1.本发明涉及自然语言处理技术领域,具体地,涉及一种基于语义匹配的间隙句生成的文本摘要方法。
背景技术:
2.文本摘要是快速从海量文本信息中获取知识的重要手段,随着互联网上大量的文本以指数级别增长,自动文本摘要变得愈发重要。人工摘要需要大量人力,在文本内容庞大的情况下变得不切实际,因此,对各类文本进行一个压缩处理显得非常必要。
3.现有的摘要方法主要分抽取式和生成式两类。大多数抽取摘要系统是从原文中逐个打分、提取句子,甚至更小的语义单元,对句子之间的关系进行建模,然后选择几个句子形成摘要。在抽象式摘要中,通过编码器
‑
解码器这一套架构来生成能表达文本中心思想的摘要。另外还有混合摘要方法结合了这两种主要的摘要类型。尽管已经存在各种方法,但是在句子之间的流畅性和文本的冗余信息还存在不足。
4.随着大规模数据集的出现,深度学习的发展,序列到序列已经成为一个主流框架,基于该框架的rnn或者cnn架构把源文本编码成一个向量,再由解码器从向量中提取信息,获取语义并生成摘要。但是受模型的输入限制,如果文本长度超过模型的最大输入标记数,文档会被独立截断,最大输入大小的摘要窗口不允许在窗口之间进行信息交流,并导致摘要不一致。
5.最近在大型文本语料库上使用自监督目标的预训练模型在对下游nlp任务进行微调后取得很大成果,把重要的句子进行mask标识替换来通知模型进行预测生成。
技术实现要素:
6.有鉴于此,本发明的目的在于提供一种基于语义匹配的间隙句生成的文本摘要方法,该方法通过滑动窗口的指针生成网络对长文本进行重要内容截取,控制输入预训练模型的长度,使用bert编码候选组,选出语义最贴近源文本的一组作mask替换输入预训练模型进行预测生成摘要。
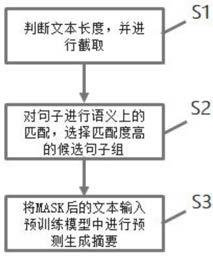
7.为达到上述目的,本发明提供如下技术方案:
8.s1、判断输入文本是否超过预训练模型输入长度,超过则进行截取;
9.s2、对经过步骤s1判断处理后的输入文本进行语义上的匹配,选择匹配度最高的候选句子组进行mask;
10.s3、将mask后的文本输入预训练模型进行预测生成摘要。
11.进一步的,步骤s1中输入长度限制为1024个tokens,截取的具体步骤为:
12.s11、滑动窗口,预先计算解码器需要为每个输入窗口生成的tokens数量;让窗口{win1,win2,...,win
n
}的大小等于源窗口数量,由窗口长度t
w
和滑动步长ss确定,使用公式(1)来确定每个窗口的权重e
s
:
13.e
s
(win
i
)=exp(
‑
k(1 i
·
d
i
))
ꢀꢀ
(1)
14.其中,k和d作为定义窗口上摘要分布形状的参数,i表示第i个窗口;
15.解码器要为窗口win
i
生成的tokens数量表示为:
16.num
i
=len*e
s
(win
i
)
ꢀꢀ
(2)
17.其中,num
i
为第i个窗口win
i
需生成的tokens数量,len为总的截取tokens数量;
18.s12、使用指针生成网络扩充基本的序列到序列模型,允许解码器在每个窗口中选择从扩展词汇表中生成token或源文档中复制token;生成概率可表示为:
[0019][0020]
其中,c
t
为上下文向量,s
t
为解码器的隐藏状态,x
t
为解码器的输入,w
c
、作为学习参数,σ为sigmoid函数;
[0021]
扩展词汇表中单词w的输出概率和从源文档中复制的概率分布可表示为:
[0022][0023]
这使指针生成网络在指定窗口中进行操作,下一步需要指定何时从一个源文档窗口转换到另一个源文档窗口。
[0024]
进一步的,步骤s2的具体步骤为:
[0025]
s21、使用原始bert从文档d和候选句子组c中导出语义上有意义的嵌入,所以直接用bert顶层的
″
[cls]
″
标识的向量作为文档或句子组的表示;让r
d
和r
c
分别表示文档d和候选句子组c的嵌入,则候选句子组得分为:
[0026]
c
sum
=cosine(r
d
,r
c
)
ꢀꢀ
(5)
[0027]
在推理阶段,选择语义得分最高的候选句子组作为模型的掩盖;从文档中抽取的所有候选句子组c中寻找最佳候选组,目标函数可表示为:
[0028]
c
max
=argmax(c
sum
)
ꢀꢀ
(6)
[0029]
s22、微调bert,加入一个边际为基础的三重损失函数来绑定权重;为了使摘要答案在语义上与源文档最接近,对应损失函数如下:
[0030][0031]
其中,d为源文档,c为候选句子组,c
*
为摘要答案,γ1是边际值;
[0032]
此外,还为所有候选句子组设计了一个成对的边际损失;将所有候选句子组按照与源文档的语义得分作降序排名;排名差距较大的候选对应该有较大的差距,故有如下损失函数:
[0033][0034]
其中,i<j,表示排名为i的候选句子组,γ2表示区分好坏的候选句子组的超参数;
[0035]
最终,损失函数表示为:
[0036]
α
loss
=α1 α2ꢀꢀ
(9)
[0037]
s32、候选句子组语义匹配时会碰到组合爆炸问题,为解决这个问题,提出一种剪枝策略,引入一个内容选择模块来计算单个句子的得分;该内容选择模块会去为每个句子计算一个在文档中的分数,并删减与当前文档无关的句子,从而生成一个删减后的文档d
′
:
[0038]
d
′
={s
′1,
…
,s
′
fil
|s
′
i
∈d} (10)
[0039]
内容选择器是使用bertsum对每个句子进行评分,然后根据得分对句子作降序排序,选择前fil个得分较高的句子,并根据文档中的原始位置重新组织句子顺序,形成候选句子集合;因此,将得到种候选句子组。
[0040]
进一步的,步骤s3对于中文摘要,使用基于lcsts数据集训练得到的预训练模型;对于英文摘要,使用基于c4数据集训练得到的预训练模型。
[0041]
本发明的有益效果在于:
[0042]
1、本发明利用滑动窗口的指针生成网络进行长文本截取,可以有效解决神经网络模型输入长度限制问题。
[0043]
2、通过选择语义匹配度最高的候选组句子作掩盖输入预训练模型,降低摘要的耦合度。
[0044]
3、无论在长文本摘要还是在短文本摘要,都能达到良好的鲁棒性。
[0045]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0046]
图1为本发明的流程示意图;
[0047]
图2为长文本截取的示意图;
[0048]
图3为语义匹配间隙句生成的示意图。
具体实施方式
[0049]
下面对本发明的实施例作详细说明:本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
[0050]
本发明实施例提供了一种基于语义匹配的间隙句生成的文本摘要方法,该方法适用于目标为k个句子的摘要,无论长短文本。对于长文本,更倾向于重要信息在源文档中分布均匀的。该方法能较好地解决处理长文本时独立截断出现的主要内容缺失问题,以及根据语义匹配选择mask输入预训练模型,降低摘要的耦合度。
[0051]
假设输入的源文本为d={s1,...,s
n
},一个文档包含n个句子。候选句子组为c={s1,...,s
k
|s
i
∈d},里面包含k个句子。该方法主要包括如下步骤:
[0052]
s1、判断输入文本是否超过预训练模型输入长度,超过则进行截取。
[0053]
s2、对句子进行语义上的匹配,选择匹配度最高的候选组中的句子进行mask。
[0054]
s3、将mask后的文本输入预训练模型进行预测生成摘要。
[0055]
优选地,步骤s1结合附图1对此步骤进一步详细描述。
[0056]
对于长度超过1024个tokens的长文本,根据不同的文本领域,采用不同的截取策略。新闻类的本文重要信息大多集中在文本开头,所以可以直接截断前1024个tokens。百科类型的本文,重要信息散落在整个文档,采用滑动窗口指针生成网络作截断。将截断后的文
本作为源文本。
[0057]
具体地,学习每个源文本位置在一个t
w
标记窗口上的注意力,然后依次在长文本上滑动窗口,从而允许在推断时总结任意长度的文档进行截取。
[0058]
对于指针生成网络,扩充了基本序列到序列模型,允许解码器在每一步中选择从训练词汇生成token和源文档中复制token。生成概率可表示为:
[0059][0060]
其中,c
t
为上下文向量,s
t
为解码器的隐藏状态,x
t
为解码器的输入,w
c
、作为学习参数,σ为sigmoid函数。
[0061]
扩展词汇表中单词w的输出概率和从源文本中复制的概率分布可表示为:
[0062][0063]
这使指针生成网络在指定窗口中进行操作。
[0064]
对于滑动窗口,需要指定何时从一个源文本窗口转换到另一个窗口。预先计算解码器需要为每个输入窗口生成的令牌数。让窗口{win1,win2,...,win
n
}的大小等于源窗口数量(由t
w
和ss确定)。我们使用下面函数来确定每个窗口的权重:
[0065]
e
s
(win
i
)=exp(
‑
k(1 i
·
d
i
))
[0066]
其中,k和d作为定义窗口上摘要分布形状的参数。
[0067]
解码器要为窗口win
i
生成的tokens数量可以表示为:
[0068]
num
i
=len*e
s
(win
i
)
[0069]
其中,num
i
为第i个窗口需生成的tokens数量,len为总的截取tokens数量。
[0070]
优选地,步骤s2可以细分为mask句子选择、微调bert、候选剪枝三部分。
[0071]
对于mask句子选择,使用原始bert从文档d和候选摘要c中导出语义上有意义的嵌入,所以直接用bert顶层的
″
[cls]
″
标识的向量作为文档或句子组的表示。让rd和rc分别表示文档d和候选句子组c的嵌入,则候选句子组得分为
[0072]
c
sum
=cosine(r
d
,r
c
)
[0073]
在推理阶段,我们将选择语义得分最高的候选句子组作为模型的掩盖。在从文档中抽取的所有候选句子组c中寻找最佳候选组,目标函数可表示为:
[0074]
c
max
=argmax(c
sum
)
[0075]
对于微调bert,加入了一个边际为基础的三重损失函数来绑定权重。为了使摘要答案在语义上与源文档最接近,对应损失函数如下:
[0076][0077]
其中,d为源文档,c为候选句子组,c
*
为摘要答案,γ1是边际值。
[0078]
此外,还为所有候选句子组设计了一个成对的边际损失。我们将所有候选句子组按照与源文档的语义得分作降序排序。排名差距较大的候选对应该有较大的差距,故有如下损失函数:
[0079][0080]
其中,c
i
表示排名为i的候选句子组,γ2表示区分好坏的候选句子组的超参数。
[0081]
最终,损失函数可以表示为:
[0082]
α
loss
=α1 α2[0083]
对于候选剪枝,候选句子组语义匹配时会碰到组合爆炸的问题,为解决这个问题,我们提出一种剪枝策略,引入了一个内容选择模块来计算单个句子的得分。该模块会去为每个句子计算一个在文档中分数,并删减与当前文档无关的句子,从而生成一个删减后的文档d’={s
′1,...,s
′
fil
|s
′
i
∈d}。
[0084]
内容选择器是使用bertsum对每个句子进行评分,然后根据得分对句子作降序排序,选择前fi1个得分较高的句子,并根据文档中的原始位置重新组织句子顺序,形成候选句子集合。因此,将得到种候选句子组。
[0085]
优选地,步骤s3中预训练模型,是基于pegasus的,对于英文摘要,可以使用其中的c4预训练模型;对于中文摘要,可以使用lcsts数据集在pegasus
base
上重新训练得到中文的预训练模型。将前几步得到的选中候选句子组在对应的源文本作mask替换,得到{s1,[mask],...,s
n
}。输入预训练模型进行预测摘要生成。
[0086]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
