1.本发明涉及自然语言处理领域的信息抽取方法,尤其涉及一种基于词性分析的文本时间信息抽取与规范方法。
背景技术:
2.时间是描述事件的三种基本要素的其中之一,可以用来定位事件发生的时间,根据上下文时间点和事件顺序来推断当前事件发生时间以及对事件的跟踪等。
3.时间是客观存在的,是自然语言处理领域实体抽取中的一项基础性任务,是自然语言表述中必不可少的一个语义成分。基于英文文本抽取的技术相对较为成熟,已经有timex一系列的标注规范,然而人们虽然对时间概念已经形成了一定的一致性,但是只存在于一些规范化要求比较高的文本或者在文章特殊的位置,对时间概念的描述形式会因为中文表达的灵活性和多样性,语法和语义跟英文差别较大,使得不能照搬英文的处理方式,抽取难度较大。
4.目前,时间信息抽取相关研究还是比较多的,主要分为基于规则匹配的方法和基于机器学习的方法两种。其中,基于规则匹配的方法较为简单,需要归纳总结各种时间信息表达的规律,通过遵循这些规律来编写信息抽取规则,来实现这些规则下的时间信息抽取。这种方法方便理解和扩展,而且抽取效率和准确率都较高,但受限于制定的规则体系,人工需要总结的规则较多,工作量较大。基于机器学习的方法需要一定规模标注好的语料训练机器学习模型,该方法受限于训练语料的标注质量和规模,而且准确率往往没有基于规则匹配的高,较少使用在时间信息抽取的任务当中。
技术实现要素:
5.本发明提供一种基于词性分析的文本时间信息抽取与规范方法,相对于现有技术方法,旨在提高抽取正确率和召回率。
6.本发明可以通过以下技术方案实现:
7.一种基于词性分析的文本时间信息抽取与规范方法,在规则上加入词性分析,来提供更高的准确率和召回率,所述的方法包括以下步骤:
8.s1、构建多个时间词性模版;
9.s2、文本通过分词工具提取出分词结果和对应词性列表,利用时间信息匹配模版提取出时间信息短语;
10.s3、根据不同时间词性模版,提取多个时间信息短语,并对提取出来的时间信息短语进行分类;
11.s4、根据映射规则,输出最后规范化后的结果。
12.进一步的,时间词性模版具体的表达形式是(*pos_tagging,unit),unit是时间单位,*pos_tagging是修饰时间单位的词性列表,该参数长度不固定,依据双亲委派原则,优先使用长度较长的模版进行匹配。
13.进一步的,步骤s1具体为:
14.s101、从标注好的训练语料中通过nlpir工具,自动生成各种时间信息分词后的结果和对应词性,并将该结果转化成时间词性匹配模版;
15.s102、提取并总结时间正则模版,用于时间信息提取后的分类问题;
16.s103、提取并总结时间信息前、中、后,三个位置的介词,形成三种介词模版,用于词性匹配后的修正问题和时间信息提取后的分类问题。
17.进一步的,根据双亲委派原则,对文本分词后对应的词和词性进行时间词性模版匹配,优先传递给等级高的模版,然后回溯返回结果,每个时间词性模版匹配前都会先判断是否已经匹配成功,只有未匹配成功才会进行匹配,否则直接回溯。
18.进一步的,步骤s2根据介词模版对匹配结果进行修正,介词包括:前置介词、中置介词和后置介词。其中有些词既可作前置介词,又可作后置介词。
19.进一步的,步骤s3时间信息短语分类,主要分为五类:日历时间、时钟时间、相对时间、段时间、其他时间。其中,日历时间和时钟时间是具体的时间点,它们的时间表示粒度不同,通常作为参考时间;日历时间最小粒度为天,最大粒度为年;时钟时间最小粒度为秒,最大粒度为小时;相对时间,是需要上下文时间才能确定下的时间;段时间,是指一段时间,从一个时间点到另一个时间点,通常会有明显的中置介词。其他时间,包括模糊时间和一些无法规范的时间。
20.进一步的,步骤s3时间信息短语分类,通过总结的时间正则模版,对时间信息提取的结果进行分类,具体为:
21.a、根据日历时间的时间正则模版去匹配,将匹配上的时间信息短语标注上日历时间类别;
22.b、根据时钟时间的时间正则模版去匹配,将匹配上的时间信息短语标注上时钟时间类别;
23.c、根据前置介词和后置介词修正的时间信息,直接对时间信息短语标注上相对时间类别并覆盖之前标注的类别;
24.d、根据中置介词修正的时间信息,直接对时间信息短语标注上段时间类别并覆盖之前标注的类别。
25.进一步的,步骤s4时间信息映射和规范化,包括时间信息粒度的一一对应,以及对段时间的推理规范化。
26.进一步的,所述段时间推理规范化可用函数关系式表示:
27.result=offset*number*unit contexttime
28.其中,result表示规范化后的结果,offset表示偏移量,number表示偏移长度,unit表示时间粒度,contexttime表示上下文参考时间。
29.进一步的,时间推理规范化过程中,缺少时间粒度的采用以下方法进行补全:
30.a、只有时钟时间没有日历时间的情况下,缺少日历时间部分根据上下文参考时间进行补全;
31.b、只有日历时间没有时钟时间的情况下,直接对时钟时间部分的各个时间粒度置零。
32.与现有技术相比,本发明具有以下优点:
33.1、解决了规则匹配中因缺少词性分析而造成了多义词语的类型识别;
34.2、形成了高质量的时间信息匹配模版,提高了时间信息识别、抽取的准确率和召回率;
35.3、解决了时间信息映射过程中主要的难点:时间类别的区分、相对时间的转换以及时间缺少部分的补全;
36.4、精简了时间类型,更加针对性地解决时间规范化的问题。
37.本发明提高了召回率和准确率,并补充了上下文词性相关信息、解决了多以词的区分,解决了时间信息映射过程中主要的难点:时间类型的区分、相对时间的转换以及时间缺少部分的不全。
附图说明
38.图1为构建时间信息模版库流程图;
39.图2为时间信息抽取与规范化流程图。
具体实施方式
40.下面将结合发明附图对实施例中的技术方案进行清楚、完整地描述。基于本发明中所描述的实施例,仅用于解释本发明,本领域普通技术人员在没有创造性劳动下获得的实施例都应该属于本发明的保护范围。
41.本发明公布了一种基于词性分析的文本时间信息抽取与规范方法,实现对时间信息的抽取和规范,从而为命名实体抽取中的时间实体抽取提供高性能解决方案。
42.图1所示为本发明实施例提供的时间信息模版构建的流程图。模版构建主要包括以下过程:
43.1、通过分词工具将带有标注的时间信息语料进行分词并标注词性,输出token和pos_tagging二元组形式,其中token表示单个词,pos_tagging表示对应的词性。
44.2、对带有时间单位时间信息进行词性分析,生成对应的时间词性匹配模版,可以由函数(*pos_tagging,unit)表达,其中unit表示时间单位,*pos_tagging是修饰时间单位的词性列表,该参数长度不固定,依据双亲委派原则,优先使用长度较长的模版进行匹配。如表1所示。
45.3、对所有时间信息通过人工统计,构建了包含前置介词、中置介词、后置介词的介词库。如表2所示。并总结时间信息的特征类别,将时间信息短语分类,主要分为五类:日历时间、时钟时间、相对时间、段时间、其他时间。其中,日历时间和时钟时间是具体的时间点,它们的时间表示粒度不同,通常作为参考时间。日历时间最小粒度为天,最大粒度为年,时钟时间最小粒度为秒,最大粒度为小时。相对时间,是需要上下文时间才能确定下的时间。段时间,是指一段时间,从一个时间点到另一个时间点,通常会有明显的中置介词。其他时间,包括模糊时间和一些无法规范的时间。如表3所示。
46.表1词性匹配示例表
47.模版表达式示例adjective numeral classifier noun unit近四个月numeral numeral classifier unitxx多年
numeral classifier unit8个月numeral adjective unit一个多月numeral unit三天pronoun unit这个月
48.表2介词库示例
[0049][0050]
表3时间正则模版库
[0051][0052]
[0053]
表中所示示例仅为一般文本通用实现,可根据自身需求对不同领域文本进行扩充,如:历史相关文本,有较多关于帝王年号的时间信息,可根据这些时间信息的特征加入到对应的库中。
[0054]
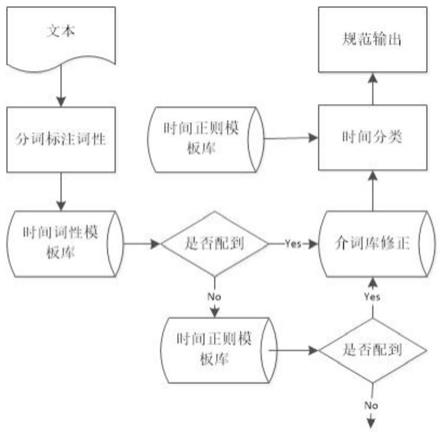
图2所示为本发明实施例提供的时间信息抽取与规范化流程图,包括以下步骤:
[0055]
s1、构建多个时间词性模版;
[0056]
s2、文本通过分词工具提取出分词结果和对应词性列表,利用时间信息匹配模版提取出时间信息短语;
[0057]
s3、根据不同时间词性模版,提取多个时间信息短语,并对提取出来的时间信息短语进行分类;
[0058]
s4、根据映射规则,输出最后规范化后的结果。
[0059]
所述的分词工具,为nlpir分词工具,输入文本后能得到文本的分词结果,输出token和pos_tagging二元组形式,其中token表示单个词,pos_tagging表示词对应的词性。
[0060]
根据上述的分词结果进行遍历匹配自动打上标签。
[0061]
假设匹配到('月','noun'),它是一个时间单位词,它所处的上下文为[('8','numeral'),('个','classifier'),('月','noun')]。首先会使用时间词性模版进行匹配,根据双亲委派原则对其进行匹配,当匹配成功时,会在匹配的到token下打上标签"1",如果未匹配上就打上标签"0"。
[0062]
对于没有匹配上的,会使用时间正则模版库中的模版进行匹配,主要针对一些不带时间单位的特殊时间信息词和分词工具无法精确拆分带有时间单位的时间信息词,如"元旦"、“妇女节”、“三月”等。也将自动地打上标签。
[0063]
所述的双亲委派原则是指,会优先递归提交给等级较高的词性模版进行匹配,在本发明中等级较高指词性模版长度较长的。当前模版匹配前会先判断当前有无匹配上,如果匹配上了,则会直接回溯,如果没有匹配上,才会进行匹配任务。这样可以缩短匹配时间,提升匹配效率。
[0064]
基于一个文本中的内容,所有token都匹配过了才会进入介词库的修正,使用介词库对已经匹配上的时间信息词前中后三个位置进行修正:
[0065]
a、假设示例['本','周六']对应的标签为[0,1],会对这个['本']使用前置介词进行匹配,然后更新对应标签;
[0066]
b、假设示例['三月','到','八月']对应的标签为[1,0,1],会对中间的['到']使用中置介词进行匹配,然后更新对应标签;
[0067]
c、假设示例['3','年','后']对应的标签为[1,1,0],会对后面的['后']使用后置介词进行匹配,然后更新对应标签。
[0068]
所述的根据不同模版提取出来时间信息进行判定分类,分类过程具体为:
[0069]
1)依据匹配后的标签结果进行合并token,假设示例['上','个','月']对应标签为[1,1,1],合并结果为"上个月";
[0070]
2)将合并后得到的时间信息短语依据正则模版和介词库进行匹配分类;
[0071]
3)根据日历时间的正则模版去匹配,将匹配上的标注上日历时间类别;根据时钟时间的正则模版去匹配,将匹配上的标注上时钟时间类别;
[0072]
4)根据前置介词和后置介词修正的时间信息匹配,覆盖标注上相对时间类别;
[0073]
5)根据中置介词修正的时间信息匹配,覆盖标注上段时间类别。
[0074]
时间信息映射和规范化,包括时间信息粒度的一一对应,以及对段时间的推理规范化,利用函数对段时间推理规范化表示:
[0075]
result=offset*number*unit contexttime
[0076]
其中,result表示计算的结果,offset表示偏移量,number表示偏移长度,unit表示时间粒度,contexttime表示上下文参考时间。
[0077]
相对时间通常特定的前置或者后置介词,如“四天后”、“今年”、“下个星期”,根据上述推理式子,确定上下文参考时间contexttime和时间单位unit,根据前后介词选择对应的偏移量,根据短语中的数词确定偏移长度,这两个参数往往是对立的,当有数词的时候,偏移量可选只有1和
‑
1,当没有数词时,number默认为1,具体偏移完全由offset决定。如,“下下个星期”,offset为
‑
2,number为默认的1,unit为星期。“5天后”,offset为1,number为5,unit为天。
[0078]
表达式规范化后的输出结果表示:
[0079]
具体时间点"yyyy
‑
mm
‑
dd hh:mm:ss",段时间"yyyy
‑
mm
‑
dd hh:mm:ss~yyyy
‑
mm
‑
dd hh:mm:ss"。
[0080]
例,"2020
‑
10
‑
09 09:30:00","2020
‑
10
‑
09 09:30:00~2020
‑
10
‑
1009:30:00"。
[0081]
对于时间规范化过程中,缺少粒度的,采用以下方法进行补全:
[0082]
a、只有时钟时间没有日历时间的情况下,缺少日历时间部分可用根据上下文参考时间进行补全;
[0083]
b、只有日历时间没有时钟时间的情况下,直接对时钟时间部分的各个粒度置零。
[0084]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
