基于trustzone的可信量化模型推理方法
技术领域
1.本发明属于物联网技术领域,更为具体地讲,涉及一种基于trustzone的可信量化模型推理方法。
背景技术:
2.随着物联网技术的发展,人们对硬件设备的安全化和智能化方面提出了更高的要求。得益于提供计算服务的硬件平台以及并行计算技术的发展,物联网设备的智能化得到巨大的提高。人工智能模型在设备端上的推理流程可以分为两个部分。一部分为非运行态的服务部分,即对模型管理的部分,其中包括网络模型解析、量化功能、优化网络模型等功能。另一部分为运行态相关的部分,其中包括计算库和硬件计算资源提供计算服务。而计算库中往往集成量化计算、neon指令技术、计算算法优化、并行计算等技术。图1是物联网人工智能模型推理的流程示意图。
3.由于对抗攻击技术的发展以及物联网设备面向的环境复杂多样,物联网设备的智能化过程面临着巨大的安全问题。因此物联网设备上的人工智能引擎如何能提供安全的计算环境服务,逐渐成为物联网中人工智能应用落地的一个研究发展的方向。而物联网中的设备终端,是安全保护的重点。trustzone是arm公司推出的,针对物联网设备终端的处理器cpu运行环境的安全技术。trustzone技术的思想是把一个单核cpu分为两种不同的执行环境:一种环境为普通世界,在这种环境下的cpu拥有很丰富的资源,因此linux系统和普通的用户应用会部署在普通世界的环境中;另一种环境是安全世界,在这种环境中的任务往往和安全相关的,例如安全算法校验、密码验证等,因此安全的os和应用会部署在安全中。但由于该架构技术的本质是单个cpu不同运行环境的分时共享,安全环境中安全应用根本无法执行多线程的操作,也就无法在多核上加速运行,这也是trustzone技术带来的资源限制问题。这也给人工智能模型推理带来了许多不便,需要进行进一步研究。
技术实现要素:
4.本发明的目的在于克服现有技术的不足,提供一种基于trustzone的可信量化模型推理方法,通过将简单计算节点部署至安全世界,复杂计算节点部署至普通世界,从而利用普通世界的多线程并行计算加快复杂计算节点的运算过程,从而提高人工智能模型推理效率。
5.为实现上述发明目的,本发明基于trustzone的可信量化模型推理方法包括以下步骤:
6.s1:对于执行人工智能模型推理的物联网终端设备,采用trustzone将cpu划分为两个执行环境:安全世界和普通世界;
7.s2:预先对人工智能模型进行量化规则设置,并生成量化模型保存至物联网终端设备的安全世界中;
8.s3:物联网终端设备对人工智能模型进行解析:将人工智能模型从原有格式转换
为onnx模型,然后进行protobuf反序列化,提取出人工智能模型的数据,将得到的数据划分为张量数据和计算节点数据,张量数据为人工智能模型推理各个计算节点的输入数据和输出数据,计算节点数据为人工智能模型中各个计算节点的数据和相关参数数据;然后根据步骤s1中设置的量化规则对张量数据进行量化,将量化后的张量数据和计算节点数据缓存至安全世界中;
9.s4:物联网终端设备根据预设的复杂度判定标准将接收到的计算节点划分为简单计算节点和复杂计算节点,然后在安全世界中划分出共享内存,将复杂计算节点数据及相关的张量数据放置到共享内存;
10.s5:当物联网终端设备需要进行人工智能模型推理时,将简单计算节点在安全世界中运行,将复杂计算节点通过共享内存发送至普通世界中运行,复杂计算节点运行时采用多线程操作;
11.s6:复杂计算节点在普通世界中计算得到运行结果后将其回传至安全世界,物联网终端设备在安全世界中根据预设的可信校验对复杂计算节点的运行结果进行校验,校验通过后和简单计算节点的运行结果整合,得到人工智能模型的推理结果。
12.本发明基于trustzone的可信量化模型推理方法,首先将执行人工智能模型推理的物联网终端设备采用trustzone技术划分为两个执行环境:安全世界和普通世界,在安全世界中对人工智能模型进行解析并进行数据量化,将计算节点划分为简单计算节点和复杂计算节点,将简单计算节点部署至安全世界,复杂计算节点通过安全世界的共享内存使得普通世界可以对其进行调用,在进行人工智能模型推理时,将简单计算节点在安全世界中运行,将复杂计算节点通过共享内存发送至普通世界中运行并将运算结果返回至安全世界,物联网终端设备在安全世界中对复杂计算节点的运算结果进行校验后与简单计算节点的运算结果进行整合,得到人工智能模型推理结果。
13.本发明通过将简单计算节点部署和复杂计算节点分别进行部署,提高人工智能模型推理效率。
附图说明
14.图1是物联网人工智能模型推理的流程示意图;
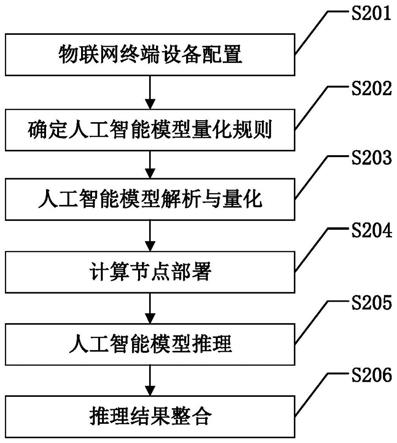
15.图2是本发明基于trustzone的可信量化模型推理方法的具体实施方式流程图;
16.图3是本发明中物联网终端设备的结构图;
17.图4是本发明中人工智能模型解析的流程图。
具体实施方式
18.下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
19.实施例
20.图2是本发明基于trustzone的可信量化模型推理方法的具体实施方式流程图。如图2所示,本发明基于trustzone的可信量化模型推理方法的具体步骤包括:
21.s201:物联网终端设备配置:
22.对于执行人工智能模型推理的物联网终端设备,采用trustzone将cpu划分为两个执行环境:安全世界和普通世界。
23.图3是本发明中物联网终端设备的结构图。如图3所示,本发明中物联网终端设备分为两个执行环境:安全世界和普通世界,安全世界承担模型解析、数据量化、推理执行和可信校验的任务,普通世界承担推理执行的任务,安全世界和普通世界之间通过通信接口实现信息交互。
24.s202:确定人工智能模型量化规则:
25.由于人工智能模型的输入数据通常是浮点数值,为了提高人工智能模型在物联网终端设备cpu上的运算速度,需要预先对人工智能模型进行量化规则设置,并生成量化模型保存至物联网终端设备的安全世界中。
26.量化规则可以根据人工智能模型输入数据的实际情况来进行设置,通常可以从arm计算库中选取。量化的方式包括对称与非对称两种方式。通过将浮点数值转成低比特数值,可以有效的降低人工智能模型计算强度、参数大小和内存消耗。本实施例中量化规则采用非对称量化,量化参数为量化比例和零点,通过遍历训练集数据来找到合适的量化参数。量化模型以尽可能保障量化前后数据的分布一致为原则,以信息熵为评价标准。
27.s203:人工智能模型解析与量化:
28.物联网终端设备对人工智能模型进行解析。图4是本发明中人工智能模型解析的流程图。如图4所示,本发明中人工智能模型解析方法为:将人工智能模型从原有格式转换为onnx模型,然后进行protobuf反序列化,提取出人工智能模型的数据,将得到的数据划分为张量数据和计算节点数据,张量数据为人工智能模型推理各个计算节点的输入数据和输出数据,计算节点数据为人工智能模型中各个计算节点的数据和相关参数数据。然后根据步骤s202中设置的量化规则对张量数据进行量化,将量化后的张量数据和计算节点数据缓存至安全世界中。
29.onnx(open neural network exchange,开放神经网络交换格式)是框架共用的一种模型交换格式,相当于一个翻译的作用,将不同格式的模型转换为统一格式,然后从中提取出所需的张量数据和计算节点数据。表1是张量数据格式示例。
[0030][0031][0032]
表1
[0033]
表2是计算节点数据格式示例。
[0034][0035]
表2
[0036]
s204:计算节点部署:
[0037]
物联网终端设备根据预设的复杂度判定标准将接收到的计算节点划分为简单计算节点和复杂计算节点,然后在安全世界中划分出共享内存,将复杂计算节点数据及相关的张量数据放置到共享内存。
[0038]
复杂度判定标准可以参考文献“molchanov p,tyree s,karras t,et al.pruning convolutional neural networks for resource efficient transfer learning[j].2016.”中方法进行设置。一般来说,复杂计算多为卷积计算。表3是卷积计算节点的数据格式示例。
[0039][0040]
表3
[0041]
s205:人工智能模型推理:
[0042]
当物联网终端设备需要进行人工智能模型推理时,将简单计算节点在安全世界中运行,将复杂计算节点通过共享内存发送至普通世界中运行,复杂计算节点运行时采用多线程操作。
[0043]
安全世界中的ta(trust application)与普通世界中的ca(client application)实现共享内存的具体方法如下:安全世界中ta和普通世界中ca建立连接,ca发送共享内存的命令tee_ios_shm_alloc,并通过硬件指令命令让自身陷入阻塞。linux系统通过smc指令让世界从普通世界切换到安全世界。由于ca并不知道共享内存应该设置的大小,在安全世界下,ta通过反向rpc调用,把需要共享的内存大小传递给linux系统,linux系统为ta与ca分配用于数据交互的共享内存,从而实现共享内存。
[0044]
在计算节点运行时,主要通过arm计算库接口进行计算。基于opencl以及opengl计算库,对计算算子初始化以及为各种张量分配内存空间,然后根据计算节点的具体计算内容进行运算。以卷积计算节点为例,首先对卷积计算节点调用cltensor接口初始化输入、输出、卷积核权重的张量层、卷积核偏置,创建cl调度器并进行初始化。通过cl调度器,设置运行时候的线程数涉及运行线程数,从而实现多线程并行计算,以提高运算速度。其次,创建卷积核权重的tensorshape类、偏置的tensorshape类,padstrideinfo类,并利用输入、输出、卷积核权重、卷积核偏置的分配器对计算节点进行初始化和配置,对输入的内存块与共享内存空间进行影射。
[0045]
s206:推理结果整合:
[0046]
复杂计算节点在普通世界中计算得到运行结果后将其回传至安全世界,物联网终端设备在安全世界中根据预设的可信校验对复杂计算节点的运行结果进行校验,校验通过后和简单计算节点的运行结果整合,得到人工智能模型的推理结果。
[0047]
以卷积计算节点为例,卷积计算中需要大量使用矩阵乘法,一个卷积运算可以由平铺算法和矩阵乘法来实现,执行矩阵乘法的为clgemm类。clgemm执行的是卷积矩阵与特征矩阵的乘法,矩阵乘法根据freivald算法进行。当节点任务需要进行卷积操作时候,就需要对该操作进行可信校验。本实施例中采用的可信校验方法为:在安全世界中从卷积运算中选取部分矩阵乘法进行计算,和普通世界中这些矩阵乘法的计算结果,如果计算结果一致,则可信校验通过,否则不通过。由于计算中涉及到量化数值,在计算后进行数值会因为饱和产生精度的变化,因此采用基于freivald算法思想的矩阵乘法校验来进行可信校验。
[0048]
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
