1.本发明属于深度学习领域,具体涉及一种集成小波分解与深度神经网络的水质指标多步预测方法。
背景技术:
2.水是生命之源,是人类生产生活的必要保障。然而,随着科技的发展,工业活动用水量急剧增长;随着人均寿命的提高,人口不断膨胀,生活用水量也与日俱增。目前,国内外的研究人员一直都在展开水质预测的相关研究,并已经提出了许多不同方法,目前主要使用的方法有水质模拟模型、回归分析、时间序列分析、机器学习等。其中,目前的水质预测方法中,水质模拟模型方法适用范围小,时间序列分析方法对于数据要求高,回归分析方法不适合表达复杂数据,而深度神经网络作为实现机器学习的一种现代手段,由于网络中的各个神经元能够进行独立运算和处理,且各个神经元由非线性激活函数驱动,因此它既适用于线性问题,又适用于非线性问题,普适性强、灵活性高,高度适用于非线性、波动强的水质数据。
3.此外,目前对水质预测研究主要面向单步预测,即仅针对未来某一时间点进行预测。上述各类水质预测方法中,水质模拟模型、时间序列分析、回归分析方法最终输出一个值,不适用于多步预测任务;机器学习与神经网络方法可以输出多个值,自这类方法出现后业内逐渐萌发了少量多步预测应用研究。总体而言,水质数据多步预测目前仍缺乏系统性的探讨和优化。
技术实现要素:
4.本发明的目的是克服现有的不足,提供一种集成小波分解与深度神经网络的水质指标多步预测方法。
5.为实现本发明目的,提供的技术方案如下:
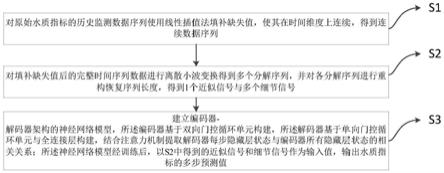
6.一种集成小波分解与深度神经网络的水质指标多步预测方法,它的步骤如下:
7.s1:对原始水质指标的历史监测数据序列使用线性插值法填补缺失值,使其在时间维度上连续,得到连续数据序列;
8.s2:对填补缺失值后的完整时间序列数据进行离散小波变换得到多个分解序列,并对各分解序列进行重构恢复序列长度,得到1个近似信号与多个细节信号;
9.s3:建立编码器
‑
解码器架构的神经网络模型,所述编码器基于双向门控循环单元构建,所述解码器基于单向门控循环单元与全连接层构建,结合注意力机制提取解码器每步隐藏层状态与编码器所有隐藏层状态的相关关系;所述神经网络模型经训练后,以s2中得到的近似信号和细节信号作为输入值,输出水质指标的多步预测值。
10.作为优选,所述步骤s1中,针对历史监测数据中的每个缺失值,利用其前后位置的水质指标值进行线性插值:
[0011][0012]
式中,x表示需要插值的位置,y表示待插的缺失值,x0表示x的前一位置,y0表示x0位置的值,x1表示x的后一位置,y1表示x1位置的值。
[0013]
作为优选,所述步骤s2的具体方法如下:
[0014]
s21:对线性插值处理后的完整时间序列数据进行离散小波变换,将原始的完整时间序列数据分解为1个低频信号和多个高频信号;
[0015]
s22:再通过小波重构对分解得到的各信号序列进行逆变换,将每个信号序列转化为与完整时间序列数据等长,得到1个近似信号与多个细节信号。
[0016]
作为优选,所述步骤s3的具体方法如下:
[0017]
s31:构建基于双向门控循环单元的神经网络结构,以步骤s2中获得的近似信号和细节信号作为双向门控循环单元的输入,构成编码器;
[0018]
s32:构建基于单向门控循环单元与全连接层的神经网络结构作为解码器,计算解码器每步隐藏层状态对于编码器所有隐藏层状态的注意力权重矩阵,并基于注意力权重矩阵和编码器所有隐藏层的输出值进行加权求和,计算上下文向量;以编码器的最后一个时间步的输出值作为初始输入值,以编码器正向细胞状态与反向细胞状态之和作为初始细胞状态,将当前步的上下文向量、上一步的输出、上一步的隐藏层状态合并作为下一个时间步的输入值,在单向门控循环单元上叠加全连接层,输出下一个时间步的水质指标预测值;
[0019]
s33:按照设定的预测步数不断迭代,直至获得指定步数的预测值。
[0020]
作为优选,所述神经网络模型采用小批量梯度下降法对模型进行训练。
[0021]
作为优选,所述神经网络模型训练过程中使用adam优化算法辅助梯度下降和学习率衰减,使神经网络模型能够针对性输出水质指标的多步预测值。
[0022]
作为优选,所述原始水质指标的历史监测数据为周监测数据。
[0023]
作为优选,所述原始水质指标的历史监测数据序列预先经过数据清理,去除异常数据。
[0024]
本发明与现有技术相比具有的有益效果:
[0025]
(1)本发明针对目前水质预测领域多步预测研究较少的问题,提出了水质指标的多步预测方法,实现了对于未来多个时间点的一步式预测,并在准确度、一致性与多步预测精度稳定性上有所提升。
[0026]
(2)本发明在水质指标预测模型中结合使用了小波分解与深度神经网络技术。其中,利用小波分解提取水质指标长时间序列中的高低频特征,提升模型抗噪性;使用深度神经网络中的编码器
‑
解码器架构与注意力机制,有效提取了小波分解序列上的局部信号波动,进一步放大并融合了不同频次上的关键信息。
附图说明
[0027]
图1为集成小波分解与深度神经网络的水质指标多步预测方法流程图;
[0028]
图2为集成小波分解与深度神经网络的水质指标多步预测神经网络模型结构图;
[0029]
图3为模型优化训练流程图;
[0030]
图4为2014
‑
2018年长江流域codmn(高锰酸盐指数)预测值与真实值散点图。
具体实施方式
[0031]
下面结合附图和具体实施方式对本发明做进一步阐述和说明。
[0032]
目前的水质预测方法中,水质模拟模型方法适用范围小,时间序列分析方法对于数据要求高,回归分析方法不适合表达复杂数据,而神经网络模型具有特征逐层抽取、拟合非线性变化、自动融合特征信息的特点,适用于构建普适性高、数据复杂的水质预测模型。然而,目前使用人工神经网络展开的水质预测研究主要面向单步预测,即仅针对未来某一时间点进行预测。自机器学习与神经网络方法出现后,业内逐渐萌发了少量多步预测应用研究,但主要通过控制全连接层或lstm/gru的单元数批量输出多个值,无法体现出前期预测值对于后期预测值的影响。总体而言,针对水质数据的神经网络多步预测目前仍缺乏系统性的探讨和优化。在此基础上,本发明结合使用小波分解与神经网络模型中的编码器
‑
解码器架构、注意力机制,其中小波分解方法用于分离数据波动的高频与低频特征,提取时频二维信息,减弱噪音影响;编码器
‑
解码器架构通过组合两个循环神经网络,一次性获得多个时刻的预测结果,且使得预测结果中保持着从前向后的时序依赖;注意力机制用于自适应地拟合目标序列对输入序列各个时间步的动态相关性,减弱误差积累现象。下面本发明对技术方案进行具体描述。
[0033]
如图1所示,本发明的一个较佳实施例中提供的一种集成小波分解与深度神经网络的水质指标多步预测方法,其主要步骤包括3步,分别为s1~s3:
[0034]
s1:对原始水质指标的历史监测数据序列使用线性插值法填补缺失值,使其在时间维度上连续,得到完整时间序列数据。
[0035]
s2:对填补缺失值后的完整时间序列数据进行离散小波变换得到多个分解序列,并对各分解序列进行重构恢复序列长度,得到1个近似信号与多个细节信号。
[0036]
s3:建立编码器
‑
解码器架构的神经网络模型,其中编码器基于双向门控循环单元构建,而解码器基于单向门控循环单元与全连接层构建,结合注意力机制提取解码器每步隐藏层状态与编码器所有隐藏层状态的相关关系。上述神经网络模型需要预先经过训练,训练后的模型可以以s2中得到的近似信号和细节信号作为输入值,准确输出水质指标的多步预测值。
[0037]
下面对于本实施例中s1~s3的具体实现方式以及其效果进行详细描述。
[0038]
首先,在水质指标的数据采集过程中,由于设备故障、操作失误、断面断流及其他异常状况的影响,往往会存在一些缺失值或异常值,干扰到实验过程与结果。因此,获取的原始水质指标的历史监测数据序列如果存在异常值,则需要先进行数据清理,将异常值进行清洗剔除。被剔除的异常值以及原本的缺失值构成了整条数据序列的缺失值。但是对于水质指标的预测而言,如果某个水质指标的原始数据在时间维度上的缺失率过高(通常认为缺失率不能超过10%),则这些数据不但不能提供有效的信息,反而可能影响最终的模型效果与预测精度,因此不适合使用本发明进行预测。本发明中,考虑到水质预测的合理性与准确性,对于缺失值,需要使用插值方法进行修补。本发明通过步骤s1来实现原始数据补全,针对每个空缺值进行线性插值处理,下面具体展开描述步骤s1中针对水质指标的原始数据进行线性插值的具体执行流程如下:
[0039]
[0040]
式中,式中,x表示需要插值的位置,y表示待插的缺失值,x0表示x的前一位置,y0表示x0位置的值,x1表示x的后一位置,y1表示x1位置的值。
[0041]
由此可见,在步骤s1中进行线性插值后,形成了时间维度上无间断的水质指标完整时间序列数据,这些数据可以标准化格式存储。在此基础上才能进行小波分解操作,且更有利于后续的神经网络学习。s1步骤后产生的完整时间序列数据需要通过s2步骤进行小波分解操作。较之基于三角基函数的傅立叶分解,基于小波基函数的小波分解方法在分析处理非线性、非平稳信号上具有独特的优势。因此,考虑到水质指标的数据特征,本发明中,使用小波分解方法分离数据波动的高频与低频特征,提取时频二维信息,减弱噪音影响。
[0042]
在步骤s2中,要执行的具体小波分解过程包括离散小波变换与小波重构。其具体过程如下:
[0043]
s21:对填补缺失值后的完整时间序列数据进行离散小波变换(dwt),得到多个分解序列。离散小波变换属于现有技术,通过变换可以将原始一维序列分解为1个低频信号a
n
和n个高频信号[d1,d2,
…
,d
n
]。
[0044]
s22:在小波变化结束后,通过小波重构(wavelet reconstruction)对分解序列进行逆变换。做小波重构的原因是由于小波变换后得到的分解序列样本点数量少于原始序列,而预测模型最好具有统一长度的输入,因此使用小波重构将它们分别转换为1个新的低频信号ra
n
和一系列n个新的高频信号[rd1,rd2,
…
,rd
n
],其序列长度与原始的完整时间序列数据一致,其中低频信号为近似分量,而高频信号为细节分量。由此,得到1个近似信号与多个细节信号。小波重构可以理解为小波变换的逆过程,其也属于现有技术。
[0045]
在步骤s2结束后,原始序列被分解为1个低频信号ra
n
和一系列高频信号[rd1,rd2,
…
,rd
n
],将其输入神经网络模型中进行多步预测。本发明中,提出的神经网络模型为一个基于注意力机制的编码器
‑
解码器模型,具体结构如图2所示,共包含了输入层、基于双向gru的编码器层、注意力层、基于单向gru的解码器层、输出层。
[0046]
上述步骤s3为该神经网络模型的具体构建过程:
[0047]
s31:构建基于双向门控循环单元(bidirectional gated recurrent neural network,bi
‑
gru)的神经网络结构,以步骤s2中获得的多个信号序列即1个近似信号和n个细节信号作为双向门控循环单元的输入,构成编码器。
[0048]
在该编码器层中,通过bi
‑
gru,可以将输入序列处理为等长的一系列隐藏层状态,同时输出前向、后向两个细胞状态,作为之后注意力计算和解码器解码的基础。bi
‑
gru的具体结构以及各参数计算公式属于现有技术,为了便于理解简述如下:
[0049]
h
f(t)
=f(h
f(t
‑
1)
,x
t
)
[0050]
h
b(t)
=f(h
b(t
‑
1)
,x
t
)
[0051]
h
t
=[h
f(t)
,h
b(t)
]
[0052]
式中,h
f
表示正向gru的输出,h
b
表示反向gru的输出,h表示双向gru的输出,t表示第t个时间步,[]表示串联操作。
[0053]
s32:构建基于单向门控循环单元(gated recurrent neural network,gru)与全连接层的神经网络结构作为解码器,并融入注意力机制,计算解码器每步隐藏层状态对于编码器所有隐藏层状态的注意力权重矩阵(attention weight)。再基于注意力权重矩阵和编码器所有隐藏层的输出值进行加权求和,计算上下文向量(contextvector)。然后以编码
器的最后一个时间步的输出值作为初始输入值,以编码器正向细胞状态与反向细胞状态之和作为初始细胞状态,将当前步的上下文向量、上一步的输出、上一步的隐藏层状态合并作为下一个时间步的输入值,在单向门控循环单元上叠加全连接层,输出下一个时间步的水质指标预测值,通过计算公式可以表示如下:
[0054]
y
i
=f(c
i
,p
i
‑1,s
i
‑1)
[0055]
式中,y
i
为当前步的输出,p
i
‑1为上一步的输出值,c
i
为当前步的上下文向量,s
i
‑1为上一步的隐藏层状态。
[0056]
单向门控循环单元gru本身也属于现有技术,为了便于理解,将其具体结构和各参数计算公式简述如下:
[0057]
z
t
=σ(w
z
·
[h
t
‑1,x
t
])
[0058]
r
t
=σ(w
r
·
[h
t
‑1,x
t
])
[0059][0060][0061]
y
t
=σ(w
o
·
h
t
)
[0062]
式中,h
t
为隐藏层状态,为候选隐藏层状态,r
t
为重置门,z
t
为更新门,不同的w为不同的权重矩阵,σ为激活函数,x
t
为当前t时刻的输入,yt为当前t时刻的输出。
[0063]
s33:上述s32中完成了一个未来时间步的水质指标预测,但本发明的目的在于实现多步预测,因此可不断将上一步的输出用于预测下一步。即按照设定的预测步数不断迭代,直至获得指定步数的预测值,即可得到水质指标多步预测结果。
[0064]
上述步骤s3构建了一个基于结合了注意力机制的基于单向gru循环神经网络与全连接层的解码器网络。注意力机制的核心在于反映出当前输出与输入序列中所有元素(而非仅仅上一个时间点)之间的关联程度,将其与解码器相结合,使得解码器中每个时间步都对编码器中各个时间步投以动态关注,解决了传统编码器
‑
解码器架构中信息衰减和误差积累的问题。
[0065]
需要注意的是,上述建立的编码器
‑
解码器架构的神经网络模型在实际使用前,需要进行模型训练,才能准确的用于水质指标多步预测。一般情况下,神经网络越深、越复杂,往往就越难优化。通过不断迭代、反向传播来实现梯度下降,以期逼近最佳结果是神经网络训练的通用思路,但在实际应用中,并不是训练代数越多,神经网络模型的效果就会越好。神经网络的训练效率和效果取决于多方面因素,为了获得更好的训练结果,我们需要对模型的训练过程进行调优。神经网络训练过程调优有多种方式,其中,使用学习率衰减(learning rate decay)机制能够很好地解决此问题,也就是慢慢降低学习率。在神经网络训练初期,选择比较大的学习率,更快地向最小值的方向收敛;在神经网络训练后期,即损失函数最小值附近、梯度下降速度变慢时,不断减少学习率,小步逼近最优结果。因为最终是要将模型应用于以测试集为代表的未知数据中,所以理论上神经网络模型的训练应该停在测试集损失函数值最小的时候,而非训练集损失函数值最小时。但实际应用中,由于测试集的损失函数值是不可知的,因此根据验证集进行早停是尽量避免模型在训练集上过拟合的有效手段。小批量梯度下降(mini
‑
batch gradient descent,mbgd)法将数据集分成多个固定大小的mini
‑
batch,每次训练其中一个,一次训练结束后更新一次权重和偏差,一代
(epoch)训练中可以调整多次,梯度下降更加高效,对于计算资源的需求也相对较少;同时由于是多个数据共同决定了本次梯度下降,训练过程较之随机梯度下降法更为稳定,不容易产生大的振荡。自适应矩估计(adaptive moment estimation,adam)算法可以对模型的训练过程进行优化,它结合了momentum算法和rmsprop算法,令每个参数都有独立的学习率和动量,训练过程中将有针对性地进行独立更新,对于稀疏或密集的数据集均适用。
[0066]
在本发明中,可使用自定义的模型优化训练框架对该模型加以训练,该框架中集成了学习率衰减机制、早停机制、小批量梯度下降策略与adam优化算法,训练步骤的具体过程如下:
[0067]
1)采用指数下降的学习率衰减方式,设定学习率衰减计算公式为:
[0068][0069]
式中,α0为原始学习率,α
′
为更新后的学习率,为学习率衰减比例,sg为总迭代次数,s
c
为冷静期总长,sd为衰减周期。
[0070]
2)指定监控误差指标与早停迭代阈值;
[0071]
3)指定小批量梯度下降法中的批大小;
[0072]
4)指定模型使用adam优化算法辅助梯度下降和学习率衰减;
[0073]
5)基于上述超参数,对构建的神经网络模型进行训练,使模型能够针对性输出多步水质指标预测值。
[0074]
下面基于上述s1~s3所述的方法,将其应用至具体的实例中对其效果进行展示。具体的过程如前所述,不再赘述,下面主要展示其具体参数设置和实现效果。
[0075]
实施例
[0076]
下面以长江流域2004
‑
2018年的cod
mn
(高锰酸盐指数)周监测数据为例,对本发明进行具体描述,其具体步骤如下:
[0077]
1)采用中国环境监测总站提供的长江流域2004
‑
2018年的cod
mn
(高锰酸盐指数)周监测数据,数据采自国家地表水环境质量监测网在长江流域内设置的23个监测断面,分别为湖南长沙新港、湖南岳阳城陵矶、湖南益阳万家嘴、湖南常德沙河口、湖南常德坡头、湖北宜昌南津关、湖南岳阳岳阳楼、湖北武汉宗关、湖北丹江口胡家岭、江苏扬州三江营、江苏南京林山、重庆朱沱、河南南阳陶岔、安徽安庆皖河口、贵州赤水鲢鱼溪、江西九江蛤蟆石、江西九江河西水厂、江西南昌滁槎、四川乐山岷江大桥、四川广元清风峡、四川宜宾凉姜沟、四川攀枝花龙洞、四川泸州沱江二桥。按照前述步骤s1利用线性插值法进处理缺失值和异常值,总数据量为17918条记录,缺失率为0.25%。
[0078]
2)按照前述步骤s2,使用小波分解和小波重构方法将插值补全后的cod
mn
数据分解为1个近似信号与3个细节信号,小波族选择daubechies小波族,消失矩个数选择5,分解级别选择3。
[0079]
3)根据前述步骤s3构建用于水质指标多步预测的基于编码器
‑
解码器架构的神经网络模型,其中编码器中双向gru的单元数设置为96,解码器中单向gru的单元数设置为96。模型历史步长选择8,预测步长选择3。
[0080]
4)根据历史步长8周、预测步长3周切分数据集,将分解后的数据划分为训练集、验证集、测试集,占比分别为80%、10%、10%。
[0081]
5)将训练集数据输入集成注意力机制的神经网络模型,开始训练模型,使用验证集进行控制模型训练方向,训练完毕得到水质指标多步预测模型。模型整体优化训练架构如图3所示,训练时各超参数的定义与赋值如下:
[0082]
(1)初始学习率:0.1;
[0083]
(2)最低学习率:1
×
10
‑8;
[0084]
(3)学习率衰减设置:监控指标:损失函数值;容忍期:5;冷静期:3;衰减比例:0.2;
[0085]
(4)早停设置:监控指标:均方误差;容忍期:10;
[0086]
(5)训练样本批大小batch_size:64;
[0087]
(6)最大训练迭代数:100。
[0088]
4)最后在测试集上检验上述水质指标多步预测模型的水质指标多步预测效果。
[0089]
将本实施例的水质指标多步预测模型命名为wd_attention_seq2seq_wqpp,采用消融实验(ablation experiment)方法验证模型中各个机制产生的作用,即逐一从完整模型中剥去相关模块,对比二者间的结果差异。各对比模型设定如下:
[0090]
①
基于wd_attention_seq2seq_wqpp剔除小波分解过程得到的attention_seq2seq_wqpp模型
[0091]
②
基于
①
再剔除attention机制得到的seq2seq_wqpp模型
[0092]
③
基于
②
再剔除编码器
‑
解码器架构得到的gru_wqpp模型
[0093]
与各对比模型相比,本发明提出的为wd_attention_seq2seq_wqpp模型在预测准确度(mae、rmse)、预测结果与真实值的分布一致性(ia)上均有提升,如下表1所示。在预测准确度上提高了至少65%(按rmse计算),预测值与真实值的分布一致性提高了至少19%。
[0094]
表1
[0095][0096]
为了直观展示重构效果,绘制了本模型的预测结果分布散点图,如图4所示,预测值与真实值集中分布在y=x直线附近,mae为0.148,rmse为0.256,mae为0.980,表明本发明的方法的各精度指标较为理想,预测值数据分布特征与真实值高度一致,对于水质指标的多步预测具有十分重要的实际应用价值。
[0097]
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
