生成至少一个来源的来源观点概要包括:基于目标电子文档的来源观点部分的自然语言解释生成作者观点概要的第一部分;基于目标电子文档的来源观点部分的来源观点度量生成作者观点概要的第二部分;以及将作者观点概要的第一部分和作者观点概要的第二部分两者包括在作者观点概要中。
31.在那些实施方式的一些进一步的版本中,作为目标电子文档的来源观点部分的解释的第一附加资源和第二附加资源包括由作者写作的其他文档、与作者相关联的社交媒体账户的社交媒体帖子、或与作者相关联的社交媒体账户的社交媒体交互。在那些实施方式的更进一步的版本中,基于至少第一附加资源的第一内容和第二附加资源的第二内容生成至少一个来源的偏向概要包括基于由作者写作的其他文档的附加内容生成作者观点概要的第一部分,以及基于社交媒体帖子和与作者相关联的社交媒体账户的社交媒体交互生成作者观点概要的第二部分。
32.在那些实施方式的一些版本中,基于至少第一附加资源的第一内容和第二附加资源的第二内容生成至少一个来源的来源观点概要包括将到作为目标电子文档的来源观点部分的解释的该至少第一附加资源和第二附加资源的链接的列表包括在作者观点概要中。
33.在那些实施方式的一些版本中,至少一个来源还包括核对了目标电子文档的创建者,并且来源观点概要还包括单独的创建者观点概要。在那些实施方式的一些另外的版本中,该方法还包括基于识别至少一个来源还包括目标电子文档的创建者,搜索一个或多个语料库以识别作为目标电子文档的来源观点部分的解释的多个进一步的附加资源。在那些实施方式的一些进一步的版本中,该方法进一步包括,为作为目标电子文档的偏向部分的解释的识别的进一步的附加资源中的每一个,处理进一步的附加资源中的对应的一个的对应的进一步的附加资源特征和偏向部分的特征以生成对应的附加相关性分数。例如,对应的相关性分数能够表示附加资源中的对应的一个对于目标电子文档的来源观点部分的解释程度。在那些实施方式的一些进一步的版本中,该方法进一步包括基于附加相关性分数并且从识别的另外的附加资源中选择作为目标电子文档的偏向部分的解释的至少第三附加资源和第四附加资源。在那些实施方式的一些进一步的版本中,该方法进一步包括基于至少第三附加资源的第三内容和第四附加资源的第四内容生成至少一个来源的创建者观
点概要。
34.在那些实施方式的更进一步的版本中,基于至少第三附加资源的第三内容和第四附加资源的第四内容生成至少一个来源的来源观点概要包括分析至少第三附加资源的第三内容和第四附加资源的第四内容以确定创建者对目标电子文档的来源观点部分的解释,以及将创建者对目标电子文档的来源观点部分的解释包括在创建者观点概要中。在那些实施方式的又更进一步的版本中,创建者对目标电子文档的来源观点部分的解释包括目标电子文档的来源观点部分的自然语言解释或目标电子文档的来源观点部分的来源观点度量。在那些实施方式的还更进一步的版本中,基于至少第三附加资源的第三内容和第四附加资源的第四内容生成至少一个来源的来源观点概要包括:基于目标电子文档的来源观点部分的自然语言解释生成创建者观点概要的第一部分;基于目标电子文档的来源观点部分的来源观点度量生成创建者观点概要的第二部分;并且将创建者观点概要的第一部分和创建者观点概要的第二部分两者包括在创建者观点概要中。
35.在一些实施方式中,搜索一个或多个语料库以识别解释了目标电子文档的来源观点部分的多个附加资源包括:对识别的多个附加资源应用一种或多种去重复技术以确定识别的多个附加资源的子集;基于识别的多个附加资源的子集的特征,生成目标电子文档的来源观点部分的来源观点度量;以及将目标电子文档的来源观点部分的来源观点度量包括在来源观点概要中。
36.在一些实施方式中,一个或多个语料库包括知识图,该知识图具有与至少一个来源相对应的来源节点,该至少一个来源连接到至少对应于多个附加资源的资源节点。在那些实施方式的一些版本中,处理附加资源中的对应的一个的对应的附加资源特征和来源观点部分的特征以为作为目标电子文档的来源观点部分的解释的识别的附加资源中的每一个生成对应的相关性分数包括将知识图作为跨图神经网络的输入来应用以生成与知识图的来源节点和资源节点相对应的嵌入节点,并且基于该嵌入节点中包括的信息生成相关性分数。
37.在一些实施方式中,提供了一种由一个或多个处理器实现的方法,并且该方法包括:识别目标电子文档;处理目标电子文档以确定目标电子文档的来源观点部分;识别发布了目标电子文档的发布者;以及基于识别发布了目标电子文档的发布者,搜索一个或多个语料库以识别解释了目标电子文档的来源观点部分并且也由发布者发布的多个附加资源。该方法进一步包括,为作为目标电子文档的来源观点部分的解释的识别的附加资源中的每一个,处理附加资源中的对应的一个的对应的附加资源特征和来源观点部分的特征以生成对应的相关性分数。例如,对应的相关性分数能够表示附加资源中的对应的一个对目标电子文档的来源观点部分的解释程度。该方法进一步包括:基于相关性分数并且从识别的附加资源中选择作为目标电子文档的来源观点部分的解释的识别的第一附加资源和第二附加资源;以及基于至少第一附加资源的第一内容和第二附加资源的第二内容,生成发布者观点概要。该方法进一步包括,在生成发布者观点概要之后,使正在渲染目标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染发布者观点概要。
38.本文中公开的技术的这些和其他实施方式能够可选地包括以下特征中的一个或多个。
39.在一些实施方式中,基于至少第一附加资源的第一内容和第二附加资源的第二内
容生成发布者观点概要包括:分析该至少第一附加资源的第一内容和第二附加资源的第二内容以确定发布者对目标电子文档的来源观点部分的解释;以及将作者对目标电子文档的来源观点部分的解释包括在发布者观点概要中。
40.在那些实施方式的一些版本中,发布者对目标电子文档的来源观点部分的解释包括目标电子文档的来源观点部分的自然语言解释或目标电子文档的来源观点部分的来源观点度量。
41.在那些实施方式的一些另外的版本中,基于至少第一附加资源的第一内容和第二附加资源的第二内容生成发布者观点概要包括:基于目标电子文档的来源观点部分的自然语言解释生成发布者观点概要的第一部分;基于目标电子文档的来源观点部分的来源观点度量生成发布者观点的第二部分;以及将发布者观点概要的第一部分和发布者观点概要的第二部分两者包括在发布者观点概要中。
42.在一些实施方式中,提供了一种系统,并且该系统包括:数据库;存储器,该存储器存储指令;以及一个或多个处理器,该一个或多个处理器执行存储在存储器中的指令,以使一个或多个处理器:识别目标电子文档,处理目标电子文档以确定目标电子文档的一个或多个来源观点部分,识别目标电子文档的至少一个来源,并且基于识别目标电子文档的至少一个来源,搜索一个或多个语料库以识别作为目标电子文档的来源观点部分中的一个或多个的解释的多个附加资源。指令进一步使一个或多个处理器为作为目标电子文档的来源观点部分中的解释的一个或多个的附加资源中的每一个,处理附加资源中的对应的一个的对应的附加资源特征和来源观点部分中的一个或多个的特征以生成对应的相关性分数。例如,对应的相关性分数能够表示附加资源中的对应的一个对于目标电子文档的来源观点部分的解释程度。指令进一步使一个或多个处理器基于相关性分数并且从识别的附加资源中选择作为目标电子文档的来源观点部分中的一个或多个的解释的至少第一附加资源和第二附加资源,并且基于该至少第一附加资源的第一内容和第二附加资源的第二内容,生成至少一个来源的来源观点概要。指令进一步使一个或多个处理器在生成至少一个来源的来源观点概要之后,并且响应于从消费目标电子文档的用户接收到要查看来源观点概要的指示,使正在渲染目标电子文档的计算设备连同在计算设备处渲染目标电子文档一起渲染至少一个来源的来源观点概要。
43.在一些实施方式中,提供了一种由一个或多个处理器实现的方法并且该方法包括:识别目标电子文档;处理目标电子文档以确定目标电子文档的来源观点部分;识别发布了目标电子文档的发布者文档;以及基于识别发布了目标电子文档的发布者,搜索一个或多个语料库以识别也由发布者发布的多个附加资源。该方法进一步包括,为识别的也由发布者发布的附加资源中的每一个,处理附加资源中的对应的一个的对应的附加资源特征和来源观点部分的特征以生成对应的相关性分数。例如,对应的相关性分数能够表示附加资源中的对应的一个对于目标电子文档的来源观点部分的解释程度。该方法进一步包括,基于相关性分数选择至少由发布者发布的第一附加资源和由发布者发布的第二附加资源。该方法进一步包括:响应于选择该至少第一附加资源和第二附加资源,基于来自第一附加资源的第一内容并且基于来自第二附加资源的第二内容生成发布者观点概要;以及在一个或多个数据库中定义目标电子文档与基于至少来自第一附加资源的第一内容并且基于来自第二附加资源的第二内容而生成的发布者观点概要之间的关系。该方法进一步包括,在定
义关系之后,并且响应于关系被定义,使正在渲染目标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染发布者观点概要。
44.本文中公开的技术的这些和其他实施方式能够可选地包括以下特征中的一个或多个。
45.在一些实施方式中,基于至少来自第一附加资源的第一内容和来自第二附加资源的第二内容生成发布者观点概要包括将第一内容和第二内容两者包括在发布者观点概要中。在那些实施方式的一些版本中,第一内容是第一文本并且第二内容是第二文本。在那些实施方式的一些另外的版本中,发布者观点概要包括结合到第一文本和第二文本的单个句子。在那些实施方式的一些版本中,使正在渲染目标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染发布者观点概要包括使计算设备连同渲染发布者观点概要与来源观点部分相关的指示一起渲染发布者观点概要。
46.在一些实施方式中,使正在渲染目标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染发布者观点概要包括:使计算设备最初渲染指示与来源观点相关的附加内容是可用的可选择的界面元素,而不最初渲染发布者观点概要;以及使计算设备响应于针对可选择的界面元素的肯定用户界面输入而渲染发布者观点概要。
47.在一些实施方式中,提供了一种由一个或多个处理器实现的方法并且该方法包括:识别目标电子文档;处理目标电子文档以确定目标电子文档的来源观点部分;识别创作了目标电子文档的作者;基于识别创作了目标电子文档的作者,搜索一个或多个语料库以识别也由作者创作的多个附加资源。该方法还包括,为识别的也由作者创作的附加资源中的每一个,处理附加资源中的对应的一个的对应的附加资源特征和来源观点部分的特征以生成对应的相关性分数。例如,对应的相关性分数能够表示附加资源中的对应的一个对于目标电子文档的来源观点部分的解释程度。该方法进一步包括基于相关性分数选择至少由作者创作的第一附加资源和由作者创作的第二附加资源。该方法进一步包括:响应于选择至少第一附加资源和第二附加资源,基于至少来自第一附加资源的第一内容和来自第二附加资源的第二内容生成作者观点概要;以及在一个或多个数据库中定义目标电子文档与基于来自第一附加资源的第一内容和基于来自第二附加资源的第二内容而生成的作者观点概要之间的关系。该方法进一步包括,在定义关系之后,并且响应于关系被定义,使正在渲染目标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染作者观点概要。
48.本文公开的技术的这些和其他实施方式能够任选地包括以下特征中的一个或多个。
49.在一些实施方式中,基于至少来自第一附加资源的第一内容和来自第二附加资源的第二内容生成作者观点概要包括将第一内容和第二内容两者包括在作者观点概要中。在那些实施方式的一些版本中,第一内容是第一文本并且第二内容是第二文本。在那些实施方式的一些进一步的版本中,作者观点概要包括结合到第一文本和第二文本的单个句子。
50.在那些实施方式的更进一步的版本中,生成作者观点概要进一步包括将到第一附加资源的第一链接和到第二附加资源的第二链接包括在作者观点概要中。第一链接和第二链接基于第一附加资源和第二附加资源在生成作者观点概要时被利用而被包括在作者观点概要中。
51.在那些实施方式的更进一步的版本中,使正在渲染目标电子文档的计算设备与在
计算设备处渲染目标电子文档同时地渲染作者观点概要包括使计算设备连同渲染作者观点概要与来源观点部分相关的指示一起渲染作者观点概要。
52.在那些实施方式的更进一步的版本中,使正在渲染目标电子文档的计算设备与在计算设备处渲染目标电子文档同时地渲染作者观点概要包括:使计算设备最初渲染指示与作者观点相关的附加内容是可用的可选择的界面元素,而不最初渲染作者观点概要;以及使计算设备响应于针对可选择的界面元素的肯定用户界面输入而渲染作者观点概要。
53.另外,一些实施方式包括一个或多个计算设备的一个或多个处理器(例如,(多个)中央处理单元(cpu(s))、(多个)图形处理单元(gpu(s))和/或(多个)张量处理单元(tpu(s)),其中一个或多个处理器可操作以执行存储在相关存储器中的指令,并且其中指令被配置为引起前述方法中的任一种的执行。一些实施方式还包括一个或多个非暂时性计算机可读存储介质,该非暂时性计算机可读存储介质存储可由一个或多个处理器执行以执行前述方法中的任一种的计算机指令。
54.应该理解,在本文中更详细地描述的上述概念和附加概念的所有组合都被设想为作为本文中公开的主题的一部分。例如,在本公开末尾处出现的要求保护的主题的所有组合都被设想为作为本文中公开的主题的一部分。
附图说明
55.图1是本文中公开的实施方式能够在其中被实现的示例环境的框图。
56.图2图示具有突出显示的偏向部分的目标电子文档。
57.图3图示包括与突出显示的附加内容相关联的偏向部分一起被渲染的目标电子文档的示例界面。
58.图4a图示连同目标电子文档一起渲染的另外的内容的示例。
59.图4b图示基于用户的肯定输入而渲染的另外的内容的示例。
60.图5图示用于渲染具有另外的内容和/或与目标电子文档的偏向部分相关联的偏向概要的电子文档的示例方法的流程图。
61.图6图示计算设备的示例架构。
62.图7a图示包括偏向概要的示例界面。
63.图7b图示包括偏向概要的另一示例界面。
具体实施方式
64.现在转向图1,本文中公开能够在其中被实现的技术的示例环境被图示。该示例环境包括客户端设备105和远程计算机110。尽管客户端设备105和远程计算机110在图1中均被图示为单个组件,但是应理解,一个或多个模块和/或任何一个的方面能够全部地或部分地由一个或多个其他设备实现。例如,在一些实施方式中第一模块组和/或方面由第一远程系统的一个或多个处理器实现,并且第二模块组和/或方面由与远程计算机110网络通信的一个或多个单独的远程服务器设备的一个或多个处理器实现。(多个)远程服务器系统能够是,例如,处理来自一个或多个客户端设备的请求以及来自附加设备的请求的高性能远程服务器设备的集群。
65.客户端设备105能够是移动电话计算设备、平板计算设备和/或用户的包括计算设
备的可穿戴装置(例如,用户的具有计算设备的手表、用户的具有计算设备的眼镜、虚拟或增强现实计算设备)。附加和/或替代的客户端设备能够被提供。进一步地,客户端设备105的一个或多个组件能够在单独的设备上被实现。例如,(多个)应用107能够在与客户端设备105通信的一个或多个替代的计算设备上被实现。客户端设备105的组件和远程计算机110的组件能够经由通信网络进行通信。通信网络能够包括例如广域网(wan)(例如,因特网)。进一步地,客户端设备105的组件能够经由通信网络与一个或多个其他组件进行通信。例如,通信网络能够包括局域网(lan)和/或蓝牙并且能够经由lan和/或蓝牙与一个或多个其他设备(例如,与用户的手持计算设备进行通信的自动助理设备)进行通信。
66.客户端设备105包括一个或多个应用107,其均能够被利用以向客户端设备的用户渲染内容。例如,用户能够利用(多个)应用107中的一个(例如,web浏览器应用或自动助理应用)以向搜索引擎提供搜索查询,并且搜索引擎能够提供响应于搜索查询的(多个)结果。用户能够查看由搜索引擎提供的结果,并且点击(或以其他方式选择)结果中的一个以使应用107渲染与搜索查询相对应的对应的文档和/或其他内容。用户能够经由客户端设备105的一个或多个输入设备与应用107交互,诸如键盘、鼠标和/或能够选择界面107的区域的其他输入设备、语音控件、触摸屏控件和/或允许用户提交输入并且选择要被渲染的内容的其他输入方法。
67.在一些实施方式中,客户端设备105和/或远程计算机110的一个或多个模块能够经由(多个)应用107中的一个来渲染文档。例如,用户能够通过提供搜索查询来与搜索引擎交互并且搜索引擎能够向用户提供能够被渲染给用户的一个或多个文档(或文档的可选择的指示)。用户然后能够经由应用107查看渲染后的内容,并且在一些实例中,能够与渲染后的内容交互以被提供有另外的内容(例如,选择文档中的链接、选择图形用户界面按钮)。作为另一示例,用户能够在(多个)应用107中的一个内直接导航到文档。
68.作为示例,用户能够经由(多个)应用107中的一个被提供响应于“关于去亚洲旅行的文章”(“articles about travel to asia”)的提交查询的搜索结果。用户能够选择搜索结果中的一个并且(多个)应用107中的一个能够渲染与所选择的链接相关联的文档。如本文中使用的,用户感兴趣的文档将被称为“目标电子文档”。这能够是如先前所描述的基于搜索查询被渲染的文档,和/或经由在客户端设备105上执行的一个或多个应用以其他方式被渲染的文档。
69.在许多实例中,目标电子文档与至少一个来源相关联。该至少一个来源能够包括文档的作者、文档的发布者和/或文档的创建者。文档的发布者能够是,例如,持有文档的网站和/或准备和/或发布文档的公司。例如,准备和/或发布新闻文章的新闻机构能够是新闻文章文档的发布者。文档的创建者能够是核对文档的内容但不一定是文档的内容的原始作者的一个或多个个人。文档的作者能够是写作了文档的文本内容和/或生成了目标电子文档的其他部分(例如,图像)的个人。例如,作为新闻故事的目标电子文档能够在文档的文本中指定来源,能够在与文档相关联的元数据中指定来源,和/或来源能够基于另一相关文档的内容被识别。因为作者是人类,创建者包括一个或多个人类,并且人类代表发布者行事,而且那些(多个)人类具有独特的经历和意见,所以目标电子文档的一个或多个部分可以包括基于那些意见和/或经历的来源观点。在一些实例中,读者可能不知道这些经历和/或意见,并且即使一个或多个部分实际上可能被来源的意见曲解,也可以接收文件的内容作为
客观内容。
70.为了确定目标电子文档的(多个)部分是否包括来源观点,用户可能不得不查看多个资源以确定来源观点,如果一个甚至存在。进一步地,用户可以浏览多个文档以确定来源观点并且可能没有找到与来源观点相关的另外的资源(并且进一步地,可能不知道何时停止搜索解释来源观点的内容)。因此,附加计算资源和时间可以被耗费,有时对用户确定是否存在来源观点无用(即,如果没有来源观点能够从附加资源被确定)。因此,通过在目标电子文档中向用户提供可以包括来源观点的部分的指示并且进一步向用户提供另外的资源以允许用户确定特定部分是否实际上包括来源观点,用户没有必要执行另外的搜索。进一步地,用户能够被提供目标电子文档内的另外的资源的概要,这减少用户导航离开目标电子文档以评估能够指示潜在来源观点的另外的资源的需要。此外,实施方式呈现用于确定文档的(多个)部分是否包括来源观点和/或用于确定与包括来源观点的部分相关的附加(多个)文档和/或附加内容的客观并且统一的处理。因此,能够独立于被呈现另外的内容的用户的主观考虑来确定文档的部分是否被认为包括为来源观点部分而被呈现的来源观点和/或附加内容。
71.来源观点识别引擎115确定目标电子文档的一个或多个部分是否包括来源观点内容,并且如果是这样的话,则将(多个)这种部分标记为包括来源观点。目标电子文档的来源观点部分是文档的这样的部分:其指示来源可能基于特定观点、基本或在先立场、倾向、经历、偏向、趋向、偏好、特定假设、意见和/或将内容的表示从纯粹客观观点向主观观点更改的其他观点而不基于客观事实而已经包括这种部分。如本文中所描述的,来源观点识别引擎115能够利用各种技术来确定目标电子文档的一部分包括来源观点。注意,在各个实施方式中,目标文档的一部分包括来源观点的确定不一定结论性地意味着该部分是来源观点。相反,这意味着来源观点识别引擎115利用诸如本文中公开的一种或多种客观技术已经确定了该部分的特征和/或基于该部分而确定的量度,指示该部分具有至少包括来源观点的阈值概率。
72.参考图2,目标电子文档的示例被提供。目标电子文档200包括可以包括来源观点的部分205和210。来源观点识别引擎115能够基于部分中包括的一个或多个词语、基于各部分与已经被注释成指示一部分包括来源观点的一个或多个文档之间的相似性和/或基于确定一部分包括来源观点的其他方法来确定部分205和210包括来源观点。
73.部分205包括来源观点识别引擎115能够识别为可能指示来源观点的词语的一个或多个词语。例如,部分205陈述“泰国是亚洲最好的旅游国家”(“thailand is the best country in asia to visit”)。在一些实施方式中,来源观点识别引擎115能够将诸如“最好”(“best”)的一个或多个词语识别为通常指示来源观点并且不完全基于客观事实的词语。因此,在那些实施方式中的一些中,来源观点识别引擎115能够至少部分地基于词语“最好”(“best”)的存在确定部分205包括来源观点。能够指示来源观点的其他词语是“我”(“i”)和/或“我认为”(“i think”)、其他最高级(“最棒”(“greatest”)、“最差”(“worst”)等),和/或指示文档的对应部分受到作者的意见、假设、偏向和/或其他主观准则影响的其他词语。
74.在一些实施方式中,来源观点识别引擎115能够附加地或可替代地基于目标电子文档的一部分与一个或多个注释的文档(例如,人类注释的文档)之间的比较来确定该部分
是来源观点部分。例如,一个或多个人类能够被提供许多文档,并且用户能够利用文档是否包括来源观点的指示、指示文档中的来源观点的级别的分数和/或能够被来源观点识别引擎115利用以确定一部分是否与包括(多个)来源观点部分的其他文档类似的其他注释来注释每个文档。例如,来源观点识别引擎115能够将陈述“著名的美食旅行专家anthony example已经多次去泰国旅行”(“famous food travel expert anthony example has traveled numerous times to thailand”)的部分210与其他注释的文档进行比较,并且基于部分210与被注释为包括(多个)来源观点部分的文档之间的相似性,确定部分210是来源观点部分。基于作者对anthony example是“著名的美食旅行专家”的声明,部分210能够被确定为来源观点部分。
75.在一些实施方式中,来源观点识别引擎115在确定文档的一部分是否包括来源观点时另外或可替代地利用训练后的机器学习模型。例如,能够基于均包括文本的一部分(和/或文本的部分的表示)的训练实例输入的训练实例以及指示文本的部分是否为来源观点部分的训练实例输出来训练该训练后的机器学习模型。作为一个特定示例,该训练后的机器学习模型能够是前馈神经网络并且训练实例输入能够均是文本的对应部分的嵌入(例如,word2vec嵌入),并且训练实例输出能够均是文本的对应部分是否为来源观点部分的人类标记的指示。例如,训练实例输出在文本的对应部分被视为“高度可能包括”来源观点及其解释的情况下能够是“1”,在文本的对应部分被视为“高度可能包括”来源观点但没有其解释的情况下为“0.75”,在文本的对应部分被视为“可能包括”来源观点或其解释的情况下为“0.5”,在文本的对应部分被视为“可能不包括”来源观点或其解释的情况下为“0.25”,而在文本的对应部分被视为“高度可能不包括”来源观点或其解释的情况下为“0”。作为另一示例,训练后的机器学习模型能够是在逐词语或逐符号基础上接受文本的各部分的循环神经网络,并且训练实例输入能够均是文本的对应部分,并且训练实例输出能够均是文本的对应部分是否是来源观点部分的人类标记的指示。在使用中,来源观点识别引擎115能够使用训练后的机器学习模型来处理文本的一部分,以生成指示该部分是否是来源观点部分的量度,并且基于该量度确定该部分是否实际上是来源观点部分。例如,如果该量度满足阈值(例如,大于0.5),则来源观点识别引擎115能够确定文本的对应部分包括来源观点。也能够基于由用户生成的训练实例来更新机器学习模型(例如,关于图7a和图7b所描述的)。
76.另外的资源引擎120搜索以识别与目标电子文档的至少一个来源相关的附加资源。在一些实施方式中,为了保存网络和/或计算资源,只有当目标电子文档的来源观点部分已经由来源观点识别引擎115识别时,附加资源引擎120才搜索以识别目标电子文档的附加资源。在一些实施方式中,附加资源引擎120能够识别与(多个)来源相关联的文档,诸如由目标文档的作者编写的文档、提及和/或引述作者的文档、由目标文档的发布者发布的文档、提及发布者的文档、由目标文档的创建者创建的文档和/或能够指示目标文档的(多个)来源的来源观点的其他文档。在一些实施方式中,附加资源引擎120能够利用包括来自目标电子文档的(多个)来源观点部分(或基于(多个)来源观点部分)的一个或多个词语的搜索查询来识别可能与(多个)来源观点部分相关的附加资源。这种搜索查询也能够包括目标电子文档的(多个)来源的名称,或者被约束于对通过一个或多个来源和/或与一个或多个来源相关的(多个)文档的搜索,以识别由来源生成(例如,创作、发布和/或创建)并且可能与文档的来源观点部分中的一个或多个相关的附加资源。例如,参考图2,附加资源引擎120能
够提交“作者jim smith”(“author jim smith”)的搜索查询以被提供与作者相关的文档。此外,例如,附加资源引擎120能够附加地或可替代地向搜索引擎提交具有“作者jim smith”的约束的“泰国”(“thailand”)的搜索查询以被提供与作者相关的文档,这些文档也与文档的主题相关。此外,例如,附加资源引擎120能够附加地或可替代地提交具有“作者jim smith”的限制的“泰国”的搜索查询以识别与部分205相关的(多个)文档,并且提交“anthony example泰国”的搜索查询以识别与部分210相关的文档。作为又一示例,如果目标电子文档200由假想新闻公司发布,则附加资源引擎120能够另外或可替代地提交具有“发布者:假想新闻公司”(“publisher:hypothetical news corporation”)的约束并且可选地具有“作者jim smith”的约束的搜索查询。如果两个约束被包括,则识别的附加资源将仅局限于由“jim smith”编写并且由“假想新闻公司”发布的资源。
77.如上面所提及的,在一些实施方式中,附加资源能够包括由与目标电子文档相同的作者编写、由与目标电子文档相同的发布者发布和/或由与目标电子文档相同的创建者创建的其他文档。例如,为由“jim smith”写作的目标电子文档寻求另外的资源的搜索查询能够包括“jim smith”或“jim smith”的约束识别符,或者搜索语料库能够被约束于由“jim smith”写作的文档。例如,附加资源引擎120能够搜索一个或多个数据库,诸如包括作者姓名和创作的文档的数据库,以识别由作者写作的文档。
78.在一些实施方式中,另外的资源能够包括一个或多个文档,这些文档又包括对目标电子文档的来源的引用。例如,一个或多个文档能够包括作者的传记和/或以其他方式引用作者(但不一定由作者写作)。为了识别关于来源的附加资源,寻找附加资源的搜索查询能够包括来源的名称,或者搜索语料库能够被约束于与来源具有限定关系(例如,在将文档映射到文档中引用的对应实体的数据库中)的文档。再次参考图2,部分205陈述“泰国是亚洲最好的旅游国家”。附加资源引擎120能够基于文档包括作者的传记将网站和/或其他文档识别为另外的资源,该传记指示“jim smith是专门从事泰国旅行的旅行代理人”,这能够由读者利用来评估目标电子文档中的语句是否为来源观点。
79.在一些实施方式中,附加资源引擎120能够识别一个或多个文档,这些文档包括对目标电子文档中包括的一个或多个词语的引用。例如,部分210包括对“anthony example”的引用并且作者可能正在将陈述建立在另一人的意见基础上和/或可能正在做出关于一个人和/或其他主体的反映他们自己的观点的语句。例如,语句“泰国是一个巨的大国家”(“thailand is a huge country”)可以是作者的意见。因此,与泰国的人口和/或面积相关的附加信息可以辅助读者确定该国家是否实际上“巨大”。为了识别另一作者和/或人的来源观点,附加资源引擎120能够搜索以识别能够指示作者相关另一主题的来源观点的附加资源。
80.在一些实施方式中,附加资源引擎120能够基于知识图中的条目识别一个或多个附加资源。例如,附加资源引擎120能够识别知识图中的来源的条目。进一步地,能够在知识图中(直接和/或间接)将来源的条目进一步映射到与已经由目标电子文档的来源生成的(多个)文档相关的一个或多个另外的条目。附加资源引擎120能够为一个或多个附加条目基于那些条目在知识图中被映射到来源的条目来识别文档。作为另一示例,能够在知识图中将来源的条目进一步映射到一个或多个附加条目,每个附加条目定义来源的对应的策展资源,并且能够利用对应的策展资源中的一个或多个作为附加资源。例如,作者的策展资源
能够包括指示作者被认为是专家的(多个)专题、作者关于其已经编写的(多个)专题的信息和/或其他信息。此外,例如,发布者的策展资源能够包括指示发布者被认为是专家的(多个)专题、发布者关于其已经发布的(多个)专题、发布者的证实偏向的信息和/或其他信息。这种来源的策展资源能够被利用作为附加资源。
81.对于识别的附加资源中的每一个,附加资源评分器125能够可选地确定一个或多个相关性分数,每个相关性分数指示附加资源(或附加资源的一部分)与电子文档之间的相关性。例如,对于给定的附加资源,附加资源评分器125能够确定给定资源与目标电子文档的第一来源观点部分之间的第一相关性分数、给定资源与目标电子文档的第二来源观点部分之间的第二相关性分数等。例如,附加资源评分器125能够基于第一来源观点部分与给定资源的一个或多个方面的比较来确定第一相关性分数,能够基于第二来源观点部分与给定资源的一个或多个方面(相同方面和/或替代的(多个)方面)的比较来确定第二相关性等。此外,如本文中所述,基于给定资源的多个相关性分数,给定资源能够被确定为与多个来源观点部分中的仅一些(例如,仅一个来源观点部分)相关(并且与其关联地存储)。
82.附加资源评分器125能够基于给定附加资源的特征与识别的目标电子文档的来源观点部分的比较来确定相关性分数。例如,附加资源引擎120能够识别提及“anthony example”的附加资源,并且附加资源评分器125能够确定与部分205和附加资源的相关性分数相比更加指示相关性的附加部分210和附加资源的相关性分数。这能够基于附加资源中的(多个)词语匹配(软和/或确切)附加部分210中的(多个)词语,但是无法匹配部分205中的(多个)词语(例如,部分205未提及“anthony example”,并且附加资源可能不包括与“泰国”相关的任何内容)。此外,例如,附加资源引擎120能够识别包括词语“泰国”的文档,并且附加资源评分器125能够确定与附加资源和附加部分210的相关性分数比更加指示相关性的附加资源和部分205的相关性分数(例如,附加资源可以包括被包括在部分205中的词语“泰国”和“亚洲”,但是缺少词语“anthony example”)。
83.在一些实施方式中,在确定目标电子文档的部分与附加资源之间的相关性分数时,附加资源评分器125能够使用训练后的机器学习模型来处理附加资源的特征和来源观点部分的特征,并且基于这种处理生成相关性分数。例如,能够处理给定部分的特征和附加资源的特征以生成给定部分与附加资源之间的相关性分数。在一些实施方式中,机器学习模型能够基于训练实例被训练,每个训练实例包括以下的训练实例输入:文本的来源观点部分(和/或文本的来源观点部分的表示),和来自对应的附加资源的内容(和/或内容的表示);以及训练实例输出,其指示来自对应的附加资源的内容是否为文本的来源观点部分提供附加上下文。作为一个特定示例,训练后的机器学习模型可以是前馈神经网络并且训练实例输入可以均是:文本的对应的来源观点部分的嵌入(例如,word2vec嵌入)以及来自对应的附加资源的对应内容的嵌入(例如,基于包括与来源观点部分共同的一个或多个词语而识别的文本的摘录的word2vec或其他嵌入)。训练实例输出能够是来自对应的附加资源的对应内容是否为文本的来源观点部分提供附加上下文的人类标记的指示。例如,训练实例输出在文本的对应部分被视为“来源观点的充分地解释”的情况下可以为“1”,在文本的对应部分被视为“来源观点的一定程度的解释”的情况下为“0.5”,并且在文本的对应部分被视为“与来源观点不相关”的情况下为“0”。因此,训练实例输出不仅能够基于附加资源是否与文本的对应的来源观点部分相关被加权,也能够基于附加资源解释目标电子文档的来
源观点部分的程度被加权。附加和/或替代机器学习模型能够被利用,诸如具有在确定两条内容是否类似时利用的架构但是使用“一条内容是否解释另一条内容中的来源观点”作为监督信号代替相似性。在使用中,附加资源评分器125能够使用训练后的机器学习模型处理(多个)来源观点部分(或其特征)和来自附加资源的内容(或其特征),以生成指示来自附加部分的内容是否解释来源观点部分中的来源观点的相关性分数,并且基于量度确定该部分是否包括实际的来源观点。
84.在各个实施方式中,(多个)来源观点部分与附加资源(例如,文档)中的对应的一个之间的相关性分数指示它提供用于理解(多个)来源观点部分的(多个)来源观点的基础而不是仅提供关于(多个)来源观点部分的(多个)基础专题的更多细节的意义上相关性。因此,相关性分数能够表示附加电子文档中的每一个(或其一部分)对于目标电子文档的(多个)来源观点部分的解释程度。例如,对于“泰国很棒”(“thailand is great”)的来源观点部分,描述来源如何由与泰国相关联的旅游委员会资助的第一附加资源与提供关于泰国的事实信息的第二附加资源比能够具有更高的相关性程度。各种技术能够在确定这种相关性分数时被利用,诸如本文中公开的基于机器学习的技术和/或基于知识图的技术。
85.如本文中所述,来源观点识别引擎115和附加资源评分器125都利用机器学习模型。在各个实施方式中,来源观点识别引擎115利用第一训练后的机器学习模型,并且附加资源评分器125利用不同的第二训练后的机器学习模型。来源观点识别引擎115能够使用训练后的机器学习模型来处理电子文档的文本的一部分,以生成指示(多个)文档的(多个)部分是否为来源观点部分的量度,并且基于该量度确定该(多个)部分是否实际上为来源观点部分。例如,来自由john smith创作的新闻文章的“蓝色大学篮球是最好的”(“university of blue basketball is the best”)的潜在来源观点部分的特征能够作为输入被应用于训练后的机器学习模型,并且基于机器学习模型的输出而生成的量度能够表明“蓝色大学篮球队是最好的”(“university of blue basketball team is the best”)的潜在来源观点部分是否实际上是作者john smith的来源观点。
86.在一些实施方式中,附加资源评分器125能够使用训练后的机器学习模型来处理目标电子文档的来源观点部分和附加文档的(多个)候选段,以为附加文档(或至少针对附加文档的(多个)候选段)生成相关性分数。在那些实施方式的一些版本中,相关性分数在它指示附加文档的(多个)候选段提供以用于理解(多个)来源观点部分的(多个)来源观点的程度的意义上指示目标电子文档的来源观点部分与附加文档之间的相关性。换句话说,在那些版本中它不是包括仅匹配或类似内容的意义上的相关性,而是解释相关性的意义上的相关性。对于由附加资源引擎120识别的多个附加文档中的每一个,附加资源评分器125能够处理与由来源观点识别引擎115识别的来源观点部分相对应的文本以及附加文档的(多个)部分,以为附加文档生成对应的相关性分数。因此,基于处理来源观点部分的(多个)特征和n个单独的附加文档中的对应的一个的特征,n个单独的相关性分数能够被生成,其中每个相关性分数是为n个单独的附加文档中的对应的一个而生成的。值得注意的是,提供(多个)来源观点的解释的附加文档能够包括与目标电子文档的(多个)来源观点部分的内容不相关的内容,并且该内容能够被(例如,全部)包括在为附加文档确定相关性分数时处理的内容中。
87.进一步地,附加资源引擎120能够搜索以识别与目标电子文档相关的附加资源。在
一些实施方式中,附加资源引擎120能够搜索包括(多个)电子文档的电子资源(例如,文档)的一个或多个语料库并且/或者能够访问知识图的与目标电子文档的(多个)来源相关联的节点。附加资源引擎120能够识别源自目标电子文档的(多个)来源(并且可选地将搜索限制到来源)的文档;解释目标电子文档的(多个)来源观点部分;并且/或者与目标电子文档的(多个)来源观点部分的内容相关。在那些实施方式的一些版本中,能够基于由附加资源引擎120识别的附加文档的部分生成候选段。附加资源评分器125能够将候选段中的每一个以及(多个)来源中的每一个的(多个)来源观点部分作为跨训练后的机器学习模型的输入来应用以生成相关性分数。
88.例如,假设由john smith创作的新闻文章包括“蓝色大学篮球队是全国最好的球队”(“the university of blue basketball team is the best team in the nation”)的一部分,并且该部分被来源观点识别引擎115识别为来源观点部分。进一步假设由john smith创作的100篇新闻文章、博客帖子和社交媒体帖子被附加资源引擎120识别。来自由john smith创作的新闻文章、博客帖子和社交媒体帖子的解释john smith关于来源观点部分“蓝色大学篮球队是全国最好的球队”的来源观点的各个候选段能够被生成并被处理以识别用于理解(多个)来源观点部分的(多个)来源观点的基础而不是仅提供关于(多个)来源观点部分的(多个)基础专题的更多细节。在该示例中,进一步假设这些新闻文章中的一篇包括“蓝色大学篮球队具有有史以来最好的招募班”(“the university of blue basketball team has the best recruiting class ever”)的候选段、这些博客帖子中的一个包括“蓝色大学篮球队击败全国第一名篮球队”(“the university of blue basketball team beat the#1basketball team in the nation”)的候选段、这些社交媒体帖子中的一个包括“由于我对蓝色大学的捐赠,我有场边座位”(“i have courtside seats because of my donation to university of blue”)的候选段以及座位的照片。能够使用训练后的机器学习模型来连同“蓝色大学篮球队是全国最好的球队”的来源观点部分一起处理(例如,迭代地或作为一个批次)来自这些文档中的每一个的候选段(或者能够基于这些部分(例如,基于社交媒体帖子的“john smith是蓝色大学的捐助者”(“john smith is a donor of university of blue”))生成候选段),以确定相关性分数。在一些实施方式中,相关性分数能够是(多个)附加文档中的对应的一个的。例如,能够为由john smith创作的100篇新闻文章、博客帖子和社交媒体帖子中的每一个确定相关性分数。在一些实施方式中,相关性分数能够是附加文档中的对应的一个的部分的。例如,能够为仅对应的附加文档的候选段确定相关性分数(例如,为仅来自新闻文章的“蓝色大学篮球队具有有史以来最好的招募班”的相关性分数),而不是总体上为对应的附加文档确定相关性分数。在那些实施方式的一些进一步的版本中,相关性分数能够是对应的附加文档的总相关性分数,其中总相关性分数基于为对应的附加文档中的候选段的相关性分数的组合。例如,如果由john smith创作的新闻文章包括“蓝色大学篮球队具有有史以来最好的招募班”和“蓝色大学篮球队今年不会输一场比赛”(“the university of blue basketball team will not lose a game this year”)的候选段,则为这些候选段中的每一个的相关性分数能够被确定并被组合以确定新闻文章的总相关性分数。因此,为“由于我对蓝色大学的捐赠,我有场边座位”的候选段(或基于社交媒体帖子而生成的“john smith是蓝色大学的捐助者”的候选段)的相关性分数可以指示它最好地解释了john smith的观点(例如,“蓝色大学篮
球队是全国最好的球队”),即使它与john smith的观点的专题不直接相关也如此,然而“蓝色大学篮球队击败全国第一名篮球队”的候选段的相关性分数可以不指示它为john smith的观点提供解释,即使它与john smith的观点的专题直接相关也如此。
89.作为另一示例,再次假设由john smith创作的新闻文章包括“蓝色大学篮球队是全国最好的球队”的一部分,并且该部分被来源观点识别引擎115识别为来源观点部分。进一步假设包括“john smith”、“蓝色大学”、“示例体育广播网络”(“example sports radio network”)、“篮球队”、“篮球排名”(“basketball rankings”)和“新闻文章”(“news article”)的节点的知识图被附加资源引擎120识别。在该示例中,“john smith”的节点能够通过“的校友”(“alumnus of”)和“的捐助者”(“donor of”)的边被连接到“蓝色大学”的节点,“john smith”的节点可以也能够通过“为
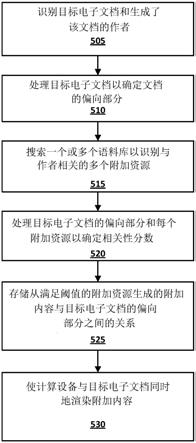
……
工作”(“works for”)的边被连接到“示例体育广播网络”的节点,“john smith”的节点也能够通过“由
……
创作”(“authored by”)的边被连接到“新闻文章”的节点,“蓝色大型”的节点能够通过“具有”的边被连接到“篮球队”的节点,“示例体育广播网络”的节点能够通过“关于
……
写作”(“writes about”)被连接到“蓝色大学”的节点,“蓝色大学”的节点和“篮球排名”的节点能够通过“#10”的边被连接,依此类推以定义来源(例如,john smith)、文档(例如,新闻文章)和/或其他实体(例如,蓝色大学、示例体育广播网络、篮球队等)之间的关系。来自知识图的解释john smith关于来源观点部分“蓝色大学篮球队是全国最好的球队”的来源观点的各个候选段能够被生成并被处理,以识别用于理解(多个)来源观点部分的(多个)来源观点的基础而不是仅提供关于(多个)来源观点部分的(多个)基础专题的更多细节。在该示例中,候选段能够从知识图生成,并且能够包括例如“john smith是蓝色大学的校友”(“john smith is an alumnus of university of blue”)、“约翰史密斯是蓝色大学的捐赠者”(“john smith is a donor of university of blue”)、“蓝色大学在篮球排名中排名第10”(“university of blue is #10 in basketball rankings”)等的候选段。“john smith是蓝色大学的校友”的候选段能够基于“john smith”的节点通过“的校友”的边连被接到“蓝色大学”的节点的连接被生成,“约翰史密斯是蓝色大学的捐赠者”的候选段能够基于“john smith”的节点通过“的捐赠者”的边被连接到“蓝色大学”的节点的连接被生成,依此类推。能够使用训练后的机器学习模型来连同“蓝色大学篮球队是全国最好的球队”的来源观点部分一起处理这些候选段中的每一个(例如,迭代地或作为一个批次),以为候选段和对应的附加资源中的每一个确定相关性分数。因此,“约翰史密斯是蓝色大学的捐赠者”的候选段的相关性分数可以指示它最好地解释了john smith的观点(例如,“蓝色大学篮球队是全国最好的球队”),即使它与john smith的观点的论题不直接相关也如此,然而“蓝色大学在篮球排名中排名第10”的候选段的相关性分数可以不指示它为john smith的观点提供解释,即使它与john smith的观点的论题直接相关也如此。
90.对于具有满足阈值的相关性分数的附加资源中的每一个,附加内容确定引擎135定义从那些附加资源中的每一个生成的附加内容与目标电子文档之间的关系。来自附加资源的附加内容与目标电子文档之间的关系能够被存储在数据库如数据库112中。例如,再次参考图2,来自文档的指示作者(即,“jim smith”)是专门从事泰国旅行的旅行代理人的附加内容能够按与目标电子文档和/或与来源观点部分205的关系而被存储。将该关系存储在数据库112中能够在由用户的计算设备对目标电子文档的后续检索之前发生,并且能够快
速且高效地检索附加内容以用于提供附加内容(以用于同目标电子文档一起渲染)。此外,将该关系存储在数据库112中使该关系能够被存储一次,但是被用于目标电子文档的许多后续检索。相比于,例如,如果关系未被存储并且附加内容未被渲染
‑
用于确定目标电子文档是否包括来源观点内容的人工搜索替代地发生,这能够保存有效资源。
91.在各个实施方式中,如果相关性分数满足阈值,则附加内容确定引擎135仅存储附加资源的附加内容与目标电子文档之间的关系。例如,附加资源评分器125能够确定来自附加资源的附加内容与目标电子文档之间的相关性分数,该相关性分数是二进制分数(例如,“1”表示相关而“0”表示不相关),并且如果相关性分数为“1”时存储关系。此外,例如,确定的相关性分数能够包括值的范围,其中较高的值指示附加内容与作为较低数字的相关性分数比更加指示相关性(例如,“0.9”指示与分数为“0.3”的附加内容比与目标电子文档更加相关的附加内容)。在这种示例中,如果相关性分数大于“0.6”或其他值,则附加资源评分器125能够存储关系。
92.在一些实施方式中,附加内容引擎135总体上定义附加内容与目标电子文档之间的关系。例如,附加内容引擎135能够将文档200与被附加资源引擎120识别的附加内容相关联。在一些实施方式中,附加内容确定引擎135能够在数据库112中定义目标电子文档的来源观点部分与附加内容之间的关系。例如,再次参考图2,内容确定引擎135能够定义部分205与来自第一附加资源的附加内容之间的关系。此外或可替代地,附加内容确定引擎135能够定义部分210与来自第二附加资源的附加内容之间的第二关系(或部分210与来自第一附加资源的附加内容之间的关系)。所定义的关系中的每一个能够被存储在数据库112中并稍后访问以利用目标电子设备渲染附加内容。
93.在一些实施方式中,附加内容能够是整个附加资源。例如,附加内容能够是整个资源,使得整个附加资源能够与目标电子文档一起被渲染,如本文中所述。在一些实施方式中,附加内容能够包括相关附加资源的一部分。例如,不是将整个附加资源与目标电子文档相关联,而是来自与目标电子文档相关的附加资源(或目标电子文档的来源观点部分)的短语之间的关系能够被存储在数据库中112。
94.在一些实施方式中,附加内容能够包括到附加资源的可选择部分,诸如链接。链接能够与例如附加资源的位置相关联。例如,链接能够与附加资源的web地址相关联,并且通过选择该链接,附加资源的至少一部分能够被渲染。可替代地或附加地,链接能够是对数据库条目、计算设备上的目录和/或允许用户访问特定附加资源的其他链接的引用。
95.在一些实施方式中,附加内容能够包括相关附加资源的概要。例如,附加资源的一个或多个短语和/或部分能够被利用以生成附加资源的内容的概要。在一些实施方式中,附加资源能够包括概要,其然后能够被识别为附加资源的附加内容。例如,附加资源能够是在文章开头处包括概要的文章。此外,例如,附加资源能够包括在文档末尾处的作者的传记(例如,在新闻故事末尾处的记者的短传记)和被用作概要的传记。
96.在一些实现方式中,附加内容能够从两个或更多个附加资源被生成。例如,第一附加资源和第二附加资源两者能够具有满足阈值的相关性分数。附加内容确定引擎135能够生成基于来自第一附加资源的第一内容和来自第二附加资源的第二内容的附加内容。例如,附加内容能够包括基于来自两个或更多个附加资源的内容而生成的来源观点概要。
97.作为示例,第一附加资源能够包括短语“jim smith是专门从事泰国旅行的旅行代
理人”(“jim smith is a travel agent specializing in trips to thailand”)。进一步地,第二附加资源能够是作者的传记并且包括短语“他去过泰国20多次”(“he has been to thailand over 20times”)。附加资源评分器125能够确定满足阈值的两个附加资源的相关性分数。来自第一附加资源的内容和来自第二附加资源的内容能够被利用以生成附加内容(例如,来源观点概要),该附加内容能够与数据库112中的目标电子文档和/或目标电子文档的来源观点部分相关联。
98.作为示例,再次参考图2,对于文档200的部分205,附加内容确定引擎135能够将满足阈值的所有附加资源(或附加资源的部分)识别为与部分205相关。进一步地,附加内容确定引擎135能够生成包括来自附加资源中的每一个的内容的概要,诸如指示因为已知“jim smith”游览的唯一外国国家是泰国所以他可能偏向于泰国的部分205的来源观点概要。进一步地,smith先生是专门从事预订泰国旅行的旅行代理人。得到的来源观点概要包括来自第一资源的内容(例如,作者仅去过泰国旅行)和来自第二资源的内容(例如,作者是专门从事泰国旅行的旅行代理人)。
99.附加内容渲染器130使用户的计算设备渲染与数据库112中的目标电子文档相关联的附加内容。附加内容与目标电子文档同时地被渲染,使得用户在查看目标电子文档时能够查看附加内容。
100.附加内容渲染器130使计算设备连同目标电子文档一起渲染由附加内容确定引擎135确定的对应的附加内容。例如,用户能够选择要查看的文档,并且该文档能够与附加内容相关联。附加内容渲染器130能够连同相关联的附加内容一起渲染选择的文档(即,目标电子文档),如本文中所述。
101.在一些实施方式中,附加内容能够与目标电子文档的特定来源观点部分相关并且附加内容渲染器130能够利用附加内容对目标电子文档的观特定来源点部分可用并且与目标电子文档的特定来源点部分相关的指示渲染目标电子文档。目标电子文档的来源观点部分能够被渲染为使得它与文档的其余部分是可区分的(例如,加下划线、粗体、大写、以不同颜色渲染),使得读者能够辨识附加内容对于文档的该部分可用。
102.在一些实施方式中,附加内容渲染器130能够渲染指示与来源观点相关的附加内容可用的可选择界面元素而不渲染附加内容。例如,参考图3,目标电子文档被提供附加内容可用而不渲染附加内容的指示。如图示,文档300包括以粗体字体突出显示以指示与来源观点部分305和/或与整个目标电子文档相的附加内容可用的第一来源观点部分305。文档300进一步包括也被突出显示以指示语句可以包括来源观点并且附加内容可用的第二来源观点部分310。在一些实施方式中,第一部分305能够与和第二部分310不同的附加内容相关联(即,每个来源观点部分与不同的附加资源相关联)。在一些实施方式中,目标电子文档的多个来源观点部分能够与相同的附加内容相关联。例如,附加内容能够与整个目标电子文档相关联(而不是关联到文档的特定来源观点部分)。因此,文档中的多个来源观点部分能够和与所有附加内容相关的相同的附加内容一起被渲染。在一些实施方式中,来源观点部分能够是可选择的并且附加内容可以在选择时渲染,如在本文中关于图4描述的。
103.在一些实施方式中,附加内容渲染器130能够渲染与基于识别的相关附加资源而生成的来源观点概要图形地相关联的目标电子文档。例如,如先前所述,多个附加资源能够与目标电子文档的来源观点部分相关并且能够基于附加资源的内容生成来源观点概要。附
加内容渲染器130能够与概要对于文档的来源观点部分可用的一个或多个图形指示一起渲染目标电子文档。
104.在一些实施方式中,目标电子文档能够包括一个或多个可选择部分,当被选择时,该一个或多个可选部分使相关联的附加资源中的一个或多个的至少一部分被渲染。例如,目标电子文档的来源观点部分能够与从文档a生成的附加内容相关联,并且文档a的一部分,诸如最相关部分,能够与目标电子文档一起被渲染。另外,目标电子文档能够包括附加内容中的链接以允许读者选择该链接并且被提供整个文档a或文档a的扩展部分。
105.作为另一示例,来源观点概要能够基于文档a和文档b的内容被生成。附加内容渲染器130能够与目标电子文档一起渲染来源观点概要或来源观点概要的一部分并且附加内容能够包括与到文档a和文档b的链接一起被渲染的来源观点概要。因此,用户能够选择链接中的一个并且被提供对应的文档和/或对应的文档的相关部分。
106.在一些实施方式中,来源观点概要或附加内容能够在界面的单独的部分中能够被渲染作为目标电子文档。例如,参考图4a,目标电子文档400由附加内容渲染器130在界面的第一部分中被渲染。附加内容界面405包括附加内容和/或从附加资源生成的来源观点概要的渲染的版本。在一些实施方式中,如图示,附加内容和/或来源观点概要能够被提供与内容和/或概要相关联的目标电子文档的来源观点部分的指示。例如,来源观点部分410与附加内容415对齐以通知读者附加内容415与来源观点部分410相关。如图示,来源观点部分410被进一步突出显示以指示语句可以包括来源观点,从而进一步通知读者附加内容与目标电子文档一起被包括。在一些实施方式中,附加和/或替代指示能够被利用以指示哪个来源观点部分与附加内容和/或来源观点概要相关联(例如,从附加内容延伸并指向来源观点部分的箭头和/或其他指示器、附加内容和来源观点部分的颜色编码)。
107.作为另一示例,来源观点概要420基于来源观点概要425与来源观点部分420的对齐与来源观点概要425相关联。来源观点概要425包括文本概要以及到被利用以生成来源观点概要430的文档的链接435的列表。因此,读者能够选择链接中的一个以被提供对应的文档和/或对应的文档的与来源观点部分420相关的一部分。
108.在一些实施方式中,来源观点概要和/或附加内容渲染可以在与目标电子文档单独的界面中被渲染。例如,参考图4b,与图4a所图示的相同的目标电子文档(即,文档400)被渲染而没有附加内容和/或来源观点概要与文档一起被渲染。如图示,光标445正悬停在来源观点部分410上方并弹出窗口440且在悬停在来源观点部分上方(或者选择其)时被渲染。弹出窗口提供与来源观点部分410相关联的附加内容。在一些实施方式中,来源观点概要能够以相同方式被渲染。例如,来源观点概要能够与概要一起被渲染或者与概要和附加可选择部分两者一起被渲染,这些附加可选择部分当被选择时渲染被利用以生成来源观点概要的附加资源中的一个或多个的至少一部分(例如,包括与图4a的附加内容425相同的信息和链接的弹出窗口)。
109.在各个实施方式中,附加内容渲染器130能够由(多个)应用107中的对应的一个(全部地或部分地)实现,能够作为(多个)应用107中的对应的一个的扩展被安装,并且/或者能够与(多个)应用107中的对应的一个接口(例如,经由api)。响应于经由(多个)应用107中的一个访问给定目标电子文档,附加内容渲染器130能够访问数据库112以确定给定目标电子文档是否包括数据库112中的条目。例如,数据库112能够包括基于url和/或其他识别
符的条目的索引,并且附加内容渲染器130能够搜索该索引以为给定目标电子文档确定是否存在条目。如果是,则附加内容渲染器能够利用本文中描述的一种或多种技术来修改给定目标电子文档的渲染。例如,条目能够包括给定电子文档的(多个)来源观点部分的指示,并且这种由附加内容渲染器130利用来更改那些来源观点部分使得它们被作为队列向用户突出显示、加粗或以其他方式被划出界线作为他们可以潜在地包括来源观点的指示。此外,例如,条目能够包括与给定电子文档的来源观点部分相关的附加内容的指示,并且附加内容渲染器能够使附加内容被自动地渲染,或者使它响应于某个用户输入(例如,选择或悬停在来源观点部分上方)而被渲染。附加内容渲染器130能够修改目标电子文档的渲染以引起附加内容的渲染并且/或者能够监视某个用户输入并且使渲染响应于某个用户输入而发生。
110.图5图示用于渲染与文档的偏向部分相关的附加内容的示例方法的流程图。图5的步骤能够由诸如客户端设备的一个或多个处理器的一个或多个处理器执行。其他实施方式可以包括除图5所图示的步骤外的附加步骤,能够以不同的顺序和/或并行地执行图5的(多个)步骤,并且/或者可以省略图5的步骤中的一个或多个。图5的步骤关于作为目标电子文档的作者的来源而被描述。然而,图5的实施方式能够相对于诸如发布者、创建者或发布者、创建者和/或作者的组合的其他来源而被执行。尽管图5在本文中被描述为渲染与文档的偏向部分相关的附加内容,但是应该理解,这用于示例性目的而不意味着是限制性的。此外,应该理解,能够在对于文档的任何数量的不同来源渲染与文档的任何来源观点相关的附加内容时执行图5的步骤。
111.在步骤505,目标电子文档和文档的作者被识别。目标电子文档能够基于用户导航到文档而被识别。例如,用户能够利用计算设备105的一个或多个组件来选择要查看的文档。目标电子文档能够另外或可替代地被识别为爬取过程的一部分,或者基于先前被爬取过程爬取和识别而被识别。基于文档的内容和/或基于与文档相关联的元数据,一个或多个组件能够确定生成了目标电子文档的作者。例如,文档能够包括将一个人识别为作者的页眉和/或脚注。此外,例如,与文档相关联的元数据能够包括作者信息。
112.在步骤510,目标电子文档被处理以确定文档的偏向部分。偏向部分能够由与来源观点识别引擎115共享一个或多个特性的组件确定。例如,来源观点识别引擎115能够基于该部分中包括的词语(例如,具有“最好”(“best”)、“最棒”(“greatest”)、“我认为”(“i think”)等的语句)。此外,例如,来源观点识别引擎115能够另外或可替代地通过利用机器学习模型处理该部分、基于处理生成量度并且确定该量度满足指示很可能有偏向的阈值来确定文档的一部分是有偏向的。
113.在步骤515,搜索一个或多个语料库以识别与作者相关的多个附加资源。附加资源能够由与附加资源引擎120共享一个或多个特性的组件识别。附加资源能够包括例如由作者生成的其他文档、提及作者的其他文档、与由作者提及的其他人相关的文档和/或与作者相关的其他资源。
114.在步骤520,附加资源中的每一个和目标电子文档的偏向部分的特征被处理以生成附加资源中的每一个的相关性分数。相关性分数能够由与附加资源评分器125共享一个或多个特性的组件生成。例如,附加资源评分器125能够提供目标电子文档的偏向部分和资源中的一个或多个作为机器模型的输入并且利用训练后的机器学习模型的输出以生成偏
向部分与附加资源之间的相关性分数。在一些实施方式中,附加资源评分器125能够生成作为二进制分数(例如,“1”表示相关而“0”表示不相关)的相关性分数。在一些实施方式中,附加资源评分器125可以是非二进制的并且表示附加资源与偏向部分之间的相关性水平的相关性分数。
115.在步骤525,为具有满足阈值的相关性分数的那些附加资源从附加资源生成的附加内容与目标电子文档的偏向部分之间的关系被存储在数据库中。能够将关系存储在与数据库112共享一个或多个特性的数据库中。在一些实施方式中,关系可以是在整个目标电子文档与从一个或多个附加资源生成的附加内容之间。在一些实施方式中,关系可以是在目标电子文档的特定偏向部分与附加内容之间。
116.在步骤530,一个或多个组件使正在渲染目标电子文档的计算设备与目标电子文档同时地渲染附加内容。在一些实施方式中,与附加内容渲染器130共享一个或多个特性的组件能够使计算设备与目标电子文档一起渲染附加内容。例如,附加内容渲染器130能够使客户端设备105连同目标电子文档一起渲染附加内容,诸如图4a所图示的。在一些实施方式中,附加内容渲染器130能够使客户端设备105与和偏向部分相关联的可选择部分一起渲染目标电子文档,使得在选择可选部分时,对应的附加内容在单独的界面中被渲染,如图4b所图示的。
117.图6是可以任选地用于执行本文中描述的技术的一个或多个方面的示例计算设备610的框图。计算设备610通常包括经由总线子系统612与多个外围设备进行通信的至少一个处理器614。这些外围设备可以包括存储子系统624,其包括例如存储器子系统625和文件存储子系统626、用户界面输出设备620、用户界面输入设备622以及网络接口子系统616。输入和输出设备允许用户与计算设备610交互。网络接口子系统616提供到外部网络的接口并且被耦合到其他计算设备中对应的接口设备。
118.用户界面输入设备622可以包括键盘、诸如鼠标、轨迹球、触摸板或图形平板的定点设备、扫描仪、结合到显示器中的触摸屏、诸如语音辨识系统、麦克风的音频输入设备和/或其他类型的输入设备。一般地,术语“输入设备”的使用旨在包括用于将信息输入到计算设备610中或到通信网络上的所有可能类型的设备和方式。
119.用户界面输出设备620可以包括显示子系统、打印机、传真机或诸如音频输出设备的非视觉显示器。显示子系统可以包括阴极射线管(crt)、诸如液晶显示器(lcd)的平板设备、投影设备或用于创建可见图像的某种其他机构。显示子系统还可以例如经由音频输出设备提供非视觉显示。一般地,术语“输出设备”的使用旨在包括用于将信息从计算设备610输出到用户或到另一机器或计算设备的所有可能类型的设备和方式。
120.存储子系统624存储提供本文中描述的模块中的一些或全部的功能性的编程和数据构造。例如,存储子系统624可以包括用于执行本文中描述的方法的选择的方面以及用于实现图1中描绘的各种组件的逻辑。
121.这些软件模块通常由处理器614单独或结合其他处理器执行。存储子系统624中使用的存储器625能够包括多个存储器,其包括用于在程序执行期间存储指令和数据的主随机存取存储器(ram)630和其中存储有固定指令的只读存储器(rom)632。文件存储子系统626能够为程序和数据文件提供持久存储,并且可以包括硬盘驱动器、软盘驱动器以及关联的可移动介质、cd
‑
rom驱动器、光驱或可移动介质盒。实现某些实施方式的功能性的模块可
以由文件存储子系统626存储在存储子系统624中,或者存储在可由处理器614访问的其他机器中。
122.总线子系统612提供用于让计算设备610的各种组件和子系统按预期彼此通信的机制。尽管总线子系统612被示意性地示出为单个总线,但是总线子系统的替代实施方式可以使用多个总线。
123.计算设备610可以是各种类型,包括工作站、服务器、计算集群、刀片服务器、服务器场或任何其他数据处理系统或计算设备。由于计算机和网络的不断变化的性质,图6中描绘的计算设备610的描述仅旨在作为用于图示一些实现方式的目的的特定示例。计算设备610的许多其他配置可能具有比图6中描绘的计算设备更多或更少的组件。
124.如本文所述(例如,关于图4a和图4b),附加内容渲染器(例如,图1的附加内容渲染器130)能够使用户的计算设备渲染与目标电子文档相关联的附加内容。附加内容能够由附加内容确定引擎(例如,图1的附加内容确定引擎135)确定,并且能够与目标电子文档同时地被渲染,使得用户在查看目标电子文档时,也能够查看附加内容。
125.在一些实施方式中,附加内容能够与目标电子文档的一个或多个来源观点部分相关,并且附加内容渲染器能够与附加内容对目标电子文档的来源观点部分中的一个或多个可用并且与目标电子文档的来源观点部分中的一个或多个相关的指示一起来渲染目标电子文档。目标电子文档的一个或多个来源观点部分能够被渲染为使得它们与文档的其余部分是可区分的(例如,加下划线、粗体、大写、圈出、以不同颜色渲染等),使得读者能够辨识附加内容对于目标电子文档的来源观点部分中的一个或多个可用。
126.在一些实施方式中,附加内容渲染器能够渲染指示与来源观点部分中的一个或多个相关的附加内容可用的可选择的界面元素而不渲染附加内容。在那些实施方式的一些版本中,目标电子文档的来源观点部分中的一个或多个能够是可选择的并且可以在选择时渲染附加内容。例如,如关于图3描述的,目标电子文档能够连同附加内容是可用的而与目标电子文档同时地渲染附加内容的指示一起被提供。在一些实施方式中,目标电子文档的多个来源观点部分能够与相同的附加内容相关联。例如,附加内容能够与整个目标电子文档的发布者和/或创建者相关联(而不关联到由作者写作的文档的特定来源观点部分)。因此,目标电子文档能够连同与目标电子文档的作者、发布者和/或创建者相关的多个来源观点部分一起被渲染。
127.在一些实施方式中,附加内容渲染器能够连同为目标电子文档的作者、发布者和/或创建者的来源观点概要一起图形地渲染目标电子文档,其中来源观点概要是基于识别的与目标电子文档的一个或多个来源观点部分相关的附加资源而被生成的。例如,多个附加资源能够与由作者写作的目标电子文档的来源观点部分、发布了目标电子文档的发布者的来源观点和/或核对了目标电子文档的创建者的来源观点相关,并且为作者、发布者和/或创建者的对应的来源观点摘要能够基于附加资源的内容而被生成。附加内容渲染器能够连同对应的来源观点概要对于由作者写作的文档的一个或多个偏向部分、发布了目标电子文档的发布者的来源观点和/或核对了目标电子文档的创建者的来源观点可用的一个或多个图形指示器一起渲染目标电子文档。
128.在一些实施方式中,来源观点摘要能够基于与目标电子文档相关的多个附加资源的特征和/或内容而被生成。多个附加资源能够被存储在可搜索的一个或多个语料库中。附
加内容渲染器能够连同目标电子文档一起渲染来源观点概要或来源观点概要的一部分,并且来源观点概要能够与到在生成来源观点概要时使用的多个附加资源中的一个或多个的链接一起被渲染。因此,用户能够选择链接中的一个并且被提供多个附加资源中的对应的一个。在一些实施方式中,来源观点概要能够作为目标电子文档渲染在界面的单独的部分中被渲染(例如,如关于图4a和图7a描述的)。在其它实施方式中,来源观点概要能够在与目标电子文档单独的界面中被渲染(例如,如关于图4b和图7b描述的)。
129.此外,来源观点概要能够提供对目标电子文档的至少一个来源的观点的解释。至少一个来源能够包括目标电子文档的作者、目标电子文档的发布者和/或目标电子文档的创建者。目标电子文档的作者能够是写作了目标电子文档的内容和/或生成了目标电子文档的其他部分(例如,图像)的个人。例如,写作新闻文章或者为新闻文章创建漫画的人能够被认为是该新闻文章的作者。目标电子文档的发布者能够是例如持有、准备和/或促进目标电子文档的传播的网站、杂志、新闻媒体、企业和/或其他实体。例如,准备和/或发布新闻文章的新闻机构能够被认为是该新闻文章的发布者。目标电子文档的创建者能够是核对了文档的内容(例如,将目标电子文档重新发布在对应网站上,经由与创建者相关联的社交媒体账户和/或核对目标电子文档的其他形式共享目标电子文档)但是不一定原始创作和/或原始发布目标电子文档的一个或多个个人。例如,发布由第一新闻机构原始发布和/或准备的新闻文章(或其轻微变化)并且核对该新闻文章的第二新闻机构能够被认为是该新闻文章的创建者,即使第二新闻机构确实没有原始创作和/或原始发布新闻文章也如此。
130.进一步地,对目标电子文档的至少一个来源的来源观点概要能够基于与至少一个来源相关和/或与目标电子文档的来源观点部分相关的多个附加资源的内容和/或附加资源特征。换句话说,对目标电子文档的来源的来源观点概要能够基于由作者写作的其他相关文档(当作者是来源时)、由发布者发布的其他相关文档(当发布者是来源时)和/或由创建者核对的其他相关文档(当创建者是来源时)。例如,对作者的作者观点概要能够提供关于作者的目标电子文档的来源观点部分(例如,偏向部分、有意见的部分和/或其他主观部分)的解释,并且能够基于由作者写作的包括与目标电子文档的偏向部分相关的内容的其他文档的特征而被生成。作为另一示例,对发布者的发布者观点概要能够提供关于发布者的目标电子文档的来源观点部分(例如,偏向部分、有意见的部分和/或其他主观部分)的解释,并且能够基于由发布者发布的包括与目标电子文档相关的内容的其他文档的特征而被生成。在该示例中,其他文档能够由同一作者或不同作者写作。作为又一示例,对创建者的创建者观点概要能够提供关于创建者的目标电子文档的来源观点部分(例如,偏向部分、有意见的部分和/或其他主观部分)的解释,并且能够基于由创建者核对的包括与目标电子文档相关的内容的其他文档的特征而被生成。因此,来源观点概要能够基于与至少一个来源相关联的其他文档而不是基于包括与目标电子文档的来源观点部分相关的内容但是与至少一个来源不相关联的其他文档来提供来自电子目标文档的至少一个来源的观点的解释。
131.在各个实现方式中,能够通过搜索一个或多个语料库来识别与至少一个来源相关和/或与目标电子文档的来源观点部分相关的附加资源。一个或多个语料库能够包括不同类型的附加资源,诸如新文章、博客帖子、社交媒体帖子和/或多个类型的文档。在一些实施方式中,多个来源观点概要能够为不同类型的附加资源中的每一个的至少一个来源而被生成。在那些实施方式的一些版本中,对至少一个来源的来源观点概要的第一部分能够基于
第一类型的附加资源而被生成,并且对至少一个来源的来源观点概要的第二部分能够基于第二类型的附加资源而被生成。例如,能够基于与由发布者发布的目标新闻文章相关的新闻文章的特征来生成对发布者的来源观点概要的第一部分,并且发布者的来源观点摘要的第二部分能够基于与发布者相关联的社交媒体账户的社交媒体帖子和/或与其的交互而被生成。
132.在一些实施方式中,单个来源观点概要能够为至少一个附加来源被生成。在那些实施方式的一些版本中,至少一个来源的来源观点能够基于附加资源的类型通过一个或多个加权因子而被加权。例如,如果作者是写作关于国际旅行目的地并且包括“泰国是亚洲最好的旅游国家”的来源观点部分的文章的旅行代理人,则能够通过1.0的加权因子对该文章进行加权以指示该文章高度地指示作者的观点。相比之下,如果作者写作了包括“泰国是亚洲最酷的旅游国家”(“thailand is the coolest country in asia to visit”)的来源观点部分的社交媒体帖子,则能够通过0.7的加权因子对社交媒体帖子进行加权以表明该文章指示作者的观点,而不是像新闻文章那样指示作者的观点。在其他实施方式中,每种类型的附加资源能够被同等地加权。
133.此外,来源观点概要能够包括对目标电子文档的至少一个来源的来源观点的解释,其关于至少一个来源(例如,写作了目标电子文档的作者、发布了目标电子文档的发布者和/或核对了目标电子文档的创建者)的观点通知消费目标电子文档的用户。在一些实施方式中,来源观点概要包括至少一个来源的各个部分。来源观点概要的这些部分中的每一个能够包括解释目标电子文档的至少一个来源的观点的不同方式。在那些实施方式的一些版本中,来源观点概要的第一部分作为基于与目标电子文档相关的附加资源的特征而生成的一个或多个自然语言解释(例如,单词、短语和/或句子)能够被呈现给消费目标电子文档的用户。在那些实施方式的另外和/或替代版本中,来源观点概要的第二部分作为基于与目标电子文档相关并且来自相同来源的附加资源的特征而生成的一个或多个来源观点度量能够被呈现给消费目标电子文档的用户。一个或多个来源观点度量能够包括,例如,指示至少一个来源以特定方式(例如,正面地、负面地和/或其他方式)刻画目标电子文档的来源观点部分中包括的内容多频繁的一个或多个来源观点百分比、指示目标电子文档的(多个)来源观点部分中包括的内容与来自至少一个来源的其他文档的来源观点部分相比如何包括给定观点的一个或多个来源观点统计(例如,平均值、中值、标准差和/或其他来源观点统计)、指示至少一个来源以特定方式刻画目标电子文档的来源观点部分中包括的内容多频繁的一个或多个视觉表示(例如,饼图、条形图和/或其他视觉表示)和/或其他来源观点度量。在那些实施方式的一些另外和/或替代版本中,来源观点概要的第三部分能够包括到被利用以为来源观点概要生成自然语言解释和/或被利用以为来源观点概要生成来源观点度量的附加资源中的一个或多个的链接的列表。链接的列表中包括的每个链接当被选择时能够使计算设备导航到被利用以为来源观点概要生成自然语言解释和/或被利用以为来源观点概要生成来源观点度量的对应的附加资源(或与对来源观点的解释相关联的对应的附加资源的特定部分)。链接的列表中的链接能够被表示为超链接文本,当被选择时,该超链接文本使计算设备导航到对应的附加资源。因此,来源观点概要能够包括对目标电子文档的至少一个来源的不同观点的各种解释。
134.在一些实施方式中,来源观点概要能够在与目标电子文档单独的界面中被渲染。
例如,参考图7a,目标电子文档700由附加内容渲染器(例如,图1的附加内容渲染器130)在界面的第一部分中渲染。图7a的目标电子文档700的标题为由“john smith”创作并且由“示例体育广播网络”发布的“篮球赛季揭幕”(“basketball season tips off!”)。值得注意的是,目标电子文档700是包括如由偏向部分710和720指示的对蓝色大学篮球队的偏向的新闻文章。在一些实施方式中,如图示,目标电子文档700能够被提供目标电子文档700的来源观点部分710和720的指示。例如,来源观点部分710和720被加粗以通知消费目标电子文档的用户目标电子文档700中包括的语句可能受到来源的观点影响。用于对来源观点部分710和720图形地划出界线的其他技术能够被利用,并且能够包括,例如,圈出、加下划线、突出显示和/或对目标电子文档的(多个)来源观点部分图形地划出界线的其他方式。
135.附加内容界面705包括基于与来源观点部分710和720的内容相关的附加资源的特征而生成的发布者观点概要715和作者观点概要725的渲染的版本。在一些实施方式中,附加内容界面705能够与目标电子文档700同时地被渲染。在其他实施方式中,附加内容界面705能够响应于接收到要查看附加内容界面705的指示而被渲染。例如,用户可以点击、突出显示、加下划线或以其他方式选择来源观点部分710和710中的一个或多个,并且附加内容界面705能够响应于选择而被渲染。作为另一示例,目标电子文档能够连同一个或多个可选元素一起被渲染,这些可选元素在选择时,将附加内容界面705连同目标电子文档700一起渲染,并且在附加选择时,移除附加内容界面705。以这种方式,附加内容界面705能够被打开和关闭以供由用户消费。
136.对于发布者观点概要715,附加内容确定引擎(例如,图1的附加内容确定引擎135)能够搜索一个或多个语料库以识别与来源观点部分710和720的内容相关的附加资源。所识别的附加资源能够包括(或被约束于)由“示例体育广播网络”准备和/或发布的其他文档、与示例体育广播网络相关联的社交媒体账户的社交媒体帖子和/或交互、和/或与“示例体育广播网络”相关联的其他附加资源示例。所识别的附加资源的特征使来源观点识别引擎(例如,图1的来源观点识别引擎115)能够生成对发布者观点概要715的自然语言解释733a,其解释示例体育广播网络对内容的观点,诸如偏向、意见、假设、倾向和/或其他观点(例如,示例体育广播专门从事发布关于蓝色大学体育的文章)。例如,能够基于来自与来源观点部分710和720相关和/或解释示例体育广播网络的偏向、意见和/或其他主观量度的附加资源的内容来生成对发布者观点概要715的自然语言解释733a。
137.进一步地,发布者观点概要715能够包括到被利用以生成对发布者观点概要715的自然语言解释733a的附加资源的链接735a的列表。链接735a的列表包括到文档a的第一链接、到文档b的第二链接和可选择的界面元素,当被选择时,该可选界面元素使消费目标电子文档700的用户能够查看在生成自然语言解释733a时利用的更多附加资源。在一些实施方式中,链接735a的列表中包括的链接包括在生成自然语言解释733a时提供最大解释范围的链接(例如,如关于附加资源评分器125所描述的)。因此,用户能够选择要与对应的文档和/或对应的文档的与来源观点部分710和720相关的特定部分一起被提供的链接中的一个。进一步地,发布者观点概要715也能够包括对发布者示例体育广播网络的发布者观点度量737a(例如,在图7a中示出为发布者观点百分比)。发布者观点度量737a指示由示例体育广播网络准备和/或发布的文档、通过与示例体育广播网络相关联的社交媒体账户共享/点赞的社交媒体帖子和/或与来源观点部分710和720相关的附加资源的其他特征的90%以正
面方式刻画蓝色大学篮球队,而仅10%以负面方式刻画蓝色大学篮球队。进一步地,发布者观点度量737a能够连同对应的超链接文本739a一起被渲染。如图7a所示,超链接文本739a使得用户能够导航到在对示例体育广播网络对蓝色大学的正面刻画(例如,标题为“蓝色大学是最棒的”(“university of blue is the greatest”))并且对示例体育广播网络对蓝色大学的负面描述(例如,“蓝色大学再次输给了
……”
(“university of blue loses
…
again”)的社交媒体帖子)生成发布者观点度量737a时利用的附加资源。尽管对应的超链接文本739a对于发布者观点度量737a中的每一个被描绘为到单个附加资源的超链接文本,但是应该理解,这是出于示例性目的而不意味着是限制性的。例如,对应的超链接文本739a也能够与可选界面元素一起被渲染,该可选界面元素当被选择时使消费目标电子文档700的用户能够查看在生成发布者观点度量737a时利用的更多附加资源。
138.对于作者观点概要725,附加内容确定引擎能够搜索一个或多个语料库以识别与来源观点部分710和720的内容相关的附加资源。所识别的附加资源能够包括(或被约束于)由john smith写作的其他文档、与john smith相关联的社交媒体账户的社交媒体帖子和/或交互、和/或与john smith相关联的其他附加资源。所识别的附加资源的特征使来源观点识别引擎能够为作者偏向概要725确定和生成解释john smith对内容的观点例如偏向、意见、假定、素因和/或其他观点(例如,john smith是蓝色大学的杰出校友、蓝色大学体育的拥护者,并且经常参加蓝色大学的体育赛事)的自然语言解释733b。例如,能够基于来自与来源观点部分710和720相关和/或解释john smith的偏向、意见和/或其他主观量度的附加资源的内容来生成对作者观点概要725的自然语言解释733b。
139.进一步地,作者观点概要725能够包括到被利用以为作者观点概要725生成自然语言解释733b的附加资源的链接735b的列表。链接735b的列表包括到文档a的第一链接、到文档c的第二链接和可选择的界面元素,该可选择的界面元素当被选择时使消费目标电子文档700的用户能够查看在生成自然语言解释733b时利用的更多附加资源。在一些实施方式中,链接735b的列表中包括的链接包括在生成自然语言解释733a时提供最大解释范围的链接(例如,如关于附加资源评分器125所描述的)。因此,用户能够选择要与对应的文档和/或对应的文档的与来源观点部分710和720相关的特定部分一起提供的链接中的一个。此外,作者观点概要725也能够包括作者john smith的作者观点度量737b(例如,在图7a中示出为作者观点百分比)。作者观点度量737b指示由john smith写作的文档、通过与john smith相关联的社交媒体账户共享/点赞的社交媒体帖子和/或与来源观点部分710和720相关的附加资源的其他特征的95%以正面方式刻画蓝色大学篮球队,而仅5%以负面方式刻画蓝色大学篮球队。进一步地,作者观点度量737b能够与对应的超链接文本739b一起被渲染。如图7a所示,超链接文本739b使用户能够导航到在对john smith对蓝色大学的正面刻画(例如,标题为“蓝色大学是不可阻挡的”(“university of blue is unstoppable”)的新闻文章)并且对john smith对蓝色大学的负面刻画(例如,“蓝色大学有球队历史上最差的一年”(“university of blue has worst year in team history”)的社交媒体帖子)生成作者观点度量737b时利用的附加资源。尽管对应的超链接文本739b为作者观点度量737b中的每一个被描绘为到单个附加资源的超链接文本,但是应该理解,这是出于示例性目的而不意味着是限制性的。例如,对应的超链接文本739b也能够与可选择的界面元素一起被渲染,该可选界面元素当被选择时使消费目标电子文档700的用户能够查看在生成作者观点度量
737b时利用的更多附加资源。
140.值得注意的是,在图7a的示例中,对发布者观点概要715的自然语言解释733a是基于至少文档a和文档b中包括的特征(例如,内容、元数据和/或其他特征)而被生成的,而对作者观点概要725的自然语言解释733b是基于至少文档a和文档c中包括的特征(例如,内容、元数据和/或其他特征)而被生成的。因此,文档a是由示例体育广播网络发布并且也由john smith创作的附加资源。然而,文档b是由示例体育广播网络发布但不是由john smith创作的附加资源。此外,文档c是由john smith创作但不是由示例体育广播网络发布的附加资源。即使图7a中的文档b和文档c不包括与目标电子文档700(例如图7a中的文档a)相同的作者(例如,john smith)和相同的发布者(例如,示例体育广播网络),附加内容确定引擎(例如,图1的附加内容确定引擎135)仍然能够识别这些附加资源中的每一个,因为它们包括与目标电子文档的各个来源的来源观点部分710和720相关的内容。
141.此外,在来源观点概要中提供自然语言解释的实施方式(例如,基于文档a和文档b的特征的自然语言解释733a以及基于文档a和文档c的特征的自然语言解释733b)能够导致需要减少用户输入量(或甚至无用户输入)以识别解释电子文档的来源观点部分的附加资源。那些实施方式另外或可替代地通过在单个界面中将自然语言解释连同目标电子文档一起渲染来保存客户端和/或网络资源,并且也允许“一键”导航到在生成自然语言解释时利用的附加资源。若不存在这些技术,将需要进一步用户输入以进行附加搜索、基于该搜索打开新标签和/或导航到附加界面。
142.尽管图7a被描绘为包括仅发布者观点概要715和作者观点概要725,但是应该理解,这是为了示例性目的而不意味着是限制性的。例如,如果目标电子文档700也由创建者核对了(例如,如关于图7b所描述的),则附加界面705可以另外和/或可替代地包括创建者观点概要。创建者观点概要能够以在本文中(例如,关于图1、图4a、图4b、图7a和图7b)描述的任何方式被生成和渲染。此外,尽管图7a的发布者观点概要715和作者观点概要725被描绘为包括各种自然语言解释、来源观点度量和链接的列表,但是应该理解,发布者观点概要715和/或作者观点概要725能够包括自然语言解释、来源观点度量、链接的列表和/或其任何组合中的一个以向消费目标电子文档的用户通知目标电子文档700中包括的潜在偏向和对潜在观点的解释和/或目标电子文档700的发布者和/或创建者的潜在观点。此外,在一些实施方式中,目标电子文档700能够包括指示目标电子文档700中包括的来源观点的元数据。
143.在一些实施方式中,来源观点概要和/或附加内容能够在与目标电子文档单独的界面中被渲染。例如,参考图7b,与图7a所图示的相同的目标电子文档(即,目标电子文档700)被渲染而没有附加界面705。进一步地,目标电子文档700也被渲染为目标电子文档700具有“示例期刊”(“the example
‑
journal”)的创建者的核对版本。如图示,光标745a正悬停在创建者“示例期刊”上方,并且在悬停在(或者选择)创建者the example
‑
journal上方时,创建者观点概要750被渲染为弹出窗口。与图7a的来源观点概要相比,图7b的创建者观点概要750仅包括指示由示例期刊核对的文档、通过与示例期刊相关联的社交媒体账户共享/点赞的社交媒体帖子和/或与来源观点部分710和720相关的附加资源的其他特征的45%以正面方式刻画蓝色大学篮球队的创建者观点度量737c(例如,在图7b中示出为创建者观点百分比),而55%以负面方式刻画蓝色大学篮球队。进一步地,创建者观点度量737c能够连同
对应的超链接文本739c一起被渲染。如图7b所示,超链接文本739c使用户能够导航到在对示例期刊对蓝色大学的正面刻画(例如,标题为“蓝色大学全国最好的新成员到来”(“university of blue lands the nation’s best recruit”)的新闻文章)并且对示例期刊对蓝色大学的负面描述(例如,“蓝色大学成为全州最差球队”(“university of blue finishes as the worst team in the state”)的另一新闻文章)生成创建者观点度量737c时利用的附加资源。尽管对应的超链接文本739c为创建者观点度量737c中的每一个被描绘为到单个附加资源的超链接文本,但是应该理解,这是为了示例性目的而不意味着是限制性的。例如,对应的超链接文本739c也能够与可选择的界面元素一起被渲染,该可选择的界面元素当被选择时使消费目标电子文档700的用户能够查看在生成创建者观点度量737c时利用的更多附加资源。类似地,光标745b正悬停在第一来源观点部分710上方,并且在悬停在(或者选择)第一来源观点部分710上方时,作者观点概要715被渲染为弹出窗口。与图7a的作者观点概要725相比,图7b的作者观点概要725仅包括作者观点度量737b(例如,在图7b中示出为作者观点百分比)和对应的超链接文本739b。
144.尽管图7b被描绘为仅包括作者观点概要725和创建者观点概要750,但是应该理解,这是为了示例性目的而不意味着是限制性的。例如,在悬停在(或者选择)发布者示例体育广播网络上方时,能够将发布者观点概要715渲染为弹出窗口。此外,尽管图7b的作者发布者概要725和创建者观点概要750被描绘为包括仅来源观点百分比和相关链接,但是应该理解,作者观点概要725和/或创建者观点概要750也能够包括自然语言解释、其他来源观点度量、其他链接和/或链接的列表和/或其任何组合中的一个以向消费目标电子文档的用户通知目标电子文档700中包括的潜在观点和/或对潜在观点的解释和/或目标电子文档700的发布者和/或创建者的潜在观点。
145.在一些另外的和/或替代实施方式中,用户能够选择目标电子文档700的除了来源观点部分710和720之外的其他内容(例如,经由点击、突出显示、加下划线或以其他方式选择)。在那些实施方式的一些版本中,用户界面元素能够响应于用户选择其他内容而连同目标电子文档700一起被渲染,并且该用户界面元素当被选择时能够使来源观点识别引擎分析所选其他内容。在那些实施方式的一些进一步的版本中,所选择的其他内容能够被分析以确定所选择的其他内容是否潜在地包括与目标电子文档700的作者、发布者和/或创建者相关联并且与所选择的其他内容相关的观点(例如,使用来源观点识别引擎115)和/或以确定是否存在解释所选择的其他内容中包括的任何来源观点的附加文档(例如,使用附加资源评分器125)。如果所选择的其他内容包括来源观点并且/或者能够解释来源观点,则能够经由附加内容界面705和/或经由新界面(例如,图7b的弹出窗口)渲染另一来源观点概要,并且/或者能够更新渲染后的来源观点概要中的一个或多个。另外或可替代地,用户对目标电子文档700的其他内容的选择能够被用作用于更新一个或多个机器学习模型(例如,关于图1描述的由观点识别引擎115利用的机器学习模型和/或由附加资源评分器125利用的机器学习模型)的训练实例)。例如,如果用户突出显示“当下周蓝色大学队对阵红色大学队时,蓝色大学队将获胜”(“when the university of blue team plays the university of red team next week,the university of blue team will win”)的其他内容并且如果确定该其他内容潜在地包括作者john smith的主观观点,则作者观点概要715能够经由附加内容界面705被渲染和/或基于所选择的附加内容被更新。此外,作者观点概要715能够
包括到解释所选择的其他内容中包括的任何来源观点的附加文档的链接。以这种方式,用户能够标记目标电子文档700的潜在地包括先前未被识别为包括(多个)来源观点的(多个)来源观点的(多个)部分。
146.在各个实施方式中,如果目标电子文档包括由创建者核对的(多个)引述和/或内容,则目标电子文档能够被分析(例如,使用来源观点识别引擎115)以确定由创建者核对的(多个)引述和/或内容是否错误呈现来自原始来源的原始内容。进一步地,来自原始来源的原始内容也能够被识别。在那些实施方式的一些版本中,来源观点概要也能够包括在目标电子文档中错误呈现的任何内容的指示。例如,如果示例期刊即图7b中的目标电子文档700的创建者在目标电子文档700中包括来自蓝色大学队的教练的陈述“我认为如果我们振作好则我们有机会赢得比赛”(“i think we have a chance to win the game if we rebound well”)的引述,但是蓝色大学教练实际上陈述“如果我们振作好我们将赢得比赛”(“we will win the game if we rebound well”),则这种错误呈现能够被包括在图7b的创建者观点概要750中。尽管该示例中的错误呈现可以看起来是可忽略的,但是它可以以比由教练的实际语句所传达的方式更值得喜欢和/或值得尊敬的方式刻画蓝色大学球队的教练,并且它可以解释创建者对蓝色大学球队的主观观点。在那些实施方式的一些进一步的版本中,附加内容界面705也能够包括引述的原始来源的来源观点概要。例如,附加内容界面705也可以包括作为引述的原始作者的蓝色大学教练的偏向概要。
147.在各个实施方式中,附加内容渲染器(例如,图1的附加内容渲染器130)能够由(多个)应用(例如,图1的(多个)应用107)中的对应的一个(全部地或部分地)实现,能够作为(多个)应用中的对应的一个的扩展被安装,并且/或者能够与(多个)应用中的对应的一个接口(例如,经由api)。响应于经由(多个)应用中的一个访问给定目标电子文档,附加内容渲染器能够访问一个或多个数据库(例如,图1的数据库112)以确定给定目标电子文档是否包括数据库中的一个或多个中的条目。例如,数据库中的一个或多个能够包括基于url和/或其他识别符的条目的索引,并且附加内容渲染器能够搜索该索引以确定对于给定目标电子文档是否存在条目。如果是,则附加内容渲染器能够利用本文中描述的一种或多种技术来修改给定目标电子文档的渲染。例如,条目能够包括给定电子文档的(多个)来源观点部分的指示,以及这种由附加内容渲染器利用来更改那些来源观点部分使得它们作为队列向用户被突出显示、被加粗或以其他方式被划出界线为他们可以潜在地包括来源观点的指示。另外,例如,条目能够包括与给定电子文档的来源观点部分相关的附加内容的指示,并且附加内容渲染器能够使附加内容被自动地渲染,或者使它响应于某个用户输入(例如,选择或悬停在来源观点部分上方)而被渲染。附加内容渲染器能够修改目标电子文档的渲染以引起附加内容的渲染并且/或者能够监视某个用户输入并且使渲染响应于某个用户输入而发生。
148.在各个实施方式中,附加内容确定引擎(例如,图1的附加内容确定引擎135)能够利用一种或多种去重技术来确保来源观点概要更准确地反映目标电子文档的至少一个来源的实际来源观点。附加内容确定引擎能够比较附加资源的特征,并且能够避免在确定来源观点度量时包括与其他附加资源重复的某些附加资源,从而产生所识别的附加资源的子集。例如,如果发布者在与发布者相关联的网站上发布新闻文章,然后在与发布者相关联的社交媒体账户上分享链接以及来自新闻文章的引述,则将在为发布者确定(多个)来源观点
度量时包括仅该新闻文章的原始发布的内容。相比之下,如果发布者在与发布者相关联的社交媒体账户上共享链接以及未被包括在新闻文章中的附加内容(例如,“蓝色大学队也是全国最好的防守球队”(“the university of blue team is also the best defensive team in the nation”)),则该新闻文章的原始发布的内容和社交媒体帖子的附加内容两者将在为发布者确定(多个)来源观点度量时被包括。进一步地,如果写作了新闻文章的作者分享来自与发布者相关联的社交媒体账户的链接以及未被包括在新闻文章(例如,“蓝色大学球队也是全国最好的进攻球队”(“the university of blue team is also the best offensive team in the nation”))中的附加内容,则该新闻文章的内容和社交媒体帖子的附加内容两者将在为作者确定来源观点度量时而不在为发布者确定来源观点度量时被包括。通过使用这些去重技术,来源观点概要能够更准确地反映目标电子文档的至少一个来源的实际观点,因为对应的(多个)来源观点度量未被重复资源所扭曲。
149.在各个实施方式中,附加内容确定引擎能够利用图神经网络来识别与目标电子文档的来源观点部分相关的附加资源。进一步地,附加资源评分器(例如,图1的附加资源评分器125)也能够利用图神经网络来确定指示识别后的附加资源中的给定一个(或附加资源的一部分)与目标电子文档之间的相关性的相关性分数。知识图能够包括各种节点,诸如作者节点、发布者节点、创建者节点和/或资源节点,并且连接每个节点的边能够定义这些各种节点之间的关系。例如,“john smith”的作者节点能够通过“创作的”(“authored”)边被连接到“篮球赛季揭幕!”的资源节点;“示例体育广播网络”(“example sports radio network”)的发布者节点能够通过“发布的”(“published”)边被连接到“篮球赛季揭幕!”的资源节点;“示例期刊”(“the example
‑
journal”)的创建者节点能够通过“创建的”(“created”)边被连接到“篮球赛季揭幕!”的资源节点;依此类推。知识图也能够包括与社交媒体交互相关的各个边。例如,如果作者(例如,john smith)分享新闻文章(例如,“蓝色大学球队最有希望赢得全国冠军”(“university of blue team favorite to win national championship”)),则与作者相关联的作者节点(例如,作者节点“john smith”)能够通过“共享的”(“shared”)边被连接到与该新闻文章相关联的资源节点(例如,资源节点“蓝色大学球队最有希望赢得全国冠军”)。
150.此外,在那些实施方式中的一些中,能够将知识图作为跨图神经网络的输入迭代地应用以生成表示知识图的节点和/或边的一个或多个矢量。在每次迭代时,然后能够将表示节点和/或边的向量与知识图进行比较。基于该比较,图神经网络在知识图的每个节点中嵌入关于知识图中的邻近节点的信息。进一步地,在每次迭代时,节点的每一个被嵌入有关于邻近节点的邻近节点的信息,使得关于每个节点的信息跨知识图被传播。因此,通过将具有嵌入节点的知识图作为跨图神经网络的输入迭代地应用,知识图的每个节点被嵌入有关于知识图的其他节点中的每一个的信息。例如,假设知识图包括被连接到发布者节点和创建者节点两者的作者节点,但是发布者节点与创建者节点未被连接。进一步假设知识图被作为跨图神经网络的输入应用以生成在知识图中表示作者节点、发布者节点、创建者节点和/或这些节点之间的对应边的矢量。在该示例中,作者节点将被嵌入有来自发布者节点和创建者节点两者的信息,但是发布者节点和创建者节点两者都将仅被嵌入有来自作者节点的信息。然而,通过随后将具有嵌入节点的知识图作为跨图神经网络的输入应用,发布者节点能够经由所嵌入的作者节点被嵌入有来自创建者节点的信息,并且创建者节点能够经由
所嵌入的作者节点被嵌入有来自发布者节点的信息。以这种方式,能够识别与目标电子文档的来源观点部分相关的附加资源以在为目标电子文档的至少一个来源生成来源观点概要时使用。
151.此外,在那些实施方式中的一些中,附加资源评分器能够基于嵌入在知识图的每个节点中的信息来确定识别的附加资源中的每一个的相关性分数。例如,嵌入在节点中的信息能够包括其他节点中的每一个中包括的内容的索引。这允许附加内容确定引擎快速地识别与目标电子文档的来源观点部分相关的附加资源,而不必遍历知识图的边来识别附加资源。此外,这允许附加资源评分器在从消费目标电子文档的用户接收到要查看一个或多个来源观点概要的任何指示之前为目标电子文档的给定来源观点部分确定一些附加资源的相关性分数。
152.在本文中讨论的某些实施方式可以收集或使用关于用户的个人信息(例如,从其他电子通信中提取的用户数据、关于用户的社交网络的信息、用户的位置、用户的时间、用户的生物特征信息以及用户的活动和人口统计信息、用户之间的关系等),用户被提供有用于控制信息是否被收集、个人信息是否被存储、个人信息是否被使用以及信息如何关于用户被收集、被存储并被使用的一个或多个机会。即,本文中讨论的系统和方法仅在从相关用户接收到要这样做的明确授权时才收集、存储和/或使用用户个人信息。
153.例如,用户被提供对于程序或特征是否收集关于该特定用户或与该程序或特征相关的其他用户的用户信息的控制。个人信息要为其被收集的每个用户被呈现有用于允许控制与该用户相关的信息收集、关于信息是否被收集并且关于信息的哪些部分要被收集提供许可或授权的一个或多个选项。例如,用户能够通过通信网络被提供一个或多个这种控制选项。另外,某些数据可以在它被存储或使用之前以一种或多种方式被处理,使得个人可识别的信息被移除。作为一个示例,用户的身份可以被处理,使得没有个人可识别的信息能够被确定。作为另一示例,用户的地理位置可以被一般化为更大的区域,使得用户的特定位置不能够被确定。
154.虽然已在本文中描述并图示了若干实施方式,但是可以利用用于执行功能和/或获得结果和/或本文中描述的优点中的一个或多个的各种其他手段和/或结构,并且这种变化和/或修改中的每一个被视为在本文中描述的实施方式的范围内。更一般地,本文中描述的所有参数、尺寸、材料和配置都意味着是示例性的并且实际的参数、尺寸、材料和/或配置将取决于使用教导针对的一个或多个特定应用。本领域的技术人员将认识到或使用不止一个例行实验能够查明本文中描述的特定实施方式的许多等价形式。因此应当理解,前面的实施方式仅作为示例被呈现,并且在所附权利要求及其等价形式的范围内,实施方式可以以不同于具体地描述和要求保护的方式被实践。本公开的实现方式涉及本文描述的每个单独的特征、系统、制品、材料、套件和/或方法。另外,两个或更多个这种特征、系统、制品、材料、套件和/或方法的任何组合在这种特征、系统、制品、材料、套件和/或方法不相互不一致的情况下,被包括在本公开的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
